







- url: https://hangzhou.anjuke.com/community/
相比较房天下, 只需要在请求头中加入cookie即可(不带cookie会被封ip)
直接上代码:
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
import time
#需要杭州: 区域,地址,板块,房价,小区名,楼龄等信息
columns = ["名称", "竣工时间", "版块", "单价", "周边", "物业类型", "权属类别", "竣工时间", "产权年限", "总户数", "建筑面积", "容积率", "绿化率",
"建筑类型", "所属商圈", "统一供暖", "供水供电", "停车位", "物业费", "停车费", "车位管理费", "物业公司", "小区地址", "开发商"]
headers = {
'User-Agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"cookie" : "你的cookie",
"referer": "https://hangzhou.anjuke.com/community/"
}
def getUrl(URL):
headers2 = {
'User-Agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"cookie" : "你的cookie",
"referer": "https://hangzhou.anjuke.com/community/"
}
re2 = requests.get(URL, headers=headers2)
soup2 = BeautifulSoup(re2.text, "html.parser")
return soup2
def getLabel(html, isprint=True):
info = html.find("div", {"class":"info-list"})
label1 = info.find_all("div", {"class":"column-1"})
label2 = info.find_all("div", {"class":"column-2"})
Label1 = []
Label2 = []
Label = []
for i in range(len(label1)):
lab1str = label1[i].text.replace("\n", ":").replace(" ", "")[:-1]
if isprint == True:
print(lab1str)
Label1.append(lab1str[lab1str.find(":")+1::])
for j in range(len(label2)):
lab2str = label2[j].find("div", {"class":"hover-value"}).text.replace(" ", "").replace("\n", "")
if isprint == True:
print("{0}:{1}".format(label2[j].div.text, lab2str))
Label2.append(lab2str)
#print(Label1)
Label = Label2 + Label1
return Label
def getPage(url):
df = pd.DataFrame(columns=columns)
response = requests.get(url, headers=headers)
print(response.status_code)
soup = BeautifulSoup(response.text, "html.parser")
title = soup.find_all("a", {"class":"li-row"})
#print(title[0])
for i in range(len(title)):
Label0 = []
Info = []
print(title[i].attrs["href"])
name = title[i].find("div", {"class":"nowrap-min li-community-title"}).text
Label0.append(name)
year = title[i].find("span", {"class":"year"})
if year == None:
Label0.append("无")
else:
Label0.append(year.text)
location = title[i].find("span", {"class":""})
if location == None:
Label0.append("无")
else:
Label0.append(location.text)
price_rural = title[i].find("div", {"class":"community-price"})
if price_rural == None:
Label0.append("无")
else:
price = re.findall(r"\d+元/m²", price_rural.text.replace(" ", ""))[0]
Label0.append(price)
tags = []
tag = title[i].find_all("span", {"class":"prop-tag"})
for span in tag:
tags.append(span.text)
Label0.append(tags)
sonpage = getUrl(title[i].attrs["href"])
res = getLabel(sonpage)
Info = Label0 + res
print(Info)
df.loc[i] = Info
time.sleep(3) # 增加间隔, 防止被封
return df
headers是list页面的请求头
headers2是某条内容的请求头, 二者使用的cookie不同
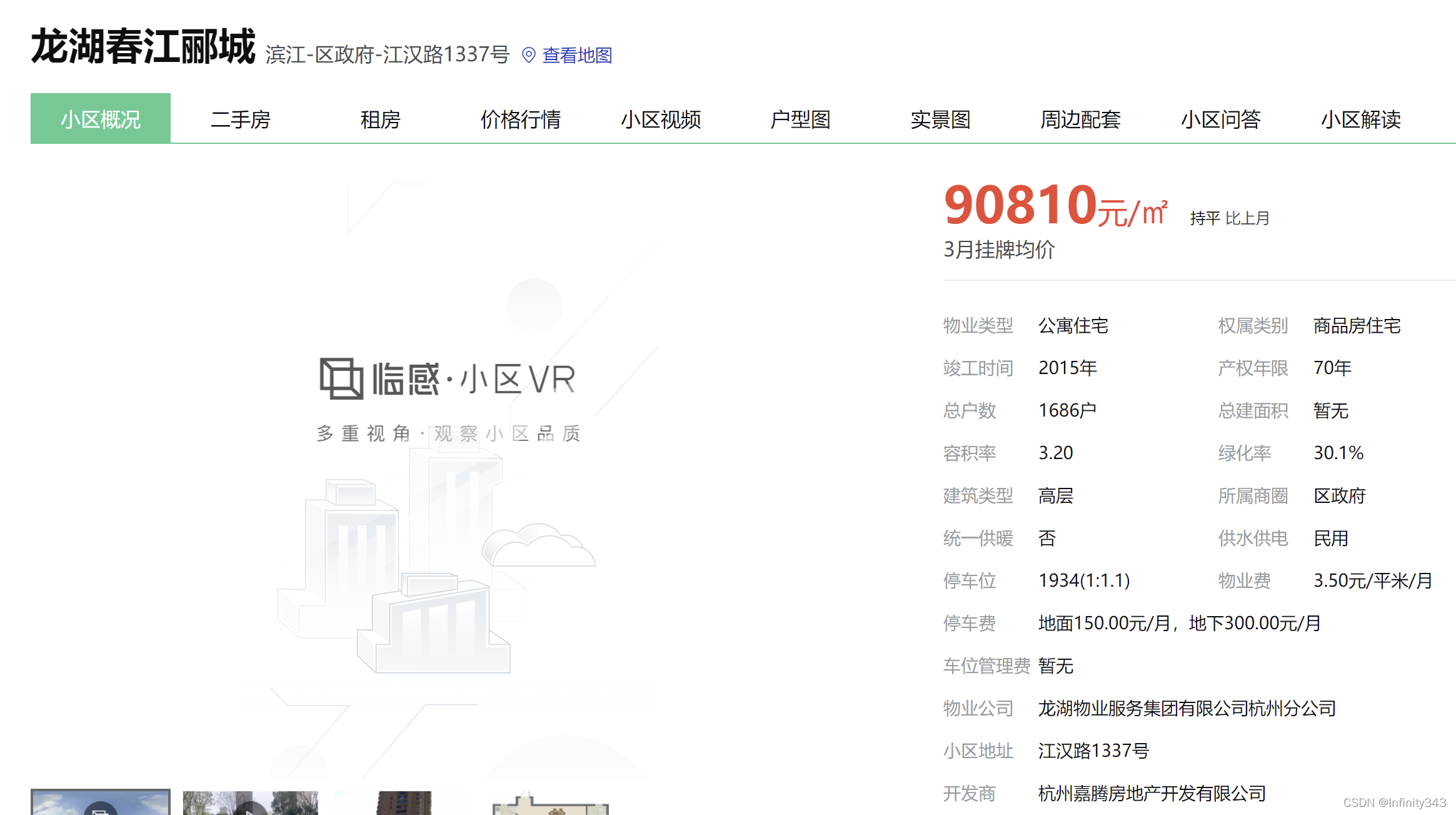
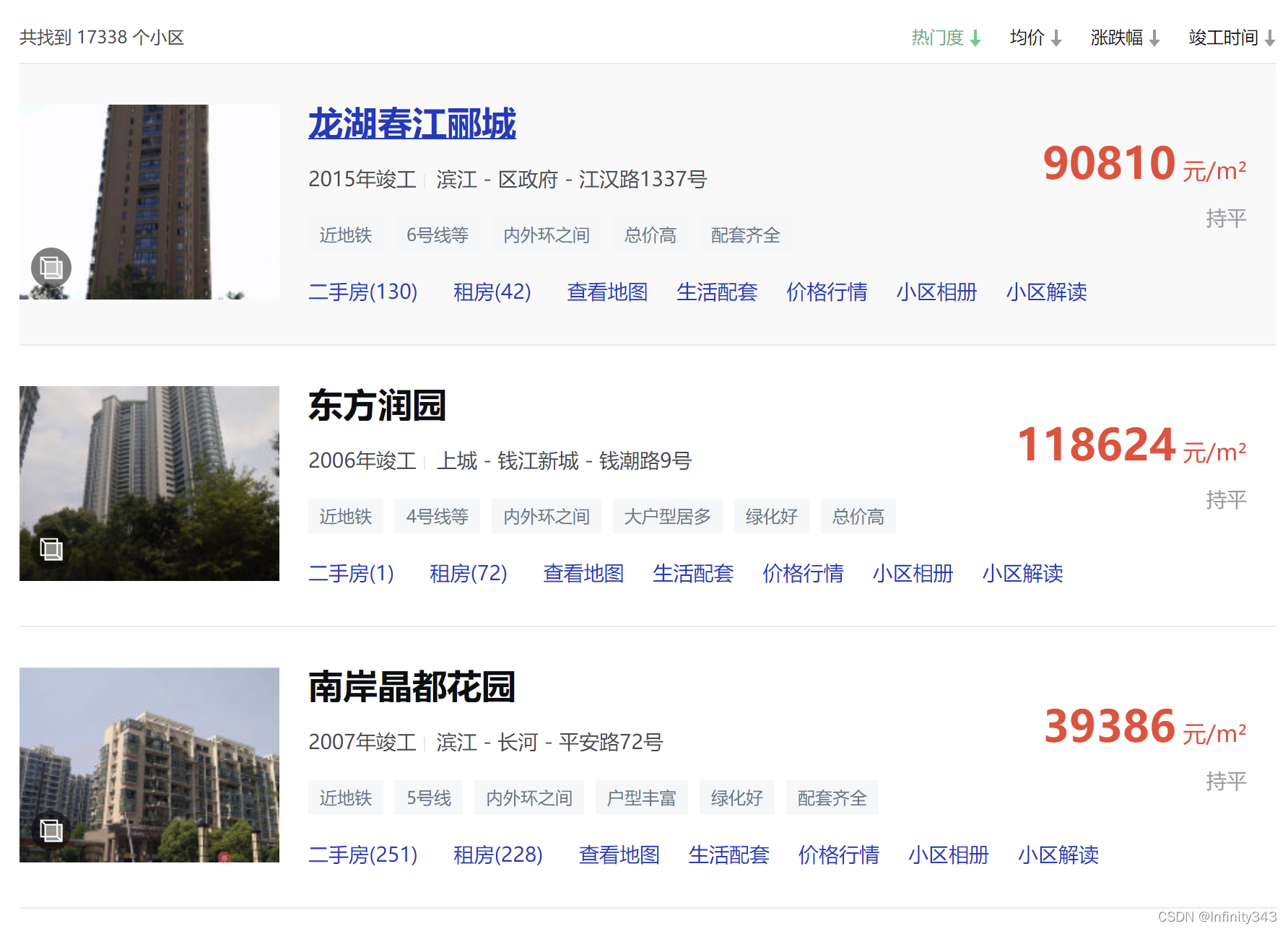
只需要在调试模式下对内容标签做简单的分析和整理, 就能够得到其组织关系和页面跳转的规则. 之前已经写过多期爬虫实例, 不再赘述. 简单爬个42页
















 2134
2134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











