







Multiscale Byte Language Models -- A Hierarchical Architecture for Causal Million-Length Sequence Modeling
目录
1. 引言
字节(byte)是数字世界的基本单位,因此基于字节的语言模型(Byte Language Models,BLMs)成为近年来的研究热点。BLMs 旨在摆脱子词分词(subword tokenization)的限制,使其能够适应不同语言和多模态数据。然而,由于字节流(bytestreams)长度过长,传统的 Transformer 架构在计算复杂度上遇到瓶颈。
因此,本文提出了一种新的 多尺度字节语言模型(Multiscale Byte Language Model,MBLM),其采用层级解码结构,可在单张 GPU 上以完整模型精度训练 5M 字节的上下文窗口。MBLM 通过结合 Transformer 和 Mamba 块,实现高效的长序列处理,并在单模态(文本)和多模态(视觉问答)任务上进行了全面评估。
实验结果表明,混合架构 在长序列建模上具备高效的计算性能,同时在视觉问答任务上,MBLM 仅使用下一个 token 预测方法即可达到 CNN-LSTM 分类器的性能水平。本文的研究强调了 MBLM 在未来通用多模态基础模型(Omnimodal Foundation Models)中的潜力。
2. 相关工作
MBLM 构建在 MegaByte(Yu et al., 2023)模型的基础上,MegaByte 采用两级 Transformer 解码器,可处理最长 1.2M 字节 的上下文窗口。此外,MambaByte(Wang et al., 2024)证明了在 FLOP 受限条件下,Mamba 结构在多个数据集上优于 MegaByte。
然而,现有方法大多依赖于 特定模态优化(modality-specific optimizations)或 模型特定特征(model-specific features),限制了其泛化能力。
此外,虽然 Perceiver IO(Jaegle et al., 2022) 提出了基于 潜在表示(latent representation)的跨模态方法,但至今仍缺乏在多模态任务(如视觉问答)上的 BLM 研究。因此,MBLM 旨在弥补这些空白,实现真正的 模型无关(model-agnostic) 和 模态无关(modality-agnostic) 设计。
3. 方法
3.1 MBLM 结构
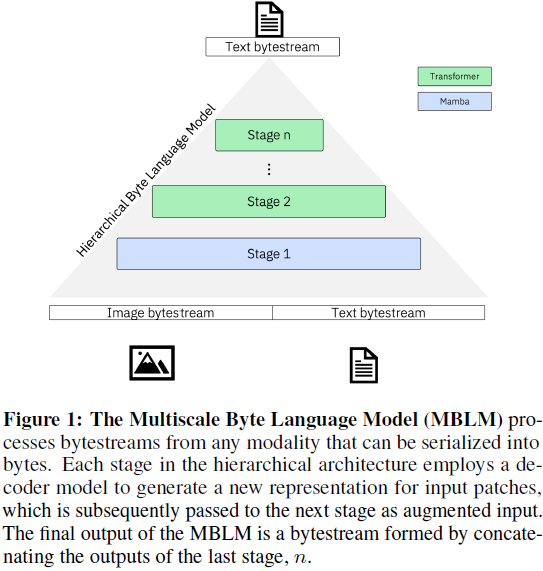
MBLM 采用 层级因果解码(hierarchical causal decoding),包含 N 层解码器:
- 前 N-1 层作为 全局模型(Global Model),主要对输入字节流进行上下文压缩。
- 第 N 层作为 局部模型(Local Model),负责最终的字节预测。
MBLM 的核心思想是 将长序列嵌入成小块(patches),并通过多个层级逐步精炼表示,从而实现高效的计算和存储管理。
3.1.1 块嵌入(Patch Eembedder)
1)采用 256 维字节词汇表,嵌入维度为 D_N。在每个阶段 i 为输入 x 中的字节分配嵌入向量,并加入位置编码。
![]()
2)将 x^{emb}_i 重塑为 Patch 嵌入 P^emb 的嵌套序列,使得序列长度 L_max = P_1 × P_2 × ... × P_N。
![]()
- 如果 L 不能分解为 P_1 × . . . × P_N,则内部序列长度 P_2 到 P_N 将用填充 token 填充。
- 如果 L > L_max 且未应用位置嵌入,我们还允许 P_1 大于指定值,通过扩展第一个全局模型的上下文窗口,使 MBLM 能够对更长的输入进行操作。
3)将 token 嵌入投影为全局阶段的 patch
- 回想,每个阶段的 Patch 嵌入具有相同的形状 P^{emb}_i ∈ R^{B×P_1×...×P_N×D_N}。
- 对于每个阶段,将嵌入展平(flatten),并应用线性投影,使其符合该阶段的模型维度:
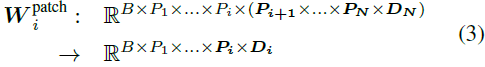
- 然后,在每个 patch P_i 的开头 添加一个可训练的起始 token E^{pad}_i ∈R^{D_i},并在投影过程中丢弃最后一个 patch 以匹配长度:
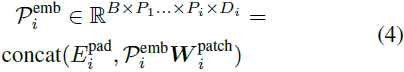
3.1.2 全局模型投影
全局模型通过捕获 Patch 之间的依赖关系并输出更新的 Patch 表示来执行 Patch 间建模。
为了用各层 Transformer 或 Mamba 模块 M_i 并行处理 P^{emb}_i 中包含的所有 patch,我们将 P^{emb}_i 重塑为新的 batch 维度 K_i:
![]()
全局模型对各 patch 进行信息聚合,并在每个阶段投影到下一级。
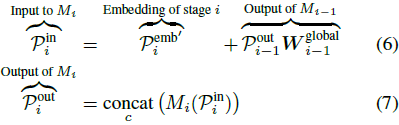
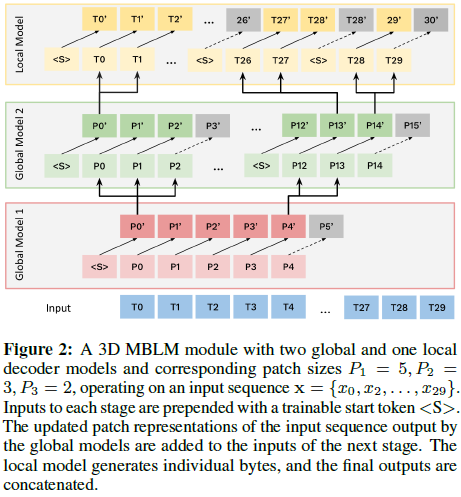
所有模块并行处理 Patches。为了提升计算效率,所有除第一层的全局模型都采用 梯度检查点技术(Gradient Checkpointing),减少显存占用。
3.1.3 局部 Patch 内建模
与主要作用是将 patch 上下文化(contextualize)的全局模型不同,局部模型通过从位于 P_{N,0} 的可训练起始 token 开始自回归预测单个字节来执行字节级 patch 内建模。我们通过 梯度检查点 提供与全局模型相同的并行性权衡。
预测 logits 通过交叉熵损失进行优化,目标是 最小化下一个字节的预测误差。
3.2 分层模型
MBLM 可支持 不同的解码器模型,包括:Transformer、Mamba 和混合架构(Hybrid Architectures)
采用 混合 Mamba-Transformer 架构,在计算效率和性能之间实现良好平衡。
(2023,SSM,门控 MLP,选择性输入,上下文压缩)Mamba:具有选择性状态空间的线性时间序列建模
(2024|ICML,Mamba2,SSD,SSM,SMA,矩阵变换,张量收缩,张量并行)Transformer 是 SSM
(2024,Attention-Mamba,MoE 替换 MLP)Jamba:混合 Transformer-Mamba 语言模型
(2024,Jamba1.5,ExpertsInt8量化,LLM,激活损失)大规模混合 Transformer-Mamba 模型
3.3 数据集与评估
1)数据集:
PG19(Project Gutenberg,文本任务):
- 包含 11.6GB 的文本数据(28,752 本书)。
- 适用于 超长文本建模。
CLEVR(视觉问答任务):
- 包含 70,000 张 RGB 图片 和 700,000 个问答样本。
- 评估 MBLM 在 跨模态任务 上的表现。
2)评估指标:
- Bits-Per-Byte(BPB):度量模型对每个字节的预测能力,值越低越优。
![]()
- 词级困惑度(Perplexity, PPL):用于文本任务的通用评估标准。
- 视觉问答任务的准确率。
4. 实验结果
对于长字节序列的建模,我们利用 MBLM 在每个阶段组合不同模型的能力,并将 Transformer 解码器与 Mamba-2 模型以不同的方式组合。
所有模型都按其维度引用;
- 1D MBLM 仅包含一个具有 Transformer 解码器或 Mamba-2 模型的阶段。
- 3D MBLM 由一个全局 Mamba 和两个 Transformer 解码器组成
4.1 语言建模扩展
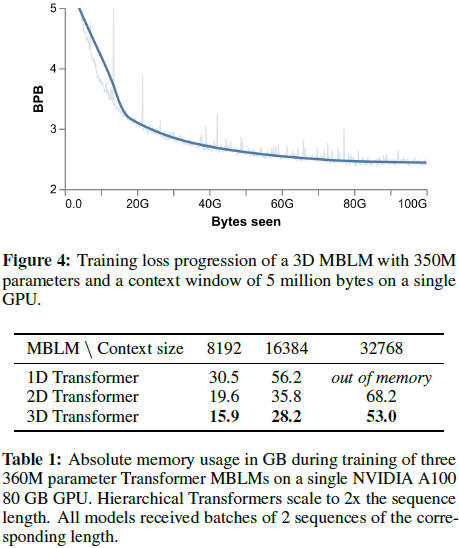
采用 350M 参数的 3D MBLM,可在单张 A100 GPU 上训练 5M 字节上下文窗口。经过超过 15 个小时的训练,这个 350M 的参数模型处理了 100 GB 的 UTF-8 字节,并在 PG19 测试集上实现了 2.448 BPB。

相比 MegaByte,MBLM 可处理更长的上下文,同时保持高效计算。
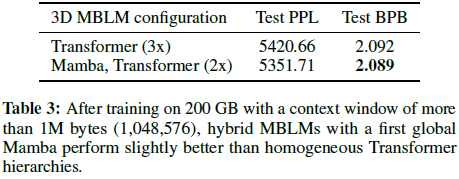
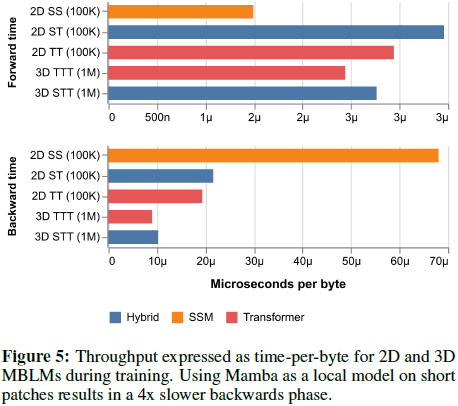
混合 Mamba-Transformer 架构在 100K+ 字节任务上优于纯 Transformer MBLM。
4.2 字节级视觉问答任务
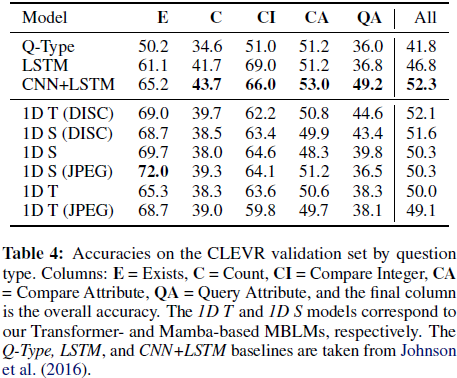
MBLM 在 CLEVR 任务上表现与 CNN-LSTM 基线相当,甚至在“存在性(Exists,E)”任务上表现更优。
JPEG 文件直接建模 方式提高了模型的泛化能力,证明了字节级模型的跨模态潜力。
5. 讨论
在本研究中,我们提出了一种 多尺度字节语言模型(Multiscale Byte Language Model, MBLM),这是一种 分层的、模型无关的架构,能够在单张 GPU 上扩展至 最长 500 万字节的序列。MBLM 采用 分层结构,在每个阶段使用独立的 自回归模型。输入的字节序列被划分为小块(patches),经过嵌入和层级精炼,最终由局部模型进行字节级自回归预测。这一方法通过压缩机制,实现了对超长字节序列的高效处理。
我们的语言建模实验证明了 MBLM 可以处理前所未有的超长序列。虽然 基于 Mamba 的层级架构 取得了最佳性能,但 混合架构——即 全局层采用 Mamba,局部层采用 Transformer 解码器,在性能与计算效率之间达到了最佳平衡。混合模型不仅 收敛速度更快,在推理阶段还展现出 近乎线性的生成效率。此外,我们对字节级语言模型在视觉问答任务中的首次评估发现,即使 仅使用语言建模头并从多模态字节流中学习,自回归模型的性能仍能与 CNN 结构的基线模型相媲美。
我们建议进一步扩展 MBLM 的评估,涵盖需要超长上下文的任务,例如多模态文档摘要 或 “大海捞针” 检索任务(needle in a haystack tasks),并研究 MBLM 在数十亿参数规模下的表现。目前,MBLM 已在 GitHub 和 PyPi 发布,提供了 模块化且灵活的框架,便于进一步开发。其扩展能力可通过张量并行(tensor parallelism)或模型分片(model sharding) 进一步增强,并且能够无缝集成到不同层级的解码器模型 之中。
通过适当的技术扩展,我们相信 MBLM 具备处理“千万级”字节序列的潜力。这些能力使 MBLM 成为超长字节序列建模的坚实基础,并有望推动未来层级化架构的创新发展。
论文地址:https://arxiv.org/abs/2502.14553
项目页面:https://github.com/ai4sd/multiscale-byte-lm
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群
合作联系同上,请备注说明


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









