







文章目录
实验目的:
1.熟悉requests请求的发送
2.掌握爬取页面的保存
实验内容:
1.使用百度搜索引擎查询给定的一个关键词(例如:bigdata),将搜索得到的网页存储起来。
2.给定使用baidu搜索引擎的关键词列表,将搜索得到的网页分别存储起来。
关键词列表:数据科学, 大数据, 人工智能, 机器学习, 数据挖掘, 多元统计, 数据科学与大数据技术, hadoop, hive, spark, hbase
因为一二两题的逻辑相同,所以代码经过函数封装,用两问的代码如下
2.1 代码展示
def search_baidu(word:str):
"""使用百度搜索引擎查询给定的一个关键词(例如:bigdata),将搜索得到的网页存储起来。
Args:
word (str): 关键词
"""
import requests
import os
import time
current_path = os.path.dirname(__file__)
try:
result_dir_path = os.path.join(current_path, "search_baidu_result")
os.mkdir(result_dir_path)
except:
FileExistsError()
fileName = f'{word}.html'
file_path = os.path.join(result_dir_path, fileName)
url = "https://www.baidu.com/s"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36",
"cookie": "BAIDUID=DA699FCD7A80FD44AC7BDE1394D8BF03:FG=1; BIDUPSID=DA699FCD7A80FD44AC7BDE1394D8BF03; PSTM=1682335906; BDUSS=BzdTIzdGF5Wi12WX5vREY2dkJpVmRJWHhlblVRVVdQeTRSdUNMRzkwSEQ2dlprSVFBQUFBJCQAAAAAAAAAAAEAAAC9Vem~wdm352FkdWx0AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAMNdz2TDXc9kSH; BDUSS_BFESS=BzdTIzdGF5Wi12WX5vREY2dkJpVmRJWHhlblVRVVdQeTRSdUNMRzkwSEQ2dlprSVFBQUFBJCQAAAAAAAAAAAEAAAC9Vem~wdm352FkdWx0AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAMNdz2TDXc9kSH; BD_UPN=12314753; BAIDUID_BFESS=DA699FCD7A80FD44AC7BDE1394D8BF03:FG=1; BA_HECTOR=01a58k2005200k248l2k8gan1igo9nu1o; ZFY=5ETOScQaDmVYUyRxJsBOitC:AF:AOuM3pyHm8K0Ado5Nc:C; COOKIE_SESSION=161522_0_1_1_4_0_1_0_1_0_0_0_161542_0_55_0_1680853952_0_1680853897%7C3%230_0_1695302087%7C1%7C1; channel=bing; B64_BOT=1; baikeVisitId=02d8db48-c770-4ca4-aa49-69c210937c81; BD_CK_SAM=1; PSINO=6; delPer=0; H_PS_PSSID=39309_39364_39281_39347_39407_39097_39358_39307_39233_39403_26350_39428; BDRCVFR[feWj1Vr5u3D]=mk3SLVN4HKm; sugstore=0; H_PS_645EC=c327S49hWZbAupxVZJEMbJLQHUVrkWMagF5D3KMTvbIDRFqrIRvsH7ZRgth2jZ8qhAOb"
}
params = {
"wd": word
}
response = requests.get(url, headers=headers, params=params)
print(file_path)
with open(file_path, "wb") as f:
f.write(response.content)
time.sleep(2)
if __name__ == "__main__":
search_baidu("bigData")
word_list = ["数据科学", "大数据", "人工智能", "机器学习", "数据挖掘", "多元统计", "数据科学与大数据技术", "hadoop", "hive", "spark", "hbase"]
for wd in word_list:
search_baidu(wd)
2.2 效果展示
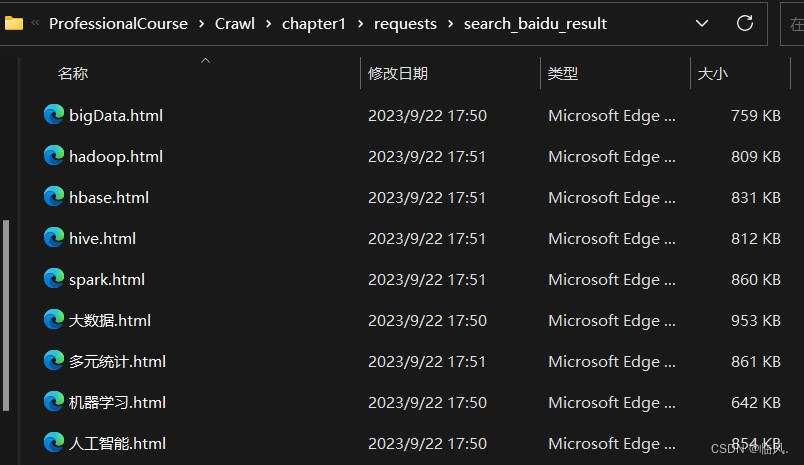
2.3 注意事项
因为百度的反爬(安全认证)机制,所以在代码中加入cookie和sleep,限制了爬取速度,使得能够顺利爬取,或者可以使用不同的ua以及代理也可行。
3.在人邮教育官网上搜索“爬虫”的图书信息,结果保存起来。
3.1 代码展示
def search_ryjiaoyu(word:str):
"""在人邮教育官网上搜索“爬虫”的图书信息,结果保存起来
Args:
word (str): 图书名称
"""
import os
import requests
current_path = os.path.dirname(__file__)
try:
result_dir_path = os.path.join(current_path, "search_ryjiaoyun_result")
os.mkdir(result_dir_path)
except:
FileExistsError()
fileName = f'{word}.html'
file_path = os.path.join(result_dir_path, fileName)
url = "https://www.ryjiaoyu.com/search"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31"
}
params = {
"q": word
}
response = requests.get(url, headers=headers, params=params)
with open(file_path, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
search_ryjiaoyu("爬虫")
3.2 效果展示
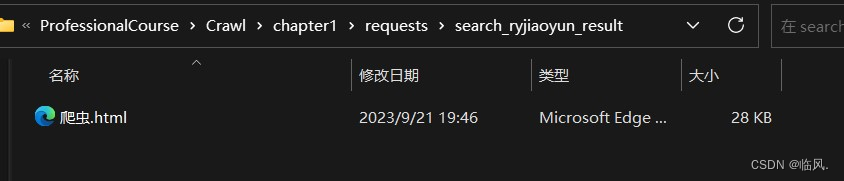
4.给定关键词列表(例如:【大数据、java、python】),在人邮教育官网上搜索图书、文章、资源、题库,并分类保存
4.1 代码展示
def search_ryjiaoyuPlus(wd_list:list):
"""给定关键词列表(例如:【大数据、java、python】),在人邮教育官网上搜索图书、文章、资源、题库,并分类保存
Args:
wd_list (list): 关键词词列表
"""
import os
import requests
url = "https://www.ryjiaoyu.com/search"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31"
}
current_path = os.path.dirname(__file__)
try:
result_dir_path = os.path.join(current_path, "search_ryjiaoyunPlus_result")
os.mkdir(result_dir_path)
except:
FileExistsError()
wd_types = ["book", "article", "res", "paper"]
for wd in wd_list:
for wd_type in wd_types:
params = {
"q": wd,
"type": wd_type
}
try:
wd_dir_path = os.path.join(result_dir_path, f"{wd}_result_dir")
wd_type_dir_path = os.path.join(wd_dir_path, f"{wd}_{wd_type}")
os.makedirs(wd_type_dir_path)
except:
FileExistsError()
file_path = os.path.join(wd_type_dir_path, f"{wd}_{wd_type}.html")
response = requests.get(url, headers=headers, params=params)
with open(file_path, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
wd_list = ["大数据", "java", "python"]
search_ryjiaoyuPlus(wd_list)
4.2 效果展示
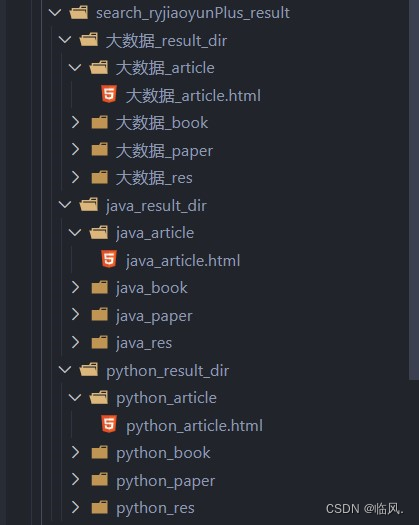
5.爬取人邮教育官网,关于“大数据”搜索结果的所有文章
5.1 代码展示
def search_ry_bigData():
"""爬取人邮教育官网,关于“大数据”搜索结果的所有文章"""
import os
import requests
url ="https://www.ryjiaoyu.com/search"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31"
}
current_path = os.path.dirname(__file__)
try:
result_dir_path = os.path.join(current_path, "search_ry_bigData_result")
os.mkdir(result_dir_path)
except:
FileExistsError()
for page in range(1, 9):
filePath = os.path.join(result_dir_path, f"第{page}页的大数据文章.html")
params = {
"q": "大数据",
"type": "article",
"page": page
}
response = requests.get(url, headers=headers, params=params)
print(response.text)
with open(filePath, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
search_ry_bigData()
5.2 效果展示
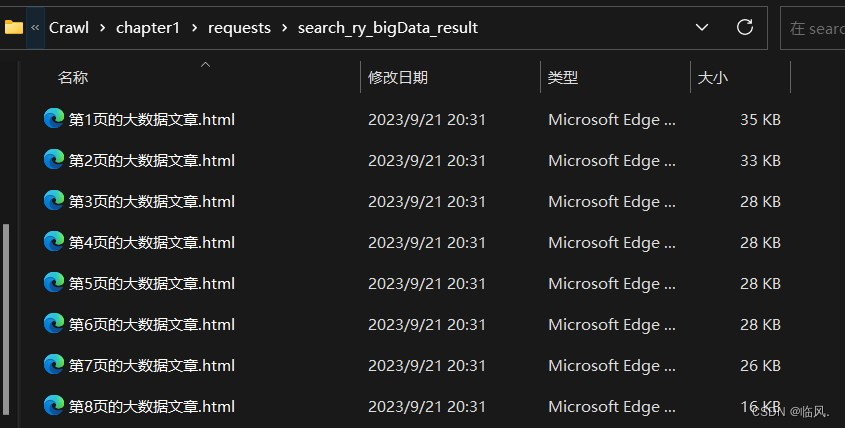
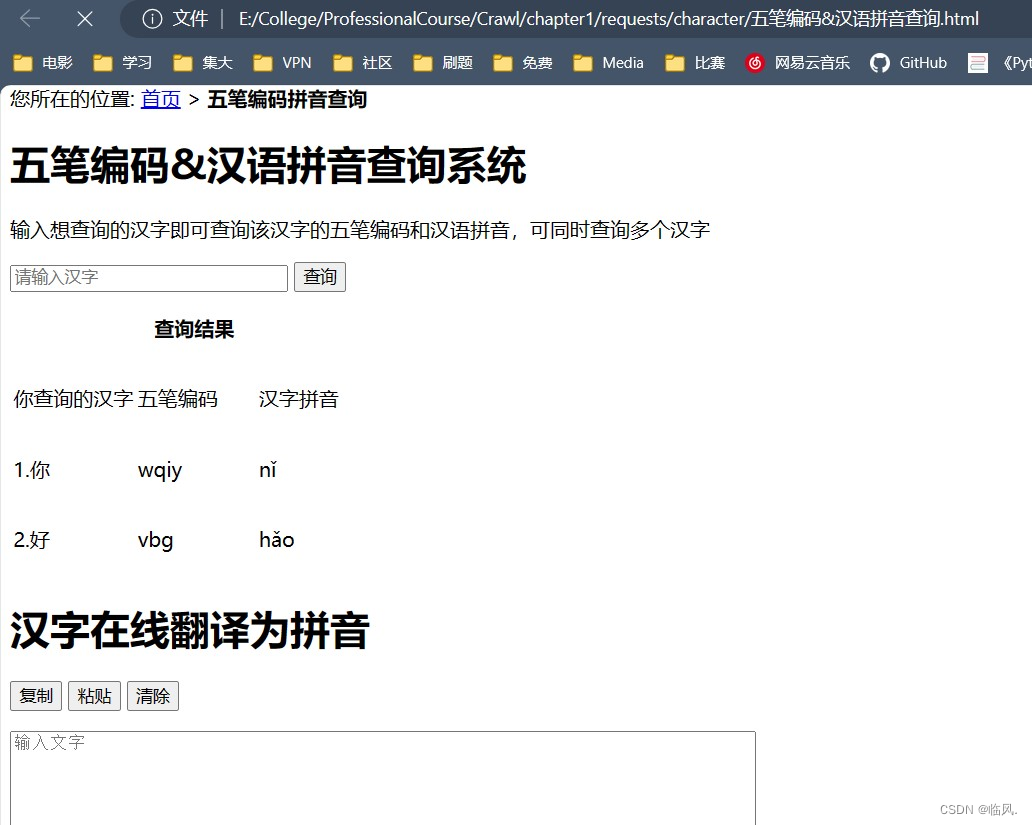
6.通过汉字查五笔和拼音,并将结果保存起来,要求爬虫封装在函数里。
https://qq.ip138.com/wb/wb.asp
6.1 代码展示
def search_wubi_pinyin(characters:str):
"""通过汉字查五笔和拼音,并将结果保存起来,要求爬虫封装在函数里。
https://qq.ip138.com/wb/wb.asp
Args:
characters (str): 汉字或者句子
"""
import os
import requests
url = "https://qq.ip138.com/wb/wb.asp"
data = {
"querykey":characters
}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31"
}
current_path = os.path.dirname(__file__)
result_dir_path = os.path.join(current_path, "character")
try:
os.mkdir(result_dir_path)
except:
FileExistsError
filePath = os.path.join(result_dir_path, "五笔编码&汉语拼音查询.html")
response = requests.post(url, headers=headers, data=data)
with open(filePath, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
search_wubi_pinyin("你好")
6.2 效果展示
实验小结
- 使用os库注意当前路径
- 爬虫时注意网站是get还是post,因为使用的参数不同,一个为params,一个为data
- 输出时要注意编码问题















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









