






1、所用数据集为开放大型数据集中的(随机)多少张:
举例:

已有下载好原始coco数据集到原始文件夹内,现想要将其中的随机10000张复制到A文件夹内充当新训练集,随机1000张图像复制到B文件夹内充当新验证集,且希望A和B文件夹图像没有重叠:
import os
import random
import shutil
# 源文件夹路径和目标文件夹A、B路径
source_folder = "原始文件夹路径"
target_folder_A = 'A文件夹路径'
target_folder_B = 'B文件夹路径'
# 获取源文件夹中所有文件名
file_list = os.listdir(source_folder)
# 从文件列表中随机选择10000个文件放入文件夹A
selected_files_A = random.sample(file_list, 10000)
remaining_files = [file for file in file_list if file not in selected_files_A]
# 从剩余文件列表中随机选择1000个文件放入文件夹B
selected_files_B = random.sample(remaining_files, min(1000, len(remaining_files)))
# 确保目标文件夹A和B存在,如果不存在则创建
if not os.path.exists(target_folder_A):
os.makedirs(target_folder_A)
if not os.path.exists(target_folder_B):
os.makedirs(target_folder_B)
# 复制选中的文件到目标文件夹A
for file in selected_files_A:
source_file_path = os.path.join(source_folder, file)
target_file_path = os.path.join(target_folder_A, file)
shutil.copyfile(source_file_path, target_file_path)
# 复制选中的文件到目标文件夹B
for file in selected_files_B:
source_file_path = os.path.join(source_folder, file)
target_file_path = os.path.join(target_folder_B, file)
shutil.copyfile(source_file_path, target_file_path)
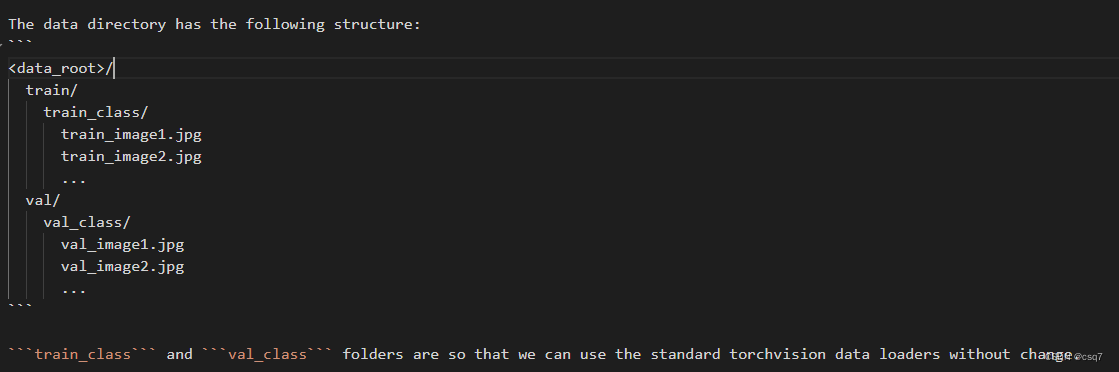
print("复制完成!")2.数据集内的图片需要按照给出的组织格式进行重命名:
举例:
import os
folder_path = '/home/linux/code/csq/IGA-main/dataset/coco/train/train_class/' # 替换为你的文件夹路径
file_format = 'train_image{}.jpg' # 重命名格式,{} 表示编号
# 获取文件夹内所有图片文件名
image_files = [file for file in os.listdir(folder_path) if file.endswith('.jpg') or file.endswith('.png')]
# 重命名文件
for i, image_file in enumerate(image_files, start=1):
extension = os.path.splitext(image_file)[1] # 获取文件扩展名
new_name = file_format.format(i) + extension
old_path = os.path.join(folder_path, image_file)
new_path = os.path.join(folder_path, new_name)
os.rename(old_path, new_path)
print("重命名完成!")















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









