







RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models

目录
1. 引言
近年来,人工智能(AI)在医疗领域的应用迅速增长,其中医疗大规模视觉语言模型(Med-LVLMs)用于疾病诊断、治疗规划和医疗建议。然而,现有 Med-LVLMs 经常生成与医学事实不符的回答,影响其在临床应用中的可靠性。
为了解决这一问题,检索增强生成(Retrieval-Augmented Generation,RAG)方法被引入,通过外部知识提高模型的事实准确性。然而,RAG 仍然面临两个主要挑战:
- 检索内容数量选择:检索过少可能无法涵盖所需信息,过多则可能引入不相关或错误的内容,干扰模型生成。
- 对检索内容的过度依赖:某些情况下,即使模型原本能够正确回答问题,但引入检索内容后反而会生成错误答案。
本文提出了 RULE(一种可靠的多模态 RAG 方法),用于改善 Med-LVLMs 的事实性(Factuality)。核心方法包括:
- 事实性风险控制:通过校准检索内容数量 k,控制因检索不足或过量带来的事实性风险。
- 知识平衡偏好微调:基于模型因过度依赖检索内容而产生错误的样本,构建偏好数据集并进行微调,使模型在内在知识与检索信息之间取得平衡。
RULE 在三个医疗数据集上进行了实验,包括医学视觉问答(VQA)和报告生成任务,平均提升 47.4% 的事实准确性。
1.1 关键词
医疗大规模视觉语言模型 (Med-LVLMs)、事实性问题、检索增强生成 (RAG)、事实风险控制(Factuality Risk Control,FRC)、直接偏好优化(DPO)、知识平衡偏好微调(Knowledge Balanced Preference Tuning,KBPT)
2. 预备知识
2.1 医疗大规模视觉语言模型(Med-LVLMs)
Med-LVLMs 结合大规模语言模型(LLM)和医疗视觉模块,可输入医疗图像 x_v 和文本查询 x_t ,并生成医学文本输出 y 。
2.2 偏好优化
偏好优化(Preference Optimization)用于微调 LLMs,使其行为与目标更对齐。本文采用直接偏好优化(DPO)方法,构造偏好数据集
![]()
其中:
- y_w 是偏好的答案(Preferred)
- y_l 是不偏好的答案(Dispreferred)
优化目标是最大化偏好答案的概率,并减少模型对错误答案的偏好。
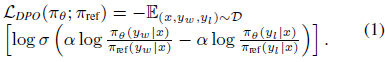
给定一个输入 x,语言模型策略 π_θ 可以产生一个条件分布 π_θ(y | x),其中 y 作为输出文本响应。π_ref 表示参考策略(reference policy),即通过监督学习微调的 LLM。
3. 方法
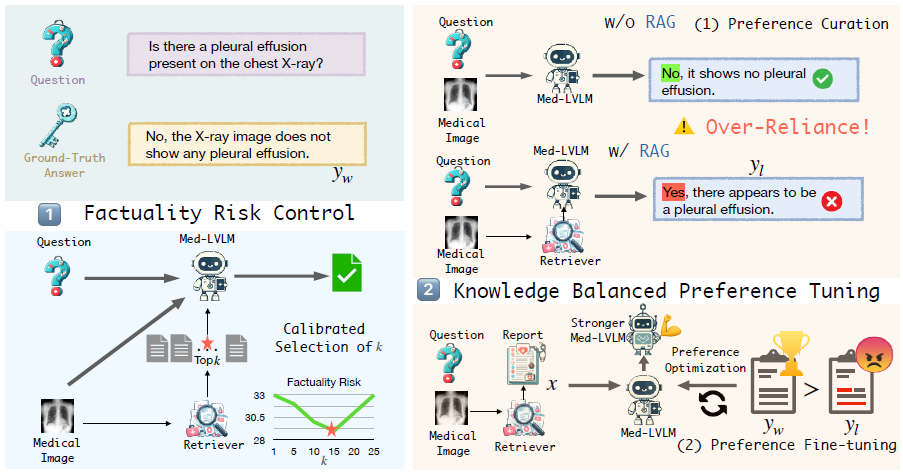
图 2:RULE 的框架由两个主要部分组成:
- (1)通过校准 k 选择的事实风险控制策略;
- (2)知识检索平衡调整。
- 在调整阶段,我们首先从由于过度依赖检索到的上下文而导致模型出错的样本中构建偏好数据集。
- 随后,我们通过采用偏好优化,使用该数据集对 Med-LVLM 进行微调。
3.1 参考内容检索
引入 RAG 方法,在 Med-LVLM 生成过程中引入外部文本描述或医学报告,提高事实性。
采用 CLIP 设计,使用视觉编码器和文本编码器,将医学图像与相应的文本报告编码为嵌入,并通过对比学习使视觉编码器和文本编码器适应到医学域。
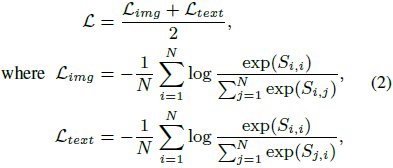
![]()
S_{i,j} 表示示例 i 的图像表示与示例 j 的文本表示之间的相似度。
在推断时,通过计算图像-文本相似度,选择 Top-K 个最相关的医学报告作为检索参考。
3.2 事实性风险控制
通过统计方法校准最佳检索数量 k ,避免过少或过多的检索内容干扰模型生成。
采用 假设检验,计算不同检索数量 k 下的 事实性风险(factuality risk):
FR(k) = 1 - ACC(M(x, (q, T_k)))
其中 ACC(⋅) 表示模型正确回答的比例,T_k 为前 k 个检索内容。
最后,我们使用任意 家族错误率 (family-wise error rat,FWER) 控制进程,例如 Bonferroni 校正 或 顺序图形测试(sequential graphical testing)选择最佳 k,保证事实性风险在可接受范围内。
3.3 知识平衡偏好微调
识别模型因过度依赖检索内容而错误的案例,构建偏好数据集:
- 偏好样本:原始回答正确但因检索干扰而变错的案例
- 不偏好样本:检索增强后错误的案例

采用 直接偏好优化(DPO)进行微调,使模型在内部知识与检索内容之间取得平衡。
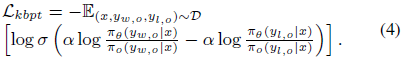

4. 实验
4.1 实验设置
基线模型:LLaVA-Med-1.5 7B
比较方法:
- 传统解码方法:贪心搜索(Greedy)、束搜索(Beam Search)
- 其他 LVLM 事实性增强方法:DoLa, OPERA, VCD
- 开源 Med-LVLMs:Med-Flamingo, MedVInT, RadFM
数据集:
- MIMIC-CXR(胸部 X 光)
- IU-Xray(胸部 X 光)
- Harvard-FairVLMed(眼科影像)
评估指标:
- VQA 任务:准确率(Accuracy)、精度(Precision)、召回率(Recall)、F1 分数
- 报告生成任务:BLEU、ROUGE-L、METEOR
4.2 结果
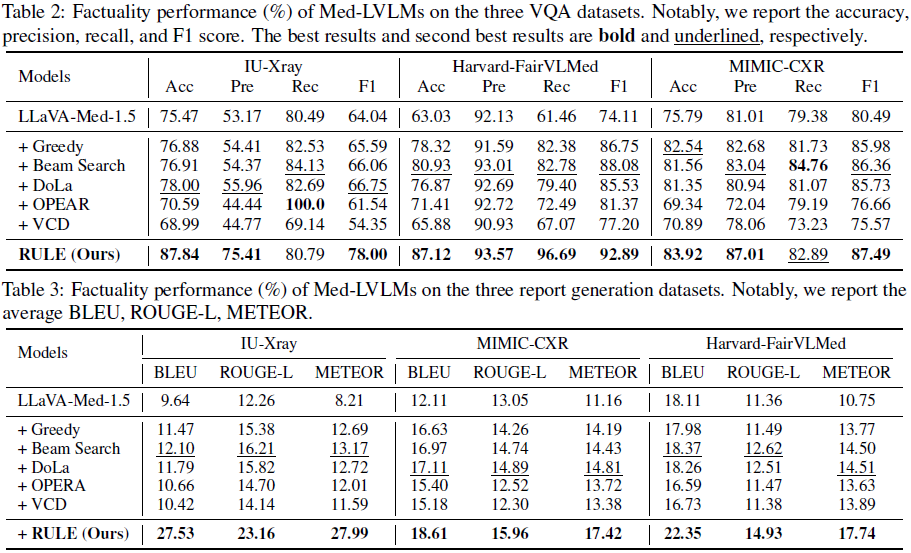
VQA 任务:RULE 方法在所有数据集上均取得最优结果,准确率平均提高 47.4%。
报告生成任务:RULE 也在 BLEU、ROUGE-L 和 METEOR 指标上大幅提升。
4.3 关键分析
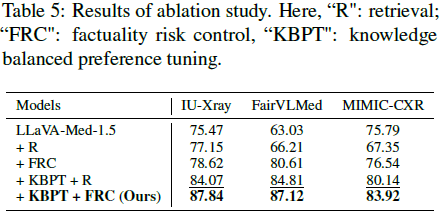
1)消融实验:
- 仅使用 RAG 时,部分数据集的事实性反而下降。
- 结合 事实性风险控制(FRC)后,效果明显提升。
- 进一步加入 知识平衡偏好微调(KBPT)后,取得最优表现。
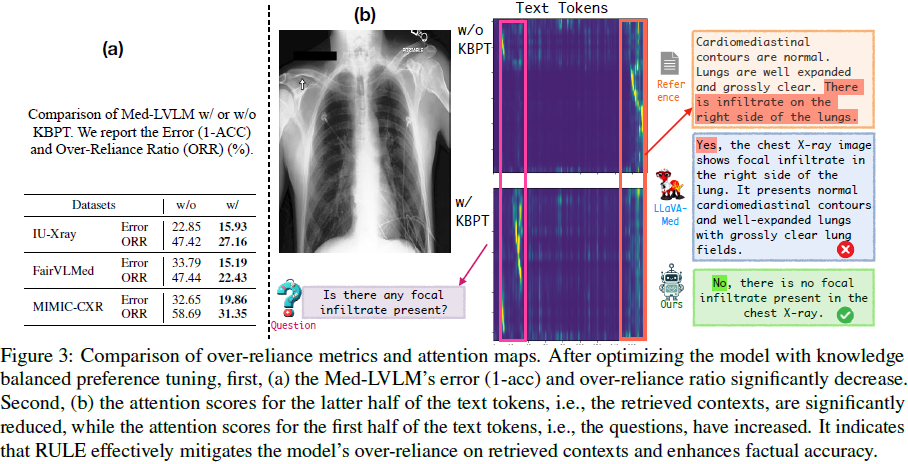
2)减少对检索内容的过度依赖:
- RULE 显著降低因过度依赖检索导致的错误率(平均下降 42.9%)。
- 通过注意力权重分析发现,经过 KBPT 微调后,模型对检索内容的关注度下降,更依赖自身知识回答问题。
3)适配不同的 Med-LVLMs:
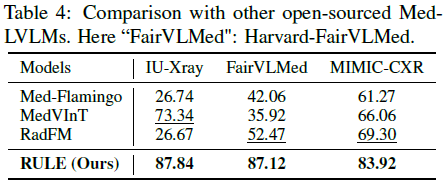
RULE 适用于不同模型架构,在 LLaVA-Med-1.0 上也显著提升准确率。
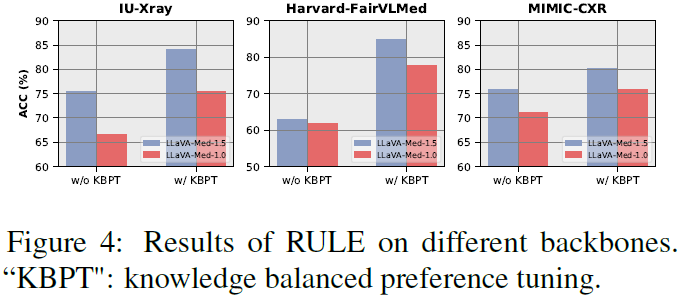
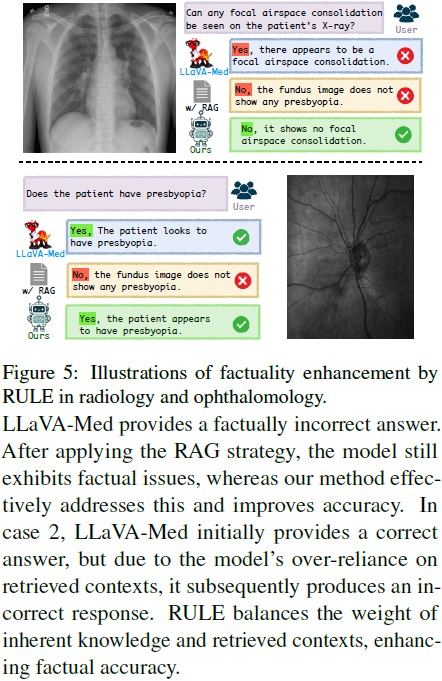
4)案例分析:
RULE 可有效纠正模型因 RAG 误导产生的错误,提升医学问答的准确性。
5. 相关工作
医疗 LVLM 事实性问题:现有 Med-LVLMs 存在幻觉问题,需要改进事实性机制。
检索增强生成(RAG):广泛用于医学问答和报告生成,但存在检索数量选择和过度依赖问题。
6. 结论
本文提出 RULE,一种适用于 Med-LVLMs 的可靠多模态 RAG 方法。RULE 优化检索内容选择,并通过 偏好微调 使模型在检索信息与自身知识之间取得平衡。该方法在三个医学数据集上取得显著提升,平均提高 47.4% 的事实准确性。RULE 可用于不同 Med-LVLMs,增强其在临床决策中的可信度。
论文地址:https://arxiv.org/abs/2407.05131
项目页面:https://github.com/richard-peng-xia/RULE
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









