







一、代码撰写目的
平时闲来无事总是不自觉的timi两把,但是有的时候对个别英雄实在是不了解,又懒得去商城翻找,于是我打开了英雄资料列表页-英雄介绍-王者荣耀官方网站-腾讯游戏王者荣耀官网,准备给里面的英雄数据一网打尽,方便在本地查阅。
一级页面
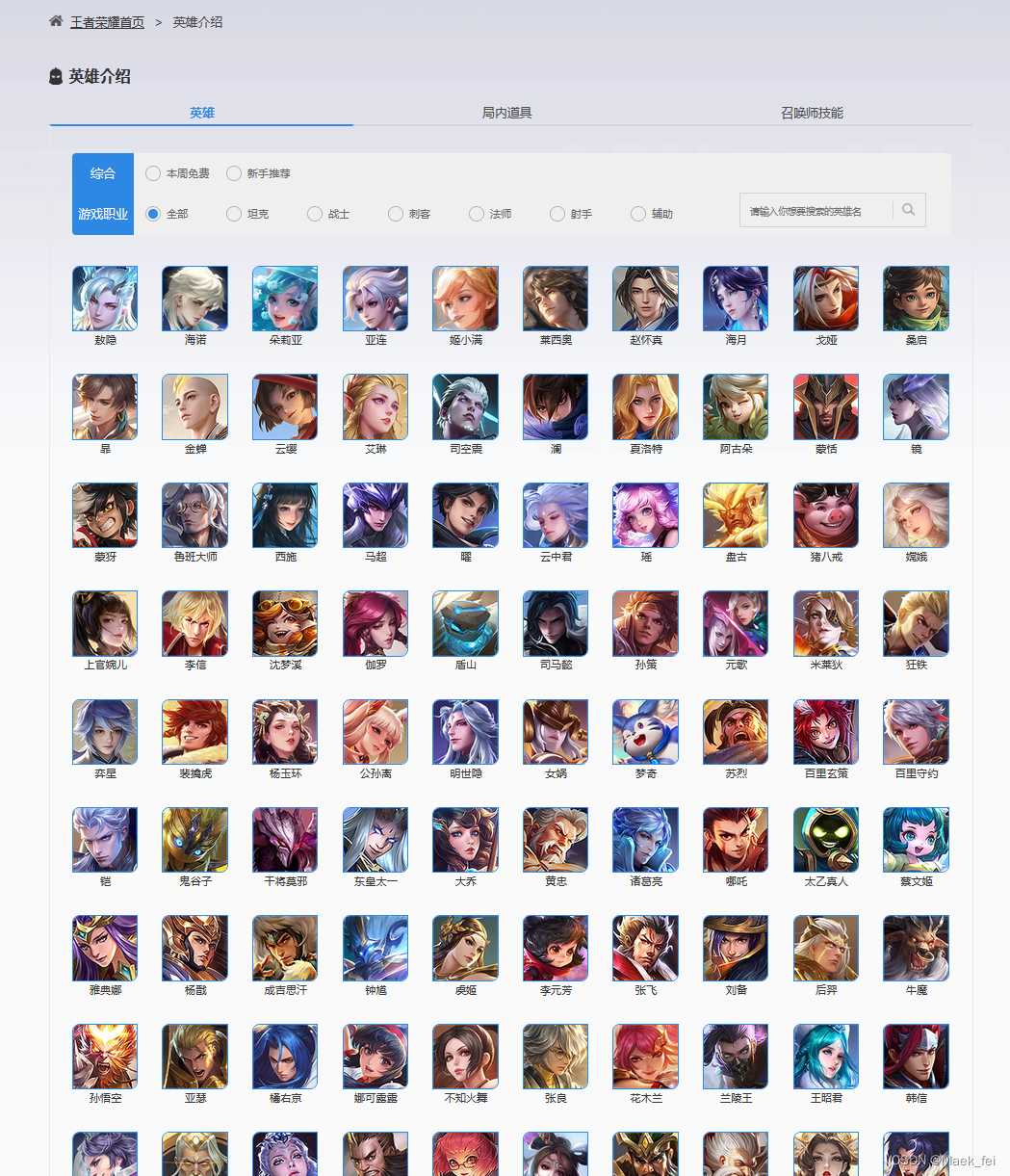
二级页面
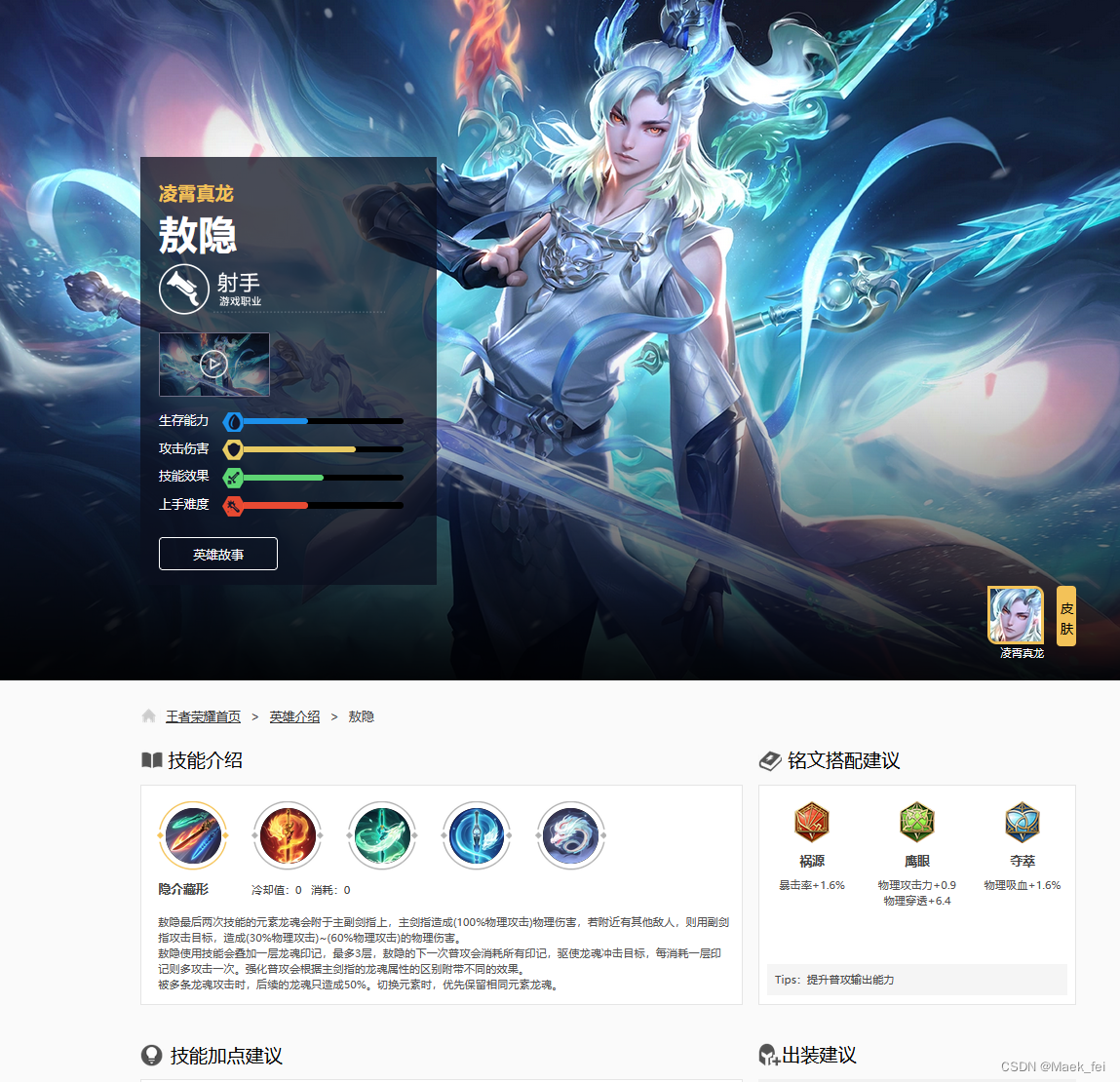
主要信息存储位置:
二级网页网址位置
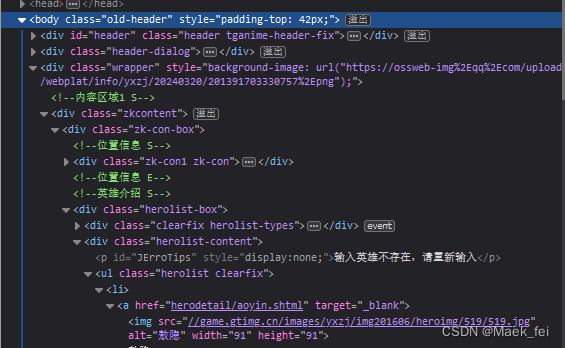
英雄具体数据位置
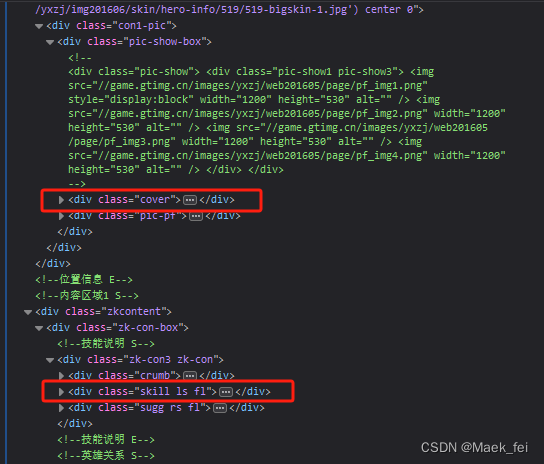
二、代码主体
话不多说,上菜
1、导入需要的库
from bs4 import BeautifulSoup #4.10.0
import matplotlib.pyplot as plt
import requests
import re
import pymysql
from wordcloud import WordCloud2、headers
headers = {
"Referer": "https://pvp.qq.com/web201605/herolist.shtml",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1"
}3、访问并解析网页
resp=requests.get('https://pvp.qq.com/web201605/herolist.shtml') #访问一级网页
soup=BeautifulSoup(resp.content,"html.parser") #利用bs4解析网页4、定位数据元素并爬取
def sum():
qu=[]
for k in soup.select('ul.herolist.clearfix a'):
a = "https://pvp.qq.com/web201605/" + k.get("href") #获得每一个英雄的子链接
qu.append(a)
name = [] #建立英雄名列表
skill1 = [] #建立英雄技能列表
beidong = [] #建立英雄技能被动列表
coat1 = [] #建立英雄皮肤名列表
form1 = [] #建立英雄召唤师技能列表
number = [] #建立英雄能力值列表
for link in qu:
hero_link = requests.get(link)
bea = BeautifulSoup(hero_link.content, "html.parser")
name1 = bea.find_all("h2")[0].text
print(name1)
name.append(name1)
for skill in bea.find('p', class_='skill-desc'): #根据网页结构找到class属性为“skill-desc”
skill = skill.text[3:] #匹配技能名称
skill1.append(skill)
print(skill)
break
for type in bea.select('span.herodetail-sort i'): #匹配被动技能名称
# print(type.get("class"))
beidong.append(type.get("class"))
# 皮肤
for coat in bea.find_all('ul', class_='pic-pf-list pic-pf-list3'): #匹配皮肤名称
coat = coat['data-imgname']
coat1.append(coat)
for form in bea.find_all('p', class_='sugg-name sugg-name3'): #匹配召唤师技能
form = form.text[5:]
form1.append(form)
for width in bea.find_all('i', class_='ibar'): #匹配英雄属性
width = width['style'][6:]
number.append(width)
life=number[::4] #提取生命值属性
hurt=number[1::4] #提取伤害属性
show=number[2::4] #提取技能效果属性
hard=number[3::4] #提取上手难度属性
reserve(name, skill1, coat1, form1, life, hurt, show, hard)
present(name, life, hurt, show, hard)5、保存数据(这里我选择保存至数据库里,大家可以自行选择保存的方式,如果要保存至自己的数据库需要自己配置host user password和port以及db名称)
def reserve(name, skill, coat, form, life, hurt, show, hard):
db = pymysql.connect(host='localhost', user='root', password='', port=3306, db='wangzhe', autocommit=True)
cursor = db.cursor()
for i in range(len(name)):
sql = """INSERT INTO wangzhe(name,
skill,coat,form,life,hurt,show1,hard)
VALUES(%s , %s, %s, %s , %s, %s , %s, %s )"""
data = (name[i], skill[i], coat[i], form[i], life[i], hurt[i], show[i], hard[i])
cursor.execute(sql, data)
db.commit()
cursor.close()
db.close()
print("还在继续")6、数据呈现
将数据展示为柱状图,并制作词云,这一部分不需要的同学可以自己删除
def present(name,life,hurt,show,hard):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name_list = name
name_list1 = []
name_list2 = []
name_list3 = []
name_list4 = []
name_list5 = []
for i in name_list:
name_list1.append(i)
for i in name_list:
name_list2.append(i)
for i in name_list:
name_list3.append(i)
for i in name_list:
name_list4.append(i)
for i in name_list:
name_list5.append(i)
num_list = life
num_list_1 = []
for i in num_list:
str1 = i[0:2]
str2 = int(str1)/100
num_list_1.append(str2)
num_list1 = hurt
num_list_2 = []
for i in num_list1:
str1 = i[0:2]
str2 = int(str1)/100
num_list_2.append(str2)
num_list2 = show
num_list_3 = []
for i in num_list2:
str1 = i[0:2]
str2 = int(str1) / 100
num_list_3.append(str2)
num_list3 = hard
num_list_4 = []
for i in num_list3:
str1 = i[0:2]
str2 = int(str1) / 100
num_list_4.append(str2)
num_list_5 = []
for i in range(len(name_list)):
num_list_5.append((num_list_1[i]+num_list_2[i]+num_list_3[i]+num_list_4[i])/4)
for i in range(1, len(num_list_5)):
for j in range(0, len(num_list_5) - i):
if num_list_5[j] > num_list_5[j + 1]:
num_list_5[j], num_list_5[j + 1] = num_list_5[j + 1], num_list_5[j]
name_list5[j], name_list5[j + 1] = name_list5[j + 1], name_list5[j]
for i in range(1, len(num_list_1)):
for j in range(0, len(num_list_1) - i):
if num_list_1[j] > num_list_1[j + 1]:
num_list_1[j], num_list_1[j + 1] = num_list_1[j + 1], num_list_1[j]
name_list1[j], name_list1[j + 1] = name_list1[j + 1], name_list1[j]
for i in range(1, len(num_list_2)):
for j in range(0, len(num_list_2) - i):
if num_list_2[j] > num_list_2[j + 1]:
num_list_2[j], num_list_2[j + 1] = num_list_2[j + 1], num_list_2[j]
name_list2[j], name_list2[j + 1] = name_list2[j + 1], name_list2[j]
for i in range(1, len(num_list_3)):
for j in range(0, len(num_list_3) - i):
if num_list_3[j] > num_list_3[j + 1]:
num_list_3[j], num_list_3[j + 1] = num_list_3[j + 1], num_list_3[j]
name_list3[j], name_list3[j + 1] = name_list3[j + 1], name_list3[j]
for i in range(1, len(num_list_4)):
for j in range(0, len(num_list_4) - i):
if num_list_4[j] > num_list_4[j + 1]:
num_list_4[j], num_list_4[j + 1] = num_list_4[j + 1], num_list_4[j]
name_list4[j], name_list4[j + 1] = name_list4[j + 1], name_list4[j]
fig = plt.figure(figsize=(50, 10))
plt.bar(name_list1, num_list_1, label='生命', fc='g')
plt.legend()
plt.savefig("英雄——生命.png")
plt.show()
plt.figure(figsize=(50, 10))
x = num_list_2
plt.pie(x)
plt.pie(x, labels=name_list2)
plt.savefig("英雄——伤害.png")
plt.show()
plt.figure(figsize=(50, 10))
x_axis_data = name_list3
y_axis_data = num_list_3
plt.plot(x_axis_data, y_axis_data, 'b*--', alpha=0.5, linewidth=1, label='acc')
plt.legend() # 显示上面的label
plt.xlabel('英雄名') # x_label
plt.ylabel('技能效果') # y_label
plt.savefig("英雄——技能效果.png")
plt.show()
fig = plt.figure(figsize=(50, 10))
plt.bar(name_list4, num_list_4, label='上手难度', fc='grey')
plt.legend()
plt.savefig("英雄——上手难度.png")
plt.show()
fig = plt.figure(figsize=(50, 10))
plt.bar(name_list5, num_list_4, label='英雄平均值', fc='pink')
plt.legend()
plt.savefig("英雄——属性平均值.png")
plt.show()
articleDict = {}
for i in name_list5:
articleDict[i] = name_list5.count(i)
word = WordCloud(background_color="white",
width=800, # 设置宽度
height=800, # 设置长度
font_path='msyh.ttf', # 字体文件
max_words=100, # 词云中显示的词汇书数量
).generate_from_frequencies(articleDict)
word.to_file('词云.png')
print("词云图片已保存")
plt.figure(figsize=(10, 10))
plt.imshow(word) # 使用plt库显示图片
plt.axis("off")
plt.show()三、注意事项(完整的代码和数据在公主号和Github)
大家白嫖代码的时候一定要注意我标明的三方库版本,版本不对很有可能会出错,此外最后保存数据的方法有很多大家可以自行挑选更改。
最重要的一点,如果大家觉得有用跪求大家给我一个关注和点赞,有不懂的问题可以私信或者留言,欢迎大家关注我的公主号,上面有更多更详尽的代码,喜欢白嫖的有福了。

GitHub - Maekfei/Spider-projects: 爬虫实战,集合了数十个爬虫实战代码,全都亲测可用,借鉴麻烦点个star谢谢 同时欢迎访问我的github主页,copy代码的同时别忘了点个star 谢谢!


















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











