 卷积与池化在深度学习中的应用
卷积与池化在深度学习中的应用





根据前面的卷积过程,我们可以达到特征提取的作用。基本上已经判断出谁是C谁是D。底下可以再进一步做一次池化。数据库连接池记得吧?把很多数据库连接放在一个池子里,想用时挑一个来用。这里做完卷积得到这么多数据,就像池子一样,对于这池子里的数据,我们可以继续做各种各样的操作,比如最大池化或平均池化。最大池化顾名思义就是从池子中取出最大值。注意取最大值,不是整体取最大值,而是邻域取最大值。结果就如下图,第一个区域(只有四个数)的最大值是5,第二个区域的最大值是1。以此类推。
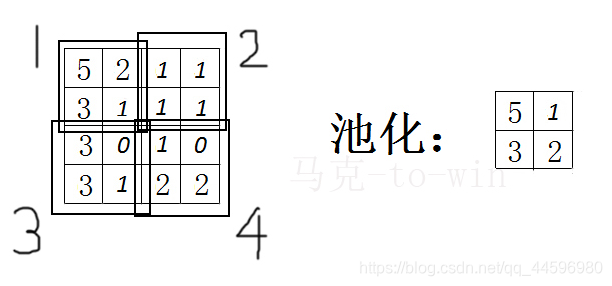
经历了以上两步卷积和池化以后,我们得到的结果,真是太好不过了。首先,经过卷积,也就是特征提取,我们成功的得到了结果5。这个值越大,就说明特征越突出,越能增加最后判断结果的正确性。第二步池化,还能把不是特征的部分丢弃,起到去燥的效果,还为我们将来。。。。。。。。。。。。。。。。。。
更多请见:http://www.mark-to-win.com/tutorial/mydb_ConvoluNeural_WhatPooling.html

















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









