







Linux内核源码分析 (A.5)多处理器调度
文章目录
注:本章节使用的内核版本为Linux 5.6.18
一、 SMT和NUMA
1、SMP (对称多处理器结构)
- 对称多处理器结构(
symmetrical mulit-processing,SMP),在对称多处理器系统中,所有处理器的地位都是平等的,所有的CPU共享全部资源,比如内存、总线、中断及I/O系统等等,都具有相同的可访问性,消除结构上的障碍,最大特点就是共享所有资源。
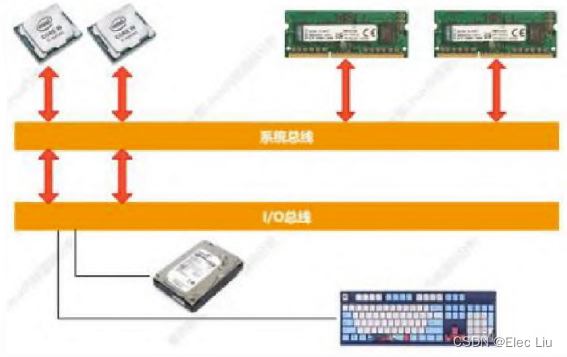
- 在多处理器系统当中,内核必须考虑几个问题,以确保良好的调度。
- CPU负荷必须尽可能公平地在所有的处理器上共享。
- 进程与系统中某些处理器的亲合性(affinity)必须是可设置的。
- 内核必须能够将进程从CPU迁移到另一个。
- Linux
SMP调度就是将进程安排/迁移到合适的CPU中去,保持各CPU负载均衡的过程。
2、NUMA (非一致内存访问结构)
- NUMA为是多处理器计算机,系统各个CPU都有本地内存,可以支持超快的访问能力,各个处理器之间通过总线连接起来,支持对其他CPU的本地内存访问。.在NUMA体系结构中,当CPU访问与它同在一个节点中的“本地” RAM芯片时,几乎没有竞争,因此访问通常是非常快的。另一方面,访问其所属节点外的“远程” RAM芯片就非常慢。

二、多核调度
-
SMP 是多核处理器最常见的,主要是将一个计算机上集中一组处理器,各处理器是对等及其系统总线和内存子系统。SMP 架构如下图所示。

-
根据处理器实际物理属性,CPU 域可分为超线程、多核。
- 超线程(SMT):Linux 内核分类
CONFIG_SCHED_SMT;超线程芯片是一个立刻执行几个执行线程的微处理器,它包括几个内部寄存器的拷贝,并快速在它们之间切换。这种由Intel发明的技术,使得当前线程在访问内存的间隙,处理器可以使用它的机器周期去执行另外一个线程。一个超线程的物理CPU可以被Linux看作几个不同的逻辑CPU。 - 多核(MC):Linux 内核分类
CONFIG_SCHED_MC。
- 超线程(SMT):Linux 内核分类
-
Linux 内核对 CPU 管理主要是通过
bitmap进行实现,并且定义四种状态:possible、online、active及present。具体如下:
include/linux/<cpumask.h>extern struct cpumask __cpu_possible_mask; extern struct cpumask __cpu_online_mask; extern struct cpumask __cpu_present_mask; extern struct cpumask __cpu_active_mask; /*表示系统当中有多少个可以执行的CPU核心*/ #define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask) /*表示系统当中有多少个处于运行状态的CPU核心*/ #define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask) /*表示系统当中有多少个具备online条件,它们不一定都处于online,有的CPU核心可能被热插拔*/ #define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask) /*表示系统当中有多少个活跃的核心*/ #define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)
三、调度域和调度组
- Linux 内核将同一个级别的 CPU 归纳为一个调度组,然后把同一个级别的所有调度组归纳为一个调度域。处理器有一个基本的调度域,它是硬件线程调度域,向上依次是核调度域、处理器调度域和 NUMA 节点调度域。具体案例分析如下:
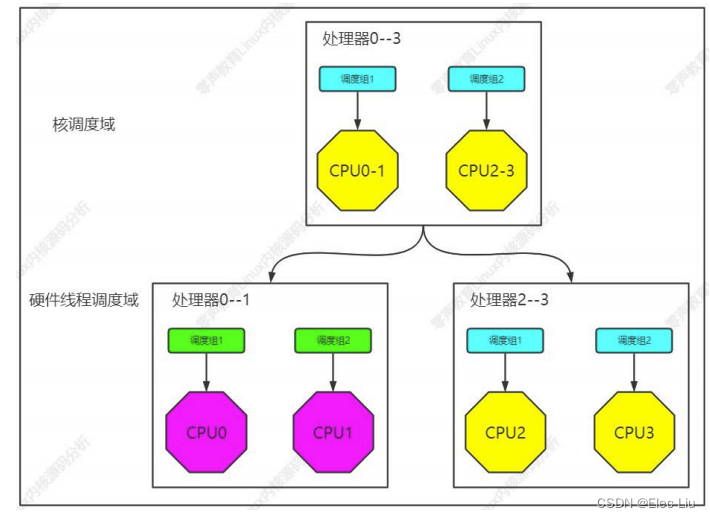
- 再举一个例子:2路4核8核心CPU,它们的CPU调度域逻辑分析
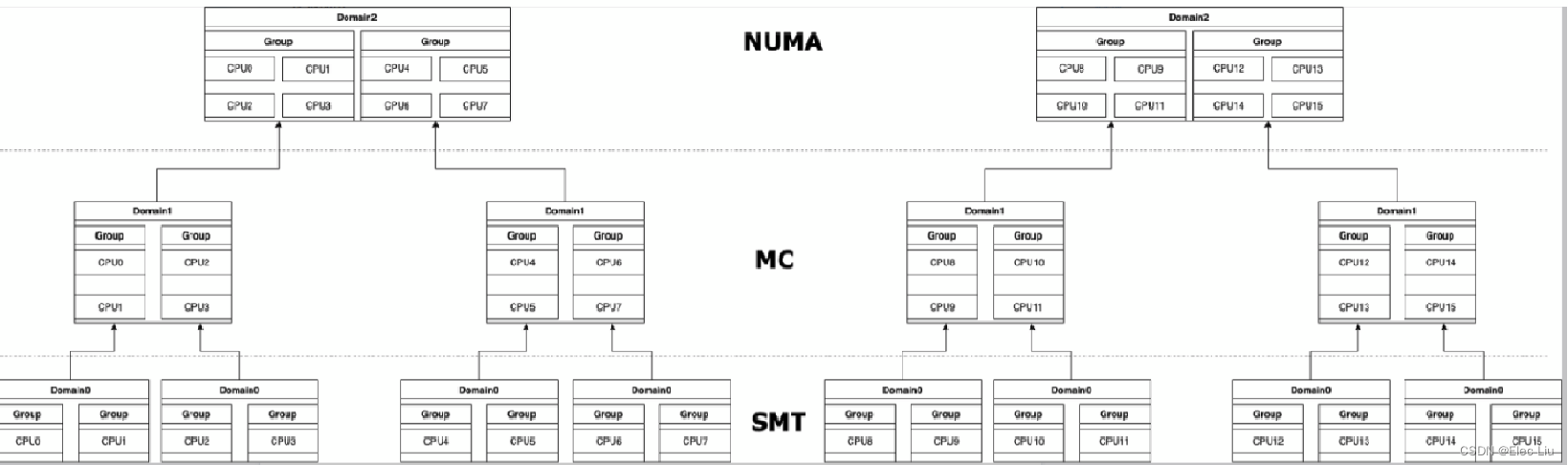
- 所有CPU一共分成三个层次:
SMT、MC、NUMA,每层都包含所有CPU,但是划分粒度不同。根据Cache和内存的相关性划分调度域,调度域内的CPU又划分一次调度组。越往下层调度域越小,越上层调度域越大。进程负载均衡会尽可以在底层调度域内部解决,这样Cache利用率最优。
- 所有CPU一共分成三个层次:
- 补充:核(
core)和硬件线程:- 核(
core):一个处理器包含多个核,每个核有独立的一级缓存,所有核共享二级缓存。(注意与核心的差别) - 硬件线程:也可以叫做虚拟处理器(或者叫做逻辑处理器),一个处理器或者核包含多个硬件线程,硬件线程共享一级缓存和二级缓存。
- 核(
四、SMP调度详解
- 周期性负载均衡:CPU对应的运行队列数据结构中记录下一次周期性负载均衡的时间,当超过这个时间点后,将触发
SCHED_SOFFIRQ软中断来进行负载均衡。scheduler_tick()==>triggerJoad_balance()。 - 用到SMP负载均衡模型的时机:
- 内核运行中,还有部分情况中需要用SMP负载均衡模型来确定最佳运行CPU:
- 进程A唤醒进程B时,
try_to_wake_up()中会考虑进程B将在那个CPU上运行; - 进程调用
execve()系统调用时 fork出子进程,子进程第一次被调度运行。
- 进程A唤醒进程B时,
- 内核运行中,还有部分情况中需要用SMP负载均衡模型来确定最佳运行CPU:
1、进程的处理器亲和性
-
设置进程的处理器亲和性,简单来讲,就是把进程绑定到某些处理器,只允许进程在某些处理器上执行,默认情况是进程可以在所有处理器上执行。
-
进程描述符增加两个成员,具体内核源码如下:
struct task_struct { ... int nr_cpus_allowed; cpumask_t cpus_mask; ... }
2、限期调度类的处理器负载均衡
- 调度器选择下一个限期进程的时候,如果当前正在执行的进程是限期进程,将会试图从限期进程超载的处理器把限期进程拉过来。
- 限期进程超载:限期运行队列至少有两个限期进程;至少有一个限期进程绑定到多个处理器。
- 具体内核源码分析如下:
static void pull_dl_task(struct rq *this_rq){ ... }
3、实时调度类的处理器负载均衡
- 调度器选择下一个实时进程时,如果当前处理器的实时运行队列中的进程的最高调度优先级比当前正在执行的进程的调度优先级低,将会试图从实时进程超载的处理器把可推送实时进程拉过来。
- 实时进程超载:实时运行队列至少有两个实时进程;至少有一个可推送的实时进程。
- 具体内核源码分析如下:
static void pull_rt_task(struct rq *this_rq){ ... }
















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











