







ACM-ZZU 1178单词数
问题:统计一篇文章里不同单词的总数(如下图)
有多组数据,每组一行,每组就是一篇小文章。每篇小文章都是由小写字母和空格组成,没有标点符号,遇到#时表示输入结束。每篇文章的单词数小于1000,每个单词最多由30个字母组成。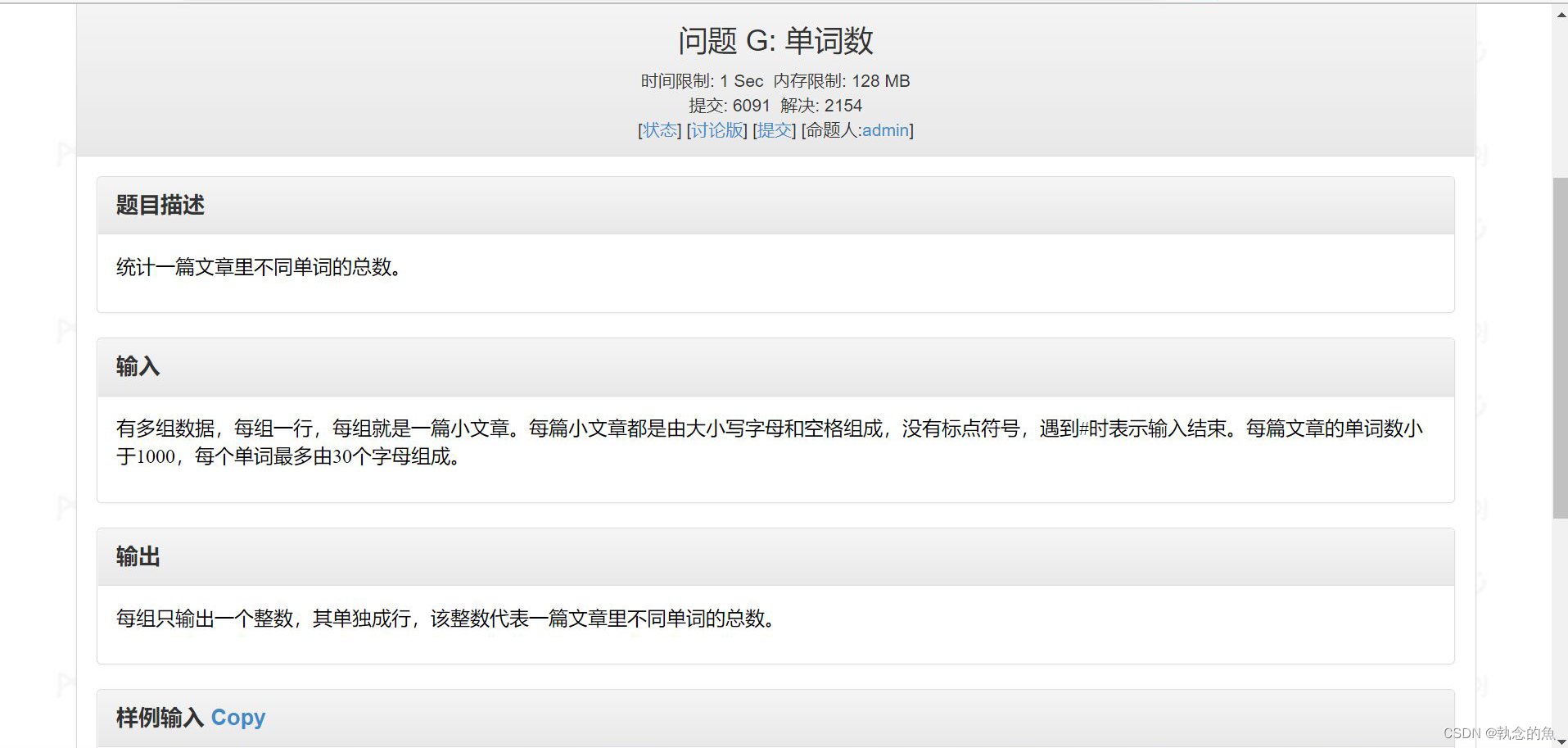
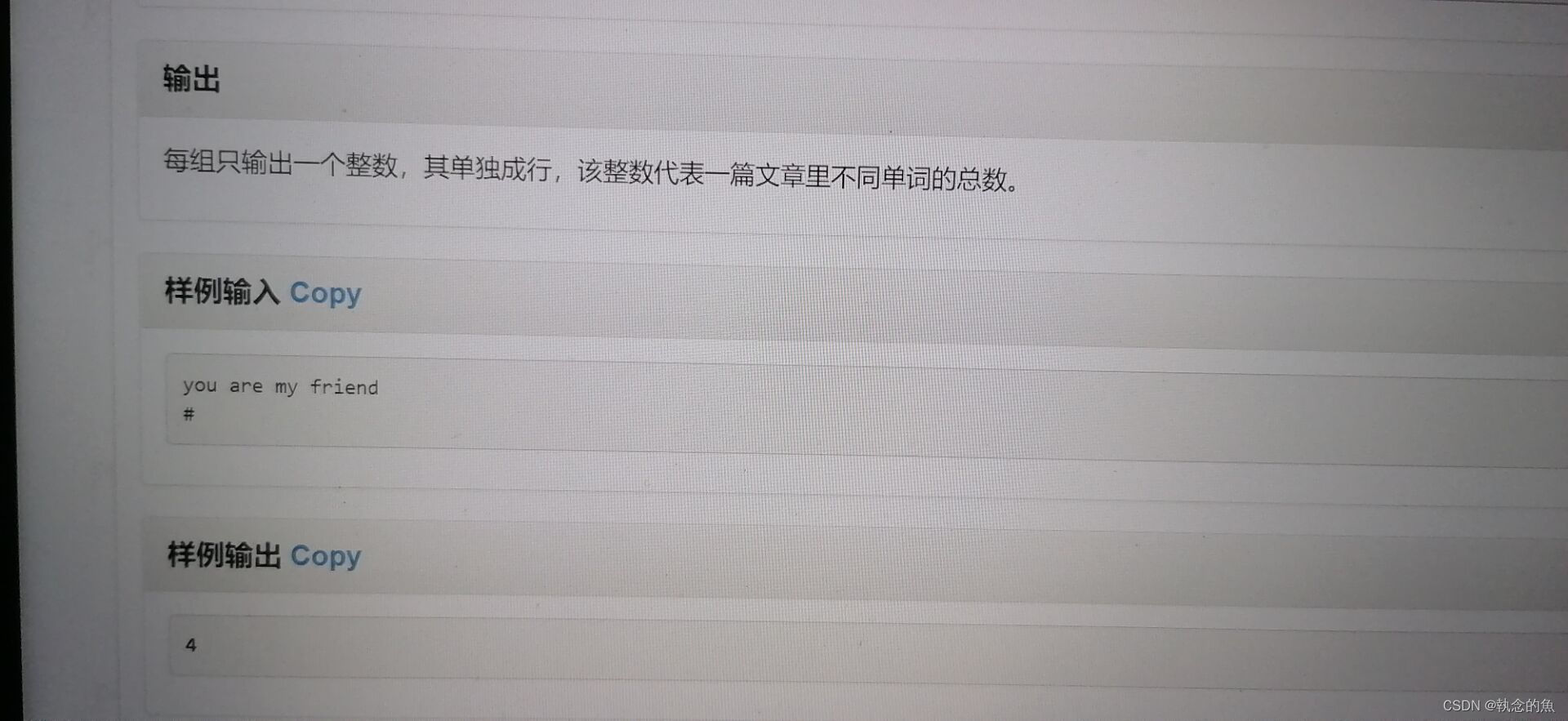
疑惑:
不明白下列代码为什么不正确。ps:系统没让看报错
import collections
keyword = '#' # 声名一个字符串等于‘#’
str_split2 = [] # 声名一个空列表2
while True:
str = input() # 输入字符串
str_split1 = str.split(' ') # 将字符串切片后存入列表1
if len(str_split1) < 1000: # 判断列表1的长度
for i in range(len(str_split1)): # 遍历列表1
var = str_split1[i] # 将列表1的值取出
if i==0 and str_split1[0] == keyword:
break
if str_split1[i] == keyword or str_split1[i] == ' ' or len(var) > 30: #判断列表1的值 :1是否等于‘#’ ,2是否值为空 , 3是否值的长度>30
var = '' # 清空var
break # 跳出for循环
else:
str_split2.append(str_split1[i]) # 将列表1的值添加到列表2
temp_str = collections.Counter(str_split2).most_common() # 统计列表1中的前N项元素保存到临时列表
print(len(temp_str)) # 打印临时列表的长度
str = '' # 清空str
str_split1.clear() # 清空列表1
str_split2.clear() # 清空列表2
temp_str.clear() # 清空临时列表
else:
break题目解决方案:
题目的正确代码如下
st = ''
str_split2 = []
while st != '#':
st = input()
str_split1 = st.split(' ')
if len(str_split1) < 1000 and str_split1[0] != '#':
for i in range(len(str_split1)):
if str_split1[i] == '#' or str_split1[i] == '' or len(str_split1[i]) > 30 or str_split1[i] in str_split2:
continue
else:
str_split2.append(str_split1[i])
print(len(str_split2))
str_split2.clear()
else:
str_split1.clear()使用pyminifier压缩过后的题目解析源码
st=''
f=input
e=len
p=range
J=print
m=[]
while st!='#':
st=f()
V=st.split(' ')
if e(V)<1000 and V[0]!='#':
for i in p(e(V)):
if V[i]=='#' or V[i]=='' or e(V[i])>30 or V[i]in m:
continue
else:
m.append(V[i])
J(e(m))
m.clear()
else:
V.clear()疑惑解决方案:
暂无















 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









