







Dialogue is Better Than Monologue - Instructing Medical LLMs via Strategical Conversations
![]()

目录
1. 概述
该论文研究了 医学大语言模型(Medical LLMs) 在临床推理中的表现,并提出了一种新的基准测试和对话式微调(Dialogue Tuning) 方法,以提升模型的 多轮推理能力 和 抗噪性能。
研究发现,与传统的 单轮多项选择题微调(Monologue Tuning) 相比,对话微调 能够更好地模拟医生的思维过程,使模型在复杂诊断任务中的表现提升 9.64%(多轮推理) 和 6.18%(抗噪环境准确率)。
研究贡献:
- 首次提出对话微调(Dialogue Tuning)用于医学 LLM 训练,并证明其对多轮推理和抗噪能力的提升。
- 构建新评测基准 Muddy Maze,包括 一轮证据排序(One-Round Evidence Ranking) 和 多轮证据排序(Multi-Round Evidence Ranking),模拟医生诊断流程,填补现有医疗 AI 评测中缺乏真实临床推理的空白。
- 提出对话数据增强方法,将多项选择题和医学文章转换为医生-患者对话,促进模型在真实医疗交互场景中对动态推理过程的学习。
- 实验表明,对话训练能让模型在多轮证据排序任务中表现更优,有助于医疗 AI 走向真实临床应用。
2. 研究背景与动机
现有医学 LLM 存在的问题:
- 传统医疗 AI 主要基于多项选择(MCQA) 和 文章问答(Article QA) 进行训练,但这类方法缺乏真实的临床推理能力。
- 医生在临床诊断过程中通常逐步收集信息、筛选无关数据、进行假设验证,但现有 LLM 缺乏这种迭代推理能力。
- 现有评测基准通常关注静态问题(单轮问题-答案匹配),忽略了真实临床决策中的交互和证据整合。
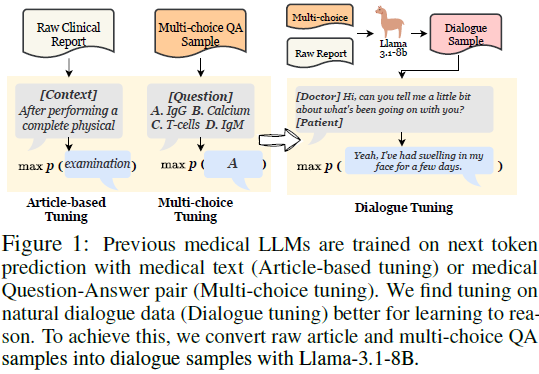
对话微调(Dialogue Tuning)的潜力:
- 医生在现实场景中通常采用 对话式推理,通过问诊逐步排查病因。
- 对话数据 能够更好地模拟真实世界的医生-患者互动,使模型学会逐步推理,而非仅仅进行模式匹配。
3. 方法
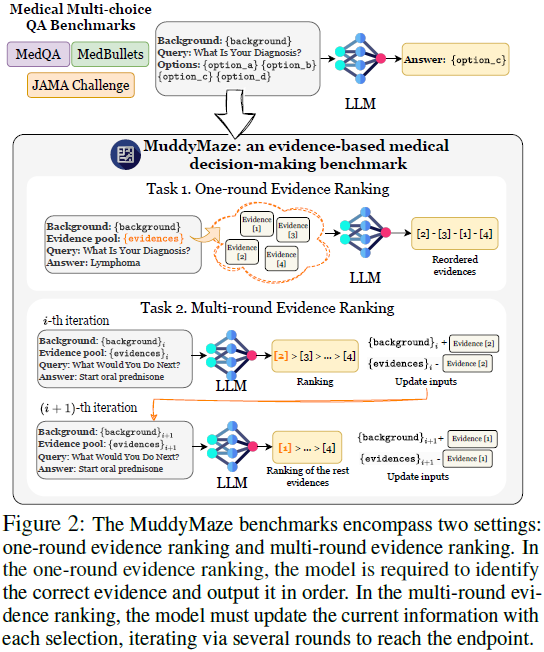
3.1 基准测试 Muddy Maze
Muddy Maze 评测基准主要包括两个任务:
- 单轮证据排序(One-Round Ranking):给定患者信息,模型需要从证据池中找到最重要的证据,并按照逻辑顺序排序。
- 多轮证据排序(Multi-Round Ranking):模型需要逐步选择和整合证据,并在多个回合后得出最终诊断。
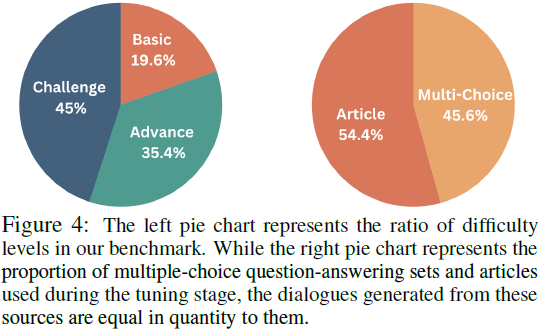
基准测试的难度等级:
- 基础(Basic):直接识别关键医学知识点。
- 高级(Advanced):需要结合多条证据进行推理。
- 挑战(Challenge):包含大量无关信息,模拟真实医生面对的信息噪声问题。
3.2 对话微调(Dialogue Tuning)
- 数据转换:将传统多项选择题和文章数据转换为医生-患者对话。
- 信息迭代更新:让模型学习逐步获取证据,而不是一次性获得所有信息。
- 信息熵减少(Entropy Reduction):随着模型获取更多信息,不确定性减少,逐步逼近最终诊断。
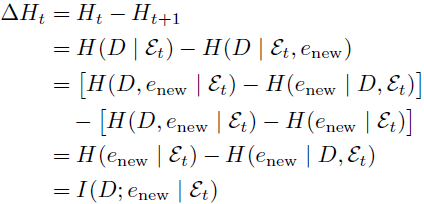
其中,ε_t 是第 t 步的证据集(Evidence set),e_new 是收集到的新信息,D 为最终输出。
4. 实验结果分析
4.1 对话微调 vs. 传统方法
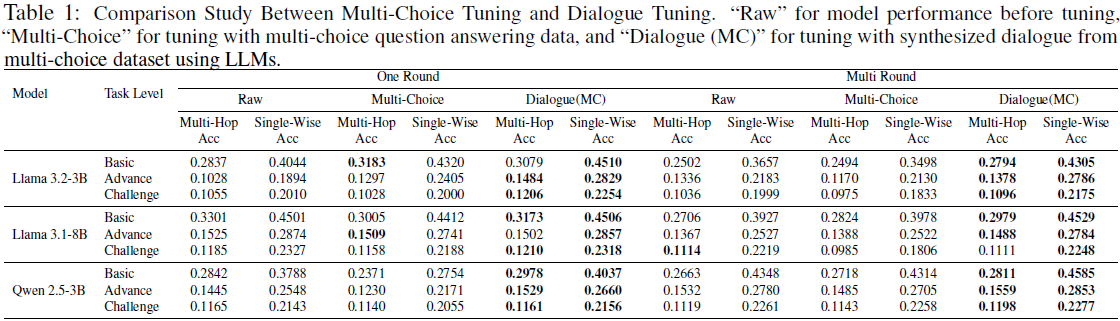
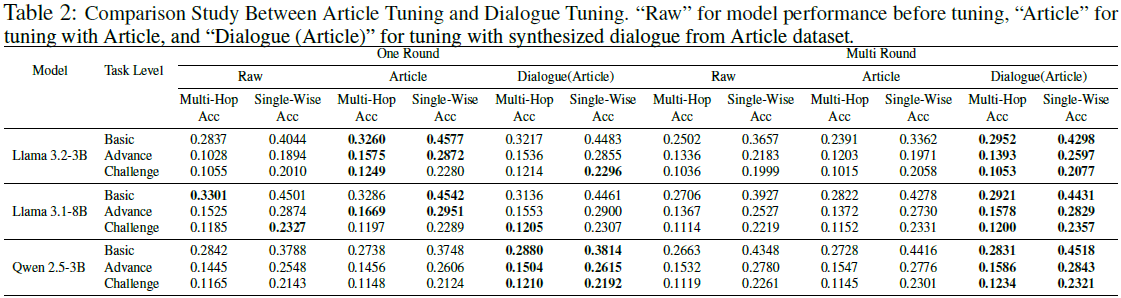
多轮证据推理:对话微调(Dialogue Tuning)相较于多选问答训练(MCQA),在 多轮任务(Multi-Round) 中提升 8.07%~9.64%。
单轮证据排序:对话微调在 单轮任务(One-Round) 中提升 1.56%~3.42%,但优势不如多轮推理明显。
文章 vs. 对话数据:相比于直接使用文章数据(Article Tuning),对话训练能够 提升 9.36%(基础任务) 和 2.06%(高级任务) 的推理能力。
4.2 抗噪能力分析
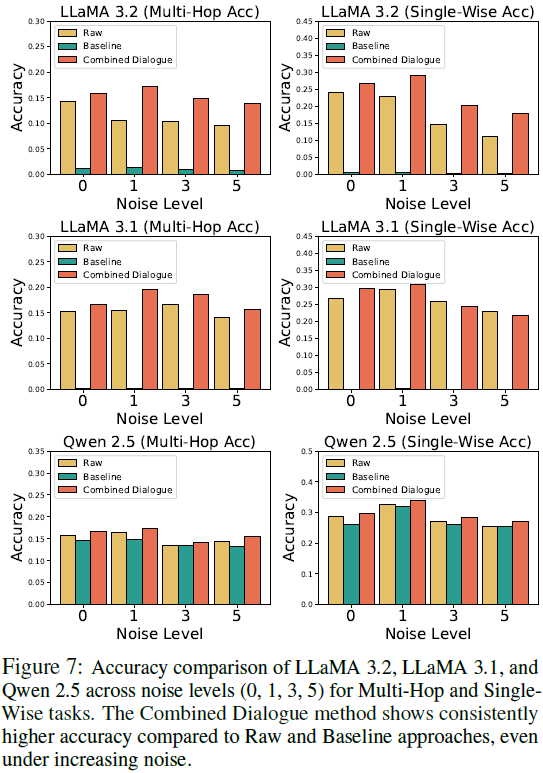
现实临床场景包含大量无关信息,医生需要从噪声中筛选关键证据。
在高噪声环境(噪声等级 5),对话训练的模型的准确率仍然比传统方法高,表明其抗噪能力更强。
4.3 结合多种对话数据的影响
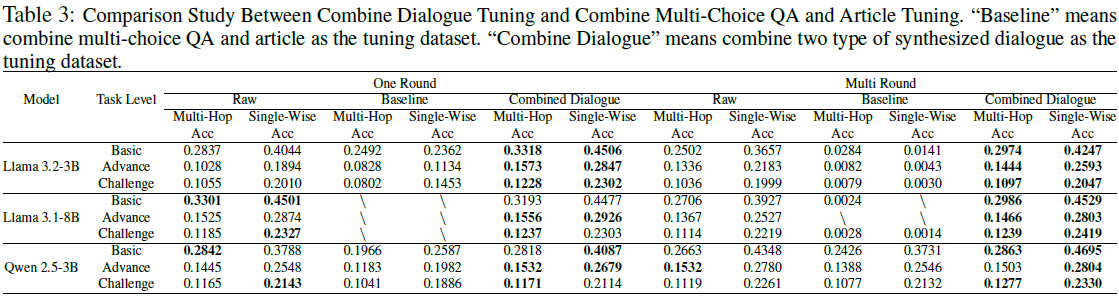
研究发现,结合不同来源的对话数据(MCQA 转换的对话 + 文章转换的对话)能提升模型泛化能力。
例如,结合两种对话数据后,LLaMA-3.2 在基础任务的单轮推理准确率提升 21.4%。
5. 结论
本文提出 对话微调(Dialogue Tuning),通过转换传统医学训练数据为医生-患者对话,提升了医学 LLM 的 多轮推理能力和抗噪性能。实验表明,对话微调比传统 多项选择训练(MCQA) 和 文章训练(Article Tuning) 更符合真实世界的医学推理过程。研究为未来医疗 AI 发展提供了新的方向,使 LLM 更接近 医生的诊断逻辑。
未来研究方向:
- 扩展多模态学习:结合医学影像、病历文本、语音对话,提升 AI 诊断能力。
- 优化训练数据:收集更真实的医生-患者对话数据,减少合成数据带来的偏差。
- 实际临床应用验证:在真实临床环境中评估 AI 的推理能力,确保安全性和可靠性。
- 提升模型鲁棒性:探索更强的抗噪方法,使模型在低质量数据或不完整病史的情况下仍能推理。
论文地址:https://arxiv.org/abs/2501.17860
进 Q 学术交流群:922230617


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









