







RegMix: Data Mixture as Regression for Language Model Pre-training

目录
5.5 数据混合的影响是否遵循扩展法则(Scaling Laws)
1. 引言
在大规模语言模型(LLMs)预训练过程中,数据混合的选择显著影响模型性能。然而,如何确定最优数据混合仍然是一个未解决的问题。本文提出了一种新的方法——RegMix,将数据混合问题建模为回归任务,通过训练小规模模型来预测不同数据混合的影响,从而自动选择高性能的数据组合。
主要贡献包括:
- 提出 REGMIX,利用小规模模型的实验结果,训练回归模型来预测大规模模型的最佳数据混合。
- 通过 512 个 1M 参数的小模型训练回归模型,并用于预测 64 个 1B 参数模型的最佳数据混合。
- 证明 RegMix 在 多种基准任务上超越了人类选择的数据混合策略,并且相比 DoReMi 方法,仅使用 10% 的计算资源就能获得相似或更好的效果。
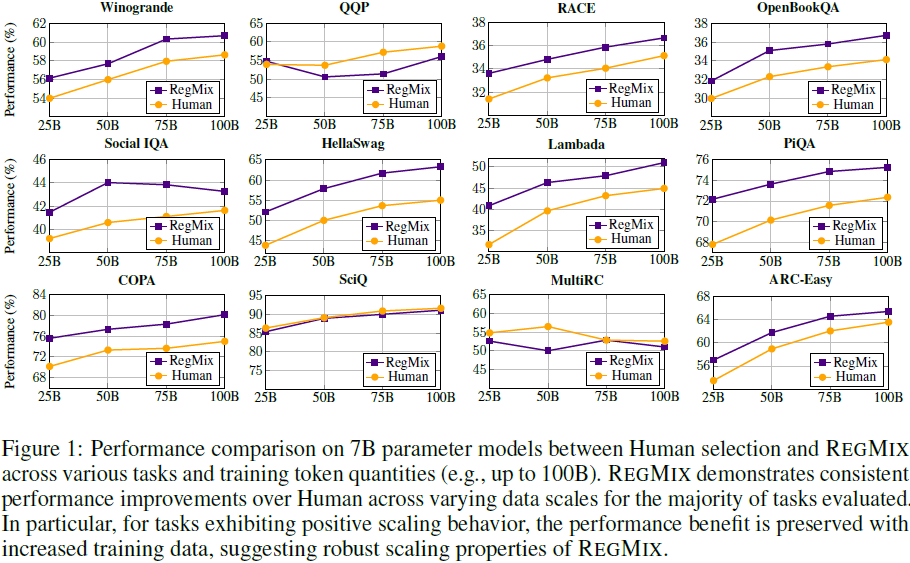
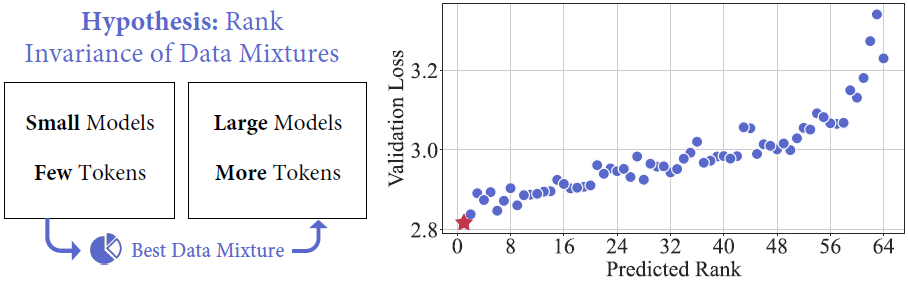
图 2:
- 左图:我们假设数据混合在模型大小和训练 token 数量上具有秩不变性。利用这一假设,我们使用在较少 token 上训练的小型模型来预测训练具有更多 token 的大型模型的有效数据混合。
- 右图:通过训练 512×1M 模型,我们的方法在训练 64×1B 模型之前确定了最佳数据混合。预测的最佳数据混合(用红星表示)实现了最低的验证损失。
研究表明:
- 数据混合对下游任务的影响极大,甚至可导致 14.6% 的性能差距。
- Web 语料(如 CommonCrawl)比 Wikipedia 更有利于模型性能。
- 不同数据领域之间的交互关系复杂,常常违反直觉,因此自动化方法(如 REGMIX)是必需的。
- 数据混合的影响超越了 Scaling Laws(扩展法则),需要额外建模数据交互。
2. 相关工作
2.1 数据选择与数据混合
- Token 级选择:基于 token 进行数据筛选(如 Lin et al., 2024)。
- 样本级选择:选择单个训练样本(如 Thakkar et al., 2023)。
- 分组级选择(Group-Level Selection):对数据集进行分组并调整混合比例(如 DoReMi)。
2.2 数据扩展法则(Scaling Laws)
- 数据扩展法则探索数据量、质量和混合比例的关系,预测不同数据组合的影响。
- 近期研究(如 Hoffmann et al., 2022; Ye et al., 2024)表明,不同数据集需要不同的扩展策略。
- REGMIX 提供了一种直接优化目标指标的方式,而非依赖静态扩展法则。
3. RegMix 方法
3.1 方法概述
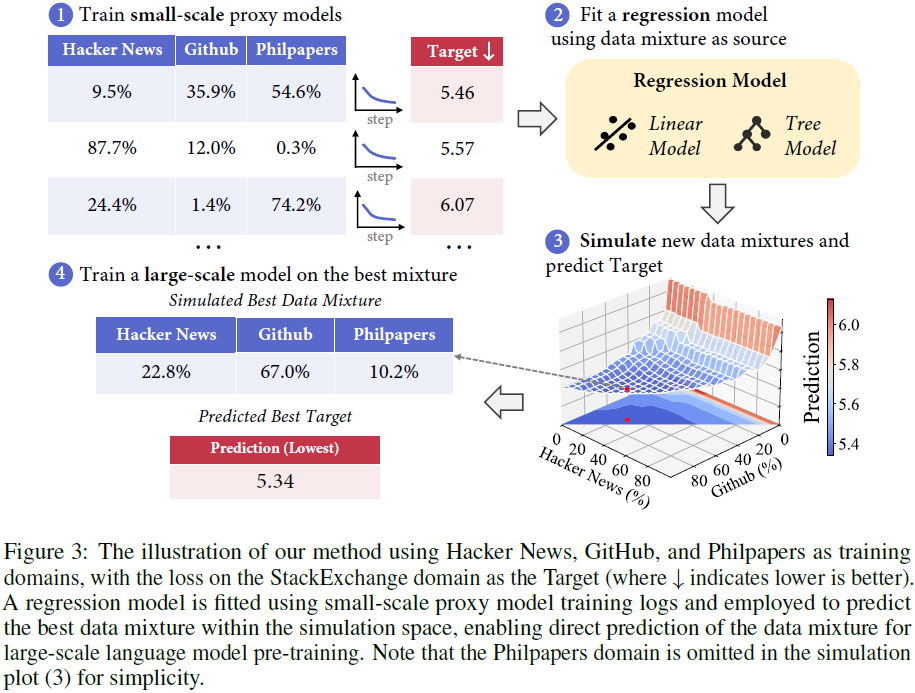
RegMix 主要包括以下 4 个步骤:
- 训练小规模代理模型(proxy models):在不同的数据混合上训练小规模模型(如 1M 参数)。
- 拟合回归模型:使用线性回归(Linear Regression)或 LightGBM 预测数据混合的性能。
- 模拟并预测最优数据混合:在大规模模型训练前,利用回归模型搜索最优数据混合。
- 大规模模型训练:在预测的最佳数据混合上进行大规模训练(如 1B 参数模型)。
3.2 小规模代理模型训练
- 通过 Dirichlet 分布 采样不同的数据混合,使得训练数据具有广泛的多样性。
- 训练 512 个 1M 参数的小规模模型,并在 1B tokens 上训练。
- 计算这些模型的验证损失,用于训练回归模型。
3.3 回归模型
线性回归(Linear Regression):通过最小二乘法(OLS)拟合数据混合与验证损失之间的关系。
LightGBM:
- 通过梯度提升树(gradient-boosting tree,GBT)建模数据混合与性能之间的复杂关系。在回归的背景下,LightGBM 学习一组决策树来预测目标变量。
- 在实验中表现 优于 线性回归,尤其是在大规模模型预测中。
3.4 预测与大规模模型训练
- 通过回归模型在 1M 数据混合 上进行快速模拟。
- 选择 前 100 个最优数据混合 进行加权平均,提升泛化能力。
- 在最终的 1B 参数模型上训练 25B tokens,以验证方法的有效性。
4. 回归预测评估
4.1 实验设置
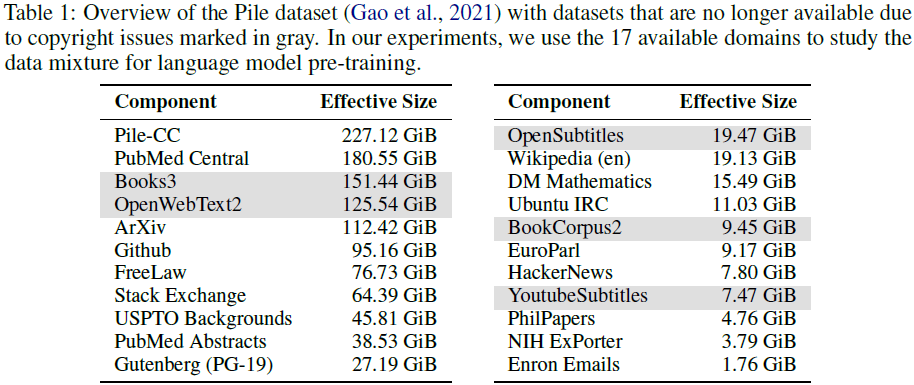
数据集:使用 The Pile 语料库的 17 个可用子集(如 Wikipedia、GitHub、CommonCrawl)。
模型规模:
- 小规模(1M 参数)→ 训练 512 个代理模型
- 中等规模(60M 参数)→ 训练 256 个模型
- 大规模(1B 参数)→ 训练 64 个模型
4.2 主要结果
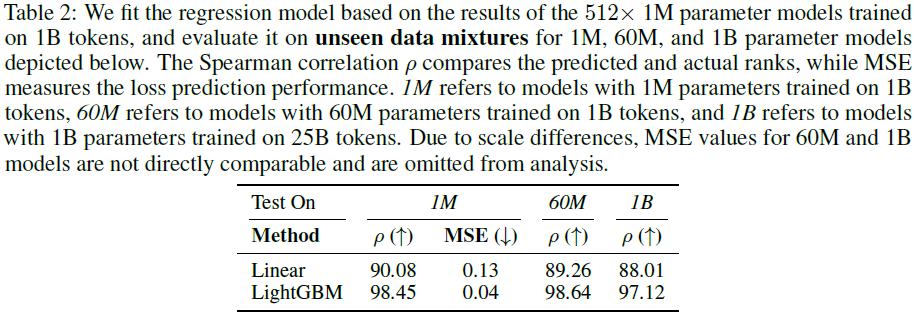
LightGBM 预测性能更优,Spearman 相关系数(ρ)可达 99.53%。
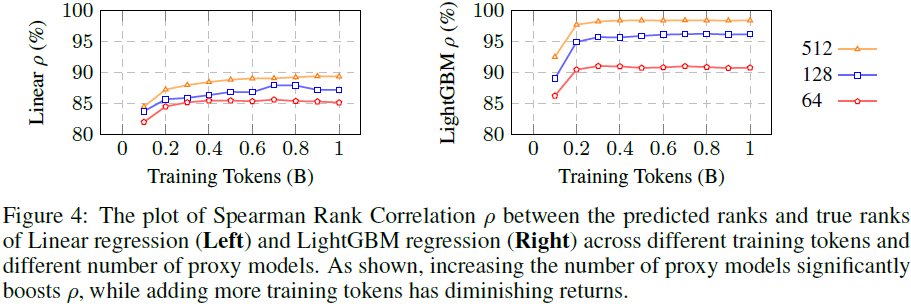
增加代理模型数量 比 增加训练 token 更有效。
5. 下游任务评估
5.1 数据混合影响
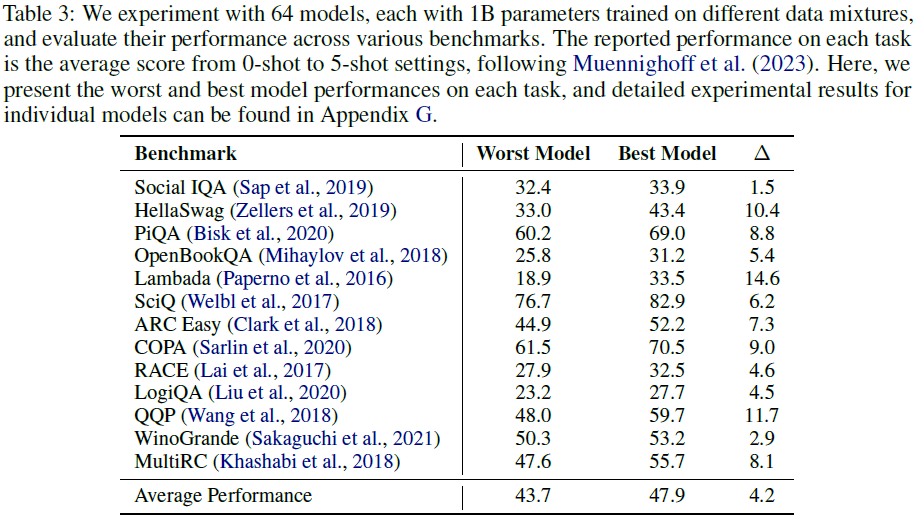
训练 64 个 1B 参数模型,比较不同数据混合对下游任务的影响:最大性能差异达到 14.6%(Lambada 任务)。这强调了研究最佳数据组合的重要性。
5.2 Web 语料比 Wikipedia 更优
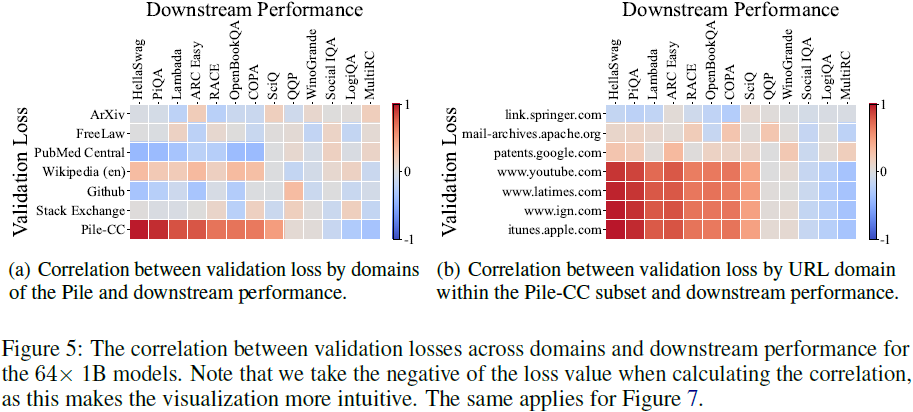
Pile-CC(Web 语料)与下游任务性能相关性最高,优于 Wikipedia。Web 语料的话题和域多样性可能是关键因素。
5.3 REGMIX vs. 其他方法
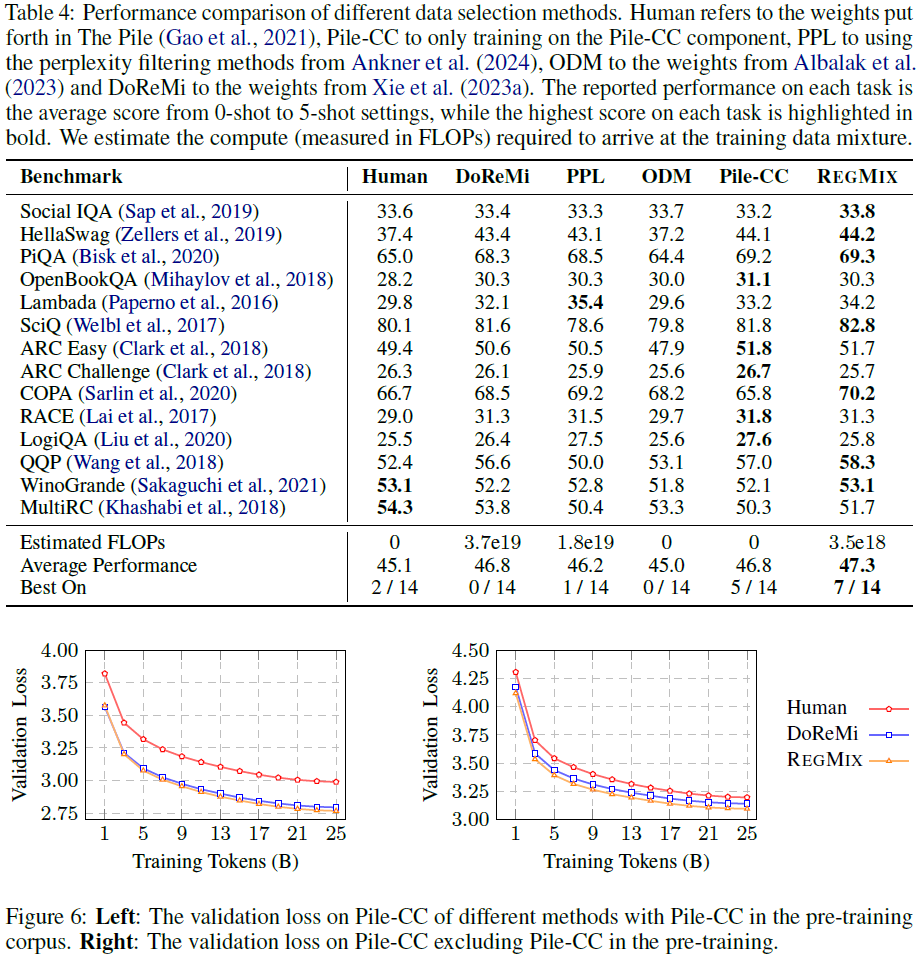
REGMIX 超越了 DoReMi、PPL 和 Human 选择,在 7/14 个任务上表现最佳。
计算成本(FLOPs)仅为 DoReMi 的 10%,但性能相当或更优。
5.4 数据域交互的复杂性
传统认为数据混合的优化可以基于独立数据集的效果进行加权。然而,数据域之间存在复杂的相互作用,使得人工选择变得困难。
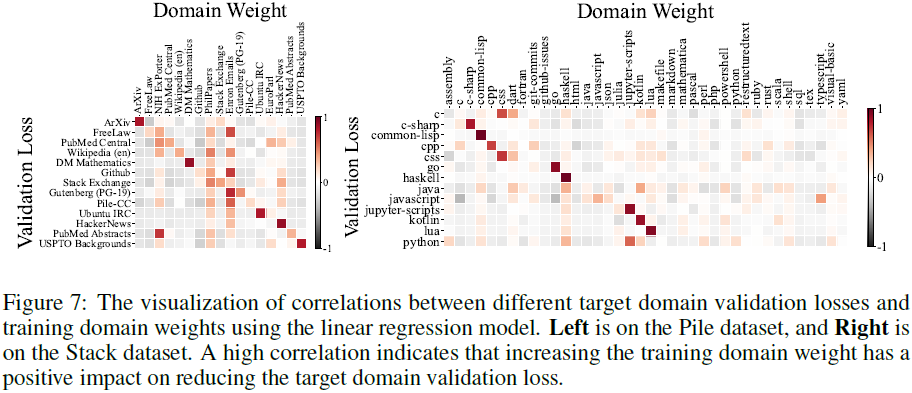
通过 线性回归系数分析,我们发现某些数据域(如 PhilPapers)对所有其他领域都有正向影响。
数据域之间的影响并不符合直觉,例如:
- GitHub 数据对 Stack Exchange 数据的影响并不明显。
- Wikipedia 训练损失与下游任务的相关性较低。
结论:
- 人工选择数据混合的策略可能会忽略关键的交互效应。
- 自动化数据混合方法(如 REGMIX)能够捕捉这些复杂的交互关系,提高 LLM 训练效率。
5.5 数据混合的影响是否遵循扩展法则(Scaling Laws)
在许多研究中,扩展法则(Scaling Laws)被用于预测数据混合的影响。然而,我们的实验表明,数据混合的影响并非简单的 log-log 关系。
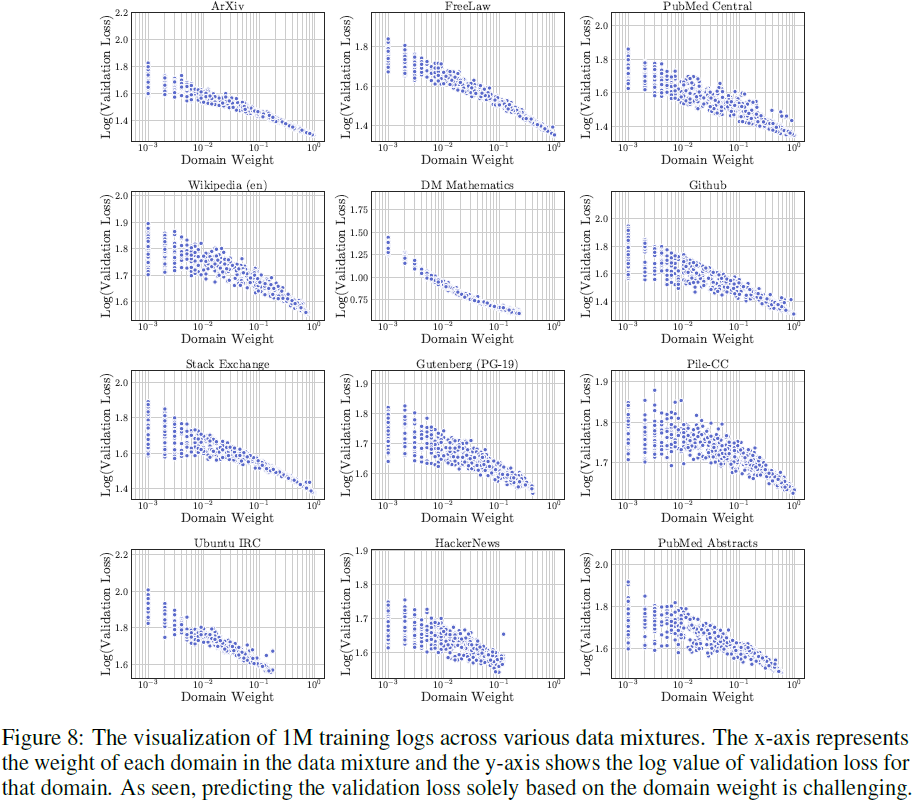
扩展法则 vs. 真实数据
- 某些领域(如 DM Mathematics)确实符合扩展法则,损失与数据比例呈线性关系。
- 但大多数领域(如 Pile-CC)表现出复杂的非线性关系,难以通过传统扩展法则预测。
结论:
- 扩展法则可能无法准确预测数据混合的影响,需要引入更复杂的建模方法。
- REGMIX 通过回归建模整个数据混合空间,能更精确地优化数据比例。
5.6 REGMIX 在 100 个数据域上的扩展能力
为验证 REGMIX 的可扩展性,我们将数据混合从 17 个域扩展到 100 个域,并训练 1000 个小规模模型进行预测。
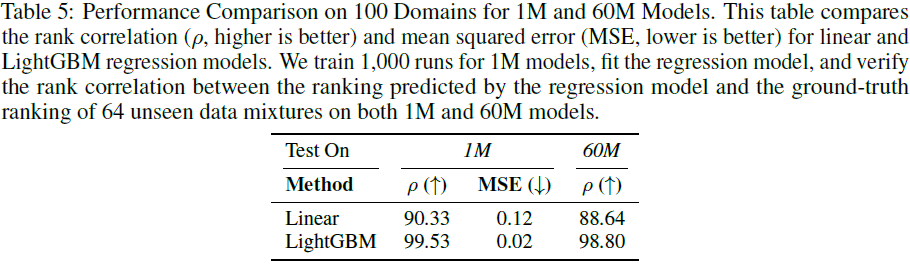
结论:
- REGMIX 在 100 个数据域上依然能够准确预测最佳数据混合。
- LightGBM 的 Spearman 相关性达到了 99.53%,表明该方法能精准捕捉数据混合影响。
6. 结论
REGMIX 提供了一种高效且自动化的数据混合优化方法,通过训练小规模模型来预测大规模模型的最佳数据混合。实验验证了数据混合对下游任务的影响巨大,并且 Web 语料优于 Wikipedia。REGMIX 在计算成本远低于 DoReMi 的情况下,仍能匹配甚至超越其性能。
论文地址:https://arxiv.org/abs/2407.01492
项目页面:https://github.com/sail-sg/regmix
进 Q 学术交流群:922230617


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









