







Hierarchical Text-Conditional Image Generation with CLIP Latents
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
像 CLIP 这样的对比模型已被证明可以学习捕获语义和风格的强大图像表示。 为了利用这些表示来生成图像,我们提出了一个两阶段模型:先验模型根据给定的文本标题生成 CLIP 图像嵌入,解码器生成以图像嵌入为条件的图像。 我们表明,显式生成图像表示可以提高图像多样性,同时将照片真实性和标题相似性的损失降至最低。 我们以图像表示为条件的解码器还可以生成图像的变体,保留其语义和风格,同时改变图像表示中缺少的非必要细节。 此外,CLIP 的联合嵌入空间能够以零样本方式进行语言引导的图像操作。 我们使用扩散模型作为解码器,并对先验模型使用自回归模型和扩散模型进行实验,发现后者的计算效率更高,并产生更高质量的样本。
1. 简介
计算机视觉的最新进展,是在从互联网收集的大型标题图像数据集上扩展模型推动的[10,44,60,39,31,16]。 在这个框架内,CLIP [39] 已经成为一个成功的图像表示学习器。 CLIP 嵌入具有许多理想的特性:它们对图像分布变化具有鲁棒性,具有令人印象深刻的零样本能力,并且经过微调以在各种视觉和语言任务 [45] 上实现最先进的结果。与此同时,扩散模型 [46,48,25] 已成为一种有前景的生成建模框架,推动了图像和视频生成任务的最先进技术 [11,26,24]。 为了获得最佳结果,扩散模型利用了一种引导技术 [11, 24],该技术以牺牲样本多样性为代价来提高样本保真度(对于图像、真实感)。
在这项工作中,我们结合这两种方法来解决文本条件图像生成问题。 我们首先训练扩散解码器来反转 CLIP 图像编码器。 我们的反转器是不确定(non-deterministic)的,并且可以生成与给定图像嵌入相对应的多个图像。 编码器及其近似逆(解码器)的存在允许超越文本到图像转换的功能。 与 GAN 反转 [62, 55] 一样,对输入图像进行编码和解码会产生语义相似的输出图像(图 3)。 我们还可以通过反转图像嵌入的插值,从而在输入图像之间进行插值(图 4)。 然而,使用 CLIP 潜在空间的一个显着优势是能够通过向任何编码文本向量的方向移动来对图像进行语义修改(图 5),而在 GAN 潜在空间中发现这些方向则需要运气和勤奋的手动检查。 此外,图像编码和解码还为我们提供了观察图像的哪些特征被 CLIP 识别或忽略的工具。
为了获得完整的图像生成模型,我们将 CLIP 图像嵌入解码器与先前模型相结合,该模型从给定的文本标题生成可能的 CLIP 图像嵌入。 我们将我们的文本到图像系统与 DALL-E [40] 和 GLIDE [35] 等其他系统进行比较,发现我们的样本在质量上与 GLIDE 相当,但在我们的生成中具有更大的多样性。 我们还开发了在潜在空间中训练扩散先验的方法,并表明它们实现了与自回归先验相当的性能,同时计算效率更高。 我们将完整文本条件图像生成堆栈称为 unCLIP,因为它通过反转 CLIP 图像编码器来生成图像。
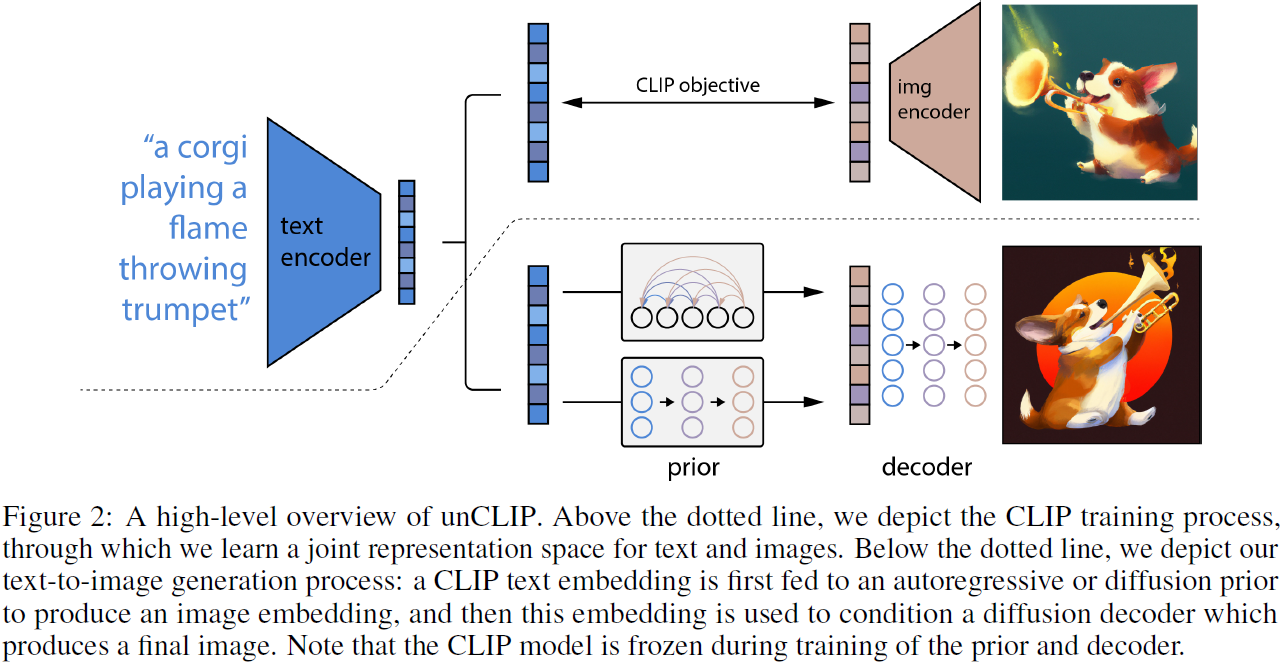
2. 方法
我们的训练数据集由图像 x 及其相应的标题 y 对 (x,y) 组成。 给定图像 x,令 z_i 和 z_t 分别为其 CLIP 图像和文本嵌入。 我们设计生成堆栈以使用两个组件从标题生成图像:
- 一个先验模型 P(z_i | y),生成以标题 y 为条件的 CLIP 图像嵌入 z_i。
- 解码器 P(x | z_i, y) 生成以 CLIP 图像嵌入 z_i(以及可选的文本标题 y)为条件的图像 x。
堆叠这两个组件会获得给定标题 y 的图像 x 的生成模型 P(x|y):
![]()
第一个等式成立,因为 z_i 是 x 的确定性(deterministic)函数。 由于链式法则,第二个等式成立。 因此,我们可以通过首先使用先验对 z_i 进行采样,然后使用解码器对 x 进行采样,从而能够从真实条件分布 P(x|y) 中进行采样。 在以下部分中,我们将描述我们的解码器和先前的堆栈。 有关训练详细信息和超参数,请参阅附录 C。
2.1 解码器
我们使用扩散模型 [25, 48] 来生成以 CLIP 图像嵌入(以及可选的文本标题)为条件的图像。 具体来说,我们修改了 Nichol 等人(2021)描述的架构,通过将 CLIP 嵌入投影并添加到现有的时间步嵌入中,以及将 CLIP 嵌入投影到四个额外的上下文标记中,这些标记连接到 GLIDE 文本编码器的输出序列。 我们保留了原始 GLIDE 模型中存在的文本调节路径,假设它可以允许扩散模型学习 CLIP 无法捕获的自然语言的各个方面(例如变量绑定),但发现它在这方面提供的帮助很少(第 7 节).。
虽然我们可以直接从解码器的条件分布中进行采样,但过去使用扩散模型的工作表明,使用调节信息 [11,24,35] 的指导可以大大提高样本质量。在训练时,通过在 10% 的训练时间随机将 CLIP 嵌入设置为零(或学到的嵌入),并在 50% 的训练时间随机丢弃文本标题,从而实现无分类器指导 [24]。
为了生成高分辨率图像,我们训练了两个扩散上采样器模型 [34, 43]:一个将图像从 64*64 分辨率上采样到 256*256,另一个将这些图像进一步上采样到 1024*1024 分辨率。 为了提高上采样器的鲁棒性,我们在训练期间稍微破坏了条件图像。 对于第一个上采样阶段,我们使用高斯模糊 [43],对于第二个上采样阶段,我们使用更多样化的 BSR 降级 [42, 59]。 为了减少训练计算量并提高数值稳定性,我们遵循 Rombach 等人 [42] 的方法并在目标大小四分之一的随机裁剪图像上训练。 我们在模型中仅使用空间卷积(即没有注意层),并且在推理时直接以目标分辨率应用模型,观察到它很容易推广到更高分辨率。 我们发现以标题为条件的上采样器没有任何好处,并且在没有指导的情况下使用无条件 ADMNet [11]。
2.2 先验
虽然解码器可以反转 CLIP 图像嵌入 z_i 来生成图像 x,但我们需要一个先验模型来从标题 y 生成 z_i,以便能够从文本标题生成图像。 我们为先验模型探索了两个不同的模型类:
- 自回归(AR)先验:CLIP 图像嵌入 z_i 被转换为离散编码序列,并以标题 y 为条件进行自回归预测。
- 扩散先验:使用以标题 y 为条件的高斯扩散模型直接对连续向量 z_i 进行建模。
除了标题之外,我们还可把 CLIP 文本嵌入 z_t 作为先验的条件,因为它是标题的确定性函数。 为了提高样本质量,我们还可以使用 AR 和扩散先验的无分类器指导进行采样,方法是在 10% 的训练时间随机丢弃文本条件信息 。
为了更有效地从 AR 先验中进行训练和采样,我们首先通过应用主成分分析(PCA)[37] 来降低 CLIP 图像嵌入 z_i 的维数。 特别是,我们发现当使用 SAM [15] 训练 CLIP 时,CLIP 表示空间的秩显着降低,同时略微提高了评估指标。 通过仅保留原始 1,024 个主成分中的 319 个主成分,我们能够保留几乎所有信息(即,重建图像表示时的平均均方误差小于 1%)。 应用 PCA 后,我们通过降低特征值大小对主成分进行排序,将 319 个维度中的每个维度量化为 1,024 个离散桶(bucket),并使用带有因果注意掩模的 Transformer [53] 模型预测结果序列。 这使得推理过程中预测的标记数量减少了三倍,并提高了训练稳定性。
我们通过将文本标题和 CLIP 文本嵌入编码为序列的前缀,来作为先验 AR 的条件。 此外,我们在前面添加一个标记,指示文本嵌入和图像嵌入之间的(量化)点积 z_i·z_t。 这使我们能够在更高的点积上调整模型,因为更高的文本图像点积对应于更好地描述图像的标题。 在实践中,我们发现从分布的上半部分采样点积是有益的。(我们测试了 50%、70%、85%、95% 的百分位,发现 50% 在所有实验中都是最佳的。 )
对于扩散先验,我们在一个序列上训练一个带有因果注意掩模的仅解码器 Transformer,该序列按顺序包括:编码文本、CLIP 文本嵌入、扩散时间步嵌入、有噪 CLIP 图像嵌入和最终嵌入(其来自 Transformer 的输出用于预测无噪 CLIP 图像嵌入)。 我们选择不像 AR 先验那样以 z_i·z_t 作为扩散先验条件; 相反,我们通过生成 z_i 的两个样本并选择与 z_t 点积较高的样本来提高采样期间的质量。不使用 Ho 等人的预测公式 [25],我们发现最好训练我们的模型来直接预测无噪 z_i,并在此预测上使用均方误差损失:
![]()
3. 图像处理
我们的方法允许我们将任何给定的图像 x 编码为二分潜在表示 (z_i, x_T),这足以让解码器产生准确的重建。 潜在表示 z_i 描述了 CLIP 识别的图像方面,而潜在表示 x_T 编码了解码器重建 x 所需的所有残差信息。 前者是通过使用 CLIP 图像编码器对图像进行简单编码获得的。 后者是通过使用解码器对 x 应用 DDIM 反演([11] 中的附录 F)获得的,同时以 z_i 为条件。 我们描述了这种二分表示所支持的三种不同类型的操作。
3.1 变化

给定图像 x,我们可以生成具有相同基本内容但在形状和方向等其他方面有所不同的相关图像(图 3)。 为此,我们使用 η > 0 的 DDIM 将解码器应用于二分表示 (z_i, x_T) 进行采样。当 η = 0 时,解码器变为确定性并将重建给定的图像 x。 较大的值 η 将随机性引入连续的采样步骤,导致感知上以原始图像 x 为 “中心” 的变化。 随着 η 增加,这些变化告诉我们在 CLIP 图像嵌入中捕获了哪些信息(因此在样本中保留了哪些信息),以及丢失了哪些信息(从而在样本中发生了变化)。
3.2 插值

还可以混合两个图像 x_1 和 x_2 以获得变化(图 4),遍历 CLIP 嵌入空间中出现在它们之间的所有概念。 为此,我们使用球形插值在它们的 CLIP 嵌入 z_i1 和 z_i2 之间进行旋转,产生从 0 到 1 变化的中间 CLIP 表示
![]()
有两种选项用于沿着轨迹生成中间 DDIM 的潜在表示。 第一个选项涉及在其 DDIM 逆转的潜在变量 x_T1 和 x_T2 之间进行插值
![]()
这会生成一条端点重建 x_1 和 x_2 的轨迹。 第二个选项涉及将轨迹中所有插值的 DDIM 潜在表示固定为随机采样值。 这会导致 x_1 和 x_2 之间产生无限数量的轨迹,尽管这些轨迹的端点通常不再与原始图像重合。 我们在图 4 中使用了这种方法。
3.3 文本差异(Text Diffs)

与其他图像表示模型相比,使用 CLIP 的一个关键优势是它将图像和文本嵌入到同一潜在空间,从而允许我们应用语言引导的图像操作(即文本差异,Text Diffs),如图 5 所示。 为了修改图像以反映新的文本描述 y,我们首先获取其 CLIP 文本嵌入 z_t,以及描述当前图像的标题的 CLIP 文本嵌入 z_t0 (除了描述当前图像,我们还尝试使用 “一张照片” 等虚假标题作为基线,或者将其完全删除。这些也起到了很好的作用)。 然后,我们通过获取它们的差异并进行归一化,计算出文本差异向量 z_d = norm(z_t - z_t0)。 现在,我们可以使用球形插值在图像 CLIP 嵌入 z_i 和文本差异向量 z_d 之间旋转,产生中间 CLIP 表示
![]()
其中 θ 从 0 线性增加到最大值,通常在 [0.25,0.50]。 我们通过解码插值 z_θ 来生成最终输出,将整个轨迹中的基 DDIM 的噪声固定为 x_T。
4. 探测 CLIP 潜在空间

我们的解码器模型允许我们直接可视化 CLIP 图像编码器所看到的内容,从而为探索 CLIP 潜在空间提供了独特的机会。 作为一个示例用例,我们可以回顾 CLIP 做出错误预测的情况,例如印刷攻击(typographic attacks) [20]。 在这些对抗性图像中,一段文本覆盖在一个对象的顶部,这导致 CLIP 预测文本描述的对象,而不是图像中描绘的对象。 这段文本本质上在输出概率方面隐藏了原始对象。 在图 6 中,我们展示了 [20] 中的这种攻击的示例,其中苹果可能被错误分类为 iPod。 令人惊讶的是,我们发现即使 “Granny Smith(绿苹果)” 的预测概率接近于零,我们的解码器仍然以高概率生成苹果图片。 更值得注意的是,该模型从未生成 iPod 的图片,尽管该标题的相对预测概率非常高。

PCA 重建提供了另一种探测 CLIP 潜在空间结构的工具。 在图 7 中,我们采用少量源图像的 CLIP 图像嵌入,并使用逐渐增加的 PCA 维度来重建它们,然后使用我们的解码器在固定种子上使用 DDIM 来可视化重建的图像嵌入。 这使我们能够看到不同维度编码的语义信息。 我们观察到,早期的 PCA 维度保留了粗粒度的语义信息,例如场景中的对象类型,而后期的 PCA 维度则编码更细粒度的细节,例如对象的形状和确切类型。 例如,在第一个场景中,较早的维度似乎编码 “有食物,可能还存在一个容器”,而较晚的维度则专门编码西红柿和瓶子。 图 7 还可视化了 AR 先验的建模内容,因为 AR 先验经过训练可以按此顺序明确预测这些主要成分。
5. 文本到图像的生成
5.1 先验的重要性

尽管我们训练先验来从标题生成 CLIP 图像嵌入,但先验对于标题到图像的生成并不是严格必要的。
- 我们的解码器可以同时以 CLIP 图像嵌入和标题为条件,但在训练期间,CLIP 图像嵌入会在 5% 的时间被丢弃 ,以便实现无分类器指导。 因此,在采样时,我们可以仅以标题为条件,尽管这不如完全以这种方式训练的模型(该模型是 GLIDE,我们在 5.2 和 5.3 节中与 GLIDE 进行了彻底的比较)。
- 另一种可能性是向解码器提供 CLIP 文本嵌入,就好像它是图像嵌入一样,如之前观察到的 [61, 54]。
- 图8的前两行描述了通过这两种方式获得的样本; 第三行描述了先验获得的样本。 仅以标题作为解码器的条件显然是最糟糕的,但以文本嵌入为条件的零样本(zero-shot)确实会产生合理的结果。
- 基于这一观察,另一种方法是训练解码器以 CLIP 文本嵌入 [9] 而不是 CLIP 图像嵌入为条件(尽管我们将失去第 4 节中提到的功能)。
为了量化这些替代方法的有效性,我们训练了两个模型:一个以 CLIP 文本嵌入为条件的小型解码器,以及一个小型 unCLIP 堆栈(扩散先验和解码器)。 然后,我们比较来自文本嵌入解码器的样本、来自 unCLIP 堆栈的样本以及通过将文本嵌入输入到 unCLIP 解码器零样本获得的样本,遍历所有模型的指导尺度。 我们发现这些方法在测试集上的 FID 分别为 9.16、7.99 和 16.55,这表明 unCLIP 方法是最好的。 我们还对前两个设置进行了人工评估,使用我们的人工评估代理模型(附录 A)遍历了每个设置的采样超参数。 我们发现,在照片真实感方面,57.0% ± 3.1% 的人更偏向完整的 unCLIP 堆栈,在字幕相似性方面,53.1% ± 3.1% 的人偏向完整的 unCLIP 堆栈。
鉴于先验的重要性,值得评估不同的训练方法。 我们在整个实验中比较了 AR 和扩散先验。 在所有情况下(第 5.2、5.4 和 5.5 节),我们发现在模型大小相当和训练计算量减少的情况下,扩散先验优于 AR 先验。
5.2 人类评估

我们在图 1 中观察到 unCLIP 能够合成复杂、逼真的图像。 虽然我们可以使用 FID 将样品质量与过去的模型进行比较,但它并不总是与人类的判断一致。 为了更好地衡量我们系统的生成能力,我们进行了系统的人工评估,比较了 unCLIP 和 GLIDE 的真实感、标题相似性和样本多样性。
- 我们遵循 Ramesh 等人、Nichol 等人 [40, 35] 的协议,用于前两个评估:对于照片真实感,用户会看到成对的图像,并且必须选择哪一个看起来更真实; 对于标题相似度,系统会另外提示用户标题,并且必须选择哪个图像与标题更匹配。 在这两项评估中,都有第三个“不确定”选项。
- 对于多样性,我们提出了一种新的评估协议,其中向人类呈现两个 4×4 网格的样本,并且必须选择哪个更多样化(还有第三个选项,“不确定”)。 对于此评估,我们使用 MS-COCO 验证集中的 1,000 个标题生成样本网格,并始终比较相同标题的样本网格。
- 在进行人类比较之前,我们使用经过训练作为人类真实感评估代理的 CLIP 线性探针遍历了每个模型的采样超参数(附录 A)。 这些超参数在所有三种类型的评估中都是固定的。
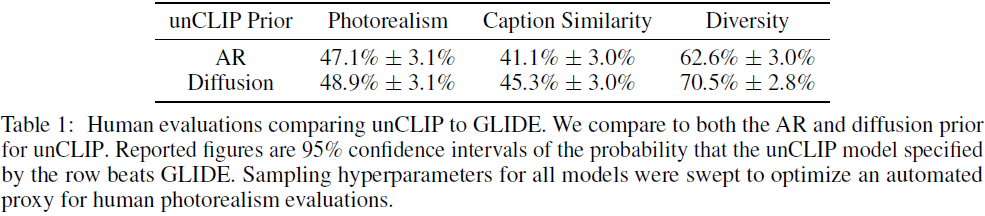
我们在表 1 中展示了我们的结果。
- 一般来说,在与 GLIDE 的成对比较中,扩散先验的表现优于 AR 先验。
- 我们发现,在照片真实感方面,人类仍然稍微喜欢 GLIDE 而不是 unCLIP,但差距很小。
- 即使具有相似的真实感,unCLIP 在多样性方面也比 GLIDE 更受青睐,这凸显了它的优势之一。
5.3 在指导下改进多样性-保真度权衡

与 GLIDE 相比,我们定性地观察到 unCLIP 能够生成更多样化的图像,同时利用引导技术提高样本质量。 要了解原因,请考虑图 9,其中我们增加了 GLIDE 和 unCLIP 的引导比例。 对于 GLIDE,随着我们增加引导比例,语义(摄像机角度、颜色、大小)会收敛,而对于 unCLIP,场景的语义信息被冻结在 CLIP 图像嵌入中,因此在引导解码器时不会崩溃。
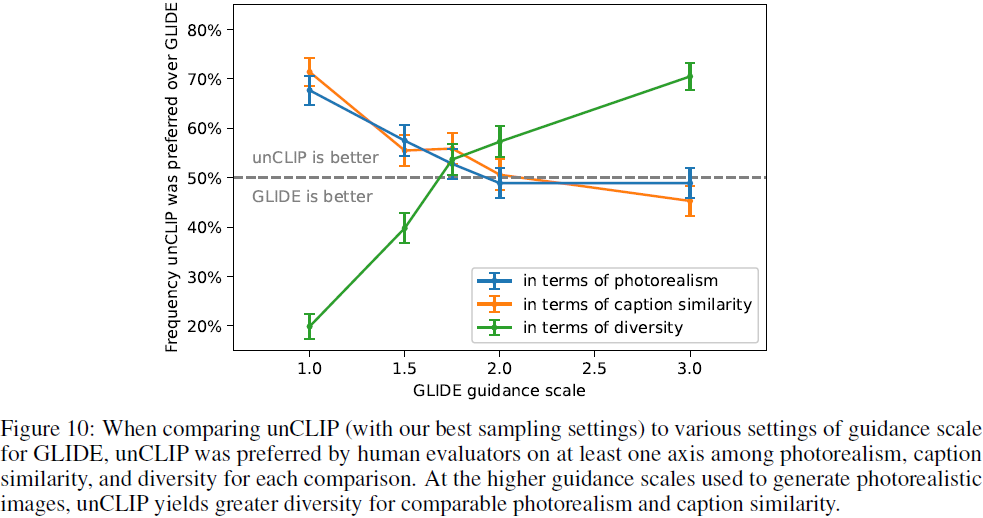
在5.2节中,我们观察到 unCLIP 在保持更多多样性的同时实现了与 GLIDE 类似的真实感,但其标题匹配能力稍差。 人们很自然地会问,是否可以降低 GLIDE 的引导尺度以获得与 unCLIP 相同的多样性水平,同时保持更好的标题匹配。 在图 10 中,我们通过对多个 GLIDE 指导尺度进行人类评估,对这个问题进行了更仔细的研究。 我们发现引导比例为 2.0 的 GLIDE 非常接近 unCLIP 的照片真实感和标题相似性,同时仍然产生较少多样性的样本。
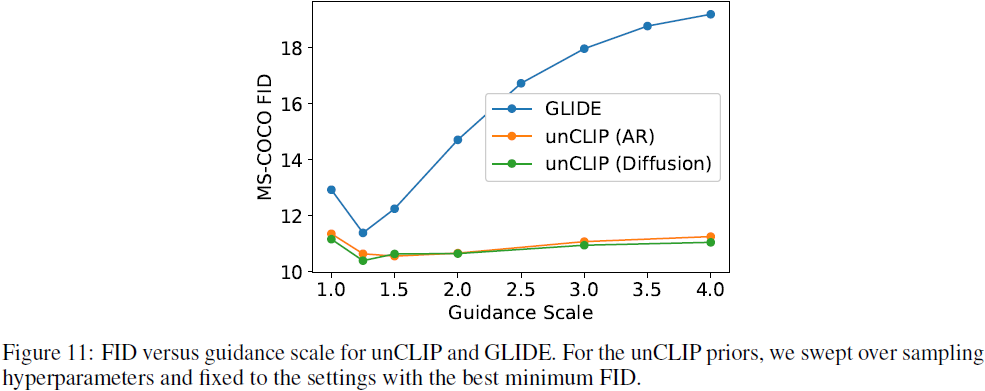
最后,在图 11 中,我们计算 MS-COCO 零样本 FID [23],同时遍历 unCLIP 和 GLIDE 的引导尺度,发现引导对 unCLIP 的 FID 的影响比对 GLIDE 的影响要小得多。 在本次评估中,我们固定了 unCLIP 先验的引导尺度,仅改变解码器的引导尺度。 这再次表明,指导意见对 GLIDE 多样性的伤害远大于 unCLIP,因为 FID 严厉惩罚了非多样性生成。
5.4 MS-COCO 上的比较
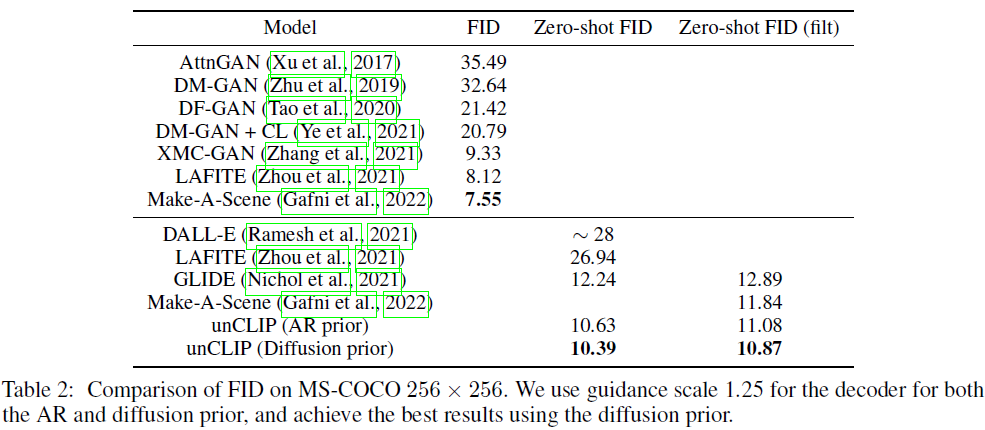
在文本条件图像生成文献中,在 MS-COCO [28] 验证集上评估 FID 已成为标准做法。 我们在表 2 中展示了该基准测试的结果。与 GLIDE 和 DALL-E 一样,unCLIP 不是直接在 MS-COCO 训练集上进行训练,但仍然可以推广到验证集零样本。 我们发现,与其他零样本模型相比,unCLIP 在使用扩散先验采样时实现了新的最先进的 FID 10.39。 在图 12 中,我们直观地将 unCLIP 与 MS-COCO 的多个标题上的各种最新文本条件图像生成模型进行了比较。 我们发现,与其他方法一样,unCLIP 可以生成捕获文本提示的真实场景。

5.5 美学品质对比
我们还执行自动美学质量评估,将 unCLIP 与 GLIDE 进行比较。 我们此次评估的目标是评估每个模型制作艺术插图和照片的效果。 为此,我们使用 GPT-3 [4] 生成了 512 个“艺术” 标题,方法是使用现有艺术作品(真实的和人工智能生成的)的标题进行提示。 接下来,我们使用 AVA 数据集 [33](附录 A)训练 CLIP 线性探针来预测人类审美判断。 对于每个模型和采样超参数集,我们为每个提示生成四张图像,并报告整批 2048 张图像的平均预测审美判断。
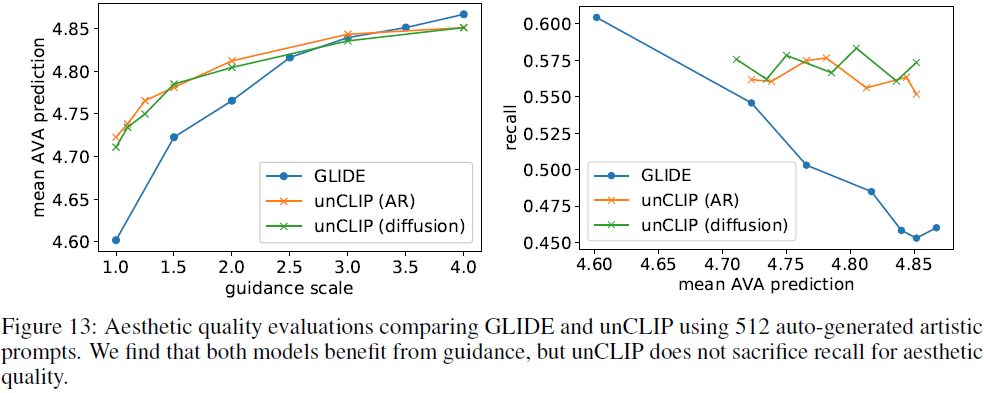
在图 13 中,我们展示了审美质量评估的结果。 我们发现指导提高了 GLIDE 和 unCLIP 的美观质量。 对于unCLIP,我们只引导解码器(我们发现引导会伤害先前的结果)。 我们还根据 Recall (根据训练数据集计算)绘制了美学质量,因为指导通常会导致保真度和多样性之间的权衡。 有趣的是,我们发现引导 unCLIP 不会降低 Recall,同时根据该指标仍然可以提高美学质量。
6. 相关工作
合成图像生成是一个经过充分研究的问题,最流行的无条件图像生成技术也已应用于文本条件设置。
- 之前的许多工作都在公开的图像标题数据集上训练了 GAN [21],以生成文本条件图像样本 [56,63,49,58,57]。
- 其他作品通过在文本标记和图像标记序列上训练自回归 transformer,将 VQ-VAE 方法 [52] 应用于文本条件图像生成 [40,12,1]。
- 最后,一些工作将扩散模型应用于该问题,使用辅助文本编码器训练连续 [35] 或离散 [22] 扩散模型来处理文本输入。
以前的作品利用分层生成过程来创建高质量的合成图像。
- Razavi 等人 [41] 训练了一个多层离散自动编码器,允许他们首先采样粗粒度的潜在代码,然后在采样更高分辨率的潜在代码时将其用作条件信息。
- Child、Vahdat 和 Kautz [5, 50] 使用 VAE 生成图像,该图像具有随分辨率逐渐增加的潜在代码层次结构。
- 在我们工作的同时,Gafni 等人 [17] 把分割掩模作为生成图像模型的条件,允许生成过程首先对图像的语义图进行采样,然后根据以该信息作为生成的图像的条件。
之前的工作已经注意到使用扩散来建模潜在空间的计算优势。
- Preechakul 等人 [38] 提出了一个自动编码器框架,其中扩散模型用于将潜在变量渲染为图像,第二个扩散模型用于生成这些潜在变量(类似于我们的扩散先验)。
- Vahdat 等人 [51] 对 VAE 的潜在空间使用基于分数的模型
- 而 Rombach 等人 [42] 对从 VQGAN [14](如自动编码器)获得的潜在特征使用扩散模型。
自发布以来,CLIP [39] 已被广泛用于引导生成图像模型转向文本提示。
- Galatolo 等人、Patashnik 等人、Murdock、Gal 等人 [19,36,32,18] 使用 CLIP 模型的梯度来指导 GAN。
- 对于扩散模型,Dhariwal 和 Nichol [11] 引入了分类器指导,作为一种使用在有噪图像上训练的分类器的梯度来引导模型走向更高质量的生成的方法。
- Nichol 等人 [35] 在噪声图像上训练 CLIP 模型并指导文本条件扩散模型
- 而 Crowson, Crowson [7, 8] 使用无噪 CLIP 模型来指导无条件或类条件扩散模型
- Ho 和 Salimans [24] 引入了无分类器指导,并表明人们可以在有或没有条件信息的情况下根据模型的预测隐式地执行指导,从而消除了对分类器的需要。Nichol 等人 [35] 表明,在文本条件图像生成方面,无分类器指导比 CLIP 指导更有效。
之前的几项工作已经训练了直接以 CLIP 嵌入为条件的生成图像模型。
- Zhou 等人 [61] 以随机扰动的 CLIP 图像嵌入作为 GAN 模型的条件,发现这些模型可以推广到 CLIP 文本嵌入以生成文本条件图像。
- Crowson [9] 训练了以 CLIP 文本嵌入为条件的扩散模型,允许直接生成文本条件图像。
- Wang 等人 [54] 训练了一个以 CLIP 图像嵌入为条件的自回归生成模型,发现它可以很好地推广到 CLIP 文本嵌入,足以允许文本条件图像合成。
Bordes 等人 [3] 训练以对比模型的图像表示作为条件的扩散模型。 虽然扩散模型本身无法无条件生成图像,但作者尝试了一种简单的两阶段图像生成方法,即采用核密度估计(Kernel Density Estimation)对图像表示进行采样。 通过将这些生成的表示输入扩散模型,他们可以以类似于我们提出的技术的方式生成端到端的图像。 然而,我们的工作在两个方面与此不同:首先,我们使用多模态对比表示而不是仅图像表示; 其次,我们在生成层次结构的第一阶段采用更强大的生成模型,并且这些生成模型以文本为条件。
7. 限制和风险



尽管以 CLIP 嵌入作为图像生成的条件可以提高多样性,但这种选择确实存在一定的局限性。 特别是,unCLIP 在将属性绑定到对象方面比相应的 GLIDE 模型更差。 在图 14 中,我们发现 unCLIP 比 GLIDE 更困难,因为它必须将两个单独的对象(立方体)绑定到两个单独的属性(颜色)。 我们假设发生这种情况是因为 CLIP 嵌入本身没有显式地将属性绑定到对象,并且发现解码器的重建经常混淆属性和对象,如图 15 所示。一个类似且可能相关的问题是 unCLIP 难以生成连贯的文本,如图 16 所示; CLIP 嵌入可能无法精确编码渲染文本的拼写信息。 这个问题可能会变得更糟,因为我们使用的 BPE 编码模糊了模型中标题单词的拼写,因此模型需要独立查看训练图像中写出的每个标记才能学习渲染它。

我们还注意到,我们的堆栈仍然很难在复杂场景中生成细节(图 17)。 我们假设这是我们的解码器层次结构的限制,以 64*64 的基本分辨率生成图像,然后对其进行上采样。 以更高的基础分辨率训练我们的 unCLIP 解码器应该能够缓解这一问题,但代价是额外的训练和推理计算。
正如 GLIDE 论文中所讨论的,图像生成模型存在与欺骗性和其他有害内容相关的风险。 unCLIP 的性能改进还提高了 GLIDE 的风险状况。 随着技术的成熟,人工智能生成的输出留下的痕迹和指示越来越少,更容易将生成的图像误认为是真实的图像,反之亦然。 还需要更多研究架构的变化如何改变模型学习训练数据偏差的方式。
应根据特定的部署环境评估这些模型的风险,其中包括训练数据、到位的护栏(guardrails in place)、部署空间以及谁有权访问。 Mishkin 等人 [30] 在 DALL·E2 Preview 平台(unCLIP 模型的首次部署)背景下对这些问题进行了初步分析。 。
参考
Ramesh A, Dhariwal P, Nichol A, et al. Hierarchical text-conditional image generation with clip latents[J]. arXiv preprint arXiv:2204.06125, 2022, 1(2): 3.
S. 总结
S.1 主要思想
本文提出了一个两阶段模型:先验模型根据给定的文本标题生成 CLIP 图像嵌入,解码器生成以 CLIP 图像嵌入为条件的图像。该方法可以提高图像多样性,同时将照片真实性和标题相似性的损失降至最低。
CLIP 潜在空间的一个显着优势是能够通过向任何编码文本向量的方向移动来对图像进行语义修改,而在 GAN 潜在空间中发现这些方向则需要运气和勤奋的手动检查。
S.2 方法
先验。本文为先验模型探索了两个不同的模型类:
- 自回归先验:CLIP 图像嵌入被转换为离散编码序列,并以标题为条件进行自回归预测。
- 扩散先验:使用以标题为条件的高斯扩散模型直接对连续向量(CLIP 图像嵌入)进行建模。
除了标题之外,还可把 CLIP 文本嵌入 z_t 作为先验的条件,因为它是标题的确定性函数。
解码器。本文使用扩散模型来生成以 CLIP 图像嵌入(以及可选的文本标题)为条件的图像。
S.3 应用
本文的方法可将任何给定的图像 x 编码为二分潜在表示 (z_i, x_T):
- 前者是通过使用 CLIP 图像编码器对图像进行简单编码获得的,描述了 CLIP 识别的图像方面。
- 后者是通过使用解码器对图像应用 DDIM 反演(同时以 z_i 为条件)获得的,编码了解码器重建图像所需的所有残差信息。
变化。使用 η > 0 的 DDIM 将解码器应用于二分表示 (z_i, x_T) 进行采样。随着 η 增加,逐渐将随机性引入连续的采样步骤,导致感知上以原始图像 x 为 “中心” 的变化,这些变化告诉我们在 CLIP 图像嵌入中捕获了哪些信息(因此在样本中保留了哪些信息),以及丢失了哪些信息(从而在样本中发生了变化)。
插值。通过使用球形插值在 CLIP 潜在空间对图像嵌入插值,可以混合图像获得变化。两种选项用于生成中间潜在表示:
- 第一是在图像的潜在表示间插值,生成一条以图像潜在表示为端点的轨迹。
- 第二是将轨迹中所有插值的潜在表示固定为随机采样值,这会导致端点之间产生无限数量的轨迹,且这些轨迹的端点通常不再与原始图像重合。
语言引导的图像操控。
- 首先获取图像 CLIP 文本嵌入,以及描述当前图像的标题的 CLIP 文本嵌入。
- 然后,通过获取它们的差异并进行归一化,计算出文本差异向量。
- 使用球形插值在图像 CLIP 嵌入和文本差异向量 z_d 之间旋转,产生中间 CLIP 表示。
- 通过解码中间 CLIP 表示来生成最终输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









