






强化学习算法——Reinforce with baseline
最近在看一篇强化学习求解组合优化问题的论文,在使用的算法Reinforce with rollout baseline 这个地方看了很久,终于弄懂了真实网络(我们称为Actor)和基线网络(我们称为baseline)这两者之间的关系和逻辑,下面结合具体代码总结一下。
论文:Solve routing problems with a residual edge-graph attention neural network
https://github.com/leikun-starting/DRL-and-graph-neural-network-for-routing-problems
Reinforce 算法是基于策略的最基本的算法,原理和实现都比较简单。
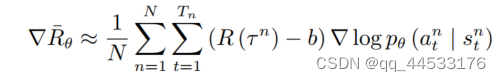
基线b可以看成是对当前策略网络的性能的平均评估(可以看成班上所有同学的平均分)。基线b的选择是多样化的,可以是一个常数(平均值),但大多时候为了提升算法的性能会选择用另一个网络来拟合基线baseline,即用一个网络来估计平均成绩,我们称之为critic网络,这样的REINFORCE算法可以看成AC算法的一种。
但这篇文献里采用的baseline是和Actor结构一样的网络,因此只需要训练一个网络,只在必要的时候将Actor复制给baseline,当成两个网络使用。
文件1.VRP_Rollout_train.py
1.创建两个数据集
data_loder:用于训练
valid_loder:用于比较Actor和baseline的性能差距(数据量小很多,毕竟只是用来检验一下两个网络的性能) 2.baseline初始化
2.baseline初始化
初始时baseline和Actor网络参数完全相同
3.Actor更新
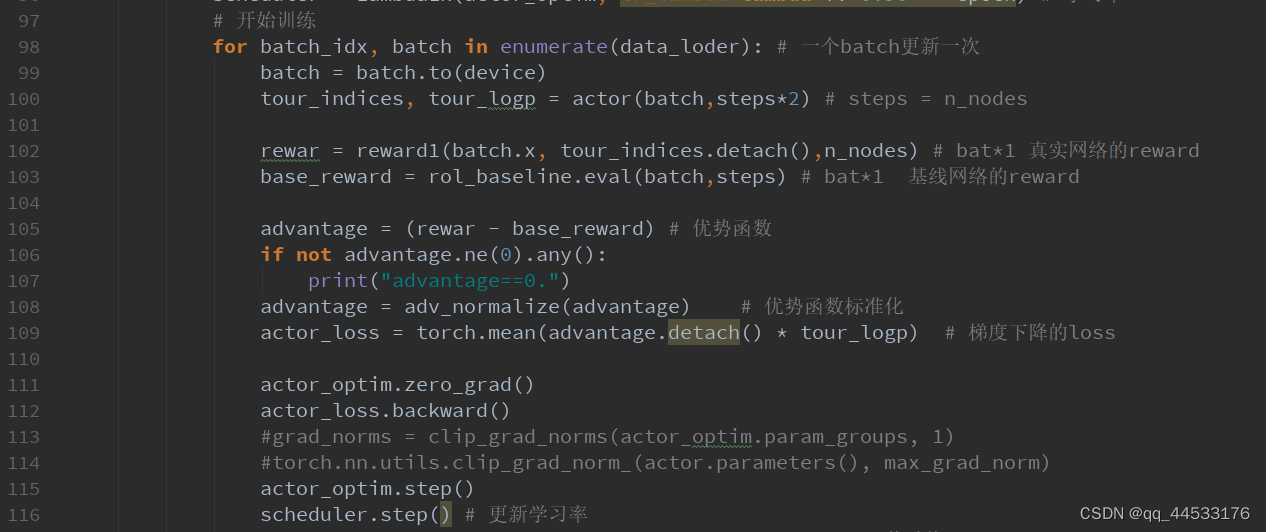 100-105行:同一个batch,分别用Actor和baseline计算奖励函数值,作差得到优势函数值
100-105行:同一个batch,分别用Actor和baseline计算奖励函数值,作差得到优势函数值
开始训练后,每过一个batch,进行一次loss反向传播,Actor进行一次更新
4.baseline更新

通过T-检验,判断Actor和baseline之间的差距,当Actor以一定的程度优于baseline时,则用当前的Actor替换baseline.
为什么要这么做呢?因为随着Actor的参数更新,输出的动作肯定是越来越优,那么真正意义上的基线值也是在随之变化的;但基线值只是反应一个大致的平均水平,因此它并不需要十分准确,但它要能实时地反映Actor的性能,所以只有当Actor以一定程度优于baseline时,才需要对baseline进行更新。
注意:Actor在每个batch都会进行更新,而baseline只在必要的时候更新(可以看成Actor一直在往前跑,而baseline跑一会停一会,当发现和Actor之间的距离太大时就跑一下)
文件2.rolloutBaseline1.py
def rollout(model, dataset, n_nodes):
model.eval()
def eval_model_bat(bat):
with torch.no_grad():
cost, _= model(bat,n_nodes*2,True)
cost = reward1(bat.x,cost.detach(), n_nodes)
return cost.cpu()
totall_cost = torch.cat([eval_model_bat(bat.to(device))for bat in dataset], 0)
return totall_cost
class RolloutBaseline():
def __init__(self, model, dataset, n_nodes=50,epoch=0):
super(RolloutBaseline, self).__init__()
self.n_nodes = n_nodes
self.dataset = dataset
self._update_model(model, epoch) # 传入RolloutBaseline的模型传入 _updata_model
# 更新模型 使用当前模型计算所有样本的路径长度的平均值
def _update_model(self, model, epoch, dataset=None):
self.model = copy.deepcopy(model) # 基线网络
self.bl_vals = rollout(self.model, self.dataset, n_nodes=self.n_nodes).cpu().numpy()
self.mean = self.bl_vals.mean() # 所有样本的平均路径长度
self.epoch = epoch
# 使用当前模型评估当前batch的路径长度
def eval(self, x, n_nodes):
with torch.no_grad():
tour, _ = self.model(x,n_nodes,True)
v= reward1(x.x, tour.detach(), n_nodes)
# There is no loss
return v
def epoch_callback(self, model, epoch): # 和_updata_model不是同一个model
print("Evaluating candidate model on evaluation dataset")
candidate_vals = rollout(model, self.dataset, self.n_nodes).cpu().numpy() # 最新的actor
candidate_mean = candidate_vals.mean() # 所有样本的路径长度的平均值
print("Epoch {} candidate mean {}, baseline epoch {} mean {}, difference {}".format(
epoch, candidate_mean, self.epoch, self.mean, candidate_mean - self.mean))
if candidate_mean - self.mean < 0: # 新的网络达到一定程度的更优
# Calc p value
t, p = ttest_rel(candidate_vals, self.bl_vals)
p_val = p / 2 # one-sided
assert t < 0, "T-statistic should be negative" # 达到一定程度的更优
print("p-value: {}".format(p_val))
if p_val < 0.05:
print('Update baseline')
self._update_model(model, epoch) # 更新基线网络
需要注意的是,epoch_callback里的model是自己传入的model,计算candidate_mean的model实际上是Actor,而self.mean是由_update_model中的model计算得到的,这个model最初由RolloutBaseline初始化得到(rolloutBaseline1.py 77行),后面经过epoch_callback方法调用_update_model方法来更新。

















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









