







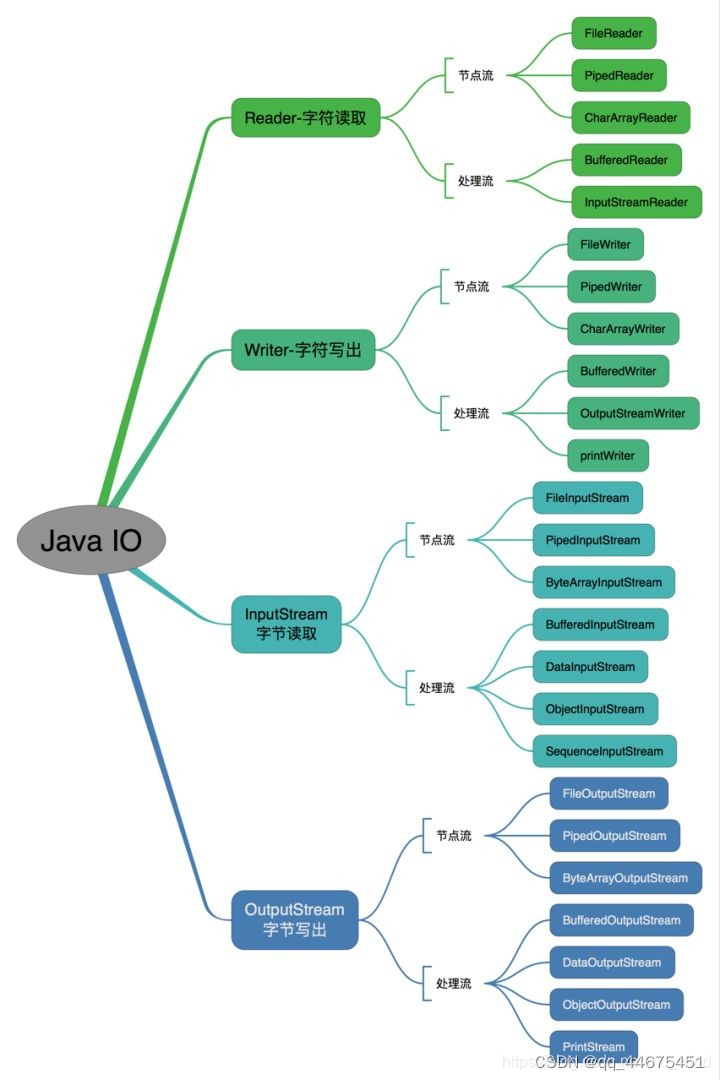
IO流主要的分类方式有以下3种:
- 按数据流的方向:输入流、输出流
- 按处理数据单位:字节流、字符流
- 按功能:节点流、处理流
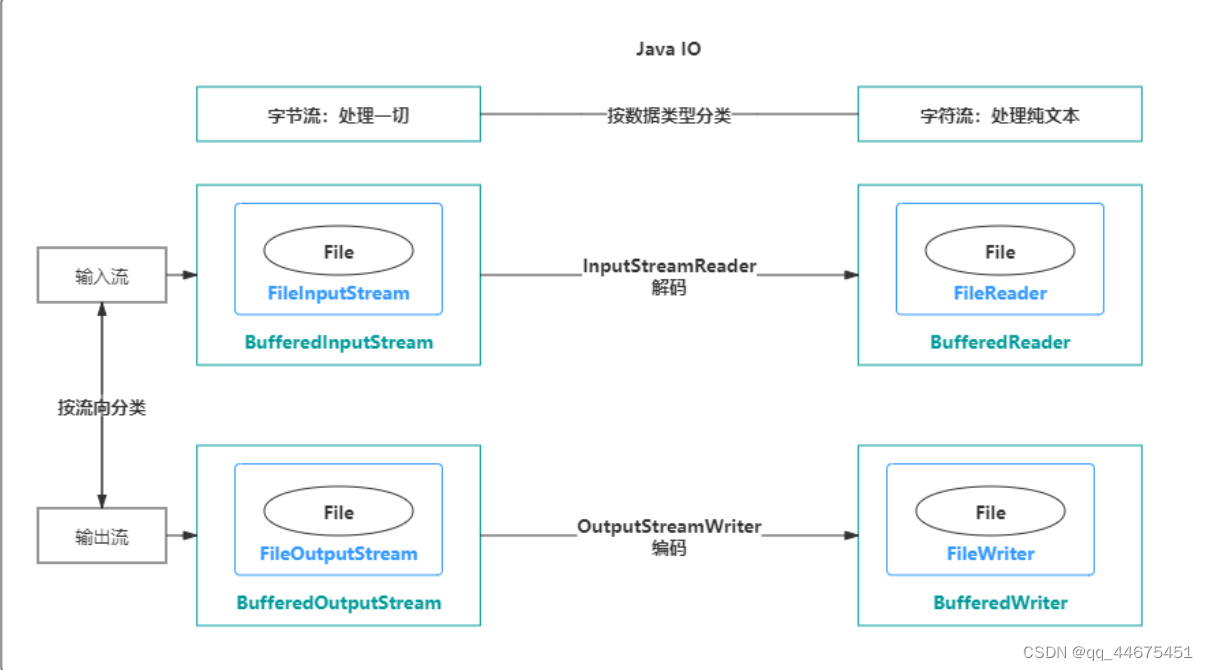
字节流字符流操作数据不同
字节流操作的单元是数据单元是8位的字节,字符流操作的是数据单元为16位的字符。
为什么用字符流?
- Java中字符是采用Unicode标准,Unicode 编码中,一个英文字母或一个中文汉字为两个字节。
- 而在UTF-8编码中,一个中文字符是3个字节。例如下面图中,“云深不知处”5个中文对应的是15个字节:-28-70-111-26-73-79-28-72-115-25-97-91-27-92-124
- 那么问题来了,如果使用字节流处理中文,如果一次读写一个字符对应的字节数就不会有问题,一旦将一个字符对应的字节分裂开来,就会出现乱码了。为了更方便地处理中文这些字符,Java就推出了字符流。
字节流和字符流的其他区别:
1.字节流:一般用来处理图像、视频、音频、PPT、Word等类型的文件。字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。
2.字符流:一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。
3.字节流可以处理一切文件,而字符流只能处理纯文本文件。字符流 = 字节流 + 编码表
一、File
构造方法:
File(String pathname):根据一个路径得到File对象
File(String parent, String child):根据一个目录和一个子文件/目录得到File对象
File(File parent, String child):根据一个父File对象和子文件/目录得到File对象
常用功能:
public boolean creatNewFile():创建一个新文件,若存在,则不重复创建
public boolean mkdir():创建一个目录,若存在,则不创建,只能创建单层目录
public boolean mkdirs():创建一个目录,若存在,则不创建,用于创建单层或多层目录
删除功能:
public boolean delete():删除文件或者文件夹
注意:只能删除空文件夹
重命名功能:
public boolean renameTo(File file):把文件重命名为指定路径
判断功能
public boolean isDirectory(): 判断是否是目录
public boolean isFile(): 判断是否是文件
public boolean exists(): 判断是否存在
public boolean canRead(): 判断是否可读
public boolean canWrite(): 判断是否可写
public boolean isHidden(): 判断是否隐藏
获取功能:
public String getAbsolutePath(): 获取绝对路径
public String getPath(): 获取相对路径
public String getParent() 获取上一级路径,返回字符串,没有返回null
public File getParentFile() 获取上一级路径,返回File类型,没有返回null
public long getTotalSpace() 返回总容量 单位字节
public long getFreeSpace() 返回剩余容量 单位字节
public String getName(): 获取名称
public long length(): 获取长度。字节数
public long lastModified(): 获取最后一次的修改时间,毫秒值
public String[] list():获取指定目录下的所有文件或者文件夹的名称数组
public File[] listFiles():获取指定目录下的所有文件或者文件夹的File数组
具体请跳转
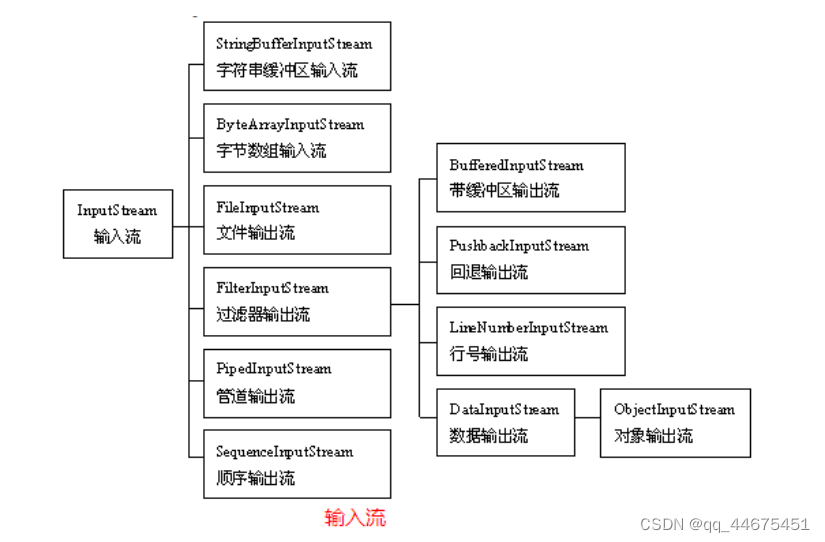
二、InputStream
FileInputStream
构造方法有三个,常用的有以下两个:
1、FileInputStream(File file),参数传入一个File类型的对象。
2、FileInputStream(String name),参数传入文件的路径。
常用方法:
1、int read()方法
从文件的第一个字节开始,read方法每执行一次,就会将一个字节读取,并返回该字节ASCII码,如果读出的数据是空的,即读取的地方是没有数据,则返回-1。
2.int read(byte b[])
该方法与int read()方法不一样,该方法将字节一个一个地往byte数组中存放,直到数组满或读完,然后返回读到的字节的数量,如果**一个字节都没有读到,则返回-1
引用
BufferedInputStream
- 当创建BufferedInputStream时,将创建一个内部缓冲区数组
- BufferedInputStream 的父类是FilterInputStream
- 使用BufferedInputStream读资源比FileInputStream读取资源的效率高(BufferedInputStream的read方法会读取尽可能多的字节,执行read时先从缓冲区读取,当缓冲区数据读完时再把缓冲区填满。
- BufferedInputStream大部分是从缓冲区读入
构造方法
1.BufferedInputStream(InputStream in)
创建一个 BufferedInputStream并保存其参数,输入流 in ,供以后使用。
2.BufferedInputStream(InputStream in, int size)
创建 BufferedInputStream具有指定缓冲区大小,可以指定缓冲区的大小。
例如:
BufferedInputStream buffer2 = new BufferedInputStream(new FileInputStream("D:\\www\\abc.txt"));
read方法的使用与FileInputStream类中读的方法是一致的
read() //一次读取一个字节
read(byte[] ch) //一次读取一个字节数组
read(byte[] ch , int off,int length) //一次读取一个字节数组,设置偏移量,以及读取字节的长度
ObjectInputStream和ObjectInputStream
- ObjectInputStream是将对象的原始数据序列化,ObjectOutputStream将序列化的数据反序列化。一定要注意ObjectOutputStream与ObjectInputStream必须配合使用,且按同样的顺序。
- ObjectInputStream 用于恢复先前序列化的对象,其它的用途包括主机之间使用socket流传递对象、远程系统调用
- 只有对象支持java.io.Serializable或java.io.Externalizable接口的才能够被从流中读取
注意:
Java对象的存取条件
1.对象所属的类需要序列化
2.对象中的属性的类也都需要序列化
3.对象所属的类需要提供全局常量serialVersionUID序列化版本号
序列化、反序列化方法
writeObject(对象)
Object o = ois.readObject();
引用
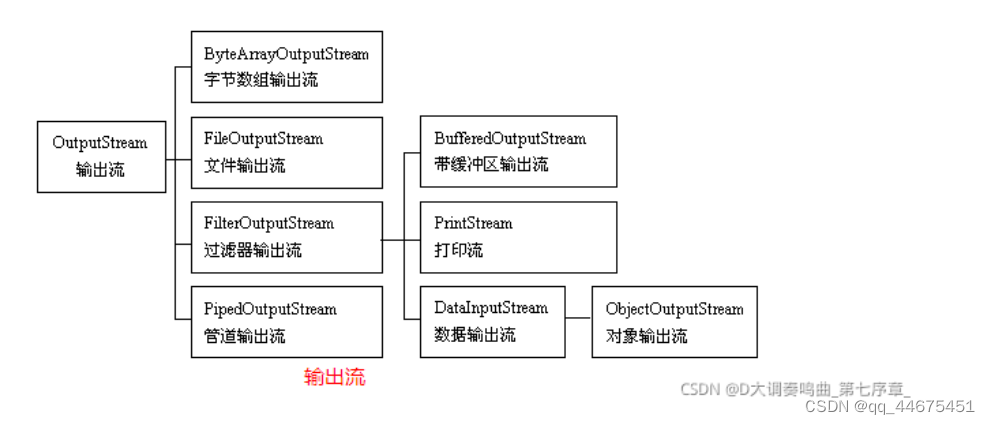
三、OutputStream
FileOutputStream
构造方法:
FileOutputStream(File file) 创建一个向指定 File 对象表示的文件中写入数据的文件输出流。
FileOutputStream(File file,boolean append) 意思同上,但是可以追加数据,不覆盖原有数据
FileOutputStream(String path) 创建一个向具有指定名称的文件中写入数据的输出文件流。
FileOutputStream(String path,boolean append)创建一个向具有指定 name 的文件中写入数据的输出文件流。
注:
它与输入流的构造方法有一些不同点
①多了一个boolean类型的参数表可追加
②若文件路径不存在会自动创建,而输入流会报错
常用方法:
//java提供个三种写入数据的形式,分别是字节数组,指定字节数组,字节
write(byte[] b) 将 b.length 个字节从指定 byte 数组写入此文件输出流中。
write(byte[] b, int off, int len) 将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此文件输出流。
write(int b) 将指定字节写入此文件输出流
BufferOutputStream
和bufferInputStream原理一样

//刷新此缓冲的输出流,保证数据全部都能写出
bos.flush();
四、Reader
FileReader
Java提供了FileWriter和FileReader简化字符流的读写,new FileWriter等同于new OutputStreamWriter(new FileOutputStream(file, true))
构造方法:
- FileReader(File file) 在给定从中读取数据的 File 的情况下创建一个新 FileReader。
- FileReader(FileDescriptor fd) 在给定从中读取数据的 FileDescriptor 的情况下创建一个新
FileReader。 - FileReader(String fileName) 在给定从中读取数据的文件名的情况下创建一个新 FileReader
常用方法:
- public int read() throws IOException 读取单个字符。 读取的字符,如果已到达流的末尾,则返回 -1
- public int read(char[] cbuf) throws IOException 读取一个字符数组
读取的字符,如果已到达流的末尾,则返回 -1 - public void close() throws IOException 关闭该流并释放与之关联的所有资源。
示例:
public static void main(String[] args) throws Exception {
//读取当前项目下的StringDemo.java文件
FileReader fr = new FileReader("StringDemo.java")
//一次读取一个字符数组
char[] chs = new char[1024] ;
int len = 0 ;
while((len=fr.read(chs))!=-1) {
System.out.println(new String(chs,0,len));
}
//释放资源
fr.close();
}
BufferedReader
构造方法:
BufferedReader(Reader inputStream)
BufferedReader(Reader inputStream, int bufSize)
常用方法:
void close()
void mark(int markLimit)
boolean markSupported()
int read()
int read(char[] buffer, int offset, int length)
String readLine()
boolean ready()
void reset()
long skip(long charCount)
注意:
StringBuffer类的readLine()从每次读取的一行内容,直至读取的为null为止。然后进行输出。
StringBuffer类的read()方法读取到的每一个数字转化后的字符,然后进行输出。
InputStreamReader
InputStreamReader类是从字节流到字符流的桥接器:它使用指定的字符集读取字节并将它们解码为字符。 它使用的字符集可以通过名称指定,也可以明确指定,或者可以接受平台的默认字符集。每次调用一个InputStreamReader的read()方法都可能导致从底层字节输入流中读取一个或多个字节。 为了实现字节到字符的有效转换,可以从基础流中提取比满足当前读取操作所需的更多字节。为了获得最高效率,请考虑在BufferedReader中包装InputStreamReader
InputStreamReader类与FileReader类的关系
1、FileReader类仅仅是InputStreamReader的简单衍生并未扩展任何功能
2、FileReader类读取数据实质是InputStreamReader类在读取,而InputStreamReader读取数据实际是StreamDecoder类读取
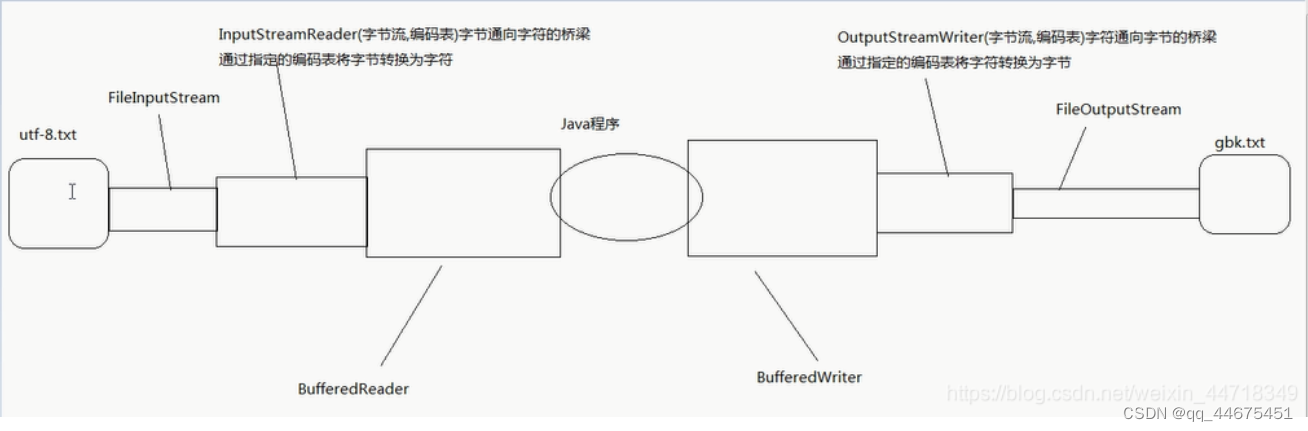 代码演示:
代码演示:
//初级版
//inputstream:将字节流转换为字符流的桥梁
InputStreamReader isr = new InputStreamReader(new FileInputStream("utf-8.txt"), "utf-8");//使用指定码表
//outputstream:将字符流转换为字节流的桥梁
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("gbk.txt"),"gbk");
int c;
while((c = isr.read()) != -1) {
osw.write(c);
}
isr.close();
osw.close();
-----------------------------------------------------------------------
//升级版
BufferedReader br = //高效的用指定的编码表读
new BufferedReader(new InputStreamReader(new FileInputStream("utf-8.txt"), "UTF-8"));
BufferedWriter bw = //高效的用指定的编码表写
new BufferedWriter(new OutputStreamWriter(new FileOutputStream("gbk.txt"), "GBK"));
int ch;
while((ch = br.read()) != -1) {
bw.write(ch);
}
br.close();
bw.close();
五、Writer
FileWriter
构造方法:
- FileWriter(File file) 根据给定的 File 对象构造一个 FileWriter 对象。
- FileWriter(File file, boolean append) 根据给定的 File 对象构造一个 FileWriter
对象。 - FileWriter(String fileName) 根据给定的文件名构造一个 FileWriter 对象。
- FileWriter(String fileName, boolean append) 根据给定的文件名以及指示是否附加写入数据的
boolean 值来构造 FileWriter 对象。
常用方法:
write(int c):写入数字,利用 ASCII 码表 或者 Unicode 表转化
write(String str):写入字符串
write(char[] cbuf):写入字符数组
write(String str, int off, int len):写入字符串的一部分
write(char[] cbuf,int off,int len):写入字符数组的一部分
举例:
public static void testOverload() throws IOException {
FileWriter fileWriter = new FileWriter("file03.txt");
// 重载方法一:写入数字,利用 ASCII 码表 或者 Unicode 表转化
// ASCII 码表中常用的:48 - 0,65 - A,97 - a
fileWriter.write(65);
fileWriter.write("\r\n");
// 定义字符串
String str = "我很骄傲我是中国人!";
// 重载方法二:写入字符串
fileWriter.write(str);
fileWriter.write("\r\n");
// 重载方法三:写入字符数组
char[] javaArray = {'J','a','v','a'};
fileWriter.write(javaArray);
fileWriter.write("\r\n");
// 重载方法四:写入字符串的一部分(结果:我是中国人)
fileWriter.write(str, 4, 5);
fileWriter.write("\r\n");
// 重载方法五:写入字符数组的一部分(结果:v)
fileWriter.write(javaArray, 2, 1);
fileWriter.close();
}
BufferedWriter
BufferedWriter类是Writer的子类,它为了提高效率,加入了缓冲技术,将字符读取对象作为参数。
BufferedWriter类将一个常量值作为默认缓冲区的大小,它同时也可以通过构造函数来指定大小。
提供了newLine()方法,它使用自己的行分隔符概念,它是由系统自带的属性line.separator定义,并非使用换行符来终止行.
writer会立即将其输出发送到基础字符或字节流,所以在使用BufferedWriter来包装writer的子类可以提高输出的效率
BufferedWriter类中的方法都返回void,write()方法,写入字符串的某一部分,flush()方法刷新该流的缓存。
举例:
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.IOException;
//缓冲区的出现是为了提高流的操作效率而出现的
//所以在创建缓冲区之前,必须先要有流对象
public class BufferedWriterDemo{
public static void main(String[] args) throws IOException{
//在这里抛一个IO异常,才能运行
FileWriter fr =new FileWriter(“E:/buf1.txt”);//创建一个读取流对象和文件相关联
bufferedWriter bufw = new buffereWriter(fw);//创建buffereWriter类对象
For(int x=1;x<9;x++){
Bufw.write(“abcd”+x);
Bufw.newLine();
Bufw.flush();
}
Bufw.flush();//刷新
Bufw.clase();//关闭缓冲区
}
}
OutputStreamWriter
原理同InputStreamWriter
换行:
Windows 操作系统下:\r\n
Linux 操作系统下:\n
Mac 操作系统下:早期使用的是 \r,现在使用的是 \n
字节与字符:
ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。
UTF-8 编码中,一个英文字为一个字节,一个中文为三个字节。
Unicode 编码中,一个英文为一个字节,一个中文为两个字节。
符号:英文标点为一个字节,中文标点为两个字节。例如:英文句号 . 占1个字节的大小,中文句号 。占2个字节的大小。
UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节(Unicode 扩展区的一些汉字存储需要 4 个字节)。
UTF-32 编码中,世界上任何字符的存储都需要 4 个字节。















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









