







Factorized Diffusion: Perceptual Illusions by Noise Decomposition
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
给定图像的一个因式分解,将其表示为线性组件的和,我们提出了一种零样本方法,通过扩散模型采样来控制每个单独的组件。例如,我们可以将图像分解为低和高空间频率,并将这些组件以不同的文本提示为条件。这会产生混合图像,其外观会根据观看距离而变化。通过将图像分解为三个频率子带,我们可以生成具有三个提示的混合图像。我们还将图像分解为灰度和彩色组件,来生成外观发生变化(以灰度的方式)的图像,这是在昏暗的光线下自然发生的现象。我们还探索了通过运动模糊核进行分解,产生在运动模糊下外观变化的图像。我们的方法通过使用复合噪声估计进行去噪来工作,该估计由在不同提示条件下的噪声估计组件构建而成。我们还展示了对于某些分解,我们的方法恢复了先前的组合生成和空间控制方法。最后,我们展示了我们可以将我们的方法扩展到从真实图像生成混合图像。我们通过固定一个组件并生成其余组件来做到这一点,有效地解决了一个逆问题。
项目页面:https://dangeng.github.io/factorized_diffusion/


2. 相关工作
计算机视觉错觉。光学错觉(Optical illusions)不仅是娱乐的,还可以作为窥视人类和机器感知的窗口。因此,已经进行了大量工作来开发生成光学错觉的计算方法。在经典的研究中,Oliva 等人介绍了混合图像,这些图像的外观会根据观看距离或持续时间而改变。这些图像利用了人类感知的多尺度处理。通过对齐一个图像的低频分量和另一个图像的高频分量,观察者在远处看到时会感知为前者,而在近处看到时则会感知为后者。相比之下,我们的方法使用扩散模型从头开始生成混合图像,而不是将两个现有图像融合在一起,因此避免了手动对齐步骤和寻找合适图像的需要,同时也减少了产生的伪影。
艺术家和研究人员最近使用文本条件的图像扩散模型生成光学错觉。例如,一个化名的艺术家将 QR 码生成模型改编为图像,使其与目标模板微妙地匹配。尽管这些也是具有多种解释的图像,但它们仅限于二进制掩模模板,并且需要专门调整的模型。Burgert 等人使用分数蒸馏采样生成图像,当从不同方向查看或叠加在一起时,可以匹配其他提示。其他方法如 Tancik 和 Geng 等使用现成的扩散模型生成多视图光学错觉,这些错觉在旋转、翻转、排列、倾斜和颜色反转等变换时会改变外观。这些方法通过在反向扩散过程中多次变换噪声图像,对每个变换版本进行去噪,然后将噪声估计平均在一起来工作。然而,许多类型的变换,如混合图像中考虑的多尺度处理,会扰乱噪声分布。与这些方法类似,我们的工作也改变了反向扩散过程,以产生具有多重解释的图像。但是,我们的方法操纵的是噪声估计而不是嘈杂的图像,使我们能够处理以前的工作无法处理的错觉。请参阅附录 G 以获取更多讨论和结果。
3. 方法
对于图像分解为组件的给定分解,我们的方法允许通过文本调节来控制每个组件。我们通过修改文本到图像扩散模型的采样过程来实现这一点。

3.1 扩散模型
3.2 因式分解扩散
我们方法的概述可以在图 2 中找到。我们的方法通过在反向扩散过程中操纵噪声估计,使估计的不同组件以不同的提示为条件化。给定图像 x ∈ R^(3×H×W) 的分解为 N 个组件的和,

每个 f_i(x) 是一个组件,我们可以将每个组件对应到一个不同的文本提示 yi。在反向扩散过程的每一步,我们不是计算单个噪声估计,而是计算 N 个——每个以一个 yi 为条件——我们用 ϵi = ϵθ(xt, yi, t) 表示。然后,我们构造一个由每个 ϵi 组成的复合噪声估计:
![]()
这个新的噪声估计 ˜ϵ 被用于执行扩散更新步骤。实际上,图像的每个组件以不同的文本提示为条件去噪,从而产生一个干净的图像。我们将这种技术称为因式分解扩散(factorized diffusion)。
正如在第 2 节中所指出的,我们的方法与 Tancik 和 Geng 等人最近的工作类似,都是修改噪声估计以生成视觉错觉。然而,我们的方法不同之处在于,我们只修改噪声估计,而不是扩散模型的输入 xt。因此,我们的方法产生了与之前工作不同类别的感知错觉。请参阅附录 G 以获取更多讨论和结果。
3.3 因式分解扩散的分析
为了直观地解释我们的方法为什么有效,我们假设我们的更新函数 update(·, ·) 是嘈杂图像 xt 和噪声估计 ϵθ 的线性组合,这在常见情况下是成立的 [25, 52]。为了简洁起见,更新函数还取决于 t,我们在此忽略。然后,我们可以将更新步骤分解为
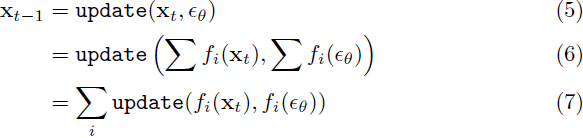
第一个等式是根据更新步骤的定义得到的,第二个等式是应用图像分解得到的,第三个等式是根据更新函数的线性性得到的。方程(7)告诉我们,在 xt 上进行的更新步骤,带有 ϵθ,可以解释为 xt 和 ϵθ 的分量的更新之和。我们的方法可以被理解为对每个分量使用不同的条件。具体地,我们方法使用的更新可以明确写为
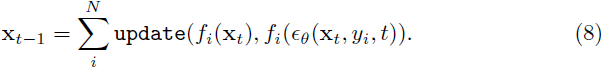
此外,让我们将更新步骤明确写出为
![]()
其中 ωt 和 γt 由方差调度和调度程序确定。然后,如果 f_i 是线性的,我们有
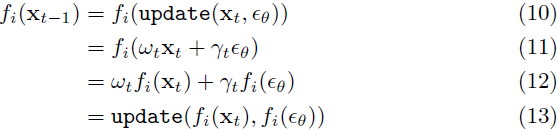
这意味着用 ϵθ 的第 i 个分量更新 xt 的第 i 个分量只会影响 x_(t−1) 的第 i 个分量。
3.4 分解考虑
我们在本文中考虑的分解细节如下。所有分解的结果均在第 4 节中进行了展示和讨论。
空间频率。我们考虑将图像分解为频率子带,并将子带条件于不同的提示,目的是生成混合图像。首先,我们考虑将图像分解为两个组件:
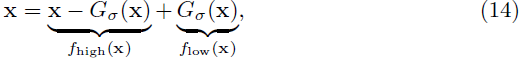
其中 Gσ 是实现为具有标准差 σ 的高斯模糊的低通滤波器,而 x - Gσ(x) 则充当 x 的高通滤波器。对于分解为三个子带,以在图 1 中创建三重混合图像为目标,组件是我们定义的拉普拉斯金字塔的级别,定义如下:
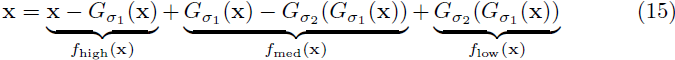
其中 σ1 和 σ2 大致定义了低通、中通和高通的截止频率。
颜色空间。我们还考虑通过颜色空间的分解,目标是创建彩色混合图像——在灰度或彩色中看到时有不同解释的图像。类似于 CIELAB 颜色空间,我们将图像分解为亮度组件 L 和色度组件 ab。 CIELAB 旨在在一个感知上均匀的空间中表示颜色,因此需要 RGB 值的非线性转换。相反,我们使用一个简单的线性分解。我们的 L 分量是所有像素的通道平均值:
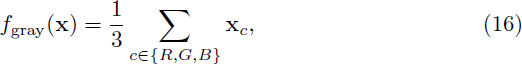
其中 xc 是图像 x 的颜色通道,结果 f_gray(x) 与 x 具有相同的形状。我们将颜色分量定义为残差:
![]()
运动模糊。运动模糊可以建模为与模糊核 K 的卷积。为了产生在模糊时外观改变的图像,我们称之为运动混合图像,我们研究以下分解:
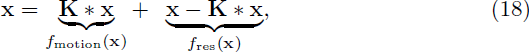
我们将图像分成运动模糊组件和残余组件。我们特别研究简单的恒定速度运动,其中 K 可以被建模为具有非零值行的零矩阵。这也可以被视为将图像分解为定向低频分量和残余分量。
空间分解。虽然我们的主要重点是感知错觉,但我们也考虑将空间掩蔽作为一种分解。给定覆盖整个图像的二进制空间掩蔽 m_i,我们可以使用分解:

其中 ⊙ 表示逐元素乘法,每个 mi ⊙ x 是一个组件。这种分解的效果是在空间上启用提示的控制。这是 MultiDiffusion 的一个特例。我们在附录 E 中讨论了这种联系。
缩放。最后一个有趣的分解形式是 x = Σ^N_(i=1) aᵢx,其中Σᵢ aᵢ = 1。当 aᵢ = 1/N 时,这恢复了 Liu等人的组合扩散方法,其中噪声估计被平均以从多个提示的连接中进行采样。
逆问题。如果我们知道我们生成的图像中必须是其中一个组件,也许是从某个参考图像 x_ref 中提取的,那么我们可以在生成所有其他组件时固定此组件。这使我们能够从真实图像生成混合图像。假设我们想要固定第一个分量,不失一般性。为了做到这一点,我们可以在每个反向过程步骤之后对 xt 进行投影:
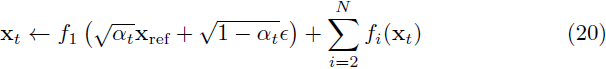
其中 ϵ ∼ N(0, I),αt 由方差调度确定。给定参考图像,f_i 的自变量是正向过程的样本,即 x_ref 在时间步长 t 的具有正确数量噪声的嘈杂版本。基本上,我们投影 xt 以使其第一个分量与 x_ref 的第一个分量匹配。这相当于解决了一个(无噪声的)由 y = f_1(x) 表征(characterized)的逆问题。已经做了大量工作来开发使用扩散模型作为先验的逆问题解决方法,我们方法的这一扩展可以看作是之前工作的简化版本。
4. 结果

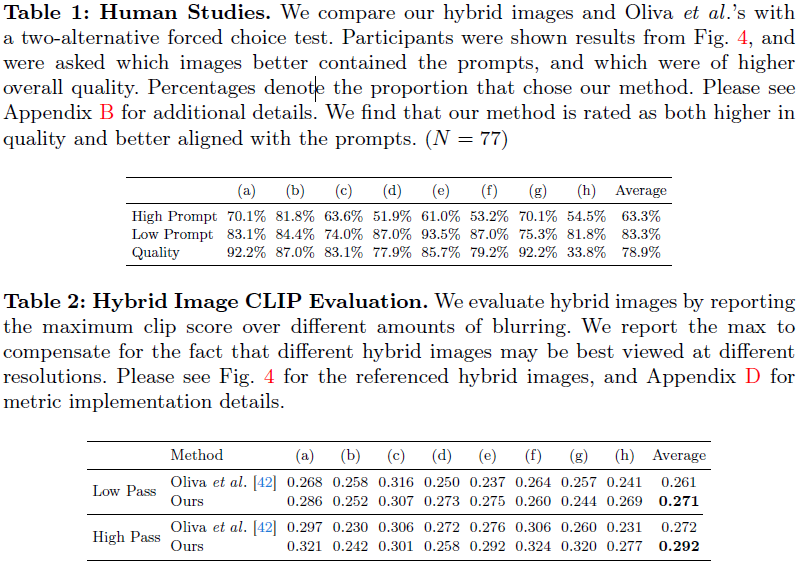



4.4 限制和负面影响
我们方法的一个主要限制是成功率相对较低。虽然我们的方法可以一致地生成很好的图像,但非常高质量的图像较为罕见。这可以从图 9 和图 18 中看出,在这些图中,我们可视化了混合图像、彩色混合图像和运动混合图像的随机样本。我们将这种脆弱性归因于我们的方法产生的图像对于扩散模型来说是高度超出分布的事实。此外,并没有机制能够阻止与一个组件相关联的提示出现在其他组件中。我们方法的另一个失败案例是一个组件的提示可能会主导生成的图像。凭经验,我们方法的成功率可以通过精心选择提示对(请参见附录I以获取更多讨论)或手动调整分解参数来提高,但我们将改善我们方法的鲁棒性的一般方法留给未来的工作。
更好地控制强大的图像合成模型的能力引发了许多社会和道德考虑。我们将我们的方法应用于生成错觉,从某种意义上说,这意味着试图欺骗感知,可能会导致误导性应用。我们认为这些以及其他担忧值得进一步研究和深思。
5. 结论
我们提出了一种零样本方法,通过扩散模型采样,实现了对图像不同组件的控制,并将其应用于创建感知错觉的任务。使用我们的方法,我们合成了混合图像、具有三个提示的混合图像以及新类别的错觉,如彩色混合图像和运动混合图像。我们对我们的方法为何有效进行了分析并提供了直观解释。对于某些图像分解,我们表明我们的方法归结为先前关于组合生成和扩散模型空间控制的工作。最后,我们建立了与逆问题的联系,并利用这一洞察力从真实图像生成混合图像。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









