







DigGAN: Discriminator Gradient Gap Regularization for GAN Training with Limited Data
公众号:EDPJ
目录
3.3 小规模案例研究:对 DigGAN 正则化器和 attractors 的直觉
4.2 在 CIFAR-10 和 CIFAR-100 上的实验结果
4.3 使用 BigGAN 生成更高分辨率:Tiny-ImageNet,CUB-200
4.4 基于 StyleGAN2 的 low-shot 生成
0. 摘要
生成对抗网络 (GAN) 在学习从给定数据集指定的分布中采样方面非常成功,尤其是当给定数据集与其维度相比相当大时。然而,鉴于有限的数据,经典 GAN 一直很困难,而输出正则化(output-regularization)、数据增强(data-augmentation)、使用预训练模型和剪枝(pruning)等策略已被证明可以带来改进。值得注意的是,这些策略的适用性是 1)通常受限于特定设置,例如预训练 GAN 的可用性;或 2) 增加训练时间,例如,在使用剪枝时。相比之下,我们提出了鉴别器梯度间隙正则化 GAN (DigGAN) ,它可以添加到任何现有的 GAN 中。DigGAN 通过鼓励缩小鉴别器预测真实图像和生成的样本的梯度范数之间的差距来改进现有的 GAN。我们观察这该方法以避免 GAN loss 范围内的不良收敛点(attractors),并且我们发现 DigGAN 在可用数据有限时,显着改善 GAN 训练的结果。
1. 简介
在现实生活中,特别是当数据集中样本的维数很高时,训练 GAN 的可用样本可能不足。数据不足可能会显着降低 GAN 的性能。为了解决该问题,最近提出了各种策略,包括使用预训练模型、剪枝和数据增强。然而,尽管改善了结果,这些策略中的每一个也施加了限制。如果数据域保持相似,则使用预训练模型效果最佳。剪枝需要多轮训练来增加神经结构的稀疏性,从而增加了训练成本。数据增强可以增强结果,但在数据不足的情况下效果有限。正则化是一种廉价且可能有效的方法,Tseng 等人最近的工作采用这种方法,控制鉴别器对真实图像和生成图像的预测之间的距离。 然而,由于数据有限,这种正则化并没有显示出显着的改进。
在这篇论文中,我们研究了一种新的正则化来增强 GAN 在有限数据下的训练。我们提出了鉴别器梯度间隙 GAN (DigGAN) 正则化,而不是像之前的工作那样限制鉴别器的输出。尽管已经为 GAN 训练提出了多个基于梯度的正则化器,但这些都没有针对数据有限的 GAN 进行训练。相反,他们专注于使用标准数据训练 GAN 的稳定性。
我们进行了全面的实验,以证明所提出的正则化器的有效性和一致性。首先,我们使用一个合成示例来证明所提出的正则化器对训练的稳定作用,避免原始 GAN 所附加的不良 attractors。 其次,使用最近取得最先进结果的架构,包括 SNGAN、BigGAN 和 StyleGAN2,我们证明了当只有有限的数据可用时,正则化器可以改善结果。
2. 相关工作
在下文中,我们将简要讨论 GAN 变体、GAN 的正则化,以及解决数据有限的 GAN 训练的先前工作。
生成对抗网络。已经提出了许多 GAN 变体来稳定训练并提高生成结果的感知质量。
- 其中,许多变体研究了不同的损失目标。
- 新架构的设计是获得不同 GAN 变体的另一个流行方向。
- 此外,还提出了多种归一化技术。
- 最后,还设计了一些技术来产生更多样化的样本并改善收敛性。
GAN 的正则化。在上述所有 GAN 中,正则化技术被广泛用于稳定训练。
- Gulrajani 等人通过惩罚鉴别器梯度的范数,使其相对于通过在真实数据和生成数据之间插值采样的输入数据点,将鉴别器正则化为 1-Lipschitz(可以理解为一个斜率永远不会超过1的测量函数)。
- Kodali 等人建议只惩罚真实数据周围的高斯流形。
- Roth 等人鼓励鉴别器对真实数据和生成数据的梯度范数为零。
- Mescheder 德等人对梯度惩罚提供了更详细的见解。
- 除了梯度范数,约束判别器是另一种常见机制,权重惩罚也是 GAN 的一种常见正则化方法。
- 与这些方法不同,我们专注于在训练数据有限的情况下改进结果。
使用有限数据训练 GAN。最近,用有限数据训练 GAN 引起了很多关注。数据稀缺导致经典 GAN 训练变得更具挑战性。已经提出了一些方法来提高使用有限数据训练的 GAN 的性能。
- 一种流行的想法是数据增强。Jiang 等人使用生成的数据作为真实数据的“增强”,而其他人则对真实实例进行增强。Chen 等人利用修剪的神经网络来提高性能。
- 一些作品使用了预训练的 GAN,这些 GAN 在迁移到目标域之前使用足够的数据在类似的数据域上学习。
- Yang 等人要求鉴别器进行实例级分类,并将每个单独的真假图像实例区分为一个独立的类别。
- 与我们的方法最密切相关的是 Tseng 等人的工作,他们将对真实数据进行评估的鉴别器与对生成数据进行评估的鉴别器之间的距离进行正则化。
- 我们的方法与这些方法的不同之处在于我们提出了一种新的正则化器,它鼓励 GAN 的鉴别器梯度间隙小。该正则化器与其他解决方案(Tseng 等人的工作除外)正交,可以同时使用。
3. 方法
3.1 回顾生成对抗网络
生成对抗网络 (GAN) 由生成器 G 和鉴别器 D 组成,它们相互对抗。由 θ 参数化的生成器 G(z;θ) 学习将域 Z 上的简单的低维分布 p(z)(例如,高斯)映射到复杂的高维数据分布域 X。鉴别器 D(x) 被训练以区分真实数据 x_R~X 和从生成器获得的综合生成数据 x_F = G(z;θ)。更正式地说,生成器 G 和鉴别器 D 之间的博弈由以下两个损失函数描述,通常也称为非饱和 GAN 损失:
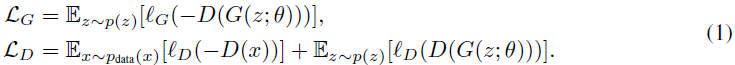
l_G 和 l_D 使用了多个损失函数。例如,Jenson-Shannon-GAN 使用 l_G(t) = l_D(t) = log(1 + exp(t)),hingeGAN 使用 l_G(t) = t 和 l_D (t) =max (0; 1 + t)。
3.2 鉴别器梯度间隙(DigGAN)

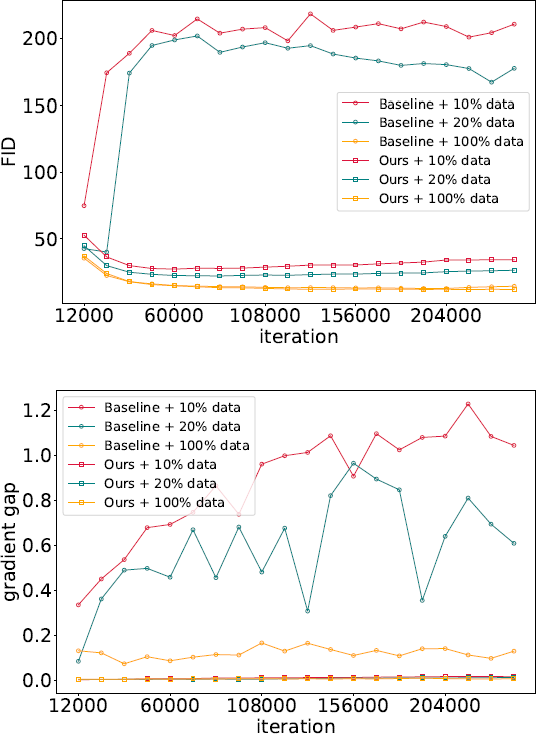
数据有限的 GAN 表现更差。Karras 等人 和 Tseng 等人观察到较少的训练样本会导致 GAN 的性能更差。在实证研究中(如图 1),我们也观察到了这一点。具体来说,我们使用 100%、20% 和 10% CIFAR-100 数据训练 BigGAN。当使用 10% 或 20% 的数据时,FID 分数(越低越好)显着增加(图 1 的右上部分)。随后生成器生成质量较差的图像(参见图 1 第一行中显示的图像)。
观察:大间隙梯度范数。在跨多个数据集的综合实验中,我们观察到,当 GAN 使用较少的数据进行训练时,鉴别器预测真实图像与生成图像的梯度范数之间的差距,即平方距离
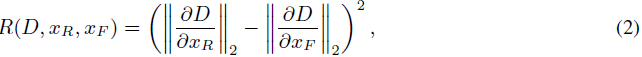
会增加。其中,x_R 和 x_F = G(z;θ) 分别表示训练数据和生成数据。为了可读性,我们通过“DIG”(鉴别器梯度差距)来指代这个差距。这种现象可以在图 1(见右下部分)观察到。
受观察的启发,我们提出了在数据有限时 GAN 训练失败的可能解释:
![]()
我们怀疑鉴别器梯度范数 (DIG) 的巨大差距是使用有限数据训练的 GAN 表现不佳的原因之一。我们在这里提供一个直观理解。我们可以将梯度视为当输入图像发生变化时鉴别器的输出变化率,并将范数视为该变化率的大小。两个范数之间的巨大差距可以解释为,真实图像和生成图像改变时,相应的鉴别器的变化率显着不平衡。此时,鉴别器在真实图像或生成的图像上学习得更快。
为了在有限数据的情况下改进 GAN 的训练,减少 DIG 是很自然的。我们建议使用等式 (2) 作为正则化器,从而在训练期间控制 DIG。反过来,这有助于平衡鉴别器的学习速度。
更具体地说,我们使用等式 (1) 中给出的目标 L_G 训练生成器 G,使用等式 (2) 中所述的额外正则化器训练鉴别器 D,修改等式 (2) 以解决可能的问题,即不同 mini-batch 中的数据可能非常不同,导致正则化器变化很大。为了减少方差,在正则化中对梯度范数项使用移动平均值,平滑因子为 α。形式上,在训练鉴别器 D 时,我们在迭代 t 时使用以下正则化目标:
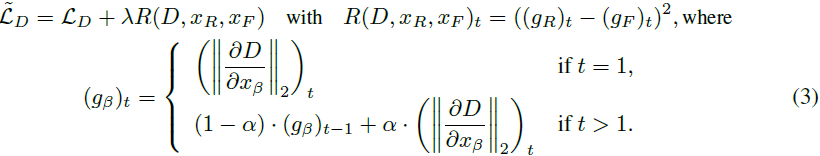
其中,λ 是一个非负的标量超参数,α∈(0,1] 是一个介于 0 和 1(包含)之间的标量超参数,β∈{R,F} 用来指代真实或生成的数据。图 2 总结了计算所提出的正则化器的过程。
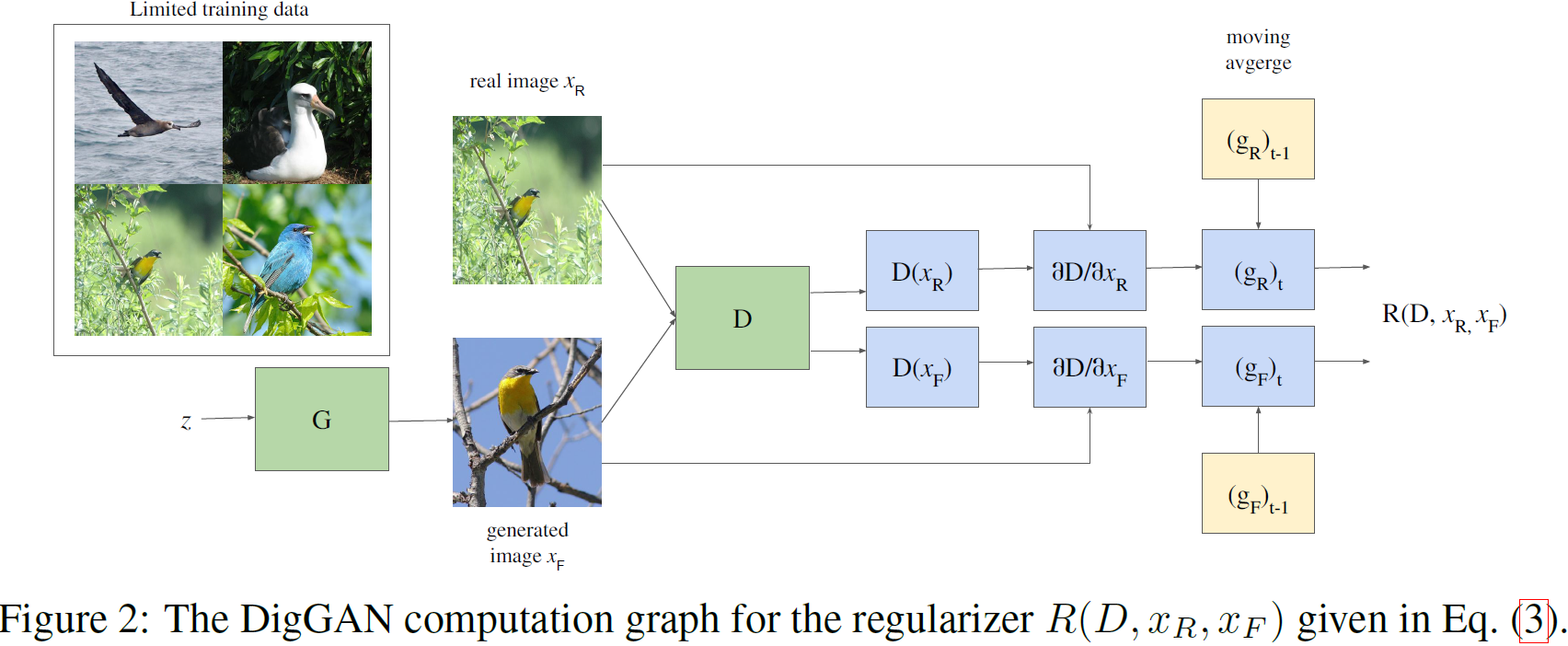
3.3 小规模案例研究:对 DigGAN 正则化器和 attractors 的直觉
在本节中,我们从 attractors 的角度分析了所提出的正则化 R 的优势。为了便于阅读,我们将非正则化 GAN 的局部 attractors 称为“非正则化局部 attractors(unregularized-local-attractors)”。先前的工作认为 GAN 训练具有次优的非正则化局部 attractors,并且当有更多样本时,这个问题变得不那么严重。事实上,随着样本数量趋于无穷大,损失会收敛到凸的总体损失。因此,随着样本数量的减少,我们预计问题会变得更加严重。我们将证明 DigGAN 至少可以通过一个简单的例子来缓解这个问题。
请注意,这四个实验扮演着不同的角色。“回避实验”(实验 3)是实践中自然发生的事情,但正则化器如何帮助避免 attractors 尚不清楚。“逃逸实验”(实验 4)经过精心设计,在随机初始化的实践中很少发生(因为 DigGAN 不会从随机初始化开始就陷入困境)。但是该实验有两个优点:(i)结果很容易证明正则化器的力量;(ii) 结果说明了“回避实验”的潜在机制。
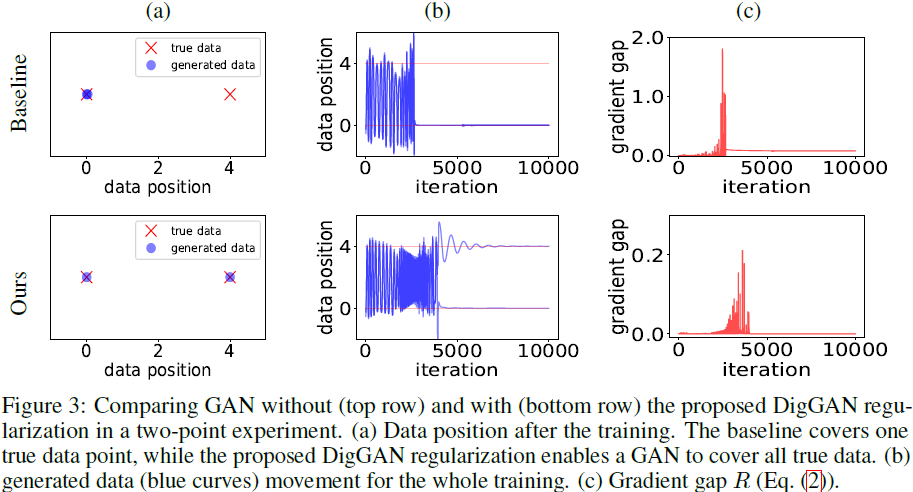
实验 1:普通 GAN 可能会陷入非正则化局部 attractors 中。我们使用随机初始化 D0 和 G0 从头开始训练普通 GAN。我们在训练结束时得到 D1 和 G1。
- 在图 3 中,我们绘制了 (a) 最终训练片段,(b) 一维数据移动,以及 (c) 等式 (2) 中给出的梯度范数间隙 R,数据贯穿整个培训过程。
- 在图 (b) 中,y 轴表示数据位置,而 x 轴表示迭代。生成数据的移动通过蓝色曲线表示,所有真实数据由 y 轴位置 0 和 4 处的两条红色直线表示。
- 我们观察到普通 GAN(图 3 中的第一行)从单模 x = 0(顶行 (a))生成数据,从粗略迭代 3000(顶行 (b))开始卡住了。在 GAN 训练陷入困境之前,基线的梯度差距(顶行 (c))显着增加。
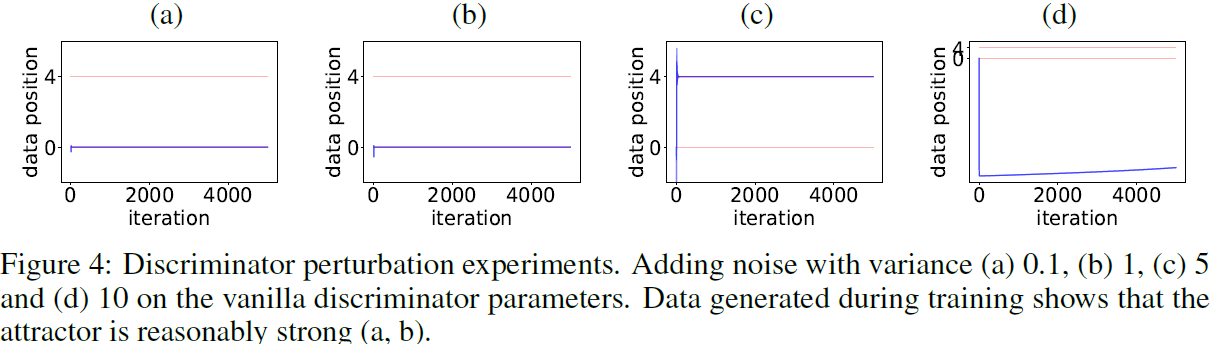
实验 2:普通 GAN 无法逃脱非正则化局部 attractors。在本实验中,我们通过测试向 D1 添加噪声是否有助于 GAN 训练逃逸并收敛到更好的结果,验证最终状态 D1、G1 是普通 GAN 的稳定局部 attractors。我们用四个级别的噪声方差进行实验,分别为 0.1、1、5 和 10。我们在图 4 中可视化数据移动。
- (a)添加噪声 N(0,0.1) 后,GAN 的初始状态与局部 attractors 不同,但 GAN 训练最终收敛到相同的 attractors
- (b)加入N(0,1) 噪声后,GAN 的初始状态与局部 attractors 的差异更大,但GAN训练最终还是收敛到相同的结果
- (c)噪声 N(0,5) 具有足够的强度来帮助 GAN 完全脱离局部 attractors。然而,GAN 训练被另一个不良 attractors 捕获,其中两个生成的数据点在 x = 4 处重叠
- (d)噪声 N(0,10) 太强,无法收敛。
这些实验表明,非正则化局部 attractors 会影响 vanilla GAN 训练。
实验 3:DigGAN 正则化有助于避免非正则化局部 attractors。为了确保比较公平,我们从与实验 1 相同的起点 D0 和 G0 训练 DigGAN。我们在图 3 第二行中可视化与普通 GAN 的比较。
- DigGAN 使 GAN 能够避免局部 attractors 并在相同设置下覆盖两种模式(第二行 (a,b))
- 与卡住之前梯度差距显着增加的普通 GAN 相比,所提出的正则化 R,通过使梯度范数差距保持在较低水平(第二行 (c)),来降低卡住的风险。
实验 4:DigGAN 正则化有助于逃避非正则化局部 attractors。我们证明 DigGAN 正则化可以帮助动态逃避非正则化局部 attractors。为了观察这一点,我们将 GAN 初始化为陷入局部 attractors 的状态,该 attractors 表示为 D2 和 G2。从这个初始化开始,没有正则化的 GAN 仍然被困(见图 4)。相反,具有 DIG 正则化器 R 的 GAN 最终能够逃脱。
4. 实验
4.1 设置
4.2 在 CIFAR-10 和 CIFAR-100 上的实验结果
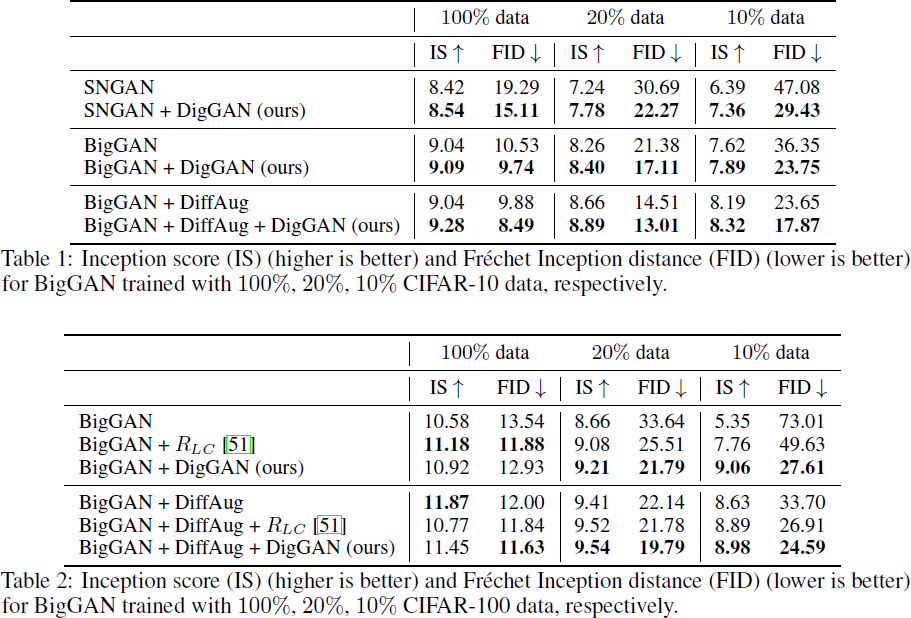
表 1 和表 2 显示了不同数据量条件下的实验结果。有四个观察结果值得注意。
- 首先,无论可用数据量有多大,DigGAN 都可以普遍提高 GAN 的性能。因此,使用正则化似乎不会损害 GAN 训练。
- 其次,我们的正则化在处理稀缺数据时可以产生显着的优势。请注意,对于 20% 和 10% 的 CIFAR-100 数据,我们的正则化分别将基线 FID 提高了 11.85(33.64 vs 21.79)和 45.4(73.01 vs 27.61)。
- 第三,对于 10% 的 CIFAR-100 数据,正则化甚至可以比使用 DiffAug 的 BigGAN 高出 6.09 FID(33.70 vs 27.61)。
- 第四,DigGAN 改进了 Tseng 等人提出的正则化。在 20% 和 10% CIFAR-100 数据的情况下,FID 分别为 3.72(25.51 vs 21.79)和 22.02(49.63 vs 27.61)。
数据增强是 GAN 训练中广泛使用的技巧,与研究的正则化方法正交。为了证明数据增强的正交性,我们遵循 DiffAug 的实验设置,这是一种可区分的数据级增强方法。我们在表 1 和表 2 中报告结果。无论数据可用性如何,我们的技术都可以通过数据增强不断提高性能并改进基线。通过我们的正则化,CIFAR-10 和 CIFAR-100 的 FID 从 23.65 提高到 17.87,从 33.70 提高到 24.59。
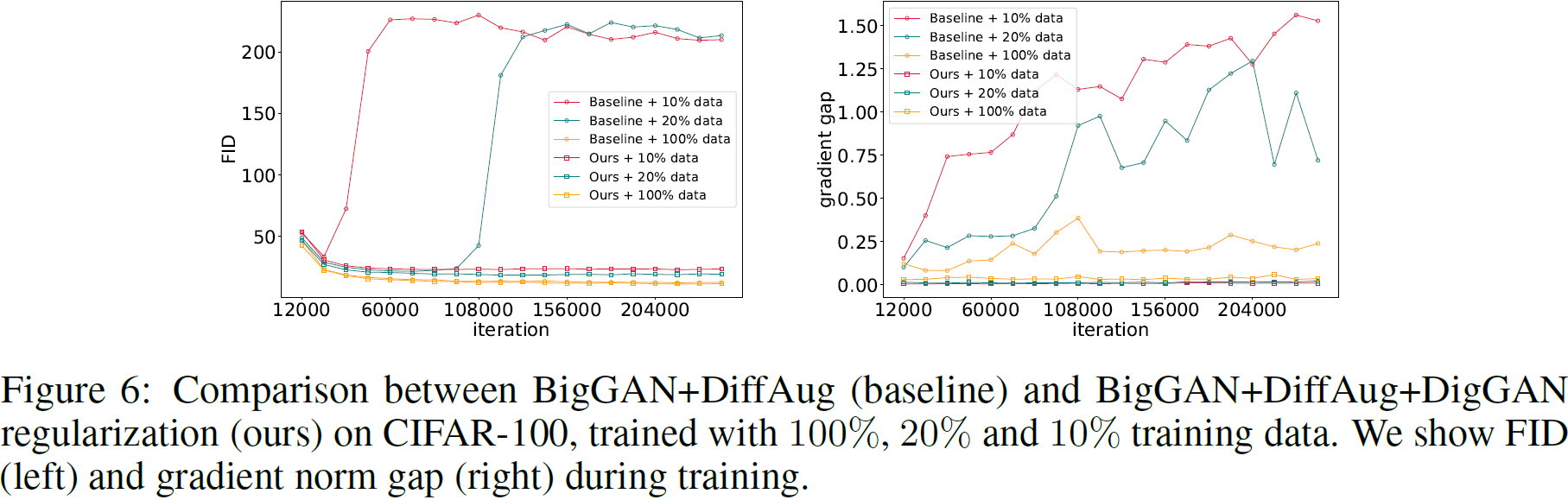
除了图 1,我们还在图 6 中展示了 FID 以及鉴别器对真实图像与使用 DiffAug 生成的 CIFAR-100 图像的预测梯度之间的差距。我们可以得出类似的结论:1)对于基线,差距随着数据越来越稀缺而变得越来越大。2) 我们的 DigGAN 正则化可以将鉴别器梯度间隙控制在较低水平。这些观察结果与我们在第 3 节中的分析一致。

一个可能的问题与生成器对稀缺训练数据的记忆有关。为了验证泛化能力,我们在训练了仅具有 10% 训练数据的生成器后,展示了生成的图像及其来自训练数据的 5 个最近邻(图 7)。我们观察到生成的数据没有出现在训练数据中。这表明该模型不只是记忆。
4.3 使用 BigGAN 生成更高分辨率:Tiny-ImageNet,CUB-200
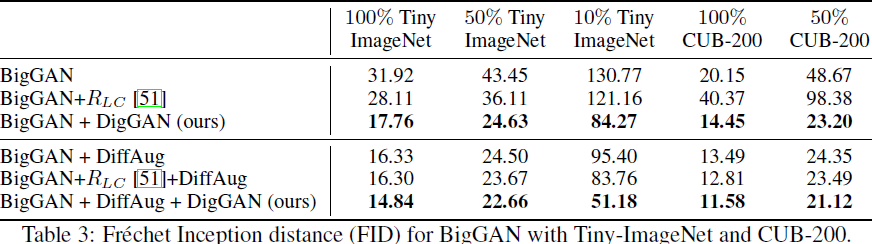
在使用有限数据进行训练时,生成更高分辨率的图像更具挑战性。在本节中,我们将报告我们在 Tiny-ImageNet 和 CUB-200 上的结果。我们与两个基线进行比较:BigGAN 和 R_LC。表 3 列出了所有的定量结果。我们注意到结论与 CIFAR 实验一致。具体来说,1)无论是否存在数据扩充,DigGAN 在使用所有可用数据时都优于基线; 2) DigGAN 的收益随着数据的减少而增加。例如,我们使用 50% Tiny-ImageNet 数据将 R_LC 提高了 1.01 FID(23.67 vs 22.66),并使用 10% Tiny-ImageNet 数据将改进提高到 32.58 FID(83.76 vs 51.18)。
4.4 基于 StyleGAN2 的 low-shot 生成

我们还在 low-shot 生成任务上测试了我们的 DigGAN。我们使用 StyleGAN2+ADA 进行了新的 low-shot 生成实验。我们在100 奥巴马、100 不爽猫(Grumpy Cat)和 AnimalFace 数据集(160 只猫和 389 只狗)上进行实验。 所有数据集的分辨率均为 256 X 256。我们对所有实验使用 600k 图像的最大训练长度。我们将正则化权重设置为 100。我们在表 4 中提供了结果,并表明 DigGAN 在所有数据集上取得了一致的收益。生成的图像如图 8 所示。
4.5 与其他基于梯度的正则化方法的比较
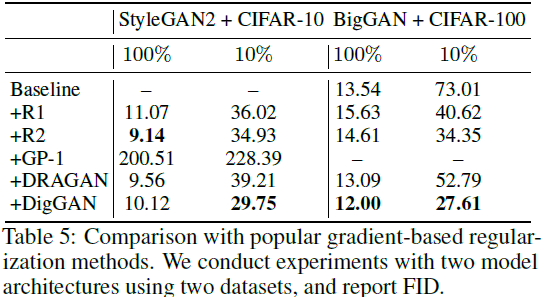
已经为 GAN 提出了几种基于梯度的正则化方法。其中,GP-1、R1、R2 和 DraGAN 是最受欢迎的。然而,GP-0 通常用于 SNGAN 结构,而 R1 通常应用于 StyleGAN2 框架。R2 和 DraGAN 并未在流行的模型架构中进行广泛测试。我们提供了两种设置的比较:StyleGAN+CIFAR10 和 BigGAN+CIFAR100。从表 5,我们观察到:
- GP-1 与 StyleGAN2 不兼容,因为它阻止了 StyleGAN2 的正确训练。此外,它不能应用于 BigGAN,因为这些类不可用于插值数据。
- DigGAN、R1、R2和DraGAN可以应用于StyleGAN2和BigGAN。有了完整的数据集,DigGAN 不一定比其他正则化方法有所改进。然而,当可用的训练数据有限时,DigGAN 能够改进其他基于梯度的正则化。当 10% 的数据可用时,与最佳基线相比,DigGAN 将 FID 提高了 5.16 和 6.74。
4.6 消融研究

正则化强度。我们使用 10% CIFAR-100 数据和 BigGAN 框架对正则化强度进行消融研究。我们遍历正则化强度 λ∈{1, 10, 100, 1k, 10k, 100k},测试模型的灵敏度。我们在图 9 中报告了结果。我们观察到,性能会随着强度的增加而提高,并且越来越好地解决过拟合问题。然而,正如预期的那样,当正则化太强时性能会下降。

配对机制。我们随机抽取真实样本和假样本,无论它们是否属于我们的实验类别。为了研究配对方法对性能的影响,我们将随机配对与其他两种方法进行比较:同一类内配对和基于梯度大小顺序的配对。在这项消融研究中,我们使用 CIFAR 数据和 BigGAN 结构进行比较。我们使用默认的正则化权重。我们在表 6 中报告结果。
对于同类配对机制,每对真实样本和假样本都来自同一类。结果显示在表 6 第 2 行:我们没有观察到随机配对的显着差异。我们认为使用指数移动平均 (EMA) 可确保训练模型不受单对的显着影响。对于梯度幅度配对机制,我们通过对每个批次中的鉴别器对真实图像和生成图像的梯度的范数进行排序,来对真实样本和虚假样本进行配对,以显示真实样本和虚假样本的排列如何影响结果。 结果在表 6 第 3 行。我们观察到梯度幅度配对在两个数据集的 100% 数据可用性下效果更好。 然而,DigGAN 比具有 10% 数据可用性的梯度幅度配对要好得多。我们认为随机配对很重要。
5. 结论和更广泛的影响
我们介绍了 DigGAN,这是一种基于梯度的鉴别器正则化方法,它改进了有限数据的 GAN 训练。 DigGAN 鼓励鉴别器对真实数据和生成数据的梯度的范数之间的微小差异。根据经验,我们观察到当 GAN 训练失败时这种差异很大。我们还证明 DigGAN 正则化减少了局部 attractors 的影响。在各种数据集和架构上,我们展示了一致的结果。
局限性。我们试图从理论的角度分析 DigGAN。但由于执行批处理的方式,对研究损失的理论分析极具挑战性。我们找不到令人信服的有意义的理论结果,并且我们不想包含不增加见解的推导。
社会影响。这项工作既可以产生积极的影响,也可以产生消极的影响。从积极的方面来说,用有限的真实世界数据训练 GAN 对于收集大型数据集成本高昂的领域来说很重要。例如,我们的研究可以使 AI 在罕见病诊断、古董鉴定等方面更加强大。在消极方面,改进的生成方法可以用于生成虚假数据并通过 DeepFakes 传播错误信息。
参考
Fang, Tiantian, Ruoyu Sun, and Alex Schwing. "DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data." arXiv preprint arXiv:2211.14694 (2022).
S. 总结
S.1 核心思想
本文解决问题的是,训练数据稀缺时,如何使 GAN 能有好的生成性能。
本文的核心思想是,为 GAN 的鉴别器的损失函数添加一个正则项,如下所示,
该正则项表示鉴别器对真实数据和生成数据梯度的范数的差距。研究表明,随着该差距的减小,生成图像的 FID 值逐渐减小,即 GAN 的生成性能逐渐增加。
S.2 分析
鉴别器对图像的梯度,实际上是鉴别器对图像的各个属性(特征)求梯度,表示的是对各个属性的变化率。当鉴别器对真实数据和生成数据所有属性的变化率相同时,相应的梯度范数差距最小,此时,生成数据更加贴合真实数据。
如图 9 所示,随着正则化权重的增加,生成数据的 FID 值逐渐减小。但当权重过大时(超过 10k),FID 值会增加。对此,我的理解是,当权重过大时,训练更多的关注正则化项,而忽视鉴别器本身的 loss。由于训练数据的稀缺性,过多的关注正则化项,可能会导致过拟合,降低生成数据的多样性。














 1563
1563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









