







InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
我们介绍 InternLM-XComposer2,这是一款先进的视觉语言模型,擅长于自由形式的文本-图像组合和理解。该模型超越了传统的视觉语言理解, 巧妙地从各种输入中制作交织的文本-图像内容, 如轮廓、详细的文本规范和参考图像,实现了高度可定制的内容创建。InternLM-XComposer2 提出了部分 LoRA (Partial LoRA,PLoRA) 方法,该方法专门将额外的 LoRA 参数应用于图像 token, 以保持预训练语言知识的完整性,找到了精确的视觉理解和具有文学才能的文本组合之间的平衡。实验证明基于 InternLM2-7B 的 InternLM-XComposer2 的卓越性能,能够生成高质量的长文本多模态内容,以及在各种基准测试中表现出色的视觉语言理解性能, 在这些测试中,它不仅显著优于现有的多模态模型, 还在某些评估中与甚至超过了 GPT-4V 和 Gemini Pro。 这突显了它在多模态理解领域的卓越能力。
代码:https://github.com/InternLM/InternLM-XComposer.

3. 方法
3.1. 模型架构
我们提出的模型,InternLM-XComposer2,包括一个视觉编码器和一个语言学习模型(Language Learning Model,LLM)。 这两个组件通过一种创新的部分 LoRA 模块相互连接。给定一组图像和文本, LLM 利用来自视觉编码器的输出作为视觉 token,将文本 token 化为语言 token。这些 token 然后被连接起来形成输入序列。
视觉编码器。我们模型中的视觉编码器被设计从原始图像中提取高级视觉特征。 它是以图像-语言对比的方式进行预训练的(CLIP)。我们的研究结果表明,当与我们的部分 LoRA 模块一起使用时,轻量级视觉模型能够有效地执行。出于效率考虑, 我们选择使用 OpenAI ViT-Large 模型。
大型语言模型。我们采用最近推出的 InternLM-2 作为我们的大型语言模型(Large Language Model,LLM)。该模型拥有出色的多语言能力,并在基准测试中展现了令人印象深刻的结果。在实际应用中,我们使用 InternLM2-7B-Chat-SFT 变体作为我们的 LLM。
部分低秩适应(Partial Low-Rank Adaptation,PLoRA)。在多模态语言学习模型(LLM)领域,一个未充分探讨的领域是不同模态的有效对齐。理想的对齐应该潜在地丰富 LLM 的新模态特定知识,同时保留其固有的能力。当前的方法主要采用两种方法之一:它们要么将视觉 token 和语言 token 视为相等,要么视为完全不同的实体。我们认为第一种方法忽视了模态之间固有的属性差异,而第二种方法会导致相当大的对齐成本。
在追求有效模态对齐的过程中,我们引入了 Partial LoRA,这是一个通用的的插件模块,旨在将新模态的知识与 LLM 对齐。Partial LoRA 受到原始 LoRA 的启发,包含一个专门应用于输入 token 的新模态部分的低秩适应。在我们的具体配置中,Partial LoRA 应用于所有视觉 token。
形式上,对于 LLM 块中的每个线性层 L_0,我们将其权重矩阵表示为 W_0 ∈ R^(C_out × C_in),偏置表示为 B_0 ∈ R^(C_out),其中 C_in 和 C_out 分别是输入和输出的维度。其对应的 Partial LoRA 包含两个低秩矩阵 W_A ∈ R^(C_r × C_in) 和 W_B ∈ R^(C_out × C_r)。给定输入x = [x_v, x_t],我们通过以下方式获得输出特征 ˆx:
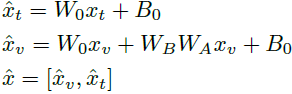
其中 x_v 和 x_t 分别是输入序列的视觉标记和语言标记。
3.2. 预训练
在预训练阶段,LLM 保持不变,同时视觉编码器和 Partial LoRA 都被微调以使视觉 token 与 LLM 对齐。预训练数据经过精心策划,有三个目标:1)一般语义对齐,2)世界知识对齐,3)视觉能力增强。
一般语义对齐。一般语义对齐的目标是赋予 MLLM 理解图像内容的基本能力。例如,MLLM 应该能够识别爱因斯坦的图片代表 ‘一个人’。我们利用来自各种来源的图像标题数据,包括来自 ShareGPT4V-PT 的高质量、详细的标题,以及来自 COCO、NoCaps、TextCaps 等的简洁而精确的标题。 在预训练阶段,我们采用简单的指令:简要/详细描述这张图片。
世界知识对齐。世界知识代表 MLLM 的高级能力。例如,MLLM 应该能够识别上述图中提到的人物为 ‘阿尔伯特·爱因斯坦’,并进一步谈论一些关于他的事情。为了将图像中描绘的世界知识与 LLM 已经获取的知识对齐,我们构建了一个概念数据集。这个数据集是从 InternLMXComposer [95] 中使用的概念数据中精心筛选出来的。鉴于概念数据中的文本只部分描述了图像中的内容,它们之间的关系复杂难以建模,我们采用了更宽泛的指令:告诉我一些关于这张图片的事情。
视觉能力增强。最后,一个先进的 MLLM 需要一些特定的视觉能力,如光学字符识别(OCR),对象定位(grounding,接地),以及对结构化图像(如图表、表格)的理解。为了实现这一点,我们编制了相关的数据集,如表 1 所述,并为训练实施了相应的指令。

由于 Partial LoRA 的设计,LLM 能够适应视觉标记,同时保持其原始的语言处理能力。固定的LLM 还使我们能够直接使用上下文学习性能作为预训练质量的衡量标准。
3.3. 监督微调
预训练阶段将视觉特征与语言进行对齐,使语言学习模型(LLM)能够理解图像的内容。然而,它仍然缺乏有效利用图像信息的能力。为了克服这个限制,我们在随后的监督微调阶段引入了一系列视觉语言任务。此阶段包括两个连续的步骤:多任务训练和自由文本-图像合成。在这个阶段,我们共同微调视觉编码器、LLM 和 Partial LoRA。

多任务训练。如表 2 所示,多任务训练数据集从各种来源汇集而来,旨在为模型提供广泛的能力。每个任务都被构造成一个对话互动,指令使用 GPT-4 进行增强以提高多样性。同时,为了保持原始的语言能力,我们还纳入 InternLM2 的监督微调数据,它构成了总监督微调(Supervised Fine-Tuning,SFT)数据的固定 10%。
自由文本-图像合成。为了进一步增强模型遵循指令和构成自由形式的图文内容的能力,我们使用了纯文本对话语料库和视觉语言对话的数据,如表 2 所述。自由形式的图文合成数据集是根据第 3.4 节中详细介绍的方法构建的。
3.4. 自由文本-图像合成
自由文本-图像合成是指以一种灵活和不受限制的方式将文本内容和视觉元素结合在一起。我们的模型生成交错排列的文本和图像,专门定制以与用户提供的文本要求对齐,这些要求可能包括标题、大纲和写作材料,以及可选的图像资源等元素。
为了促进自由文本-图像合成,我们在四个关键维度上收集了一系列高质量且多样化的内部数据。这些维度包括:
不同的写作风格。我们的数据涵盖了多种写作风格,从学术论文到社交媒体帖子和诗歌,确保了丰富多样的文本和图像内容集合。
灵活的文本编辑。我们的数据集包括大量的文本编辑示例,涵盖了各种修改,如缩短、扩展和改写。
复杂指令遵循。我们还捕捉了遵循复杂指令以创建满足不同需求的内容的实例,如标题和大纲,涵盖了文本和基于图像的组合。
材料定制。我们的收藏扩展到用于个性化内容创建的材料,涵盖了文本和图像,实现了可定制和独特的内容创建体验。
数据在这四个维度上的分布大致相等,比例约为 1:1:1:1。 我们的方法遵循先前的工作 [95],在生成文本内容后识别适合插入图像的位置。我们方法的一个显著区别是,当用户提供自己的图像材料时,这些图像材料将用于插入,而不是依赖于检索到的图像 [95]。我们还观察到,高分辨率图像输入对于文本-图像合成并非必要。因此,在预训练阶段之后,我们选择在自由文本-图像合成的 SFT阶段将图像输入分辨率降低到 224x224。
4. 实验
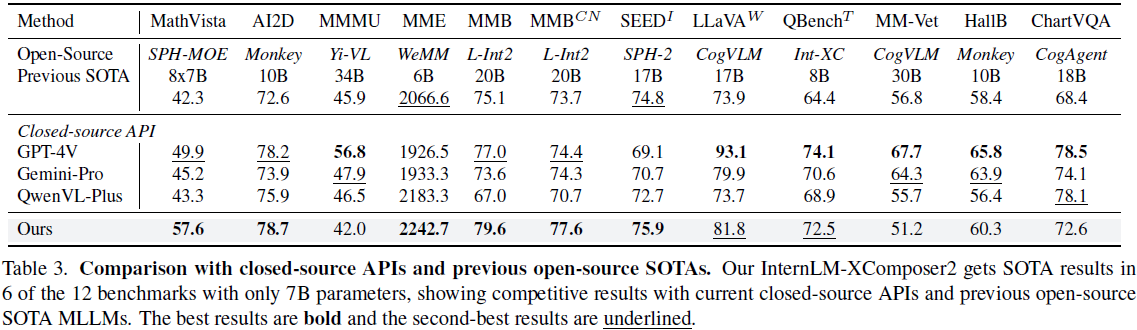
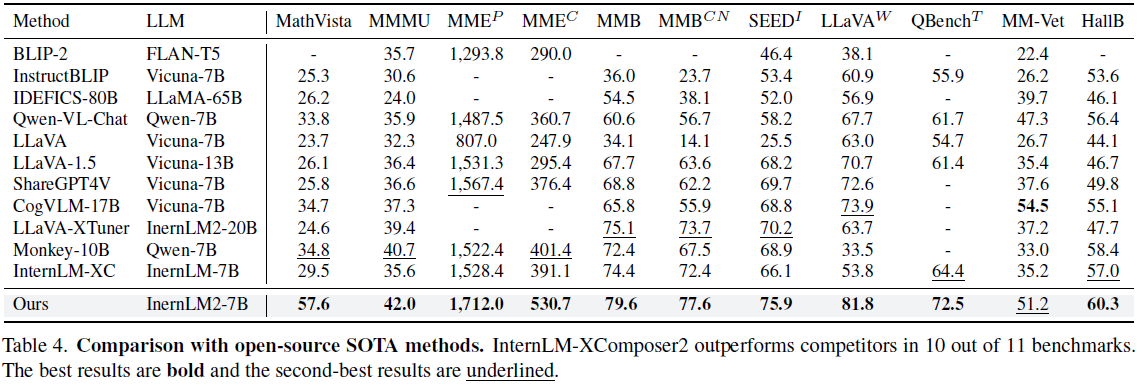
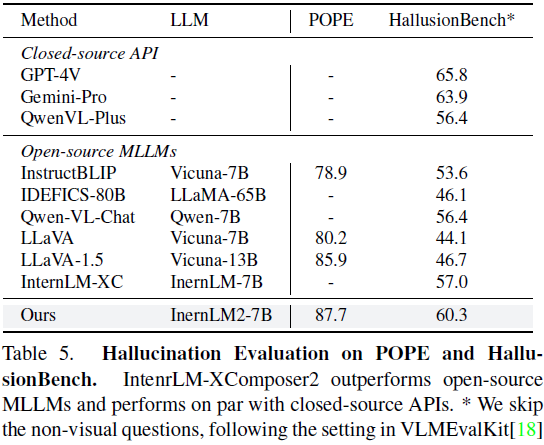


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









