







基本概念
目的:用于发现隐藏在大型数据集中的有意义的联系,用关联规则或频繁项集的形式表示。
处理关键问题:①从大型事务数据集中发现模式可能在计算中要付出很高的代价。② 所发现的某些模式可能是虚假的,因为可能是偶然发现的。
1. 问题定义
项集和支持度计数: I = { i1, i 2 ……}是购物篮中所有项的集合, T = { t1 , t2……} 是所有事务的集合。每个事务 ti 包含的项集都是 I 的子集。在关联分析中, 包含 0个或多个项的集合被称为项集(itemset)。如果一个项集包含 K 个项,则称它为 k-项集。
例子: {Milk, Bread, Diaper}
支持度计数(Support count):包含特定项集的事务个数:( σ)
例如: σ({Milk, Bread,Diaper}) = 2
**支持度:**包含项集的事务数与总事务数的比值。
例如: s({Milk, Bread, Diaper}) = 2/5
频繁项集(Frequent Itemset):满足最小支持度阈值(minsup)的所有项集。
事务的宽度:事务中出现项的个数。
关联规则:关联规则是形如 X →Y 的蕴含表达式, 其中 X 和 Y 是不相交的项集
例子: {Milk, Diaper} →{Beer}
关联规则的强度:
- 支持度 Support (s)——确定项集的频繁程度。
- 置信度 Confidence ( c ) ——确定Y在包含X的事务中出现的频繁程度。


关联规则挖掘问题
给定了事务的集合 T,关联规则发现是指找出支持度大于等于 minsup 并且置信度大于等于 minconf 的所有规则,minsup 和 minconf 是对应的支持度和置信度阈值。
挖掘关联规则的一种原始方法是:计算每个可能规则的支持度和置信度,但是这种方法代价很高,令人望而却步,因为可以从数据集提取的规则的数目达指数级。更具体的说,从包含 d 个项的数据集提取的可能规则总数为:

大多数关联规则挖掘算法通常采用的一种策略是:将关联规则挖掘任务分解成如下两个主要的子任务。
- 频繁项集产生:其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集(frequent itemset)。
- 规则的产生:其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称为强规则(strong rule)。
通常,频繁项集产生所需的计算开销远大于产生规则所需的计算开销。
1. 频繁项集的产生

格结构(lattice structure)常常被用来枚举所有可能出现的项集。一般来说,一个包含 K 个项的数据集可能产生 2 k - 1 个频繁项集。不包括空集在内。由于在许多实际应用中 k 的值可能非常大,需要探查的项集搜索空间可能是指数规模的。
发现频繁项集:
原始方法:确定格结构中每个候选项集的(candidate itemset)支持度计数。为了完场这个任务,必须将每个候选项集与每个事务进行比较。这种方法的开销很大,需要进行 O(NMw)次比较。其中 N 是事务数, M = 2 k - 1 是候选项集数,而 w 是事务的宽度。
如何降低产生频繁项集的计算复杂度?重重重重点
- 减少候选项的数目 (M)。之后要介绍的 apriori 原理,是一种不用计算支持度值而删除某些候选项集的有效方法
- 减少比较次数。替代将每个候选集与每个事务相匹配,可以使用更高级的数据结构或者存储候选项集或者压缩数据集,来减少比较次数
拓展,典型算法:
DiapAIS 算法(R. Agrawal等提出)
Apriori算法(及变种AprioriTid和AprioriHybrid))
SETM 算法(M. Houtsma等提出)
DHP 算法(J. Park等提出)
PARTITION 算法(A.Savasere等提出)
Sampling 算法(H.Toivonen提出)
FP-growth 算法(Jiawei Han提出)
重头戏 先验原理
如何使用支持度度量,帮助减少频繁项集产生是需要探查的候选项集个数,使用支持度对候选项集剪枝基于如下原理。
- 如果一个项集是频繁的,则它的所有子集一定也是频繁的
- 如果一个项集是非频繁的,则它的所有超集也一定是非频繁的:
- 这种基于支持度度量修剪指数搜索空间的策略称为基于支持度的剪枝(support-based pruning)
- 这种剪枝策略依赖于支持度度量的一个关键性质,即一个项集的支持度绝不会超过它的子集的支持度,这个性质也称为支持度度量的反单调性(anti-monotone)。
Apriori 算法的特点
- 它是一个逐层算法。即从频繁 1 - 项集到最长的频繁项集,它每次遍历项集格中的一层
- 它使用产生-测试策略来发现频繁项集。在每次迭代,新的候选项集有前一次迭代发现的频繁项集产生,对每个候选的支持度进行计数,并与最小支持度阈值进行比较。
- 该算法需要的总迭代树是 Kmax + 1,其中 Kmax 是频繁项集的最大长度
候选的产生于剪枝——如何从 频繁(k-1)-项集推导出候选k-项集
- 候选项集的产生:
(1)蛮力办法。将所有k-项集都看作可能的候选,然后使用候选剪枝出去不必要的候选,

造成了很大的浪费,很无脑。
总复杂度:
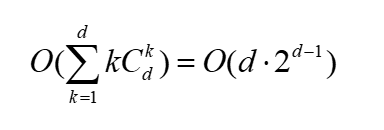
(2)Fk-1 × F 1方法 比如用 频繁2-项集和频繁 1-项集 扩展频繁 3-项集。

总复杂度:
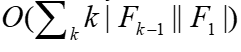
好像聪明了一些,但是其实某些候选项是不必要的,可以再次优化,比如确保每个频繁项集中的项以字典形式储存,每个频繁项集X 只用字典序比 X 中所有的项都大的频繁项进行扩展。
(3)F k-1 和 Fk-1方法,函数 apriori-gen 的候选产生过程合并一对频繁(k-1)项集,仅当它们的前 k-2个项都相同。

- 候选项集的剪枝——基于支持度的剪枝策略,剔除掉一些候选 k-项集。
如何进行剪枝中的支持度计数?
- 枚举:枚举出每个事务所包含的项集,并且利用它们更新对应的候选项集的支持度。例如枚举事务 t 中所有 3-项集的系统的方法。假定每个项集中的项都以递增的字典序排列,则可以如下枚举:

- 使用 hash树进行支持度计数——很重要
案例分析:
假设有15个候选3-项集:
{ 1 4 5 }, { 1 2 4 }, { 4 5 7 }, { 1 2 5 }, { 4 5 8 } , { 1 5 9 }, { 1 3 6 }, { 2 3 4 }, { 5 6 7 }, { 3 4 5 } , { 3 5 6 }, { 3 5 7 }, {6 8 9 }, { 3 6 7 }, { 3 6 8 }
第一步:按照 Hash 函数 h§ = p mod 3来确定应当沿着当前结点的哪个分支向下:如 1,4,7应当散列在相同的分支(即最左分支),因为除以3都具有相同的余数。

第二步:将每个事务与候选项集所在的 hash 树进行比较,并对应增加支持度计数。

Apriori算法的计算复杂度受哪些因素影响?
- 支持度阈值。 降低阈值,产生更多频繁项集,
- 项数(维度)。项数越多,需要更多的空间来存储项的支持度计数,频繁项集数目也可能受影响。
- 事务数。
- 事务的平均宽度,影响频繁项集 k- 的最大长度以及候选项集可能变得更多。

















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









