







Sparse High Rank Adapters
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
低秩适应(LoRA)在最近的生成式 AI 研究中获得了广泛关注。LoRA 的主要优点之一是它能够与预训练模型融合,在推理过程中不增加额外开销。然而,从移动部署的角度来看,我们可以在融合模式(fused mode)中避免推理开销,但失去了快速切换适配器的能力,或者在非融合模式中启用快速切换时会遭受显著(高达 30%)的推理延迟。LoRA 还在同时使用多个适配器时表现出概念丢失的问题。
在本文中,我们提出了稀疏高秩适配器(Sparse High Rank Adapters,SHiRA),一种新的范式,它不会增加推理开销,能够快速切换,并显著减少概念丢失。具体而言,SHiRA 可以通过直接微调基模型权重的 1-2% 来训练,而其他权重保持不变。这导致了一个高度稀疏的适配器,可以在融合模式中直接切换。我们进一步提供了理论和实证见解,说明高稀疏性在 SHiRA 中如何通过减少概念丢失来帮助多适配器融合。我们在 LVM 和 LLM 上的广泛实验表明,仅微调基模型参数的一小部分就足以完成许多任务,同时实现快速切换和多适配器融合。最后,我们提供了基于参数高效微调(PEFT)库的低延迟和内存高效的 SHiRA 实现。该实现的训练速度几乎与 LoRA 相同,同时消耗更少的峰值 GPU 内存,使 SHiRA 易于用于实际应用。
论文地址:https://arxiv.org/abs/2406.13175

1. 介绍
(2021|ICLR,LoRA,秩分解矩阵,更少的可训练参数)LoRA:大语言模型的低秩自适应
尽管 LoRA 取得了成功,但仍存在几个限制。
- 首先,如果将 LoRA 参数融合到相应的预训练基模型权重中,它们会修改整个权重张量。因此,在移动设备上将 LoRA 部署在大型模型(如 LLaMA-1/2(7B+参数)或 Stable Diffusion(1.5B+参数))时,需要在推理过程中更改大量权重。因此,对于需要快速适配器切换的移动场景,现有的低秩方法会带来显著的内存和延迟成本。这是一个主要的部署挑战,因为与大型 GPU 不同,小型 AI 加速器的本地内存有限,无法同时存储所有权重。这些挑战可以通过在非融合模式下运行 LoRA 部分解决;然而,非融合推理相对于基模型可以产生高达 30% 的额外延迟 [1](详见第 2.1 节)。
- 其次,当使用多个并发适配器时,例如结合多种风格迁移适配器,LoRA 有一个众所周知的限制,称为概念丢失(concept loss)。具体而言,已有大量文献 [32, 24, 7] 记录了简单的多 LoRA 适配器加性合并会导致一个或多个适配器的概念丢失。
- 最后,最近的文献还提供了关于高秩适配器价值的重要理论和实证知识。例如,Kalajdzievski [14] 显示,当使用正确的缩放因子时,高秩适配器可以大大优于低秩适配器。这需要进一步调查其他高秩适配器是否会显著优于 LoRA。
鉴于上述问题,我们在本文中解决以下关键问题:
- 如何对融合适配器进行快速切换?
- 是否有一种更简单的多适配器融合解决方案以减少概念丢失?
- 我们能否构建具有高表达能力的高秩适配器,而不会显著增加训练或推理成本?
2. 背景:LoRA 的边缘部署挑战
现有的 LoRA 部署选项有三种:
- 离线地融合适配器然后在设备上部署:这相比基模型改变了大部分权重张量,禁止快速切换,因为这会显著增加 DRAM 流量;
- 保持适配器未融合并在未融合模式下运行推理:这可以帮助快速切换,但会产生显著的额外(高达30%)延迟,如 [1] 所示,因为在推理过程中我们会有 LoRA 分支在前向传递中;
- 使用 Huggingface/Diffusers 管道(pipeline) [1](为服务器级 GPU 构建)进行移动推理。此管道包括加载→融合→推理→解融合→卸载,以切换适配器。此处,未融合的 LoRA-A 和 LoRA-B 权重(见图2(a))首先加载到内存中,然后通过计算 W_new = W + AB 融合到基模型中;此新权重用于推理。要切换适配器,我们可以解融合适配器为 W = W_new − AB,然后卸载现有的 LoRA 权重以加载新权重。我们在附录 A 中提供了进一步的证据,证明这样的管道在边缘设备上是不可行的。这主要是因为边缘设备的内存有限,无法同时存储大型生成模型的所有权重。因此,加载和融合需要在移动设备上逐层进行,这显然会导致大量的推理延迟成本。
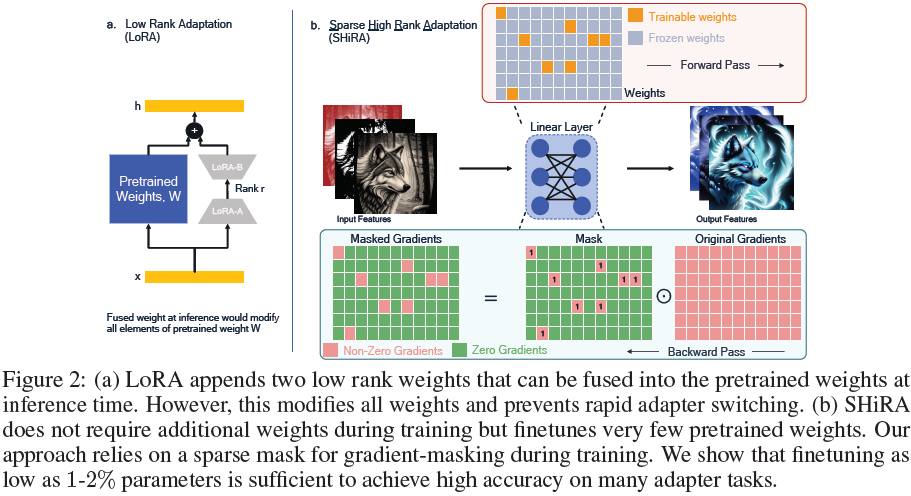
3. 提议的方法
3.1 稀疏高秩适配器(SHiRA)
SHiRA 利用预训练基础模型中高度稀疏的可训练参数。在最简单的形式下,我们提出的适配器可以通过掩蔽(mask)梯度来训练,以便仅更新原始权重的一小部分。具体来说,我们不像 LoRA(见图2(a))那样在前向传递中添加新的权重,而是使现有权重的一小部分可训练(见图2(b)顶部)。为此,我们首先创建一个极其稀疏的(约 98-99%为零)掩码 M∈R^(n×m) = {0,1}^(n×m),其中 n、m 是预训练权重矩阵的维度。然后,M 用于通过哈达玛积掩蔽反向传播中的梯度(见图2(b)底部)。因此,在训练过程中仅有少量参数得到更新,我们的适配器仅由这些稀疏权重组成。我们将在第 3.3 节中提供基于具体梯度掩蔽和另一种低延迟/低内存消耗的基于 PEFT 的 SHiRA 实现。
下面描述了创建掩码 M 的各种策略(更多细节见附录 B)。请注意,每种情况下我们只将 1-2% 的参数设为可训练:
- SHiRA-Struct:在这种结构化掩码中,将权重的特定行或列及其对角线设置为可训练。所有其他行/列均不可训练。对角线使掩码成为高秩,而结构化可训练的行/列(设置为 1 以使梯度流向对应参数)导致一个秩为 1 的适配器。因此,SHiRA-Struct 是高秩但非常稀疏的适配器和秩为 1 适配器的结合。
- SHiRA-Rand:这种掩码是通过随机设置 1-2% 的参数为可训练而获得的。
- SHiRA-WM:在这里,我们根据它们的权重大小(WM,每层权重的绝对值)选择前 K 个参数进行训练。
- SHiRA-Grad:这是基于梯度的掩码。我们首先在一个小的校准集上收集梯度,然后选择接收最高梯度大小的 1-2% 权重。
- SHiRA-SNIP:最后,这种掩码基于剪枝文献中使用的 SNIP 指标 [17]。在这里,我们结合了权重大小和梯度策略,即 SNIP 等于梯度大小乘以权重大小。

3.2 快速适配器切换、多适配器融合和高秩
由于 SHiRA 训练过程中只有很少的基础权重发生变化,我们可以简单地将它们提取出来并存储为稀疏权重及其索引(见图 3(a))。因此,SHiRA 在模型大小上与 LoRA 相当,但在推断时只覆盖了预训练权重的一小部分。相比之下,LoRA 将新权重融合到基础权重中,即 W_new = W + AB,并改变整个权重。请注意,我们实际上不需要融合的 SHiRA,而只需在预训练权重张量中正确的索引处覆盖修改后的值。这使得在资源受限设备上能够快速切换。
为了验证 SHiRA 在推断时确实比 LoRA 提供了快速切换的好处,我们提供了一种基于 scatter_op 的优化实现,用于覆盖基础模型权重而不像 LoRA 那样融合它们。我们展示,在 CPU 上,与等效的 LoRA 融合相比,SHiRA 适配器的权重加载速度可以提高多达 10 倍(见附录 C 和图 7)。
接下来,我们讨论 SHiRA 中的多适配器融合。假设我们有两个适配器 A1 和 A2,其稀疏掩码分别为 M1 和 M2。这里有两个重要的方面需要考虑:(i)稀疏性对多适配器设置中适配器之间相对干扰的影响是什么?(ii)是否可能创建某些类型的掩码,使得 SHiRA 权重在推断时几乎正交,从而不会显著干扰彼此?
获得不会相互干扰的适配器对于避免概念丢失至关重要。为此,我们在第 4.2 节中定义了特定的指标来分析各种 SHiRA 策略之间适配器权重的正交性质。我们从理论上证明了至少一种 SHiRA 方法(SHiRA-Struct)实际上可以创建几乎正交的适配器。我们在第 5.2.2 节进一步进行实验证明,SHiRA-Struct 确实在多适配器融合方面优于其他方法。
最后,由于在前向传递中没有低秩权重,我们提出的适配器可以是高秩的,但非常稀疏。我们展示了这种高稀疏性与高秩在理论上的有趣性质,详见下一节。
3.3 内存和延迟高效的SHiRA训练
我们为 SHiRA 创建了两种实现方式:
- 基于反向钩子(backward hook)的梯度掩蔽,将任何训练器转换为 SHiRA 微调(见附录D),
- 基于 PEFT 的实现。如附录 E 所述,基于 PEFT 的 SHiRA 实现消耗的 GPU 峰值内存低于16.63%,训练速度几乎与 LoRA 相似。相比之下,DoRA 相较 LoRA 展示出了内存和训练时间的增加,分别为 40.99% 和 28.9%。
4. SHiRA 的理论见解
4.1 稀疏高秩适配器
下面我们讨论参数复杂性、学习复杂性、LoRA 与 SHiRA 之间的类比,以及从秩和稀疏性的角度来看其优化属性。
引理 4.1。SHiRA 的参数复杂性和学习复杂性等于适配器中非零元素的数量。
附录 F.1 提供了证明。这个引理表明,尽管 SHiRA 具有高秩属性,但其收敛所需的数据集规模并不需要显著增大。
引理 4.2。如果我们指定一个稀疏因子,LoRA 可以看作是 SHiRA 的 r 秩近似,其近似误差边界取决于 SHiRA 适配器的第 (r+1) 个奇异值的平方 σ^2_(r+1)。
上述引理在第 F.2 节中得到证明。由于这个引理,任何大小为 (m, n) 的 r 秩 LoRA 适配器可以被视为具有 mr + rn 个非零元素的 SHiRA 适配器的近似。
引理 4.3。SHiRA 的缩放因子与适配器的秩无关,可以设为 1。
请参阅附录 F.3 中的证明。引理 4.3 表明,我们不需要缩放因子来稳定训练,因此不需要像LoRA [11] 或 LoRA+ [9] 那样为独立的 A 和 B 矩阵设置额外的超参数如 α 或独立学习率。值得注意的是,缩放因子 α 仍然可以在推断时用来调节适配器的强度。
4.2 多适配器融合中的适配器权重正交性
在本节中,我们通过研究 SHiRA 和 LoRA 适配器设计的性质,提供理论和实证见解。
引理 4.4。考虑两个适配器 ΔW1 和 ΔW2。如果其中一个适配器 ΔW1 或 ΔW2 位于另一个的零空间中,那么这些适配器不会进行乘法干扰。 证明见附录 F.4。上述引理意味着,如果两个适配器是正交的,它们可以有效地融合而不会相互干扰。为了分析任意两个适配器权重之间的正交性,我们定义了以下度量指标:
定义 1。适配器权重正交幅度(Adapter Weight Orthogonality Magnitude,AWOM)定义为两个稀疏适配器权重 A1、A2 ∈ R^(n×m) 的乘积 A^T_1 ·A_2 的 l2 范数。AWOM 使我们能够理解乘积 A^T_1 ·A_2 距离零矩阵 O ∈ R^(m×m)(O_(i,j) = {0} ∀i, j)的程度。
定义 2。适配器权重正交比率(Adapter Weight Orthogonality Ratio,AWOR)定义为乘积 A^T_1 ·A_2 的稀疏比率。具体来说,
![]()
其中 m^2 是 A^T_1 ·A_2 中的元素数量。 AWOM 和 AWOR 共同为我们提供了关于适配器权重 A1 和 A2 之间相对正交性的概念。接下来,我们分析至少一种 SHiRA 策略(如 SHiRA-Struct)可以导致近似正交的适配器。回想一下,SHiRA-Struct 适配器在训练时会训练特定的行/列和对角线元素,而将所有其他参数保持不变。因此,在减去预训练权重后,最终训练出的适配器包含了行/列和对角线元素的结构化模式,其余部分为零。现在,不失一般性,考虑一个具有方形 m×m 权重的层的两个 SHiRA-Struct 适配器:
![]()
其中 S1 和 S2 分别是两个不同任务的经过训练的权重行模式,I 是单位矩阵。同时,S1 和 S2 不重叠,例如,它们都有相同数量的非零行,但彼此偏移,以确保它们没有任何公共的训练行。那么,以下结果成立:
引理 4.5。不重叠的 SHiRA-Struct 适配器几乎正交。也就是说,对于不重叠的 SHiRA-Struct 适配器,AWOR 最多是各个适配器稀疏度的总和。由于所有 SHiRA 掩码都非常稀疏,这意味着乘积 A^T_1 ·A_2 中有很多零元素,从而使适配器几乎正交。
附录 F.5 提供了证明。
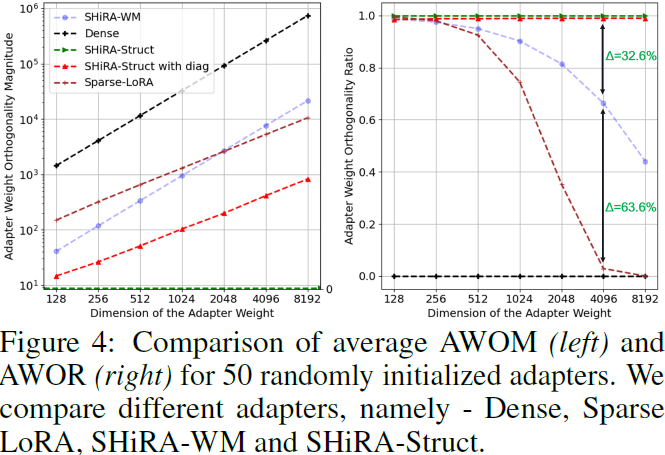
我们在图 4 中展示了各种适配器的正交性质并报告了模拟结果。在我们的实验中,我们计算了各种适配器设计(密集、稀疏 LoRA [10](稀疏 LoRA A 和 B权重)、SHiRA-WM 和 基于 SHiRA-Struct 的适配器)的 AWOM 和 AWOR。
- 如图 4 所示,无论是密集 LoRA 还是稀疏 LoRA,在维度较大的情况下(例如,在 LLMs 中典型的 4096×4096),AWOR 都很低,表明这些适配器权重是非正交的。相反,SHiRA-WM 的 AWOR 要比 LoRA 变体高得多。更有趣的是,SHiRA-Struct 几乎是正交的。
- 请注意,由于高稀疏性,相比于密集对应物,SHiRA 适配器的 AWOM 也往往更低。结合 SHiRA 适配器的 AWOR 比 LoRA 高 63-96% 的稀疏性这一事实,这可能表明,对于 SHiRA 适配器来说,乘积 A^T_1 ·A_2 会更接近于零矩阵,因此可能使它们更接近正交性并减少干扰。
- 最后,尽管我们已经展示了 SHiRA-Struct 的有趣属性,但它仍然是一个秩 1 + 对角线适配器。因此,我们需要权衡单个适配器的性能(这在很大程度上取决于适配器的表达能力)与多适配器融合能力之间的关系。例如,接下来我们将看到,虽然 SHiRA-Struct 对视觉任务很好,但 SHiRA-SNIP 在 LVMs 和 LLMs 中表现良好。
备注 1。这里显示的正交性质可以在适配器输出合并到基础模型之前导致解缠表示。然而,对于不具有正则稀疏模式(如 SHiRA-Struct)的其他 SHiRA 掩码,这种性质并不成立,即使其他 SHiRA 策略相对于 LoRA 权重来说也更正交(例如,见图 4 中 SHiRA-WM 的 AWOR)。重要的是,本分析仅关注适配器权重的正交性,而不涉及子空间的正交性分析。
5. 实验


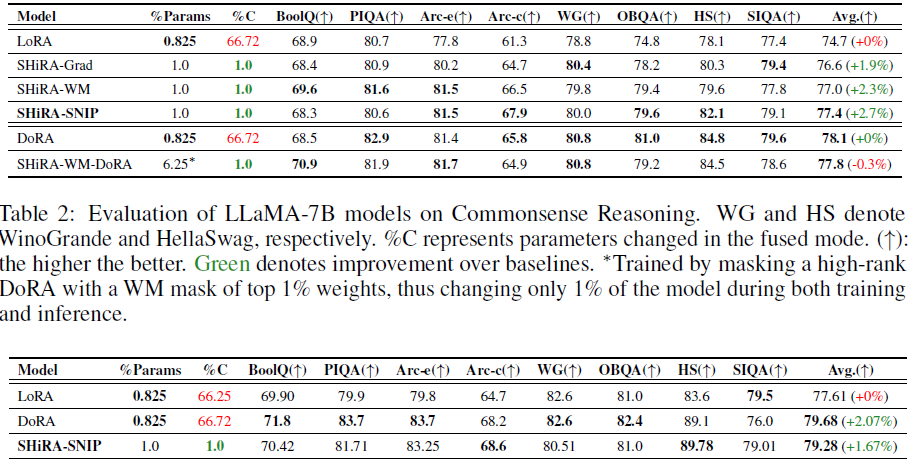

6. 结论
在本文中,我们提出了 SHiRA,这是一种新的高秩适配器范式,展示了即使仅微调预训练生成模型的 1-2% 参数,也足以在许多适配器任务上取得高性能。我们通过理论和实验证明了 SHiRA 快速切换适配器并避免概念损失的能力。此外,我们展示了如何通过特殊设计的稀疏掩码,获得近乎正交的适配器权重,从而实现自然的多适配器融合。我们在多个视觉和语言任务上进行了广泛的单适配器和多适配器实验,以证明 SHiRA 优于 LoRA。我们基于 PEFT 的 SHiRA 训练实现具有高效的延迟和内存管理,训练速度与 LoRA 几乎相同,但峰值 GPU 内存消耗减少了约 16%。最后,在推理阶段,我们提供了一种基于 scatter_op 的方法,可以比等效的 LoRA 融合在 CPU 上加载 SHiRA 快 10 倍,从而展示了我们快速切换的优势。















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









