







Towards Universal Fake Image Detectors that Generalize Across Generative Models
公众号:EDPJ
目录
0. 摘要
随着生成模型的快速增殖,对通用假图像检测器的需求不断增长。 在这项工作中,我们首先表明,现有的范式(包括训练用于真假分类的深度网络)在训练检测 GAN 假图像时无法从较新的生成模型中检测假图像。 经过分析,我们发现生成的分类器经过不对称调整,可以检测伪造图像的模式。 真实的类成为一个 “sink” 类,包含任何非伪造的内容,包括从训练期间无法访问的模型生成的图像。 基于这一发现,我们建议在不学习的情况下执行真假分类; 即,使用未明确训练的特征空间来区分真假图像。 我们使用最近邻和线性探测作为这个想法的实例。 当能够访问大型预训练视觉语言模型的特征空间时,最近邻分类的非常简单的基线在从各种生成模型中检测假图像方面具有令人惊讶的良好泛化能力; 例如,当在未见过的扩散和自回归模型上进行测试时,它比 SoTA 提高了 +15.07 mAP 和 +25.90% acc。 我们的代码、模型和数据可以在 https://github.com/Yuheng-Li/UniversalFakeDetect 找到。
1. 简介
一个常见的范例是将假图像检测构建为基于学习的问题,其中假设假图像和真实图像的训练集可用。 然后训练深度网络来执行真假二元分类。 在测试期间,该模型用于检测测试图像是真实的还是虚假的。 令人印象深刻的是,这种策略使模型具有出色的泛化能力,可以检测同一生成模型系列中不同算法的假图像; 例如,使用 ProGAN 中的真/假图像训练的分类器可以准确地检测 StyleGAN 中的假图像(两者都是 GAN 变体)。 然而,据我们所知,先前的工作尚未彻底探索不同生成模型系列的通用性,特别是对于训练期间未见过的模型; 例如,GAN 假分类器也能够从扩散模型中检测假图像吗? 我们在这项工作中的分析表明,现有方法没有达到那种泛化能力水平。
具体来说,我们发现这些模型以一种相当有趣的方式工作(或不工作)。 每当图像包含特定于用于训练的生成模型(例如 ProGAN)的(低级)指纹时,该图像就会被分类为假图像。 其他任何东西都会被归类为真实的。 这有两个含义:(i)即使扩散模型有自己的指纹,只要它与 GAN 的指纹不太相似,它们的假图像就会被分类为真实图像; (ii) 在将图像分类为真实图像时,分类器似乎并未寻找真实分布的特征; 相反,真正的类变成了“接收器(sink)类”,它主持(host)任何不是 GAN 版本的假图像。 换句话说,这种分类器的决策边界将与特定的假域紧密相连。
我们认为,分类器的决策边界与假图像类的绑定不均匀的原因是分类器很容易锁定区分假图像和真实图像的低级图像伪影。 直观地说,学习识别假图样(pattern)比学习图像真实的所有方式更容易。 为了纠正这种不良行为,我们建议使用未经训练来区分真假图像的特征来执行真假图像分类。 作为这个想法的实例,我们使用在互联网规模的图像文本对上预训练的 CLIP-ViT 模型的固定特征空间进行分类。 我们探索最近邻分类以及对这些特征的线性探测。
我们的经验表明,我们的方法在检测假图像方面可以取得显着更好的泛化能力。 例如,当训练与 ProGAN 相关的真/假图像,并评估未见过的扩散和自回归模型 (LDM+Glide+Guided+DALL-E) 图像时,我们获得了相对于 SoTA 的改进 (i) +15.05mAP 和 +25.90% acc(最近邻)和 (ii) +19.49mAP 和 +23.39% acc(线性探测)。 我们还研究了使特征空间有效用于虚假图像检测的成分。 例如,我们可以使用任何图像编码器的特征空间吗? 我们可以访问的假/真实图像的域是哪一个重要吗? 我们的主要结论是,虽然我们的方法对于用于创建特征库的生成模型的种类是稳健的(例如,GAN 数据可用于检测扩散模型的图像,反之亦然),但需要对图像编码器进行训练,使用互联网规模的数据(例如,ImageNet 不起作用)。
总之,我们的主要贡献是:
- 我们分析了现有的基于深度学习的方法在从未见过的生成模型中检测虚假图像方面的局限性。
- 在实证证明现有方法的无效性之后,我们提出了现有范式可能存在问题的理论
- 我们使用该分析来提出两个非常简单的真/假图像检测基线:最近邻和线性分类。 我们的方法带来了最先进的泛化性能,即使是 Oracle 版本的基线(调整其在测试集上的置信阈值)也无法达到。
- 我们深入研究了我们的方法的关键要素,这是良好的通用性所必需的。
2. 相关工作
合成图像的类型。
- 一个类别涉及更改真实图像的一部分,并且包含可以使用 Adobe 的 Photoshop 工具更改源图像中人物属性的方法,或者可以在源图像/视频用目标域人脸替换原始图像来创建 DeepFakes 的方法。
- 另一种可以选择性地改变真实图像的一部分的最新技术是 DALL-E2,它可以在现有的真实场景(例如办公室)中插入一个对象(例如椅子)。
- 另一类涉及从头开始生成图像所有像素的任何算法。 生成此类图像的输入可以是随机噪声、分类信息、文本提示,甚至可以是图像集合。
- 在这项工作中,我们主要考虑后一类生成的图像,并看看不同的检测方法是否可以将它们分类为假图像。
基于学习的方法也已用于检测被操纵的图像。
- 早期的方法研究了是否可以学习一个可以从同一生成模型中检测其他图像的分类器,后来的工作发现此类分类器不能泛化到从其他模型中检测赝品。
- 因此,学习分类器泛化到其他生成模型的想法开始引起人们的关注。
- 在这方面的工作中,一篇论文提出了一个令人惊讶的简单而有效的解决方案:作者在来自一种 GAN 的真/假图像上训练神经网络,并表明,如果使用适当的训练数据源和数据增强,它也可以检测来自其他 GAN 模型的图像。
- 另一篇论文扩展了这个想法来检测 patch(而不是整个图像)的真/假。
- 另一篇论文研究了一项相关但不同的任务,即预测两个测试图像中哪一个是真实的,哪一个是修改过的(假的)。
- 我们的工作分析了训练神经网络进行虚假图像检测的范式,表明它们的普遍性并没有扩展到未见过的生成模型家族。 利用这一发现,我们展示了未明确学习的特征空间对于假图像检测任务的有效性。
3. 基础
给定一个测试图像,任务是分类它是使用相机自然捕获的(真实图像)还是由生成模型合成的(假图像)。 我们首先讨论此任务的现有范例,对其进行分析得出我们提出的解决方案。
3.1 问题设置
[50] 中的作者使用与一个生成模型相关的图像来训练一个卷积网络 (f),以执行二元真 (0) 与假 (1) 分类的任务。 他们在 LSUN 的 20 个不同对象类别上训练 Pro-GAN,并为每个类别生成 18k 个假图像。real-vs-fake 训练数据集总共由 720k 图像组成(真实类 360k,假类 360k)。 他们选择在 ImageNet 上预训练的 ResNet-50 作为假分类网络,并替换全连接层,用二元交叉熵损失训练网络进行真假分类。 在训练过程中,使用了涉及高斯模糊和 JPEG 压缩的复杂数据增强方案,经验表明这对于泛化至关重要。 经过训练后,网络将用于评估其他生成模型的真实图像和虚假图像。 例如,BigGAN 通过测试其类条件生成图像(FBigGAN)和相应的真实图像(RBigGAN:来自 ImageNet)是否正确分类来进行评估; 即,是否 f(RBigGAN) ≈ 0 和 f(FBigGAN) ≈ 1。类似地,每个生成模型(在第 5.1 节中更详细讨论)都有一个测试集,其中包含与其相关的相同数量的真实图像和假图像。
3.2 分析为什么先前的工作无法泛化
我们首先研究该网络(经过训练以区分 ProGAN 假图像和真实图像)检测通过未见过的方法生成的图像的能力。 在表 1 中,我们报告了对与不同生成模型系列相关的真假图像进行分类的准确性。 正如 [50 ]中所指出的,当目标模型属于用于训练真假分类器(即GAN)的同一品种生成模型时,网络在对图像进行分类时表现出良好的整体泛化性; 例如,GauGAN 的真/假图像检测准确率达到 79.25%。 然而,当在不同系列的生成模型(例如 LDM 和 Guided)(扩散模型的变体;参见第 5.1 节)上进行测试时,分类精度急剧下降到接近随机猜测的性能(chance performance)!
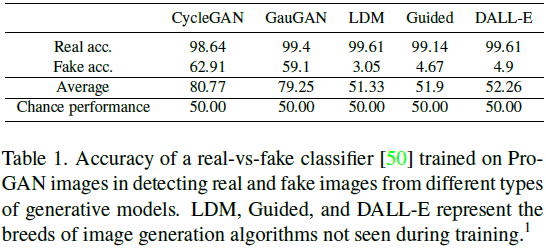
现在,当测试集具有相同数量的真图像和假图像时,分类器可以通过两种方式实现 chance performance:它可以输出(i)每个测试图像的随机预测,(ii) 所有测试图像。 从表1中,我们发现对于扩散模型,分类器以后一种方式工作,将几乎所有图像分类为真实图像,无论它们是真实的(来自 LAION 数据集)还是生成的。 鉴于此,似乎 f 已经学会了真实类和假类的不对称分离,其中对于来自 LDM(未见过的假)或 LAION(未见过的真实)的任何图像,它倾向于不成比例地输出一个类(真实)而不是另一个类 (伪造的)。
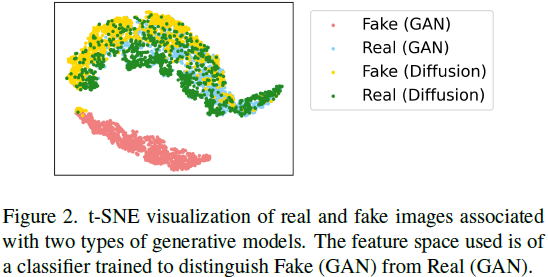
为了进一步研究这种不寻常的现象,我们将 f 用于分类的特征空间可视化。 我们考虑四种图像分布:(i)由 ProGAN 生成的假图像组成的 F_GAN,(ii)由用于训练 ProGAN 的真实图像组成的 R_GAN,(iii)由潜在扩散模型生成的假图像组成的 F_Diffusion, (iv) 由真实图像组成的 R_Diffusion(LAION 数据集),用于训练潜在扩散模型。 真假分类器根据 (i) 和 (ii) 进行训练。 对于每一个,我们使用 f 的倒数第二层获得它们相应的特征表示,并使用图 2 中的 t-SNE 绘制它们。我们注意到的第一件事是 f 确实没有平等地对待真实类和假类。 在 f 的学习特征空间中,四个图像分布将自己组织成两个明显的簇。 第一个簇是 F_GAN(粉色),另一个是其余三个簇的合并(R_GAN + F_Diffusion + R_Diffusion)。 换句话说,f 可以很容易地将 F_GAN 与其他三个区分开来,但是学习到的真实类似乎没有自己的任何属性(空间),而是被 f 用来形成一个接收器(sink)类,该接收器类托管(host)任何不是 F_GAN 的分布。 我们注意到的第二件事是,与围绕学习的真实类的簇相比,围绕学习的假类的簇非常紧凑,后者开放得多。 这表明 f 可以比检测 R_GAN 图像之间的共同属性更容易地检测 F_GAN 图像之间的共同属性。
但为什么 f 发现的 F_GAN 中常见的属性对于检测来自其他 GAN 模型(例如 CycleGAN)的假图像很有用,但对于检测 F_Diffusion 却不起作用? 来自扩散模型的假图像与来自 GAN 的图像有何不同? 受 [8,9,50,53] 的启发,我们通过可视化不同图像分布的频谱来研究这一点。 对于每个分布(例如 F_BigGAN),我们首先通过从中减去其中值模糊图像来对每个图像执行高通滤波。 然后,我们取 2000 张图像中所得高频分量的平均值,并计算傅里叶变换。 图 3 显示了四个假域和一个真实域的平均频谱。 与 [50] 类似,我们在 StarGAN 和 CycleGAN 中看到了独特且重复的图样。 然而,扩散模型(Guided [23] 和 LDM [46])的假图像中缺少这种图样,类似于真实分布的图像(LAION [48])。 因此,虽然来自扩散模型的假图像似乎有一些共同的属性,但图 3 表明该属性与 GAN 所共享的属性并不具有相似的性质。

我们的假设是,当 f 学习区分 F_GAN 和 R_GAN 时,它会锁定图 3 中描绘的伪影,仅学习寻找图像中是否存在这些图样。 由于这足以减少训练误差,因此它在很大程度上忽略了学习与真实类别相关的任何特征(例如,平滑边缘)。 这反过来又会导致决策边界出现偏差,来自扩散模型的假图像缺乏 GAN 的指纹,最终会被分类为真实图像。
4. 方法
如果学习神经网络 f 不是分离真类(R)和假类(F)的理想方法,我们该怎么办? 我们认为,关键在于分类过程应该发生在尚未学会将图像与两类分开的特征空间中。 这可以确保这些特征不会偏向于识别一个类别的图样比另一类别的图样要好得多。
特征空间的选择。 作为最初的想法,由于我们可能不想学习任何特征,我们可以简单地在像素空间中进行分类吗? 这是行不通的,因为像素空间不会捕获除点对点像素对应之外的任何有意义的信息(例如边缘)。 因此,图像的任何分类决策都应该在将其映射到某个特征空间后做出。 这个特征空间由网络产生并表示为 φ,应该具有一些理想的品质。
首先, 应该暴露于大量图像。 由于我们希望设计一个通用的假图像检测器,因此它的功能对于各种真/假图像(例如人脸、室外场景)应该是一致的。 这要求 φ 的特征空间大量填充不同类型的图像,以便对于任何新的测试图像,它知道如何正确嵌入它。 其次,如果 φ 在总体上是通用的,但也可以捕获图像的低级细节,那将是有益的。 这是因为真实图像和假图像之间的差异尤其出现在低级细节上 [10, 53]。
为了满足这些要求,我们考虑利用经过大量数据训练的大型网络作为产生 的可能候选者。 特别是,我们选择了视觉 transformer 的变体 ViT-L/14 [24],针对图像语言对齐任务 CLIP [41] 进行训练。 CLIP:ViT 在 4 亿图像文本对的超大数据集上进行训练,因此它满足了充分接触视觉世界的第一个要求。 此外,由于 ViT-L/14 的起始块大小较小,为 14 × 14(与其他 ViT 变体相比),我们相信它还可以帮助对真假分类所需的低级图像细节进行建模。 因此,对于我们所有的主要实验,我们使用 CLIP:ViT-L/14 的视觉编码器的最后一层作为 φ。
总体方法可以通过以下方式形式化。 我们假设访问与单个生成模型相关的图像(例如,ProGAN,与[50]中的约束相同)。 R = {r1, r2, ..., rN} 和 F = {f1, f2, ..., fN} 分别表示真实类和假类,每个类包含 N 个图像。 D = {R∪F} 表示整个训练集。 我们研究两种简单的分类方法:最近邻和线性探测。 重要的是,这两种方法都利用完全未经真/假分类训练的特征空间。
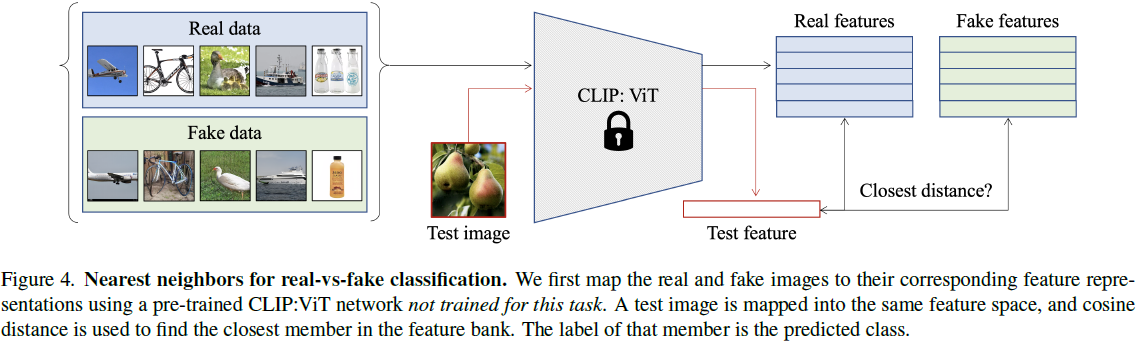
最近邻。 给定预训练的 CLIP:ViT 视觉编码器,我们使用其最后一层 φ 将整个训练数据映射到它们的特征表示(768 维)。 生成的特征库为 φ_bank = {φ_R ∪ φ_F},其中 φ_R = {φ_r1 , φ_r2 , ..., φ_rN } 且 φ_F = {φ_f1 , φ_f2 , ..., φ_fN }。 在测试期间,图像 x 首先映射到其特征表示 φ_x。 使用余弦距离作为度量 d,我们找到其与真实 (φ_R) 和虚假 (φ_F) 特征库的最近邻居。 预测(真:0,假:1)是根据两者中较小的距离给出的:
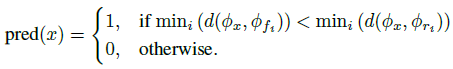
CLIP:ViT 编码器始终保持冻结状态; 见图4。
线性分类。 我们采用预先训练的 CLIP:ViT 编码器,并在其顶部添加一个具有 sigmoid 激活的线性层,并仅训练这个新的分类层 ψ,以使用二元交叉熵损失进行二元真假分类:
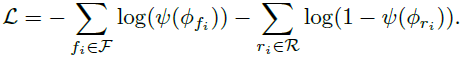
由于这样的分类器只需要训练线性层中的几百个参数(例如 768 个),因此从概念上讲,它将与最近邻非常相似,并保留其许多有用的属性。 此外,它的优点是计算和内存更加友好。
5. 实验
5.1 研究生成模型
由于创建假图像的新方法不断出现,标准做法是在训练期间限制仅访问一种生成模型,并在来自未见过的生成模型的图像上测试生成的模型。 我们遵循 [50] 中描述的相同协议,并使用 Pro-GAN 的真/假图像作为训练数据集。
在评估过程中,我们考虑各种生成模型。 首先,我们评估 [50] 中使用的模型:Pro-GAN [28]、StyleGAN [29]、BigGAN [7]、CycleGAN [54]、StarGAN [13]、GauGAN [38]、CRN [12]、 IMLE [30]、SAN [18]、SITD [11] 和 DeepFakes [47]。 每个生成模型都有真实和虚假图像的集合。 此外,我们还对引导扩散模型(guided diffusion model) [23] 进行了评估,该模型是针对 ImageNet 数据集 [21] 上的类别条件图像合成任务进行训练的。 我们还对最近的文本到图像生成模型进行了评估:(i)潜在扩散模型(LDM)[46] 和(ii)Glide [36] 是扩散模型的变体,以及(iii)DALL-E [43] 是一个自回归模型(我们考虑其开源实现 DALL-E-mini [20])。 对于这三种方法,我们将 LAION 数据集 [48] 设置为真实类,并使用相应的文本描述来生成假图像。
LDM 可用于以不同方式生成图像。 标准做法是使用文本提示作为输入,并执行 200 个噪声细化步骤 (LDM 200)。 人们还可以借助引导(LDM 200 w/CFG)生成图像,或使用更少的步骤实现更快的采样(LDM 100)。 同样,我们还尝试了预训练 Glide 模型的不同变体,该模型由两个独立的噪声细化阶段组成。 标准做法是使用 100 个步骤获得 64 × 64 的低分辨率图像,然后在下一阶段(Glide 100-27)使用 27 个步骤将图像上采样到 256 × 256。 我们还考虑了另外两个变体:Glide 50-27 和 Glide 100-10,基于两个阶段中的细化步骤数量。 所有生成模型都合成 256 × 256 分辨率的图像。
5.2 真假分类基线
我们与以下最先进的基线进行比较:
- 训练分类网络,使用二元交叉熵损失对图像给出真/假决策[50]。 作者采用在 ImageNet 上预训练的 ResNet-50 [27],并在 ProGAN 的真/假图像(以下称为训练深度网络)上对其进行微调。
- 我们包括另一种变体,将骨干网更改为 CLIP:ViT [24](以匹配我们的方法)并为相同的任务训练网络。
- 在补丁级别上训练类似的分类网络[10],作者建议截断 ResNet [27] 或 Xception [14](分别在 Layer1 和 Block2),以便在做出决定时考虑较小的感受野。 该方法主要是为了检测生成的面部图像而提出的,但我们研究了该想法是否可以扩展到检测更复杂的假图像。
- 训练分类网络,其中输入图像首先被转换为相应的共现矩阵(co-occurence matrices) [35](一种在图像隐写分析和取证中有效的技术 [16,26]),条件是网络预测真/假类别。
- 在真/假图像的频谱上训练分类网络 [53],作者表明该空间在捕获和显示 GAN 生成图像中存在的伪影方面表现更好。
所有训练细节均可在补充材料中找到。
5.3 评估指标
我们遵循现有的工作 [10,25,35,50,53] 并报告平均精度(AP)和分类精度。 为了计算基线的准确性,我们调整了可用生成模型的保留训练验证集的分类阈值。 例如,当使用与 ProGAN 相关的数据训练分类器时,会选择阈值,以便最大限度地提高 ProGAN 真实和虚假图像集的准确性。 此外,我们还计算了 [50] 的上限预言准确率,其中分类器的阈值直接在每个测试集上单独校准。 这是为了衡量分类器在每个测试集上可以执行的最佳性能(详细信息在补充中)。
6. 结果
我们首先将我们的方法与现有基线进行比较,了解它们对不同类型的真/假图像进行分类的能力,然后研究我们方法的不同组成部分。
6.1 用未见过的方法检测假图像
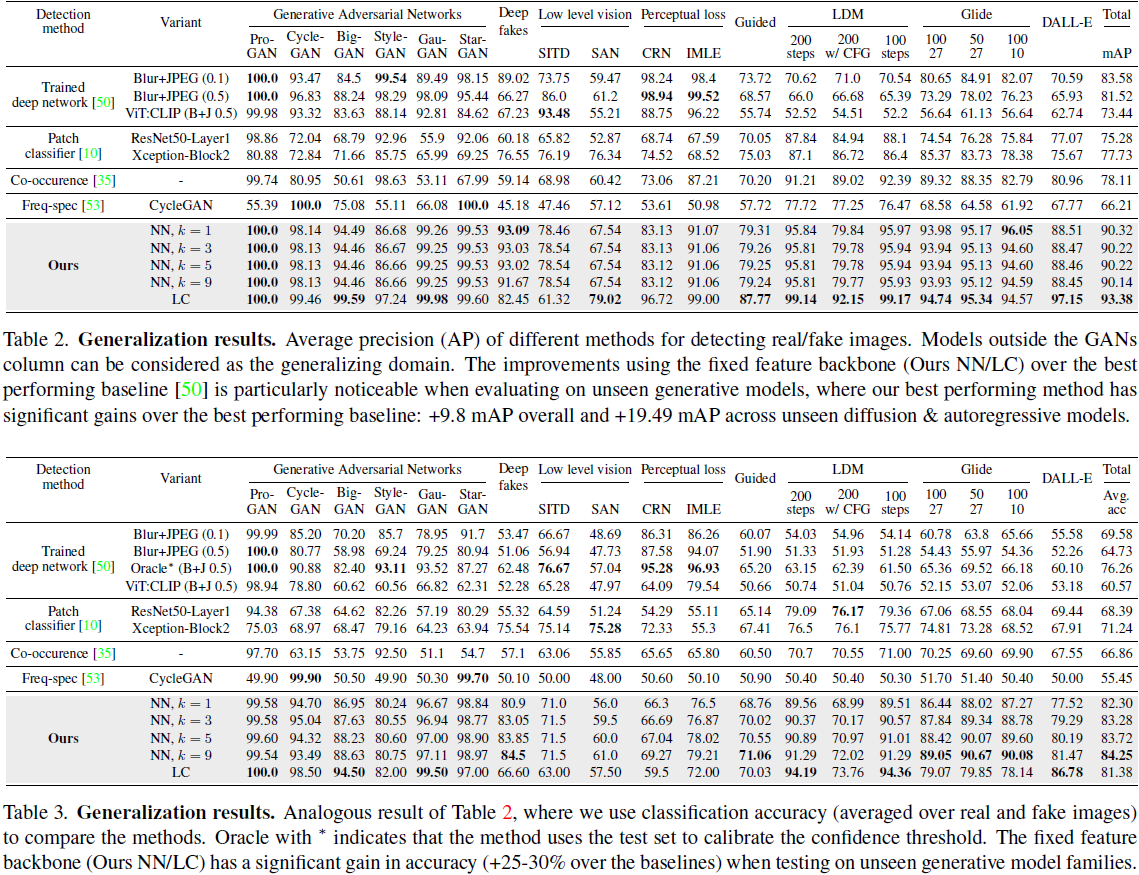
表 2 和表 3 分别显示了所有方法(行)从不同生成模型(列)检测假图像的平均精度(AP)和分类精度。 为了分类准确性,显示的数字是每个生成模型的真类和假类的平均值。所有方法都只能访问 ProGAN 的数据([53] 除外,它使用 CycleGAN 的数据),要么用于训练分类器,要么用于创建 NN 特征库。
正如第 3.2 节所讨论的,对于其他 GAN 变体来说,经过训练的分类器基线 [50] 能够以良好的准确度区分真品和假品。 然而,对于来自大多数未见过的生成模型的图像,准确率急剧下降(有时几乎达到约 50-55%;例如,LDM 变体),其中所有类型的假图像大多被分类为真实图像(请参阅补充中的表 C) )。 重要的是,即使我们将主干更改为 CLIP:ViT(我们的方法使用的主干),这种行为也不会改变。 这告诉我们,图 2 中突出显示的问题总体上影响深度神经网络,而不仅仅是 ResNet。 在 patch-level [10] 上执行分类、使用共现矩阵 [35] 或使用频率空间 [53] 也不能解决问题,其中分类器无法具有一致的检测能力,有时甚至对于在同一生成模型系列中(例如 GauGAN/BigGAN)的方法来说也是如此。 此外,在某些设置(Xception)中,即使检测来自同一训练域(ProGAN)的图像中的真/假 patch 也可能很困难。 这表明,虽然当 patch 变化不大时(例如,面部图像),学习在小图像区域内查找模式可能就足够了,但当真实和虚假图像的域变得更加复杂时(例如,自然场景),这可能就不够了。
另一方面,我们的方法在检测真/假图像方面表现出明显更好的泛化性能。 我们首先通过考虑训练领域内的模型(即 GAN)来观察这一点,其中我们的 NN 变体和线性探测分别实现了 ∼93% 和 ∼95% 的平均准确度,而性能最佳的基线、经过训练的深度网络 - Blur+JPEG (0.5) 达到 ∼85%(提高了 +8-10%)。 当考虑到诸如扩散 (LDM+Guided+Glide) 和自回归模型 (DALL-E) 等未见过的方法时,这种性能差异变得更加明显,其中我们的神经网络变体和线性探测分别实现了 82-84% 的平均准确度和 ∼82% 的平均准确度相比于通过训练有素的深度网络变体 [50] 的 53-58%(提高了 +25-30%)。 就平均精度而言,在同一 GAN 系列的模型上进行测试时,经过训练的深度网络的 AP 的最佳版本非常高,为 94.19 mAP,但在未见过的扩散/自回归模型上进行测试时,AP 会下降,为 75.51 mAP。 我们的 NN 变体和线性探测在相同 (GAN) 系列域内保持较高的 AP(96.36 和 99.31 mAP),并且在未见过的扩散/自回归模型上(90.58 和 95.00 mAP),导致约 +15-20 mAP 的改进。 对于投票池大小从 k=1 到 k=9 的 NN 变体,这些改进仍然相似,这表明我们的方法对此超参数不太敏感。
总之,这些结果清楚地证明了使用冻结的预训练网络的特征空间的优势,该网络不受下游真/假分类任务的影响。
6.2 允许训练好的分类器作弊
如第 5.3 节所述,我们使用经过训练的分类器基线 [50] 的预言(oracle)版本进行实验,其中分类器的阈值直接在每个测试集上进行调整。 即使这种灵活性(网络本质上是作弊的)也无法使分类器的性能几乎与我们的方法一样好,特别是对于来自未知领域的模型; 例如,我们的最近邻(k = 9)的平均分类精度为 84.25%,比预言基线(76.26%)高 7.99%。 这表明为此任务训练神经网络的问题不仅仅是测试时阈值不正确。 相反,经过训练的网络除了寻找一组特定的虚假图样外,基本上不能做太多事情。 如果没有它们,则在寻找与真实分布相关的功能时会遇到问题。 这就是未接受此任务训练的模型的特征空间有其优势的地方; 即使这些假特征不存在,仍然会有其他对分类有用的特征,这些特征在真假训练过程中没有被学习到排除。
6.3 网络骨干的影响
到目前为止,我们已经看到使用 CLIP:ViTL/14 特征空间的最近邻/线性探测具有令人惊讶的良好泛化性。 在本节中,我们研究如果主干架构或预训练数据集发生更改会发生什么。 我们对线性分类变体进行实验,并考虑以下设置:(i) CLIP:ViTL/14、(ii) CLIP:ResNet-50、(iii) ImageNet:ResNet-50 和 (iv) ImageNet:ViT-B /16。 对于每个数据,我们再次使用 ProGAN 的真/假图像数据作为训练数据。

图 5 显示了这些变体在相同模型上的准确性。 关键的一点是,网络架构以及训练它的数据集在确定虚假图像检测的有效性方面都发挥着至关重要的作用。 作为 CLIP 系统一部分预训练的视觉编码器比在 ImageNet 上预训练的视觉编码器表现更好。 这可能是因为 CLIP 的视觉编码器可以看到更多多样性的图像,从而使其暴露于比在 ImageNet 上训练的模型更大的真实分布。 在 CLIP 中,ViT-L/14 的性能优于 ResNet-50,这部分归因于其更大的架构和注意力层的全局感受野。

我们还提供预训练分布的可视化分析。 使用由 ProGAN 中相同的真实和虚假图像组成的四个模型的特征库中的每一个,我们绘制了四个 t-SNE 图形,并使用图 7 中的二进制(真实/虚假)标签对生成的二维点进行颜色编码。 CLIP: ViTL/14 的空间最好地分离了真实(红色)和虚假(蓝色)特征,其次是 CLIP:ResNet-50。 ImageNet:ResNet-50 和 ImageNet:ViT-B/16 似乎没有任何适当的结构来区分这两个类,这表明预训练数据比架构更重要。
6.4 训练数据源的效果
到目前为止,我们已经使用ProGAN作为训练数据的来源。 接下来,我们使用预先训练的 LDM [46] 作为源,重复表 2 中的评估设置。 真实类由 LAION 数据集 [48] 中的图像组成。 假图像是使用 LDM 200 步变体使用相应真实图像的文本提示生成的。 该数据集总共由 40 万张真实图像和 40 万张假图像组成。

图 6(上)将我们得到的线性分类器与使用 ProGAN 数据集创建的线性分类器进行了比较。 与我们迄今为止所看到的类似,仅访问 LDM 的数据集也使模型能够实现良好的泛化性。 例如,我们的模型可以检测来自 GAN 域的图像(现在是未见过的生成模型),平均 mAP 为 97.32。 相比之下,经过训练的深度网络(图 6 底部)仅当目标模型来自同一生成模型系列时才表现良好,并且在检测来自 GAN 变体的图像时无法泛化,mAP 为 60.17; 即,我们的方法对未见过的 GAN 域的改进是 +37.16 mAP。 总之,通过我们的线性分类器,人们可以从 ProGAN 的数据开始并检测 LDM 的假图像,反之亦然。 这是令人鼓舞的,因为它告诉我们,到目前为止,随着生成模型的所有进步,仍然存在连接各种假图像的隐藏链接。
7. 结论与讨论
我们研究了与训练神经网络检测假图像相关的问题。 该分析为我们简单地解决该问题铺平了道路:使用未经过真假分类训练的信息丰富的特征空间。 在这个空间中执行最近邻/线性探测可以显着提高检测假图像的泛化能力,特别是对于扩散/自回归模型等较新的方法。 正如第 6.4 节中提到的,这些结果表明即使在今天,GAN 生成的假图像和扩散模型生成的假图像之间也存在一些共同点。 然而,这种相似性是什么仍然是一个悬而未决的问题。 虽然更好地理解这个问题将有助于设计更好的假图像检测器,但我们相信我们提出的解决方案的泛化优势应该保证它们成为这一工作领域的强大基线。
参考
Ojha U, Li Y, Lee Y J. Towards universal fake image detectors that generalize across generative models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 24480-24489.
[50] Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn-generated images are surprisingly easy to spot...for now. In CVPR, 2020.
S. 总结
S.1 主要思想
每当图像包含特定于用于训练的生成模型的(低级)指纹时,该图像就会被分类为假图像,其他任何图像都会被归类为真实。这是因为分类器很容易锁定区分假图像和真实图像的低级图像伪影。
为解决这个问题,作者使用未经训练的特征空间来区分真假图像。当能够访问大型预训练视觉语言模型(CLIP)的特征空间时,使用最近邻分类的非常简单的基线对于检测各种未见过的生成模型假图像,有很良好泛化能力。
S.2 方法
特征空间的选择。应满足两个条件:
- 该预训练模型见过足够多类型的图像,从而实现良好泛化。
- 该特征空间可以捕获图像的低级细节。因为真假图像的差异在低级细节上尤为明显。
最终作者选择了视觉 transformer 的变体 ViT-L/14,针对图像语言对齐任务 CLIP 进行训练。
最近邻。给定预训练的 CLIP:ViT 视觉编码器,使用其最后一层 φ 将整个训练数据映射到它们的特征表示。然后计算待分类图像的特征表示与训练数据特征表示的余弦距离,从而完成分类。其中,CLIP:ViT 编码器始终保持冻结状态。
线性分类。 我们采用预先训练的 CLIP:ViT 编码器,并在其顶部添加一个具有 sigmoid 激活的线性层,并仅训练这个新的分类层 ψ,以使用二元交叉熵损失进行二元真假分类:
该分类器只需要训练线性层中的几百个参数(例如 768 个),因此从概念上讲,它将与最近邻非常相似,并保留其许多有用的属性。 此外,它的优点是计算和内存更加友好。
S.3 待解决问题
即使在今天,GAN 生成的假图像和扩散模型生成的假图像之间也存在一些共同点。 然而,这种相似性是什么仍然是一个悬而未决的问题。更好地理解这个问题将有助于设计更好的假图像检测器。

















 2225
2225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









