






核心数据结构
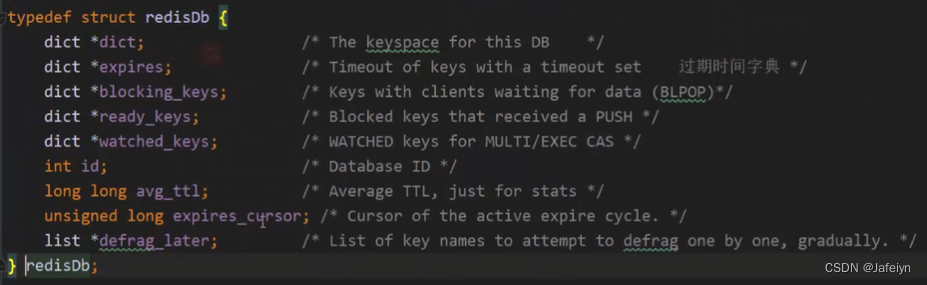
Redis DB默认16个,可在redis.conf配置,底层结构上他们都是一样的,唯一不同的是id不同,其代码结构如下:
Redis整体采用KEY-VALUE数组结构,数组中的保存的是一个个的dictEntry,其代码结构如下:
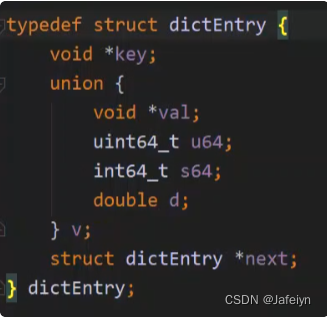
KEY用数组存储,对key进行位与运算得到下标位置,若hash冲突则用链表存储;
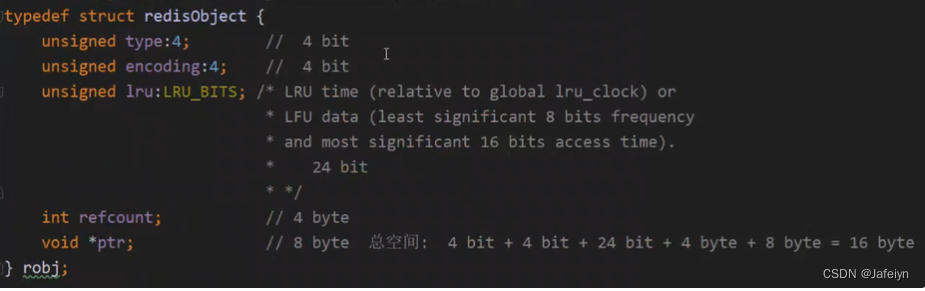
VALUE为redisObject对象,对象中的*ptr指向真实的数据Object,如:int、raw、embstr、quickList、hashtable、zipList、intset、skpList,其代码结构如下:
Redis核心数据结构包括String、Hash、List、Set、ZSet。
1. 字符串String
Redis String是最基础的key-value结构,数据保存在两个dict结构中,两个dict是为后续扩容渐进式rehash做准备,每个dict底层由hashtable(数组)实现,所有的key都会处理成String类型。
String类型在Redis3.2之前是自定义SDS数据类型,Redis3.2之后key的长度不同所对应的类型也不同。
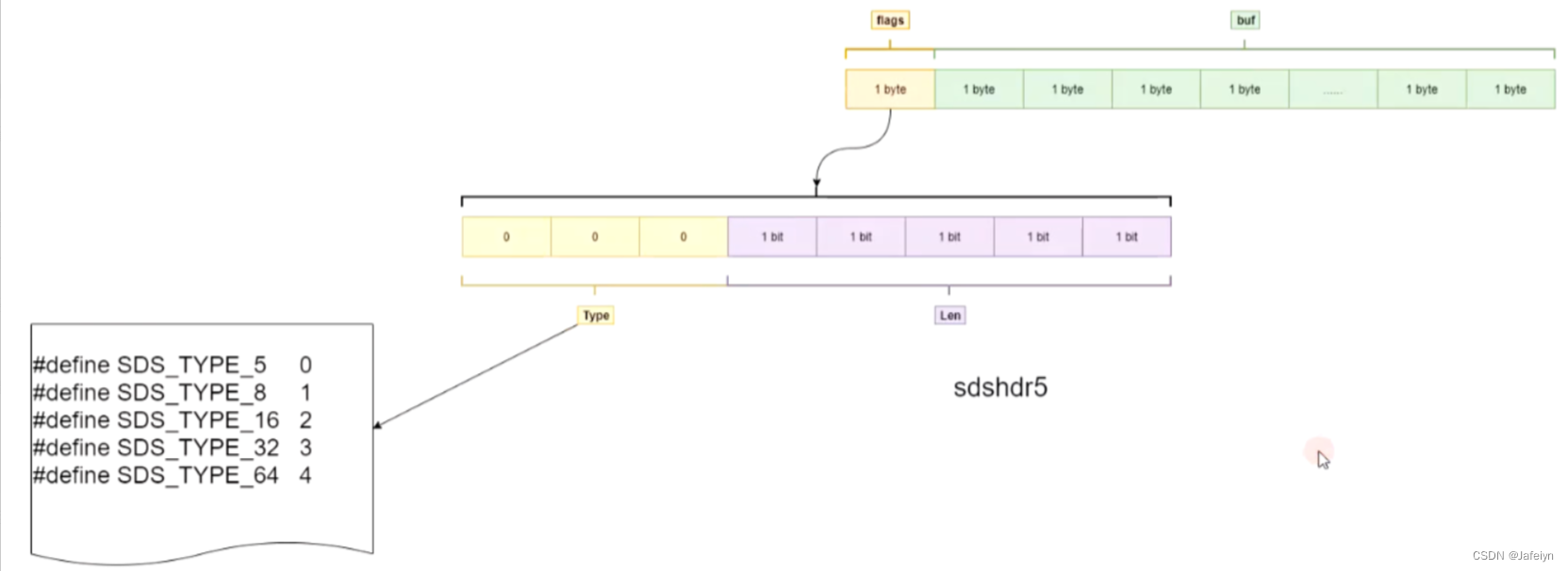
SDS类型包括:SDS_TYPE_5, SDS_TYPE_8, SDS_TYPE_16, SDS_TYPE_32, SDS_TYPE_64
下面以sdshdr5结构图例
sdshdr8代码示例:
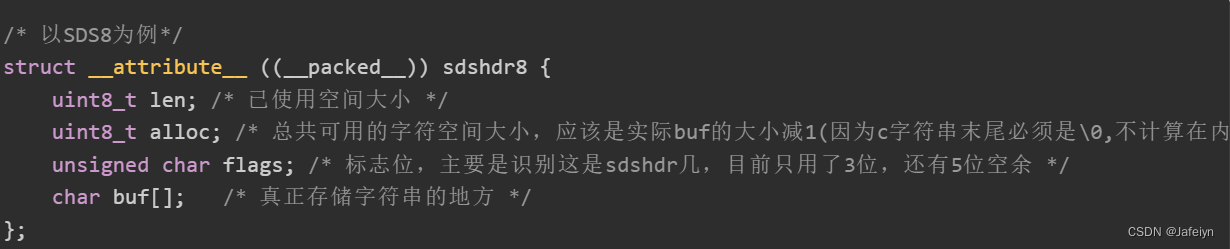
SDS与C语言字符串区别:
- C语言字符串采用N+1的字符数组的方式表示字符串;而SDS除了采用字符数组作为字符串数据外还添加了len, alloc, flag三个字段保存额外信息。
- C语言字符串一般用作不常修改的字面量,修改字符串时重新分配内存空间比较麻烦;基于性能考虑,每次新建SDS时都会预分配一些空间应对未来的增长,而这种预分配额外空间的方式有效的降低了内存溢出的可能以及减少了修改字符串时的内存分配的次数。
- C语言字符串长度获取是从头到尾挨个遍历,时间复杂度为O(n);而SDS中的len记录的是实际字符串长度,时间复杂度O(1)就可以获取到。
- C语言字符串以"\0"字符作为字符串结果标志,故不能保存二进制数据;而SDS是以len判断字符串结果,与末尾是否存在"\0"字符无关,故SDS可以保存二进制数据。
基本使用命令
- SET key value
- GET key
- MSET key value [key value …] (批量set)
- MGET key [key …] (批量get)
- SETNX key value(存入一个不存在的键值对)
- DEL key [key …]
- EXPIRE key seconds(给key设置过期时间)
- INCR key(将key中储存的数字值加1(原子操作))
- DECR key(将key中储存的数字值减1(原子操作))
- INCRBY key increment 将key所储存的值加上increment(原子操作)
- DECRBY key decrement (将key所储存的值减去decrement(原子操作))
bitmap
底层String实现,用bit保存状态(默认为0)。应用场景为 日活量统计。如一个用户占一个bit位,以用户ID为bitmap数组下标,用户1有登陆则将其值置为1,则8个用户就是1个字节,String最大值为2的32次方bit位,则可以保存512MB的用户量。
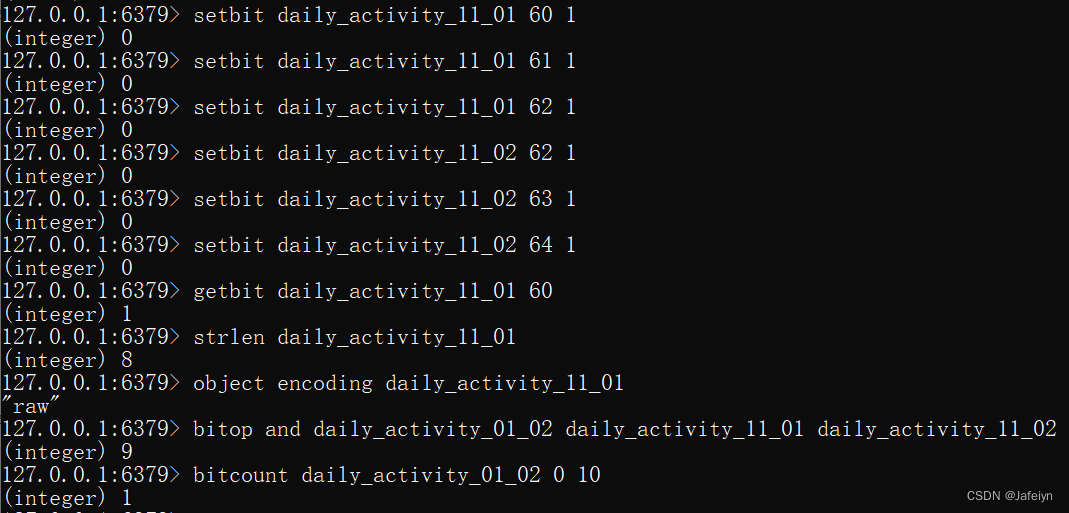
bitmap常用命令:
● setbit key offset value
● getbit key offset
● strlen key //查看value的长度
● object encoding key //查看value数据类型
● bitcount key[start end] //统计bitmap中value为1的数量
● bitop and temp login1 login2 //将login1日志和login2日志通过位与运算(类似取并集)
应用场景
- 单值缓存(set key value / get key)
- 对象缓存 (set user:1 userString / mset user:name jeffrey user:age 16 / mget user:name user:age)
- 分布式锁(setnx key value / del key)
- 计数器(incr article:like:{id} / get article:like:{id})
- web集群session共享(spring session + redis)
2. Hash哈希

哈希底层就是一个dict,同样存储Key-Value结构,当数据量较小或单个元素比较小时使用ziplist存储,数据量较大或单个元素比较大时数据结构改用hashtable存储。
Hash数据⼤⼩和元素数量阈值可以通过如下参数设置:
hash-max-ziplist-entries 512:ziplist元素个数超过512,将改为hashtable编码类型
hash-max-ziplist-value 64:单个元素⼤⼩超过64byte时,将改为hashtable编码类型
String与Hash数据结构对比:
- String类型将Key-Value保存在同一个数组中,若数据量较大就会频繁rehash扩容,
- Hash类型将外层的Key保存在一个桶中,将内层的field保存到另一个小桶中,Hash只能对外层key设置有效期而不能对field设置有效期
基本命令使用
- HSET key field value
- HGET key field
- HMSET key field value [field value …] (批量存入哈希表key多个键值对)
- HMGET key field [field …] (批量获取哈希表key中多个field键值)
- HSETNX key field value (存入一个不存在的哈希表key的键值)
- HDEL key field [field …]
- HLEN key(获取哈希表key中field数量)
- HGETALL key (获取哈希表key中所有键值)
- HINCRBY key field increment (为哈希表key中field键的值加上增量increment)
应用场景
- 对象存储(HMSET user UID01:name jeffrey UID01:age 16 / HMGET user UID01:name UID01:age)
- 购物车(HSET UID01:cart order111 2 / HINCRBY UID01:cart order111 3 / HLEN UID01:cart / HDEL UID01:cart order111 / HGETALL UID01:cart)
3. List列表
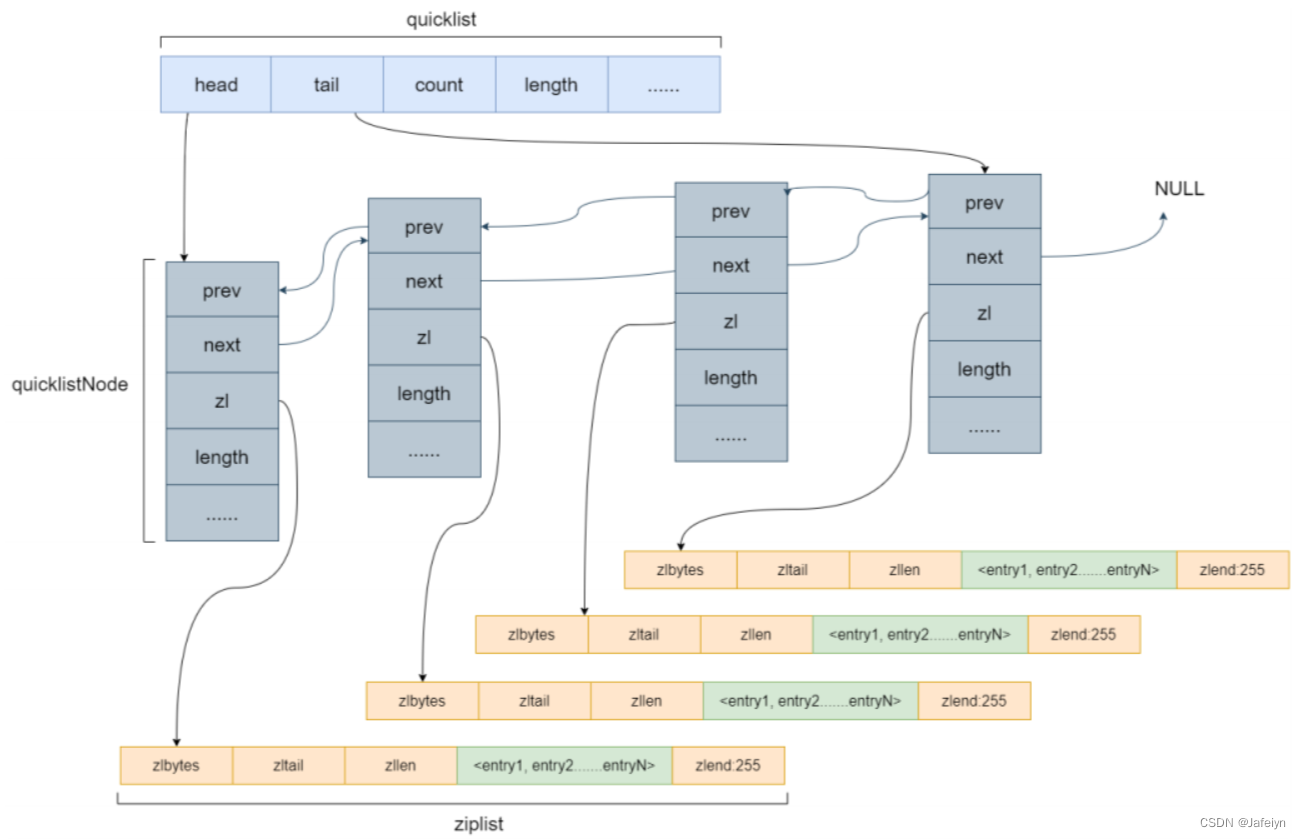
列表是个按照添加顺序排序的有序结构,底层采用quicklist(双端链表)和ziplist(保证有序)实现存储,故列表可以从两端存取数据。列表不使用链表作为存储结构的原因是链表需要额外保存两个prev和next指针空间,并且链表内存不连续易造成内存碎片造成空间浪费问题。
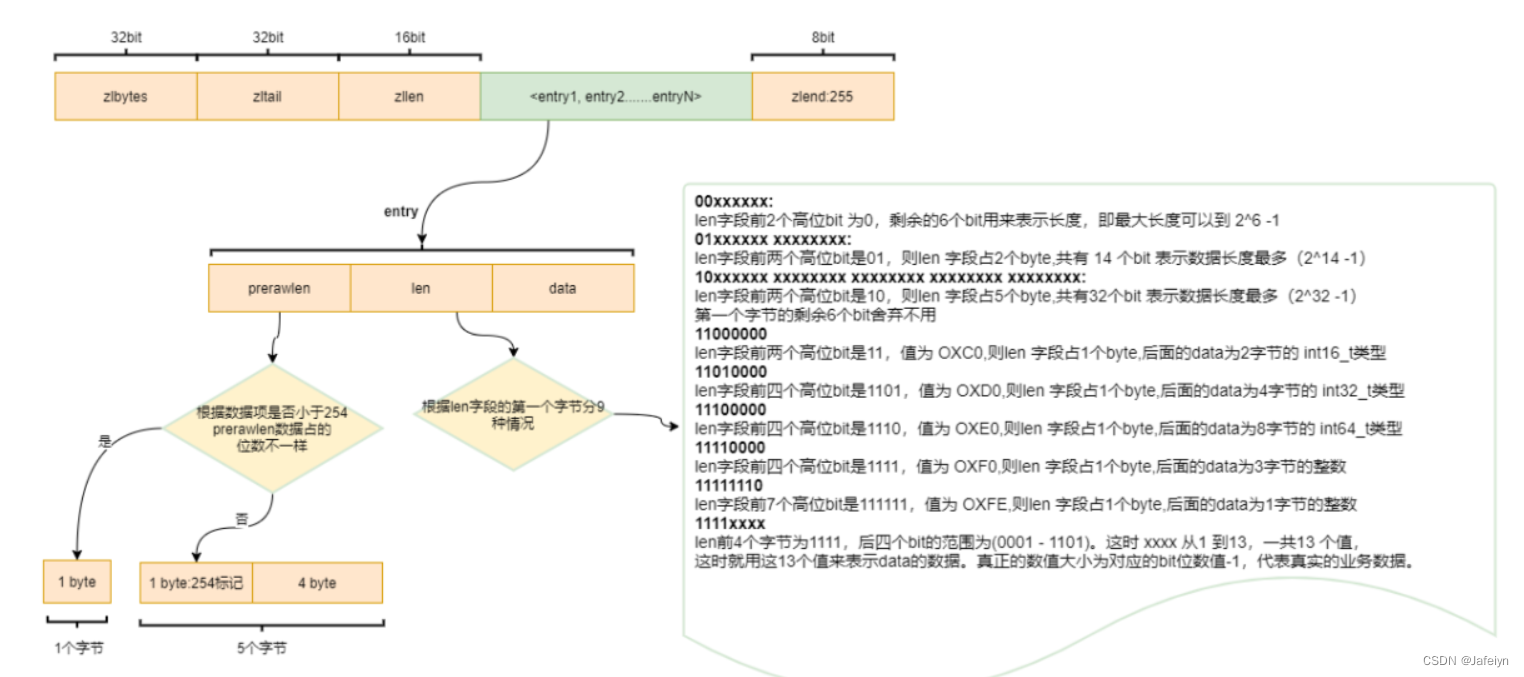
⼀个ziplist是⼀个连续的内存空间,其中包括ziplist中的数据量32位,ziplist的尾部指针32位(⽅便从后往前遍历,最快找到尾节点),ziplist的元素个数16位,在ziplist的最后⼀个元素是固定的8位,恒等于255。
中间的数据部分中,每个元素entry中包含前驱指针,⻓度和数据。前驱指针会判断是否⼤于254,如果⼩于,那么使⽤⼀个字节来保存(⼀个字节最⼤可以保存255)元素个数,如果⼤于则使⽤5个字节记录元素个数。
如果redis仅使⽤ziplist来保存list的数据,那么如果数据量很⼤的情况,在删除和新增元素的时候会出现⼤量的复制,所以把整个list分成了若⼲个ziplist,每个ziplist在形成链表。
链表的每个节点,都指向了⼀个ziplist,这样使每个ziplist都不会很⼤,过⼤的ziplist会进⾏分列,称为两个节点。
ziplist的⼤⼩是可以配置的,可以通过设置每个ziplist的最⼤容量,quicklist的数据压缩范围,提升数据存取效率。
list-max-ziplist-size-2:单个ziplist节点最⼤能存储8kb,超过则进⾏分裂,将数据存储在新的ziplist节点中。
list-compress-depth1:0代表所有节点,都不进⾏压缩,1,代表从头节点往后⾛⼀个,尾节点往前⾛⼀个不⽤压缩,其他的全部压缩,2,3,4…以此类推。
基本命令使用
- LPUSH key value [value…]
- RPUSH key value [value…]
- LPOP key (移除并返回列表key表头/最左边元素)
- RPOP key (移除并返回列表key表尾/最右边元素)
- LRANGE key start stop (返回列表key中指定区间内的元素(从表头/最左边开始))
- BLPOP key [key…] timeout(移除并返回列表key表头/最左边元素,若列表为空则阻塞timeout秒,若timeout为0则一直阻塞)
- BRPOP key [key…] timeout (移除并返回列表key表尾/最右边元素,若列表为空则阻塞timeout秒,若timeout为0则一直阻塞)
应用场景
- 常用数据结构(栈:LPUSH + LPOP,队列:LPUSH + RPOP,阻塞队列:LPUSH + BRPOP)
- 微博消息/微信公众号消息推送(LPUSH UID01 msg01,LPUSH UID01 msg02,LRANGE UID01 0 10)
4. Set集合
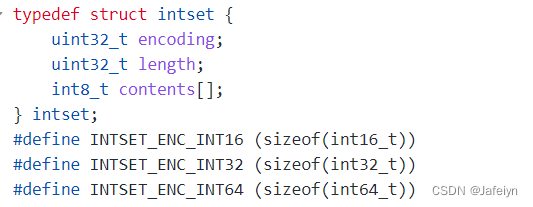
Set集合是一个无序且去重的结构,其底层为一个值为null的dict;
Set集合可以存储整形,整形数据在Set集合中被编码为intset数组结构,并且整数集合是有序的,整型集合在Redis中可以保存int16_t,int32_t,int64_t类型的整型数据,并且可以保证集合中不会出现重复数据;
当元素不是整数或者元素个数超过intset最大值set-max-intset-entries(512)时,Set集合就会用hashtable编码;
当intset数据长度超过64时也会改用hashtable编码;
基本命令使用
- SADD key element [element …]
- SREM key element [element …] (从集合key中删除元素)
- SMEMBERS key (获取集合key所有元素)
- SCARD key(获取集合key元素个数)
- SISMEMBER key element(判断元素是否在集合key中)
- SPOP key [count](从集合key中取出count个元素,元素从key中删除)
- SRANDMEMBER key [count](从集合key中取出count个元素,元素不从key中删除)
- SINTER key [key …](集合交集)
- SINTERSTORE dest key [key …](集合交集运算结果存入新集合dest)
- SUNION key [key …](集合并集)
- SUNIONSTORE dest key [key …](集合并集运算结果存入新集合dest)
- SDIFF key [key …](集合差集)
- SDIFFSTORE dest key [key …](集合差集运算结果存入新集合dest)
应用场景
- 商品筛选场景
- 抽奖场景(SADD 抽奖活动ID userId / SMEMBERS 抽奖活动ID / SPOP 抽奖活动ID 3 / SRANDMEMBER 抽奖活动ID 3)
- 点赞、关注、收藏、标签等场景(SADD 新闻 用户 / SREM 新闻 用户 / SMEMBERS 新闻 / SISMEMBER 新闻 用户 / SCARD 新闻)
- 关注模型场景(集合间的操作,如SINTER A关注集合 B关注集合 / SISMEMBER A关注集合 C / SDIFF A关注集合 B关注集合)
5. ZSet有序集合
ZSet集合是一个有序且去重的结构,底层为dict与skiplist结合实现;
当元素较少时使用ziplist编码存储,当元素个数超过128或者单个元素大小超过64字节时改用skiplist编码存储;
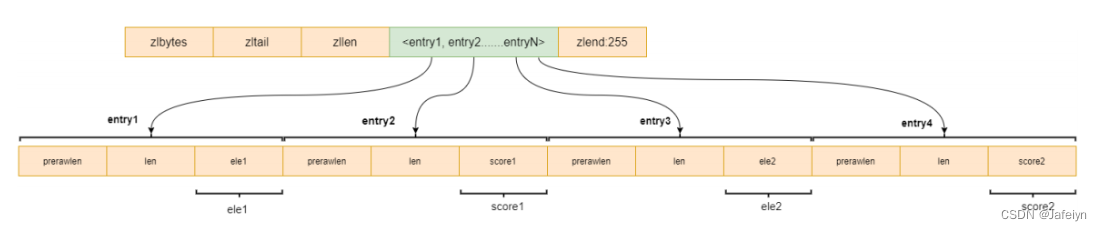

元素数量较大时不使用链表的原因包括查找数据效率低,需要每个节点都要遍历一次;
跳表工作原理为在数据层的上层,把部分数据的索引提出⼀个索引层,按照折半查找的逻辑,数据量为N,每⼀层都提出N/2个索引,第⼀层提出N/2个索引,第⼆层提出N/2 ^ 2个索引,那么提出K层时,第K层会提出N/2 ^ K个索引,假设第K层只有两个索引时,查找⼀个元素每层的索引的查找都是常数,所以时间复杂度是O(logN);
Redis Zset集合底层实现在跳表机制上进行了改进,头节点不保存数据,仅保存跳表的⾼度,有三个元素,100,120,200,每个元素都有⼀个backword指针,指向前⼀个节点,可以从后往前遍历整个链表,在zskiplist中保存了头节点和尾节点,⻓度和最⾼的层⾼,查询时是从上往下遍历的,相较于链表存储,其查询效率更高了;
基本命令使用
- ZADD key score element [[score element] …]
- ZREM key element [element …](删除有序集合key中的元素)
- ZSCORE key element(获取有序集合key中元素的分值)
- ZINCRBY key increment element(为有序集合key中的元素加increment分值)
- ZCARD key(获取有序集合key中元素个数)
- ZRANGE key start end [WITHSCORES](正序获取有序集合key中下标从start到end的元素)
- ZREVRANGE key start end [WITHSCORES] (倒序获取有序集合key中下标从start到end的元素)
- ZINTERSTORE dest numkeys key [key …](交集计算结果写入到dest集合)
- ZUNIONSTORE dest numkeys key [key …](并集计算结果写入到dest集合)
应用场景
- 排行榜场景(ZINCRBY 2022-11-12头条 1 新闻ID / ZREVRANGE 2022-11-12头条 0 9 WITHSCORES)
redis其他命令
#查看redis配置信息
info
#全量遍历键,数据量较大时阻塞线程性能较差(不建议使用)
keys
#渐进式遍历键
#cursor:游标,默认从0开始,每次会返回下一次的游标数值,一直遍历到cursor返回0为止;
#MATCH:key的正则模式;
#COUNT:一次查询的数量(返回的数量有可能比数值多,有可能比数值少,因为在遍历的时候可能会删除/新增数据);
#注意:在scan的过程中如果发生对key增删改操作,那么新增的键可能没有遍历到,遍历出了重复的键等情况,也就是说scan并不能保证完整的遍历出来所有的键
scan cursor [MATCH pattern] [COUNT]















 1637
1637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









