






训练算法:基于错误提升分类器的性能
AdaBoost是adaptive boosting(自适应boosting)的缩写,它是如何运行的呢?
- 训练样本,赋予权重,构成向量。训练数据中的每一个样本,并赋予其一个权重,这些权重构成了向量D。
- 一开始,这些权重都初始化成相等值。
- 首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。
- 在分类器的第二次训练中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。
- 为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。
错误率ε定义如下:

alpha计算公式如下:
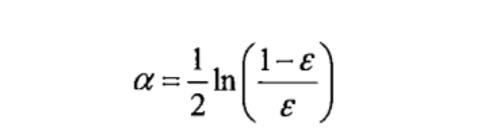
AdaBoost算法的流程图如下:

左边是数据集,其中直方图的不同宽度表示每个样例上的不同权重。在经过一个分类器之后,加权的预测结果会通过三角形中的alpha值进行加权。每个三角形中输出的加权结果在圆形中求和,从而得到最终的输出结果。
-
计算出alpha值之后,对权重向量D进行更新,使正确分类的样本权重降低而错分样本的权重升高。
如果某个样本被正确分类:
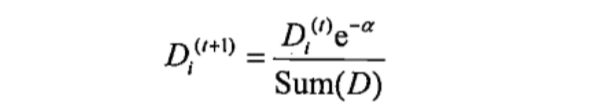
如果某个样本被错误分类:
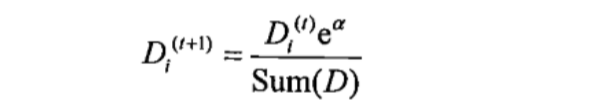
-
AdaBoost进入下一轮迭代,AdaBoost算法不断重复训练和调整权重的过程,直到训练错误率为0或弱分类器的数目达到用户的指定值为止。















 4520
4520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









