







Seed-Thinking-v1.5: Advancing Superb Reasoning Models with Reinforcement Learning
目录
4.1 监督微调(Supervised Fine-Tuning, SFT)
4.2 强化学习(Reinforcement Learning, RL)
1. 引言
本文提出了推理模型 Seed-Thinking-v1.5,采用 MoE 架构,激活参数为 20B,总参数为 200B。
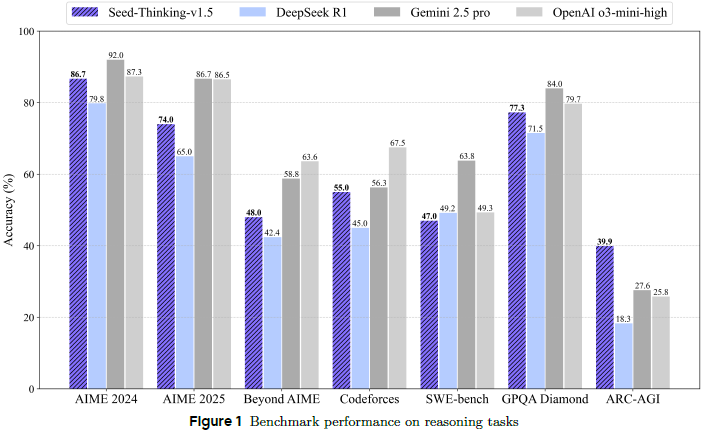
该模型在数学、编程和科学任务中表现出色。
-
数学推理方面:在 AIME 2024 中获得 86.7 的分数,与 OpenAI 的 o3-mini-high 模型相当,并显著超过 o1 和 DeepSeek R1,但仍与 o3 和 Gemini 2.5 存在差距
-
竞赛编程方面:使用 Codeforces 作为基准,采用近 12 场比赛中的 pass@1 和 pass@8 指标,其中 pass@8 更能反映用户提交习惯。Seed-Thinking-v1.5 在这两个指标上均优于 DeepSeek R1,虽然仍落后于 o3。
-
科学推理方面:在 GPQA 任务中获得 77.3 分的成绩,接近 o3 水准。这一进步主要得益于数学训练的泛化能力,而非增加了特定领域的数据。
-
非推理任务方面:通过与 DeepSeek R1 的对比,Seed-Thinking-v1.5 在真实用户场景下的人类评估中表现出色,正面反馈率提高了 8%,表明其在处理复杂用户任务方面具有更强的能力。
2. 数据
Seed-Thinking-v1.5 构建了用于强化学习训练的数据集,主要分为两类:可验证问题 与 不可验证问题。还构建了高级数学基准集 BeyondAIME
2.1 强化学习训练数据
2.1.1 可验证问题
该类数据具备确定性的标准答案,能用于自动验证,主要包括三类子任务:
1)STEM 数据
数据集中包含数十万道高质量的数学、物理和化学竞赛级问题,其中数学占比超过 80%。来源涵盖开源数据集、国内外竞赛题与私有题库。
通过数据清洗,最终形成约 10 万道清洗增强后的 STEM 题目。
2)编程数据
主要来源于高水平编程竞赛平台,题目配有清晰描述、单元测试与检查器脚本。训练中构建了本地离线评估集以代替在线提交验证。所有训练在自研代码沙箱中完成,确保执行稳定与反馈一致。
3)逻辑题数据
包括 22 类逻辑任务,如 24 点、迷宫、数独等。每类任务均构建了自动生成器与答案验证器,并能根据模型表现动态调节题目难度。共生成约 1 万道逻辑题目用于训练。
2.1.2 不可验证问题
此类数据缺乏标准答案,需借助人类偏好建模评估质量,任务类型包括:
-
创意写作
-
翻译
-
知识问答
-
角色扮演等
数据来源于 Doubao 1.5 Pro 的 RL 数据集。为提升数据质量,进行了如下筛选:
-
删除评分方差低的样本;
-
删除在 Doubao 1.5 Pro RL 中分数提升过快的样本,避免过拟合;
-
使用奖励模型对候选样本进行成对评分,从而理解人类偏好。
2.2 高级数学基准集:BeyondAIME
为弥补 AIME 每年仅 30 题、区分度不足的问题,研究团队构建了新基准集 BeyondAIME,包括 100 道高难度原创题:
-
题目由专家撰写,或对已有竞赛题进行结构和情境改写;
-
避免显性答案,降低猜中概率;
-
所有答案保证为整数,便于模型输出与评估一致。
该数据集显著提升了模型性能区分能力,为今后的数学推理研究提供重要基准。
3. 奖励建模
3.1 可验证问题的奖励建模

对于可验证问题(如数学、代码、逻辑推理),设计了两种渐进式奖励建模方案:
-
Seed-Verifier
基于人类精心设计的原则,利用大模型评估 “问题、参考答案、模型答案” 三元组。判断标准不是字面完全一致,而是依据数学规则与计算原理来确定两者在数学意义上的等价性。它能准确反馈模型答案是否本质正确,即使表述不同。 -
Seed-Thinking-Verifier
模仿人类评判思路,给出详细推理路径,并与数学任务共同优化。它能够解析参考答案和模型答案之间的相似与差异,做出精细且一致的判断。相比 Seed-Verifier,它解决了三大核心问题:- 奖励漏洞(Reward Hacking):模型通过投机取巧获取奖励而不理解问题,Seed-Thinking-Verifier 的细致推理大大降低了漏洞。
- 预测不确定性:例如对于 2^19 和 524288 这样的格式差异,Seed-Verifier 可能返回不稳定的 YES/NO,而 Seed-Thinking-Verifier 能给出稳定一致的结果。
- 边缘案例失效:面对复杂场景,Seed-Thinking-Verifier 能通过推理判断有效应对。
3.2 不可验证问题的奖励建模
对于不可验证问题(如创意写作、翻译、知识问答、角色扮演等),采用了:
-
成对生成式奖励模型(Pairwise Generative Reward Model)
其核心做法是:
-
比较两条响应的优劣,并用 “YES” 或 “NO” 的概率作为最终奖励分数。
-
该方法能直接比较响应的差异,避免模型过度关注无关细节。
实验发现,这种奖励模型在混合训练(即包含可验证和不可验证问题)场景下,能减少奖励信号之间的冲突,提高 RL 训练的稳定性。这主要归功于成对生成模型在缓解离群值打分方面的优势,避免与 verifier 模型之间产生显著的分布差异。
4. 方法
4.1 监督微调(Supervised Fine-Tuning, SFT)
用 40 万个样本训练,其中:
-
30 万个可验证问题
-
10 万个不可验证问题(创作、问答等)
工作流:
-
人工设计提示或对话
-
模型生成不同推理过程(CoT)
-
人工挑选高质量样本
-
用 Seed-Verifier 做拒绝采样(rejection sampling),提升长链推理质量
技术细节:
-
每个样本最多 32,000 tokens
-
学习率:2×10⁻⁵,逐步下降到 2×10⁻⁶
-
训练轮次:2 epoch
4.2 强化学习(Reinforcement Learning, RL)
三类数据:
-
可验证数据 → 用验证器(verifier)打分
-
非可验证数据 → 用奖励模型打分
-
混合数据 → 综合打分
核心技术:
-
值预训练(Value Pretraining):先用 SFT 策略数据更新 value 模型,保持一致性
-
解耦通用优势估计(Decoupled Generalized Advantage Estimation,GAE):value 和 policy 用不同参数,独立更新
-
长度自适应 GAE:根据输出长度调整误差分布
-
动态采样:只选梯度有效的样本,避免 “垃圾样本” 拖累训练
-
Clip-Higher:PPO 中单独调大正向截断范围,鼓励模型探索
-
逐 token 损失(Token-level Loss):每个 token 都参与损失计算,避免头尾失衡
-
正样本语言模型损失(Positive Example LM Loss):专门强化高质量样本的学习
当合并来自不同领域的数据并融入不同的评分机制时,面临数据领干扰的问题。可使用在线数据分布自适应(Online Data Distribution Adaptation):根据模型当前表现动态调整训练数据分布,实现多能力均衡提升。
5. 基础设施
5.1 框架
使用 HybridFlow 编程抽象 + Ray 集群
单个控制器负责调度,工作节点(Worker Group)负责模型训练和推理
采用 混合引擎架构,避免训练和生成任务切换时 GPU 闲置
为解决长文本生成的 “拖慢问题”,引入:SRS(Streaming Rollout System) 流式调度框架,把系统瓶颈从内存转为计算。
5.2 流式生成系统
按比例混合新旧模型生成的样本,动态调节 on-policy / off-policy 比例 α
动态精度调度:引入 FP8(8 位浮点)策略网络,降低计算成本
三层并行架构:
- TP(张量并行)→ 层内并行
- EP(专家并行)→ 动态分配专家模块(MoE)
- SP(序列并行)→ 按上下文分段(context chunking)
自动调优:系统实时监控负载,选择最优 CUDA 内核配置
5.3 训练系统
并行机制:结合 TP(张量并行)/ EP(专家并行)/ CP(上下文并行)和 FSDP(完全分片数据并行)来训练模型,其中,TP / CP 用于注意力层,EP 用于 MoE 层。
序列长度平衡:用 KARP 算法 平衡 micro-batches 负载,解决序列长度不均问题
内存优化:使用层级重计算、激活卸载、优化器卸载,通过重叠计算开销开支持更大的 micro-batches 训练。
自动并行:AutoTuner 根据内存使用预测、自动配置最优方案
检查点:用 ByteCheckpoint 灵活恢复不同配置的训练任务,提高集群利用率
6. 实验结果
6.1 自动评估结果
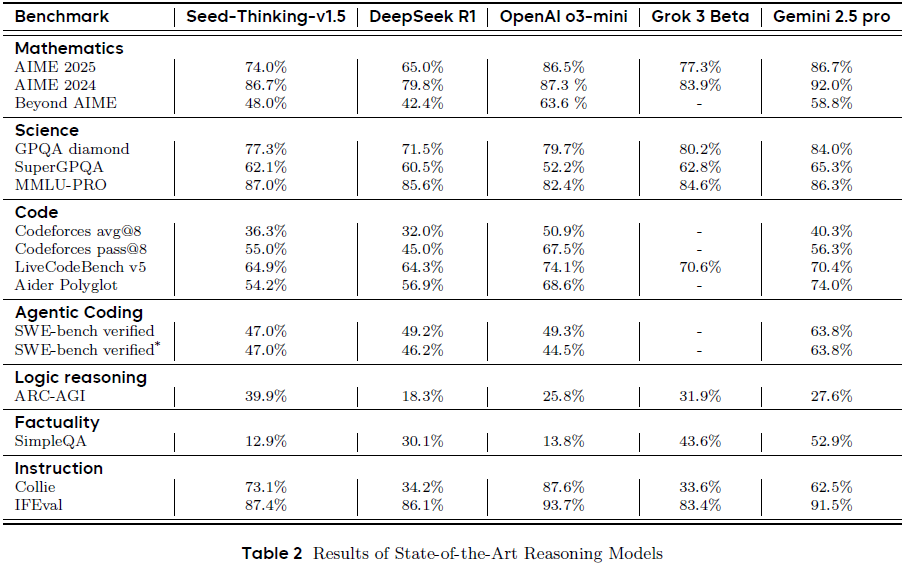
在 AIME 2024 达 86.7%,GPQA 达 77.3%,Codeforces pass@8 达 55%,在多个任务中接近或超越 SOTA 模型(如 o3-mini、Gemini 2.5 Pro)。
6.2 人类评估结果
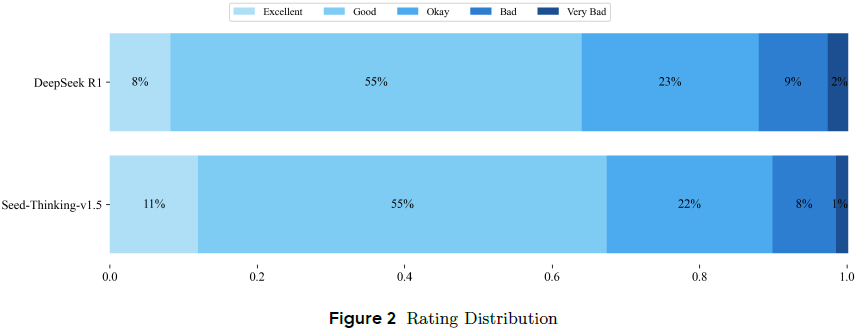
在非推理任务中优于 DeepSeek R1,平均胜率提升 8.0%,在人类评分中表现出更好的一致性和偏好对齐能力。
6.3 预训练模型的影响

实验显示 rejection fine-tuning(RFT)初始化会导致最终性能下降。RL 算法在不同架构和参数规模下保持一致排名,Qwen-32B 可作为算法 proxy。
论文地址:https://arxiv.org/abs/2504.13914
项目页面:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









