







学习时间 2022-9-3
学习内容
1、LeetCode 两道中等题
无重复字符的最长子串
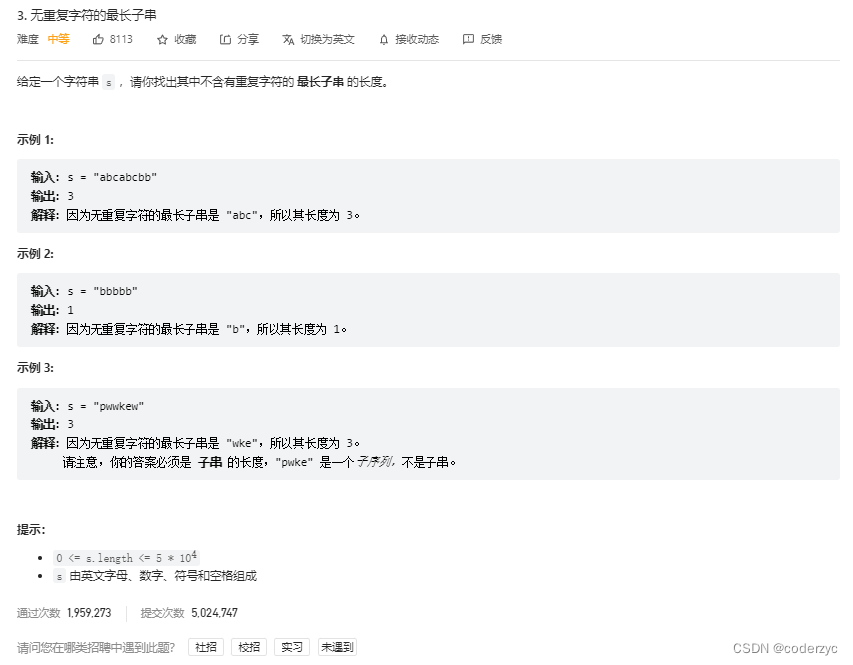
b站的模板:

做了一道题,目前的感觉是,不知道这个mx放哪里,什么时候去修改,可能需要根据不同的题目选取?
class Solution {
public int lengthOfLongestSubstring(String s) {
int L = 0;
int R = 0;
int mx = 0;
HashSet<Character> set = new HashSet();
int maxResult = 0;
char[] charList = s.toCharArray();
while(R<charList.length){//R是index
while(set.contains(charList[R])){
set.remove(charList[L++]);
mx--;
}
set.add(charList[R++]);
maxResult = Math.max(maxResult,++mx);
}
return maxResult;
}
}
等差数列划分
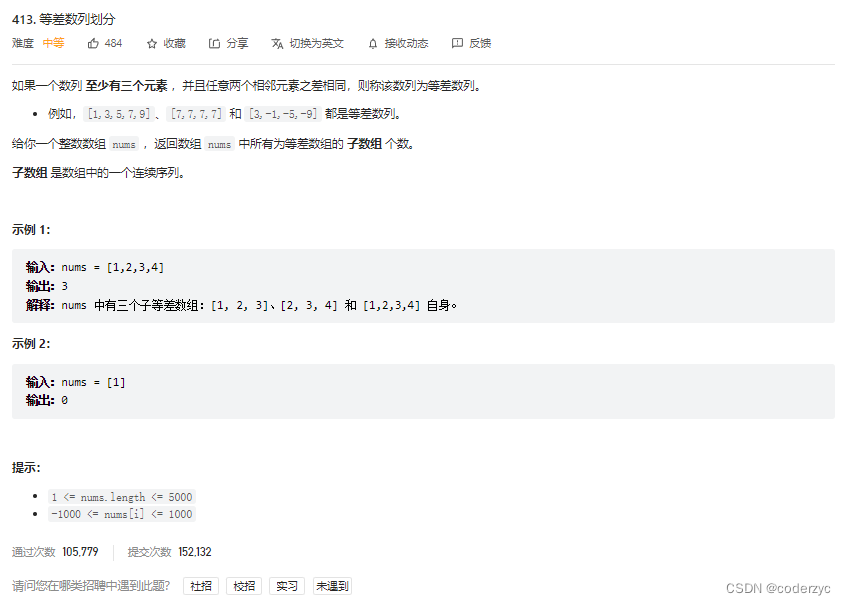
这里提供两种解法,一种是我想到的双指针写法,这个写法是我在看了滑动窗口以后思考到的,但是有点取巧的意思,里面把等差数列的值取出来了,将问题转化为:局部最长子串有多少个,每个有多长的问题
//双指针写法
class Solution {
public int numberOfArithmeticSlices(int[] nums) {
int n = nums.length;
if(n<3){
return 0;
}
int R = 2;
int L = 0;
int maxLen = 2;
int result = 0;
while(R<nums.length){
if(nums[R]-nums[R-1] != nums[R-1] - nums[R-2]){
//不是等差数列了
int lastR = R-1;
maxLen = Math.max(2,(lastR-L)+1);
L = lastR;
result+=getVal(maxLen);
}
R++;
}
//最后退出时,需要重新结算
maxLen = Math.max(2,(R-L));//这里加1减1抵消,因为出来的时候R多了一个
result+=getVal(maxLen);
return result;
}
int getVal(int len){
if(len == 2){
return 0;
}
int num = 1;
for(int i = 0;i<len-3;i++){
int acc = i+2;
num+=acc;
}
return num;
}
}
这道题也可以使用DP求解,但是这个dp条件有点怪
先附上leetcode中dp的相关描述

我的问题是,这个dp这里说的是nums[i]结尾长度大于等于3的等差数列个数,然而实际上,dp[i]并不是这个数,举例子,1,2,3,4,5 dp[4]的值是3,但其实5结尾的大于等于3的等差数列个数并不是3,而是dp1-dp5的和
//dp
class Solution {
public int numberOfArithmeticSlices(int[] nums) {
int len = nums.length;
if (len < 3) {
return 0;
}
// dp[i] 表示以:nums[i] 结尾的、且长度大于等于 3 的连续等差数列的个数
int[] dp = new int[len];
int res = 0;
// 从下标 2 开始,才有可能构成长度至少大于等于 3 的等差数列
for (int i = 2; i < len; i++) {
if (nums[i] - nums[i - 1] == nums[i - 1] - nums[i - 2]) {
dp[i] = dp[i - 1] + 1;
res += dp[i];
}
}
return res;
}
}
2、操作系统 第五章剩余内容
线程调度
在支持线程的操作系统上,内核线程是操作系统调度的,用户线程是由线程库调度的
竞争范围
用户线程和内核线程有一个区别在于他们的调度方式不同
对于实现多对一和多对多模型的系统线程库会调度用户级线程,让其可以在LWP上运行。这种方案叫进程竞争范围(PCS System-Contention Scope),因为他是在一个进程的不同线程之间的。
内核采用系统竞争范围(System-Contention Scope)。采用SCS调度发生在系统所有线程之间,采用一对一模型的系统,只采用SCS调度。
使用Pthreads调度 代码API查看

多处理器调度
调度方式
有两种方式
- 非对称多处理:一个处理器处理所有调度/IO,等系统活动,其他处理器只执行用户代码,这种代码简单,因为他简化了数据的共享
- 对称多处理(SMP):每个处理器有他自己的调度 必须确保他们不会选择同样的进程
处理器亲和性
由于将一个进程移动到其他处理器中时,对系统内存的消耗代价较大(旧进程需要清除,新进程需要备份),所以大部分的操作系统中进程都会运行在同一个处理器上,这种依赖就是处理器亲和性。
- 软亲和性 一个系统试图让进程运行在统一处理器上(不保证它一定会)
- 硬亲和性 必须在制定的处理器运行
系统的内存架构可能会影响处理器的亲和性
负载平衡
对于SMP而已比较重要,需要保证每个CPU都在忙碌中。以防止一个或多个处理器空闲,其他的处理器高负载的情况。对于有公共队列的操作系统,并不太需要负载平衡。因为当队列中有进程,就会及时的被处理器处理。
常用的两种方法:
- 推迁移 定时任务检查每个处理器的负载,如发现不平衡,则将高负载处理器中的进程push到空闲进程
- 拉迁移 与推迁移的from to 不同 从空闲进程pull
这两种任务通常并行执行,不相互排斥
负载平衡会破坏亲和性(会出现线程转移的情况)
多核处理器
将多个处理器放置在同一个物理芯片上,从而产生多核处理器
多核处理器的SMP比单核处理器的SMP更快,功耗更低
多核处理器的调度问题复杂,访问内存时会消耗大量时间。针对这种问题,现在很多硬件设计都采用了多线程的处理器核,每个核会分配到两个(或多个)物理线程。这样的话,当一个线程(这里的线程不是物理线程!)需要等待时,CPU切换到另外一个物理线程。
处理器核的多线程有两种:
- 粗粒度 当发生长时间等待的事件时切换
- 细粒度 在更细的粒度级别(通常在指令周期边界上)上切换线程
实时CPU调度
主要是一些对时效性要求高的软件需要(汽车系统等)
最小化延迟
这类系统考虑实时系统的事件驱动特性,通常这种系统等待一个实时事件的发生。这种事件发生到服务的这段时间称为事件延迟
有两种延迟会影响实时系统的性能:
- 中断延迟 从CPU收到中断到中断处理程序开始的时间(尽可能减少)
- 调度延迟 停止一个进程到启动另一个进程的时间 操作系统应该最大限度的减少这种延迟。这种延迟降低的有效技术是提供抢占式内核
优先级调度
实时操作系统的调度支持抢占的优先权算法,这种算法仅可以提供软实时功能,不能提供硬实时,需要附加调度特征,同时,这种调度具有的特点:周期性,需要根据周期性来增加调度的特征
截至期限:周期到的时候的时间
单调速率调度
抢占,静态优先级。要求进程是周期的
周期越短,优先级越高,周期越长,优先级越低。
单调速率调度可以被认为是最优的
调度N个进程的最坏情况CPU利用率为:N(2^(1/N)-1)
最早截至期优先调度(EDF)
根据截止期限动态分配优先级,截止时间越早,优先级越高,截止时间越晚,优先级越低
EDF调度不要求进程是周期的,也不要求CPU执行长度固定,只要求在可行时需要宣布他的截止日期。
比例分享调度
调度程序在所有应用之间分配T股,如果一个应用程序接收N股,则有N/T的总处理时间
准入控制策略:当请求股数小于总股数才可以进入
操作系统案例
这里只讲Linux和Windows 还有Solaris系统 建议在书中观看
Linux
默认调度算法:完全公平调度程序(CFS)
Linux的调度基于调度类,每一个类有特定优先级,不同内核针对不同的调度类。
CFS调度按比例给每个任务分配一定比例的CPU处理时间。每个任务的比例是根据他自身的友好值来计算的。这个值增加时,将会降低该任务的优先级,而因为降低了优先级,所以对其他的任务友好。CFS没有使用离散的时间片,而是目标延迟的方式让每个任务执行他应该执行的时间。
这个算法执行并不按照优先级,而是按照vruntime来维护虚拟运行时间,举个例子,如果一个任务默认优先级,需要200ms,那么他在更低优先级,他的vruntime大于200ms,在更高优先级,他的vruntime小于200ms,这个时间基于任务优先级的衰减因子。(具体在书中P160页查看)

Windows
Windows采用基于优先级的,抢占调度算法来调度线程。这里主要想说Windows的用户模式调度(UMS)
因为Windows用户交互较多,系统需要提供比较好的表现
当一个进程移动到前台,windows增加他的时间片,通常是原来的三倍,这个增加给前台进程3倍的时间来运行(在被抢占前)















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









