







cudaDeviceProp数据结构
cudaDeviceProp数据类型针对函式cudaGetDeviceProperties定义的,cudaGetDeviceProperties函数的功能是取得支持GPU计算装置的相关属性,比如支持CUDA版本号装置的名称、内存的大小、最大的thread数目、执行单元的频率等。如下所示:
struct cudaDeviceProp {
char name[256]; // 识别设备的ASCII字符串(比如,"GeForce GTX 940M")
size_t totalGlobalMem; // 全局内存大小
size_t sharedMemPerBlock; // 每个block内共享内存的大小
int regsPerBlock; // 每个block 32位寄存器的个数
int warpSize; // warp大小
size_t memPitch; // 内存中允许的最大间距字节数
int maxThreadsPerBlock; // 每个Block中最大的线程数是多少
int maxThreadsDim[3]; // 一个块中每个维度的最大线程数
int maxGridSize[3]; // 一个网格的每个维度的块数量
size_t totalConstMem; // 可用恒定内存量
int major; // 该设备计算能力的主要修订版号
int minor; // 设备计算能力的小修订版本号
int clockRate; // 时钟速率
size_t textureAlignment; // 该设备对纹理对齐的要求
int deviceOverlap; // 一个布尔值,表示该装置是否能够同时进行cudamemcpy()和内核执行
int multiProcessorCount; // 设备上的处理器的数量
int kernelExecTimeoutEnabled; // 一个布尔值,该值表示在该设备上执行的内核是否有运行时的限制
int integrated; // 返回一个布尔值,表示设备是否是一个集成的GPU(即部分的芯片组、没有独立显卡等)
int canMapHostMemory; // 表示设备是否可以映射到CUDA设备主机内存地址空间的布尔值
int computeMode; // 一个值,该值表示该设备的计算模式:默认值,专有的,或禁止的
int maxTexture1D; // 一维纹理内存最大值
int maxTexture2D[2]; // 二维纹理内存最大值
int maxTexture3D[3]; // 三维纹理内存最大值
int maxTexture2DArray[3]; // 二维纹理阵列支持的最大尺寸
int concurrentKernels; // 一个布尔值,该值表示该设备是否支持在同一上下文中同时执行多个内核
}
cudnnConvolutionForward()
此函数使用张量w指定的过滤器在张量x上执行卷积或互相关,并以张量y返回结果。
缩放因子α和β可分别用于缩放输入张量和输出张量。
cudnnStatus_t cudnnConvolutionForward(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionFwdAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)cudnnStatus_t,CuDNN 的接口一般采用在参数里包含输出指针(比如这里的 y)进行结果写入的设计,而返回值只包含成功失败的状态信息,即 status。
cudnnHandle_t,handle 是与设备进行沟通的接口,类似的概念还有 file handle,直译为句柄,任何接口都需要提供一个 cuda device 的 handle。
cudnnTensorDescriptor_t 和 cudnnFilterDescriptor_t,都属于数据描述符,包含 layout、dtype 等所有数据属性信息,因为数据内容只由一个 void* 指针(比如这里的 x 和 w)提供。
cudnnConvolutionDescriptor_t,操作描述符,与数据描述符类似,用于描述 Op 本身的一些参数和属性,比如 conv 就包括 pad、stride、dilation 等。
cudnnConvolutionFwdAlgo_t,直译是前向卷积的算法,因为卷积操作的具体计算方式多种多样,各自有其适合的数据场景,所以需要在这里指定采用什么算法。
workSpace,相比于上层代码可以随时随地创建数据对象,在设备层,一个计算需要的空间必须事前声明,而 workspace 就是除了输入输出之外,进行这个计算所需的额外“工作空间”,也可以简单理解为空间复杂度。
cudnnConvolutionBackwardData()cudnnConvolutionBackwardData()cudnnConvolutionBackwardData()
这个函数同来的计算卷积结果的倒数dy,当y是cudnnConvolutionForward()的前向计算的结果时,使用是定算法,他会返回输出的结果的dx,这个alpha和beta用来的针对当前的数据进行对应的扩张处理
cudnnStatus_t cudnnConvolutionBackwardData(
cudnnHandle_t handle,
const void *alpha,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionBwdDataAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx)handle
Input . 用于处理有cudnn指定内容数据
alpha, beta
dstValue = alpha[0]*result + beta[0]*priorDstValue
wDesc
Input. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
w
Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
dyDesc
Input. Handle to the previously initialized input differential tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
dy
Input. Data pointer to GPU memory associated with the input differential tensor descriptor dyDesc.
convDesc
Input. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
algo
Input. Enumerant that specifies which backward data convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionBwdDataAlgo_t.
workSpace
Input . Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be NIL .
workSpaceSizeInBytes
Input. Specifies the size in bytes of the provided workSpace.
dxDesc
Input . Handle to the previously initialized output tensor descriptor.
dx
Input/Output . Data pointer to GPU memory associated with the output tensor descriptor dxDesc that carries the result.
cudnnConvolutionBackwardFilter()
此函数计算张量dy的卷积权重(滤波器)梯度,其中y是cudnnConvolutionForward()中的前向卷积的输出。它使用指定的算法,并在输出张量dw中返回结果。缩放因子alpha和beta可用于缩放计算结果或与当前dw累加。
cudnnStatus_t cudnnConvolutionBackwardFilter(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionBwdFilterAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnFilterDescriptor_t dwDesc,
void *dw)handle,输入。先前创建的cuDNN上下文的句柄。有关详细信息,请参阅cudnnHandle_t。
alpha,beta 输入。用于混合计算结果与输出层中的先前值的缩放因子(在主机内存中)的指针,如下所示:
dstValue = alpha[0]*result + beta[0]*priorDstValue
xDesc输入。先前初始化的张量描述符的句柄。有关详细信息,请参见cudnnTensorDescriptor_t。
x:指向与张量描述符xDesc相关的GPU内存的数据指针。
dyDesc:输入。先前初始化的输入微分张量描述符的句柄
convDesc:输入。以前初始化的卷积描述符。有关详细信息,请参阅.cudnnConvolutionDescriptor_t.
algo:输入。枚举,指定应使用哪个卷积算法来计算结果。有关详细信息,请参阅cudnn卷积BwdFilterAlgo_t。
workSpace:输入。GPU内存的数据指针指向能够执行指定算法所需的工作空间。如果特定算法不需要工作空间,则该指针可以是NIL。
workSpaceSizeInBytes:输入。指定所提供工作空间的大小(以字节为单位)。
dwDesc:输入。先前初始化的过滤器梯度描述符的句柄。有关详细信息,请参阅cudnnFilterDescriptor_t。
dw:输入/输出。数据指针指向与过滤器梯度描述符dwDesc相关联的GPU内存,该描述符携带结果
cudnnGetConvolutionForwardWorkspaceSize()
此函数返回用户需要分配的GPU内存工作空间的尺寸
cudnnStatus_t cudnnGetConvolutionForwardWorkspaceSize(
cudnnHandle_t handle,//输入量:前期创建的cuDNN句柄
const cudnnTensorDescriptor_t xDesc,//输入量:前期初始化好的x张量描述符
const cudnnFilterDescriptor_t wDesc,//输入量:前期初始化好的筛选器描述符
const cudnnConvolutionDescriptor_t convDesc,//输入量:前期初始化好的卷积描述符
const cudnnTensorDescriptor_t yDesc,//输入量:前期初始化好的y张量描述符
cudnnConvolutionFwdAlgo_t algo,//输入量:选择的枚举型卷积算法
size_t *sizeInBytes)//输出量:计算卷积所需的GPU工作空间尺寸
cudnnRNNForward()
此例程使用x、hx、cx中的输入以及weightSpace缓冲区中的权重/偏差计算rnnDesc描述的递归神经网络的正向推理。RNN输出写入y、hy和cy缓冲区。x、y、hx、cx、hy和cy信号在多层RNN模型中的位置如下图所示。注意,时间步长之间和层之间的内部RNN信号不暴露给用户。
cudnnStatus_t cudnnRNNForward(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
cudnnForwardMode_t fwdMode,
const int32_t devSeqLengths[],
cudnnRNNDataDescriptor_t xDesc,
const void *x,
cudnnRNNDataDescriptor_t yDesc,
void *y,
cudnnTensorDescriptor_t hDesc,
const void *hx,
void *hy,
cudnnTensorDescriptor_t cDesc,
const void *cx,
void *cy,
size_t weightSpaceSize,
const void *weightSpace,
size_t workSpaceSize,
void *workSpace,
size_t reserveSpaceSize,
void *reserveSpace);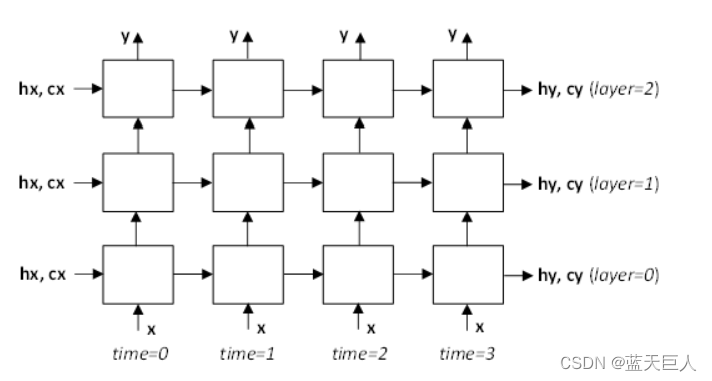
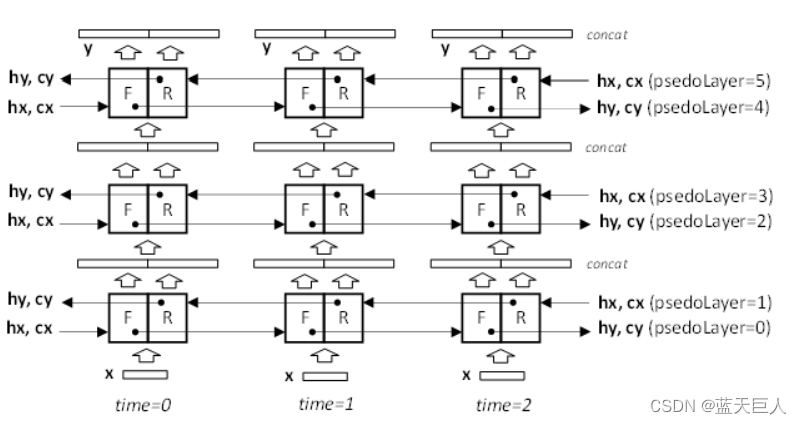
下图描述了RNN模型为双向时的数据流。在该模式中,每个RNN物理层包括两个连续的伪层,每个伪层具有其自己的权重、偏置、初始隐藏状态hx,并且对于LSTM,还具有初始小区状态cx。偶数伪层0、2、4从左到右或在前向(F)方向上处理输入矢量。奇数伪层1、3、5从右到左或在反(R)方向上处理输入矢量。两个连续的伪层对相同的输入向量进行操作,只是顺序不同。伪层0和1访问存储在x缓冲器中的原始序列。F和R单元的输出被级联,因此馈送到下两个伪层的向量具有2x hiddenSize或2x projSize的长度。后续伪层中的输入GEMM将向量长度调整为1x hiddenSize。
handle:输入。当前cuDNN上下文句柄。
rnnDesc:输入。先前初始化的RNN描述符。
fwdMode:输入。指定推理或训练模式(CUDNN_FWD_MODE_INFERENCE和CUDNN_FWD_MODE_TRAINING)。在训练模式中,附加数据被存储在保留空间缓冲器中。该信息在反向传递中用于计算导数。
devSeqLengths:输入。来自xDesc或yDesc RNN数据描述符的seqLengthArray的副本。devSeqLengths数组必须存储在GPU内存中,因为GPU内核可能会在cudnnRNNForward()函数存在之后异步访问该数组。此参数不能为NULL。
xDesc:输入。对应于RNN模型主输入的先前初始化的描述符。dataType、布局、maxSeqLength、batchSize和seqLengthArray必须与yDesc匹配。参数vectorSize必须与传递给cudnnSetRNNDescriptor_v8()函数的inputSize参数匹配。
x:输入。指向与RNN数据描述符xDesc关联的GPU内存的数据指针。向量应根据xDesc指定的布局在内存中排列。张量中的元素(包括填充向量)必须密集排列。
yDesc:输入。先前初始化的RNN数据描述符。dataType、布局、maxSeqLength、batchSize和seqLengthArray必须与xDesc匹配。参数vectorSize取决于是否启用了LSTM投影以及网络是否是双向的。具体而言:
对于单向模型,参数vectorSize必须与传递给cudnnSetRNNDescriptor_v8()的hiddenSize参数匹配。如果启用了LSTM投影,vectorSize必须与传递给cudnnSetRNNDescriptor_v8()的projSize参数相同。
对于双向模型,如果RNN cellMode为CUDNN_LSTM且投影功能已启用,则参数vectorSize必须是传递给cudnnSetRNNDescriptor_v8()的projSize参数的2倍。否则,该值应为hiddenSize值的2倍。
y:输出。指向与RNN数据描述符yDesc关联的GPU内存的数据指针。向量预期根据yDesc指定的布局在内存中布局。张量中的元素(包括填充向量中的元素)必须密集打包,并且不支持跨距。
hDesc:输入。描述RNN初始或最终隐态的张量描述子。隐藏状态数据已完全打包。张量的第一维取决于传递给cudnnSetRNNDescriptor_v8()函数的dirMode参数。
如果dirMode为CUDNN_UNIDIRECTIONAL,则第一个维度应与传递给cudnnSetRNNDescriptor_v8()的numLayers参数匹配。
如果dirMode为CUDNN_BIDIRECTIONAL,则第一个维度应为传递给cudnnSetRNNDescriptor_v8()的numLayers参数的两倍。
第二维必须与xDesc中描述的batchSize参数匹配。第三维取决于RNN模式是否为CUDNN_LSTM以及是否启用LSTM投影。具体而言:
如果RNN模式为CUDNN_LSTM且启用了LSTM投影,则第三个维度必须与传递给cudnnSetRNNProjectionLayers()调用的projSize参数匹配。
否则,第三个维度必须与传递给用于初始化rnnDesc的cudnnSetRNNDescriptor_v8()调用的hiddenSize参数匹配。
hx:输入。指向具有RNN初始隐藏状态的GPU缓冲区的指针。数据维度由hDesc张量描述符描述。如果传递NULL指针,则网络的初始隐藏状态将被初始化为零。
hy:输出。指向应该存储最终RNN隐藏状态的GPU缓冲区的指针。数据维度由hDesc张量描述符描述。如果传递了NULL指针,则不会保存网络的最终隐藏状态。
cDesc:输入。仅适用于LSTM网络。一种张量描述符,仅描述LSTM网络的初始或最终单元状态。单元状态数据被完全打包。张量的第一维取决于传递给cudnnSetRNNDescriptor_v8()调用的dirMode参数。
如果dirMode为CUDNN_UNIDIRECTIONAL,则第一个维度应与传递给cudnnSetRNNDescriptor_v8()的numLayers参数匹配。
如果dirMode为CUDNN_BIDIRECTIONAL,则第一个维度应匹配传递给cudnnSetRNNDescriptor_v8()的numLayers参数的两倍。
第二张量维度必须与xDesc中的batchSize参数匹配。第三维必须与传递给cudnnSetRNNDescriptor_v8()调用的hiddenSize参数匹配。
cx:输入。仅适用于LSTM网络。指针指向具有初始LSTM状态数据的GPU缓冲区。数据维度由cDesc张量描述符描述。如果传递NULL指针,则网络的初始小区状态将被初始化为零。
cy:输出。仅适用于LSTM网络。指向应存储最终LSTM状态数据的GPU缓冲区的指针。数据维度由cDesc张量描述符描述。如果传递NULL指针,则将不保存最终LSTM单元状态。
weightSpaceSize:输入。指定提供的权重空间缓冲区的大小(以字节为单位)。
weightSpace:输入。GPU内存中权重空间缓冲区的地址。
workSpaceSize:输入。指定提供的工作区缓冲区的大小(以字节为单位)。
workSpace:输入/输出。GPU内存中用于存储临时数据的工作区缓冲区地址。
reserveSpaceSize:输入。指定保留空间缓冲区的大小(以字节为单位)。
reserveSpace:输入/输出。GPU内存中保留空间缓冲区的地址。
cudnnActivationForward()
该例程对每个输入值应用指定的神经元激活函数元素级。
cudnnStatus_t cudnnActivationForward(
cudnnHandle_t handle,
cudnnActivationDescriptor_t activationDesc,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)本程序允许就地操作;意味着xData和yData指针可以相等。但是,这要求xDesc和yDesc描述符相同(特别是,输入和输出的步幅必须匹配,才允许就地操作)。
4维和5维支持所有张量格式,但是,当xDesc和yDesc的跨距相等且HW压缩时,可获得最佳性能。对于多于5维的张量,必须将它们的空间维数打包。
handle:输入。先前创建的cuDNN上下文的句柄。有关详细信息,请参阅cudnnHandle_t。
activationDesc:输入。激活描述符。有关详细信息,请参阅cudnnActivationDescriptor_t。
alpha, beta:输入。用于混合计算结果与输出层中的先前值的缩放因子(在主机内存中)的指针,如下所示:I
dstValue = alpha[0]*result + beta[0]*priorDstValue
xDesc:输入。先前初始化的输入张量描述符的句柄。有关详细信息,请参见cudnnTensorDescriptor_t。
x:输入。指向与张量描述符xDesc相关的GPU内存的数据指针。
yDesc:输出。先前初始化的输出张量描述符的句柄。有关详细信息,请参见cudnnTensorDescriptor_t。
y:输出。指向与输出张量描述符yDesc关联的GPU存储器的数据指针.















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









