






申请空间接口
__get_free_pages函数
此函数用于分配一页或多页的物理内存,并返回一个指向这段内存的指针。在Linux内核中的物理内存是以页的形式组织的,每一页内存通常是4KB。_get_free_pages 函数可以用来分配任意数量的页,只需要传入一个整数参数来指定需要分配的页数。这个函数在内部首先会调用get_order 函数来计算需要分配的页的数量,然后调用alloc_pages函数来真正分配内存。最后函数会返回第一个页框的起始地址。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
注意:使用*_get_free_pages* 函数分配的内存是物理内存,不是虚拟内存。这段内存是直接映射到物理内存中的,而不是通过虚拟内存映射实现的。因此在使用这个函数分配内存时,需要确保不会出现内存泄漏或者内存错误,以免造成系统崩溃或者数据丢失。
_get_free_pages 函数只能在Linux内核空间中使用,不能在用户空间调用。因为在用户空间无法直接操作物理内存,一般需要通过系统调用或者其他接口来分配内存。
alloc_pages函数会分配长度为1<<order的 连续页框块order参数的最大值由include/Linux/Mmzone.h文 件中的MAX_ORDER宏决定,在默认的2.6.18内核版本中,该宏定义为10。也就是说在理论上__get_free_pages函数一次最多能申请1<<10 * 4KB也就是4MB的内存大小。
kmalloc函数
在内存块中按照2的order次方字节来创建多个slab描述符,如16字节、32字节、64字节、128字节等大小,系统会 分别创建kmalloc-16、kmalloc-32、kmalloc-64等slab描述符,在系统启动时这在create_kmalloc_caches()函数中完成。例如,要分配30字节的一个小内存块,可以用“kmalloc(30,GFP_KERNEL)’’ 实现,之后系统会从kmalloc-32 slab描述符中分配一个对象。
kmalloc:分配物理连续的内存地址(则虚拟地址自然连续,基于 slab)。
kfree:配套,释放 kmalloc 分配的内存地址。
vmalloc函数:
vmalloc:分配不连续的物理地址空间,但虚拟内存地址是连续的。
vfree:配套,释放 vmalloc 分配的内存地址。
一致性DMA映射
不需要手动刷cache,硬件来保证cache一致性
缓冲区的分配和映射
void *dma_alloc_coherent(struct device *dev,size_t size,dma_addr_t *dma_handle,int flag);
该函数处理了缓冲区的分配和映射。前两个参数是device结构和所需缓冲区的大小。
- 函数的返回值时缓冲区的内核虚拟地址,可以被驱动程序使用。
- 相关的总线地址则保存在dma_handle中。
释放缓冲区
void dma_free_coherent(struct device *dev,size_t size,
void *vaddr,dma_addr_t dma_handle);
DMA池
DMA池是一个生成小型、一致性DMA映射的机制。调用dma_alloc_coherent函数获得的映射,可能其最小大小为单页。如果设备需要的DMA区域比这还小,就要用DMA池。
头文件 <linux/dmapool.h>
缓冲区的分配和映射
struct dma_pool *dma_pool_create(const char *name,struct device *dev,
size_t size,size_t align,
size_t allocation);
name是DMA池的名字,dev是device结构,size是从该池中分配的缓冲区大小,
align是该池分配操作所必须遵守的硬件对齐原则。
销毁DMA池
void dma_pool_destroy(struct dma_pool *pool);
DMA池分配内存
void *dma_pool_alloc(struct dma_pool *pool,int mem_flags,
dma_addr_t *handle)
释放内存
void dma_pool_free(struct dma_pool *pool,void *vaddr,dma_addr_t addr);
流式DMA映射
流式映射希望能与已经由驱动程序分配的缓冲区协同工作,因而不得不处理那些不是它们选择的地址。缓冲区来自内核的较上层,上层很可能用的是普通的kmalloc() _get_free_pages()等方法,这时候就要使用流式DMA映射
需要手动刷cache。
当建立流式映射时,必须告诉内核数据流动的方向。
- DMA_BIDIRECTIONAL:不清楚传输方向则可用该类型,一致性内存映射隐性的设置为DMA_BIDIRECTIONAL
- DMA_TO_DEVICE:数据从内存传输到设备(clean)
- DMA_FROM_DEVICE: 数据从设备传输到内存(invalid)
- DMA_NONE 调试用途,传输方向初始化时可以设为此值
流式DMA有2种映射,一种是映射单个内存区域,一种是分散/聚集映射(映射一个scatterlist)。
映射单个内存区域的接口有:
-
dma_{map,unmap}_single:不能映射高端地址,基于 va 映射
dma_map_single(dev, addr, size, dir) dev:设备 addr:虚拟地址 size:大小 dir:方向 返回值:返回io地址 dma_map_single(dev, dma, size, direction) -
dma_{map,unmap}_page:单页流式映射,解决上面不能映射高端地址的缺点,基于page映射
dma_map_page(dev, page, offset, size, direction) 参数基本同 dma_map_single,只是基于page映射 dma_unmap_page(dev, dma, size, direction);
映射scatterlist的接口有:映射分散表的第一步是建立并填充一个描述被传输缓冲区的scatterlist结构的数组。
头文件<linux/scatterlist.h>
scatterlist结构的成员:
struct page *page;
unsigned int length;
unsigned int offset;
dma_{map,unmap}_sg:将几个连续的sglist条目合并成一个
dma_map_sg(dev, sglist, nents, direction);
dma_unmap_sg(dev, sglist, nents, direction);
dev:设备
sglist:散列表指针
nents为sglist的条目数量。
direction:方向
返回值:返回真正映射的sg条目数量。返回零表示失败。
获取对应的物理地址,可以使用sg_dma_address和
sg_dma_len来获取sg的物理地址和长度
同步接口:
dma_sync_{single, sg}_for_cpu:cpu收到DMA传输完的数据后,执行
dma_map_single(dev, buffer, len, DMA_FROM_DEVICE);
//读取数据前
dma_sync_single_for_cpu(dev, buffer, len, DMA_FROM_DEVICE);
dma_sync_{single, sg}_for_device:cpu发送完数据后,同步到设备
dma_map_single(dev, buffer, len, DMA_TO_DEVICE);
//发送数据前
dma_sync_single_for_cpu(dev, buffer, len, DMA_TO_DEVICE);
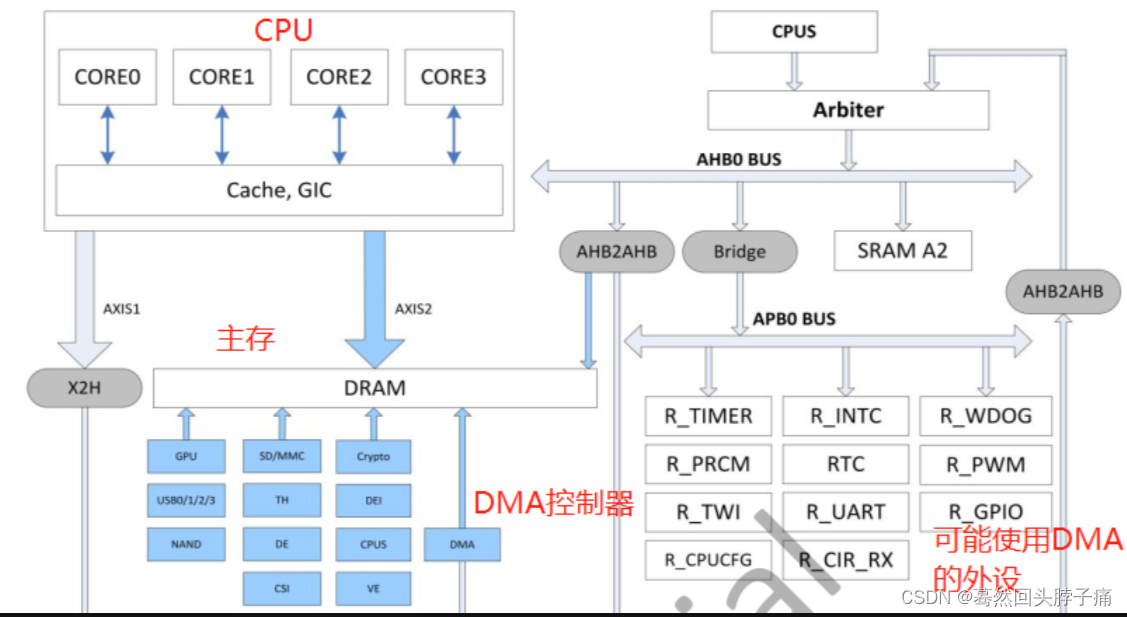
CMA连续内存分配
在内存初始化时预留一块连续内存,可以在内存碎片化严重时通过调用dma_alloc_contiguous接口并且gfp指定为__GFP_DIRECT_RECLAIM从预留的那块连续内存中分配大块连续内存。
CMA是内存管理子系统中的一个模块,负责物理地址连续的内存分配。一般系统会在启动过程中,从整个memory中配置一段连续内存用于CMA,然后内核其他的模块可以通过CMA的接口API进行连续内存的分配。
其底层还是依赖内核伙伴系统的内存管理机制,或者说CMA是处于需要连续内存块的其他内核模块(例如DMA mapping framework)和内存管理模块之间的一个中间层模块,主要功能包括:
- 解析DTS或者命令行中的参数,确定CMA内存的区域,这样的区域我们定义为CMA area。
- 提供cma_alloc和cma_release两个接口函数用于分配和释放CMA pages。
- 记录和跟踪CMA area中各个pages的状态。
- 调用伙伴系统接口,进行真正的内存分配。
优势:由操作系统来管理的,当一个驱动模块想要申请大块连续内存时,通过内存管理子系统把CMA区域的内存进行迁移,空出连续内存给驱动使用;而当驱动模块释放这块连续内存后,它又被归还给操作系统管理,可以给其他申请者分配使用。
5. 开机时,系统预留出 CMA 区域。
6. 在 CMA 业务不使用时,允许其他业务有条件地使用 CMA 区域,条件是申请页面的属性必须是可迁移的。
7. 当 CMA 业务使用时,把其他业务的页面迁移出 CMA 区域,以满足 CMA 业务的需求。
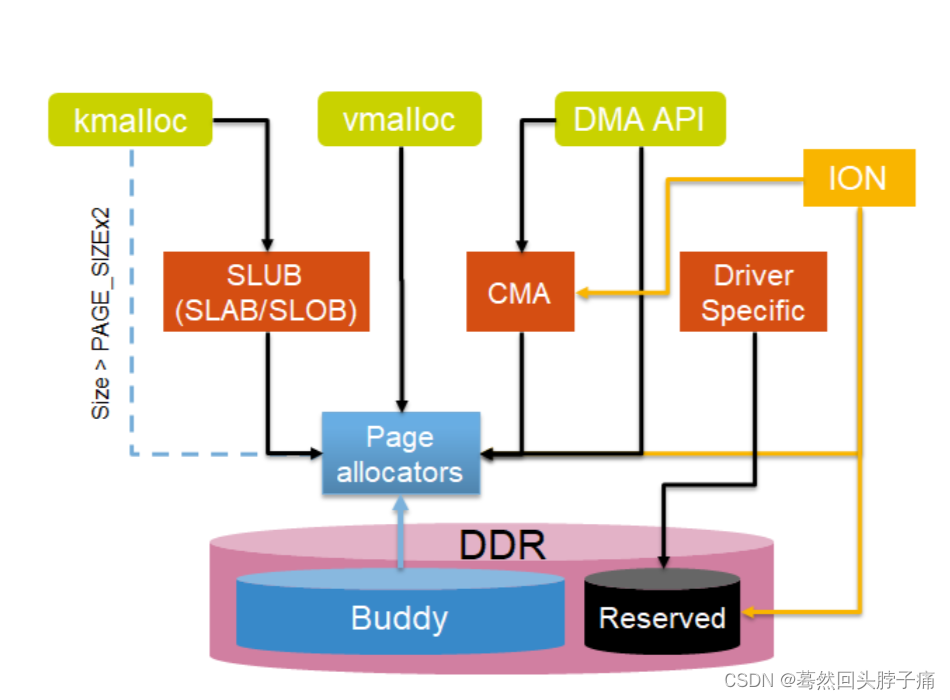
CMA数据结构
struct cma结构,用于管理一个CMA区域,此外还定义了全局的cma数组:
//头文件mm/cma.h
struct cma {
unsigned long base_pfn;
unsigned long count;
unsigned long *bitmap;
unsigned int order_per_bit; /* Order of pages represented by one bit */
struct mutex lock;
#ifdef CONFIG_CMA_DEBUGFS
struct hlist_head mem_head;
spinlock_t mem_head_lock;
#endif
const char *name;
};
extern struct cma cma_areas[MAX_CMA_AREAS];
extern unsigned cma_area_count;
base_pfn:CMA区域物理地址的起始页帧号;
count:CMA区域总体的页数。count成员说明了该cma area内存有多少个page。它和order_per_bit一起决定了bitmap指针指向内存的大小。
*bitmap:位图,用于描述页的分配情况。0表示free,1表示已经分配。
order_per_bit:位图中每个bit描述的物理页面的order值,其中页面数为2^order值。具体内存管理的单位和struct cma中的order_per_bit成员相关,如果order_per_bit等于0,表示按照一个一个page来分配和释放,如果order_per_bit等于1,表示按照2个page组成的block来分配和释放,以此类推。
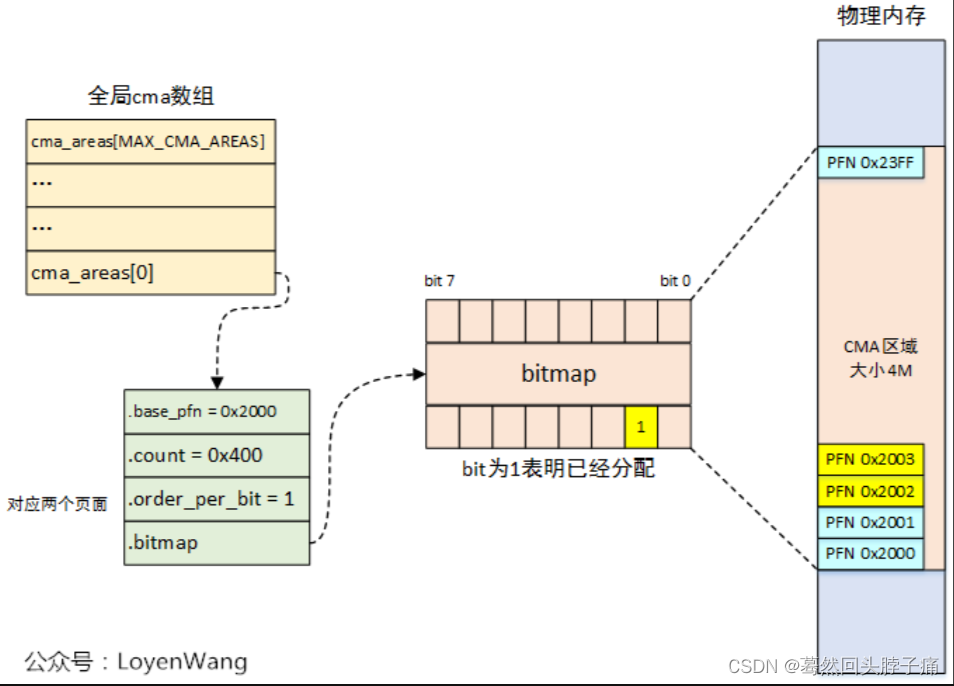
CMA区域创建
1. 命令行或者内核参数配置
通过命令行参数也可以建立cma area。使用CMA,还需要在内核启动阶段预留CMA内存。在Linux内核在启动时,会根据启动参数预留CMA内存,cma内存预留的参数的格式如下:
cma=nn[MG]@[start[MG][-end[MG]]] [ARM,X86,KNL]
Sets the size of kernel global memory area for
contiguous memory allocations and optionally the
placement constraint by the physical address range of
memory allocations. A value of 0 disables CMA
altogether. For more information, see
include/linux/dma-contiguous.h
这样命令行参数来指明Global CMA area在整个物理内存中的位置。在初始化过程中,内核会解析这些命令行参数,获取CMA area的位置(起始地址,大小),并调用cma_declare_contiguous接口函数向CMA模块进行注册(当然,和device tree传参类似,最终也是调用cma_init_reserved_mem接口函数)。
使用CMA功能,需要在内核编译时开启DMA_CMA选项,确认运行内核是否支持该选项可以使用下面的命令。
# cat /boot/config-$(uname -r) | grep DMA_CMA
如果有如下输出,则表示运行内核支持DMA_CMA选项。否则表示不支持,需要重新配置内核并编译内核。
CONFIG_DMA_CMA=y
检查CMA是否预留成功,可以执行下面的命令:
root@tronlong-virtual-machine: cat /proc/meminfo | grep Cma
CmaTotal: 1048576 kB
CmaFree: 1048576 kB
除了命令行参数,通过内核配置(CMA_SIZE_MBYTES和CMA_SIZE_PERCENTAGE)也可以确定CMA area的参数。
通过内核参数或配置宏,来进行CMA区域的创建,最终会调用到cma_declare_contiguous函数:
缺点:CMA area的概念是全局的,通过内核配置参数和命令行参数,内核可以定位到Global CMA area在内存中的起始地址和大小,并在初始化的时候,调用dma_contiguous_reserve函数,将指定的memory region保留给Global CMA area使用,有些驱动不愿意和其他驱动共享CMA,因此出现两种CMA area:Global CMA area给大家共享,而Per Device CMA可以给指定的一个或者几个驱动使用。这时候,命令行参数不是那么合适了,因此引入了device tree中的reserved memory node的概念。
2. 从dts来配置
物理内存的描述放置在dts中,最终会在系统启动过程中,对dtb文件进行解析,从而完成内存信息注册。
① device_tree中建立通用global cma area
// 源码:arch/arm/boot/dts/sun4i-a10.dtsi
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
/* Address must be kept in the lower 256 MiBs of DRAM for VE. */
default-pool {
compatible = "shared-dma-pool";
size = <0x6000000>;
alloc-ranges = <0x40000000 0x10000000>;
reusable;
linux,cma-default;
};
};
对于CMA区域的dts配置来说,有三个关键点:
- 一定要包含有reusable,表示当前的内存区域除了被dma使用之外,还可以被内存管理子系统reuse。
- 不能包含有no-map属性,该属性表示是否需要创建页表映射,对于通用的内存,必须要创建映射才可以使用,而CMA是可以作为通用内存进行分配使用的,因此必须要创建页表映射。
- 对于共享的CMA区域,需要配置上linux,cma-default属性,标志着它是共享的CMA。
② device_tree建立per device area
//源码:arch/arm/boot/dts/stm32mp157a-dk1.dts
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
.......
gpu_reserved: gpu@d4000000 {
reg = <0xd4000000 0x4000000>;
no-map;
};
};
先在reserved memory中定义专用的CMA区域,注意这里和上面共享的主要区别就是在专用CMA区域中是不包含 linux,cma-default; 属性的。
外设使用专用cma域示例:
//源码:arch/arm/boot/dts/stm32mp157a-dk1.dts
&gpu {
contiguous-area = <&gpu_reserved>;
status = "okay";
};
CMA内存初始化流程
确定整个系统的的内存布局,简单说就是了解整个memory的分布情况,哪些是memory block是memory type,哪些memory block是reserved type。毫无疑问,CMA area对应的当然是reserved type。
1. memory type内存块的建立
start_kernel
------>setup_arch
------>setup_machine_fdt
------>early_init_dt_scan_nodes
------>of_scan_flat_dt
------>early_init_dt_scan_memory
------>early_init_dt_add_memory_arch
------>memblock_add
2. 建立reserved type的memory block
start_kernel
------>setup_arch
------>arm_memblock_init
------>early_init_fdt_scan_reserved_mem
------>of_scan_flat_dt
------> __fdt_scan_reserved_mem
------> fdt_init_reserved_mem
------> memblock_add
3. 初始化reserved memory
start_kernel
------>setup_arch
------>arm_memblock_init
------>early_init_fdt_scan_reserved_mem
------>fdt_init_reserved_mem
------>__reserved_mem_init_node
为 DTS 中的预留区分配内存。 DTS 中预留区分做两类,一类是 DTB 本身需要预留的区域,另一类是 “/reserved-memory” 节点中描述的预留区。在后者中,预留区分配需要的内存之后,还会将这些预留区加入到 CMA 或 DMA 中。
__reserved_mem_init_node函数中会调用 rmem_cma_setup() 函数,该函数用于将全局 reserved-mem[] 数组的区域加入到 CMA 分配器中,即添加一块新的 CMA 区域。在该函数内,涉及从 MEMBLOCK 分配物理内存和加入新的CMA 区域,也包含了设置 CMA 分配器使用的默认分配区。rmem_cma_setup函数:
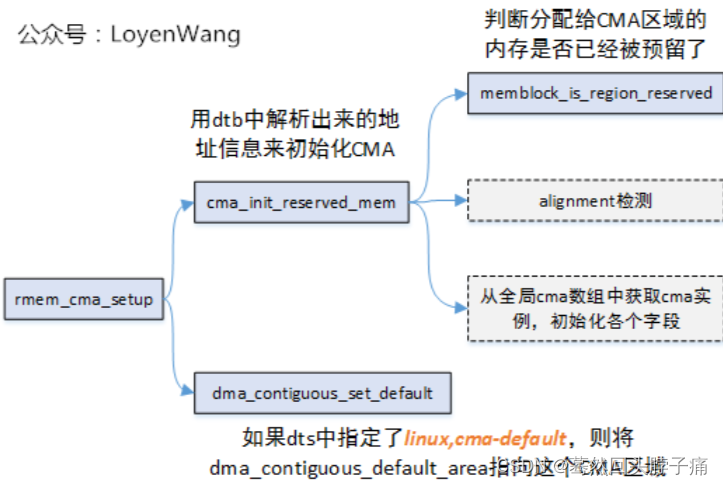
4. reserved-memory添加到cma子系统
rmem_cma_setup
|------>cma_init_reserved_mem // 将reserved-memory 添加到cma_areas数组中
|------>dma_contiguous_early_fixup// dma remap
|------>dma_contiguous_set_default// set_default cma area
页表与物理页初始化
构建完 CMA 区域之后,CMA 需要将每个 CMA 区域的页表进行映射,以及将 CMA 区域内的物理页进行初始化。该阶段初始化完毕之后还不能使用 CMA 分配器。dma_contiguous_remap该函数用于创建映射关系。
start_kernel
------>setup_arch
------>paging_init
------>dma_contiguous_remap
CMA分配器的激活
对 CMA 进行激活初始化,激活之后 CMA 就可用供其他模块、设备和子系统使用。cma_activate_area函数用于将CMA区域内的预留页全部释放添加到Buddy管理器内,然后激活CMA区域供系统使用。此函数将cma结构体剩余成员的初始化。
//源码:mm/cma.c
static int __init cma_init_reserved_areas(void)
{
int i;
for (i = 0; i < cma_area_count; i++)
cma_activate_area(&cma_areas[i]);
return 0;
}
core_initcall(cma_init_reserved_areas);
core_initcall宏将cma_init_reserved_areas函数放置到特定的段中,在系统启动的时候会调用到该函数。
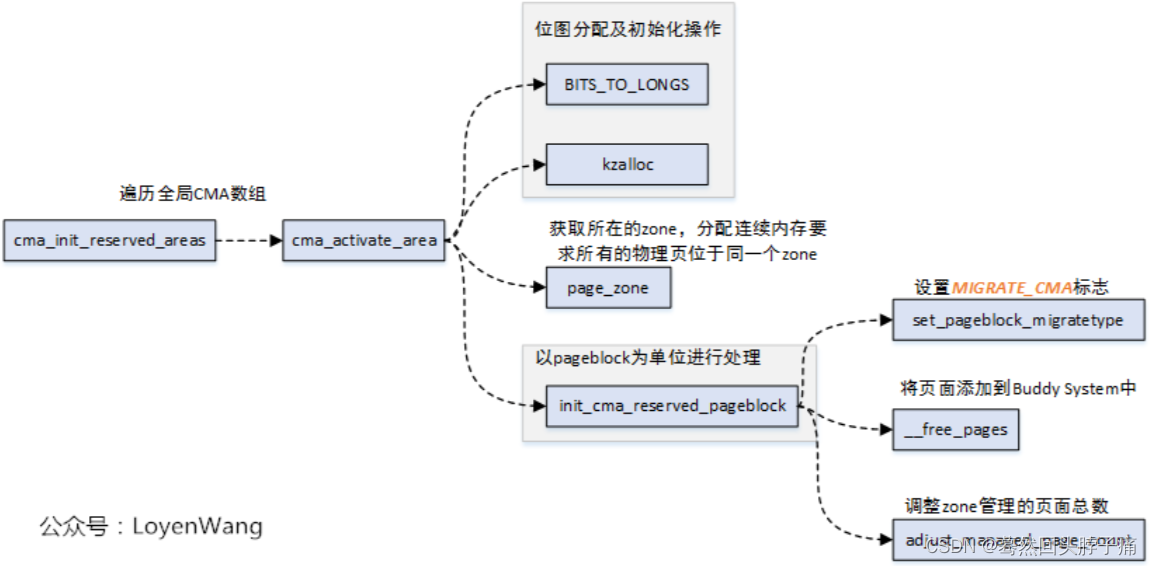
cma默认是从reserved memory中分配的,通常情况这块内存是直接分配并预留不做任何使用,无形之中造成了浪费。所以在不用的时候放入伙伴系统,作为普通内存使用。
分配器使用
CMA 激活之后,内核可以使用 CMA API 就可以使用连续物理内存。
分配 CMA 里面的连续物理内存,可以使用dma_alloc_from_contiguous:
// 源码:kernel/dma/contiguous.c
/**
* dma_alloc_from_contiguous() - allocate pages from contiguous area
* @dev: Pointer to device for which the allocation is performed.
* @count: Requested number of pages.
* @align: Requested alignment of pages (in PAGE_SIZE order).
* @no_warn: Avoid printing message about failed allocation.
*
* This function allocates memory buffer for specified device. It uses
* device specific contiguous memory area if available or the default
* global one. Requires architecture specific dev_get_cma_area() helper
* function.
*/
/*
* 指针dev 指向需要分配CMA的设备,
* 参数 count 指明需要分配的page数,
* align 参数 指明对齐的方式,align = CONFIG_CMA_ALIGNMENT;
* no_warn 控制警告消息的打印。
*/
struct page *dma_alloc_from_contiguous(struct device *dev, size_t count,
unsigned int align, bool no_warn)
{
if (align > CONFIG_CMA_ALIGNMENT)
align = CONFIG_CMA_ALIGNMENT;
return cma_alloc(dev_get_cma_area(dev), count, align, no_warn);
}
cma_alloc函数解析:
当使用完 CMA 连续物理内存之后,可以通过dma_release_from_contiguous将物理内存归还给 CMA 内存管理器:
//源码:kernel/dma/contiguous.c
/**
* dma_release_from_contiguous() - release allocated pages
* @dev: Pointer to device for which the pages were allocated.
* @pages: Allocated pages.
* @count: Number of allocated pages.
*
* This function releases memory allocated by dma_alloc_from_contiguous().
* It returns false when provided pages do not belong to contiguous area
* and true otherwise.
*/
/*
* 参数 dev 指向一个设备,
* pages 指向连续物理内存的起始页,
* 参数 count 表示分配的page数
*/
bool dma_release_from_contiguous(struct device *dev,
struct page *pages,int count)
{
return cma_release(dev_get_cma_area(dev), pages, count);
}
其他CMA操作API:
struct page *dma_alloc_contiguous(struct device *dev, size_t size,
gfp_t gfp);
void dma_free_contiguous(struct device *dev, struct page *page,
size_t size);
实例:
驱动代码
驱动模块中申请一片512M的连续内存,一个page是4k字节,要申请512M内存,count就是0x20000:
#include <linux/dma-contiguous.h>
#include <linux/cma.h>
struct page *p = NULL;
p = cma_alloc(dma_contiguous_default_area, 0x20000, (1<<PAGE_SHIFT));
//align参数表示申请的内存以多大块对齐。
得到的是连续内存的第一个page的实例指针,如果要使用这个内存就将page转换成虚拟地址:
unsigned char *buf = NULL;
buf = page_to_virt(p);
释放内存:
cma_release(dma_contiguous_default_area, p, (1<<PAGE_SHIFT));
编译加载模块
使用make进行模块编译,成功编译出内核模块ko文件,但在编译中提示了Warning:
# make
WARNING: "cma_release" [/root/cma_test/cmatest.ko] undefined!
WARNING: "dma_contiguous_default_area" [/root/cma_test/cmatest.ko] undefined!
WARNING: "cma_alloc" [/root/cma_test/cmatest.ko] undefined!
三个警告就是我们使用的CMA的接口,没有定义是会影响模块加载:
# insmod cmatest.ko
insmod: ERROR: could not insert module cmatest.ko: Unknown symbol in module
发现CMA的接口和dma_contiguous_default_area指针,都没有做符号导出(EXPORT_SYMBOL),是不能在内核之外被使用的,只有编译到内核中的代码可以调用。那么是否表示单独的内核模块ko无法使用CMA内存呢?当然我们可以修改内核,将这三个符号导出再使用,但是这样使用并不灵活。我们采用直接引用内核符号表的方式来解决。
内核符号表
CMA功能默认只提供给内核中的函数调用,CMA的相关接口没有做符号导出(EXPORT_SYMBOL),启动后加载的内核模块要使用CMA功能需要获取对应的接口的符号地址。
cma测试模块需要如下三个内核符号的地址:
- dma_contiguous_default_area: DMA_CMA管理结构体指针;
- cma_alloc: cma内存分配函数地址;
- cma_release: cma内存释放函数地址;
可以在/proc/kallsyms中获取这三个符号地址。
# cat /proc/kallsyms | grep dma_contiguous_default_area
得到运行系统中的dma_contiguous_default_area符号地址:
ffffffff9445ba58 B dma_contiguous_default_area
前面的数值既是符号的地址,同样的方法可以获取:cma_alloc和cma_release的符号地址。
注意: 每次系统重启,这些符号的地址可能会发生变化。
调整后的驱动代码
- 去掉内核头文件
- #include <linux/dma-contiguous.h>
- #include <linux/cma.h>
struct page *p = NULL;
- 添加模块参数,用于接收符号地址
static unsigned long area_base = 0;
module_param(area_base, ulong, 0600);
static unsigned long alloc_fn = 0;
module_param(alloc_fn, ulong, 0600);
static unsigned long free_fn = 0;
module_param(free_fn, ulong, 0600);
- 添加函数指针和cma实例指针
typedef struct page *(*cma_alloc_t)(struct cma *, size_t, unsigned int);
typedef bool (*cma_release_t)(struct cma *, const struct page *, unsigned int);
cma_alloc_t cma_alloc=NULL;
cma_release_t cma_release=NULL;
struct cma * dma_cma_p = NULL;
- 用模块参数初始化函数指针和cma实例指针
cma_alloc = (cma_alloc_t)alloc_fn;
cma_release = (cma_release_t)free_fn;
dma_cma_p = (struct cma *)(*(unsigned long *)area_base);
- 修改cma申请和释放调用
p = cma_alloc(dma_cma_p, 0x20000, (1<<PAGE_SHIFT));
cma_release(dma_cma_p, p, 0x20000);
重新加载模块
修改cma测试模块后编译,重新带参数的加载模块:
# insmod cmatest.ko area_base=0xffffffff9445ba58 alloc_fn=0xffffffff9a255140 free_fn=0xffffffff9a255350
CMA部署
获得系统物理内存的范围
cat /proc/iomem
root@tronlong-virtual-machine:/home/tronlong# cat /proc/iomem
00000000-00000fff : reserved
00001000-0009e7ff : System RAM
0009e800-0009ffff : reserved
000a0000-000bffff : PCI Bus 0000:00
000c0000-000c7fff : Video ROM
000ca000-000cafff : Adapter ROM
000cb000-000ccfff : Adapter ROM
000d0000-000d3fff : PCI Bus 0000:00
000d4000-000d7fff : PCI Bus 0000:00
000d8000-000dbfff : PCI Bus 0000:00
000dc000-000fffff : reserved
000f0000-000fffff : System ROM
00100000-bfecffff : System RAM
01000000-017bbc4b : Kernel code
017bbc4c-01d2537f : Kernel data
“System RAM”代表系统物理内存的起始物理地址和终止物理地址,分配的cma区域不能超过这段范围。
查看当前系统的预留区
cat /sys/kernel/debug/memblock/reserved
通过这个命令可以知道系统已预留的内存信息,这些已预留的内存信息不可使用。但排除这些预留区域,再在RAM范围内找出可用内存,再满足对其需求就可以自己手动找出可用于CMA的区域。
DTS中说明cma信息
dts方式部署cma的好处是既可以指定起始地址和长度,还可以命名该cma。
// 源码:arch/arm/boot/dts/sun4i-a10.dtsi
reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
/* Address must be kept in the lower 256 MiBs of DRAM for VE. */
default-pool {
compatible = "shared-dma-pool";
size = <0x6000000>;
alloc-ranges = <0x40000000 0x10000000>;
reusable;
linux,cma-default;
};
};














 4873
4873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









