






前言
参考资料:
《TASKING VX-toolset forTriCore User Guide》
TASKING软件想必玩英飞凌芯片的道友们应该都会用到,然而还有很多人不知道如何提高编译速度。据说经常一次编半个小时。那么下面就告诉你如何提高编译速度。
一、How to Improve the compilation speed.
1.1、Cache generated code to improve the compilation speed
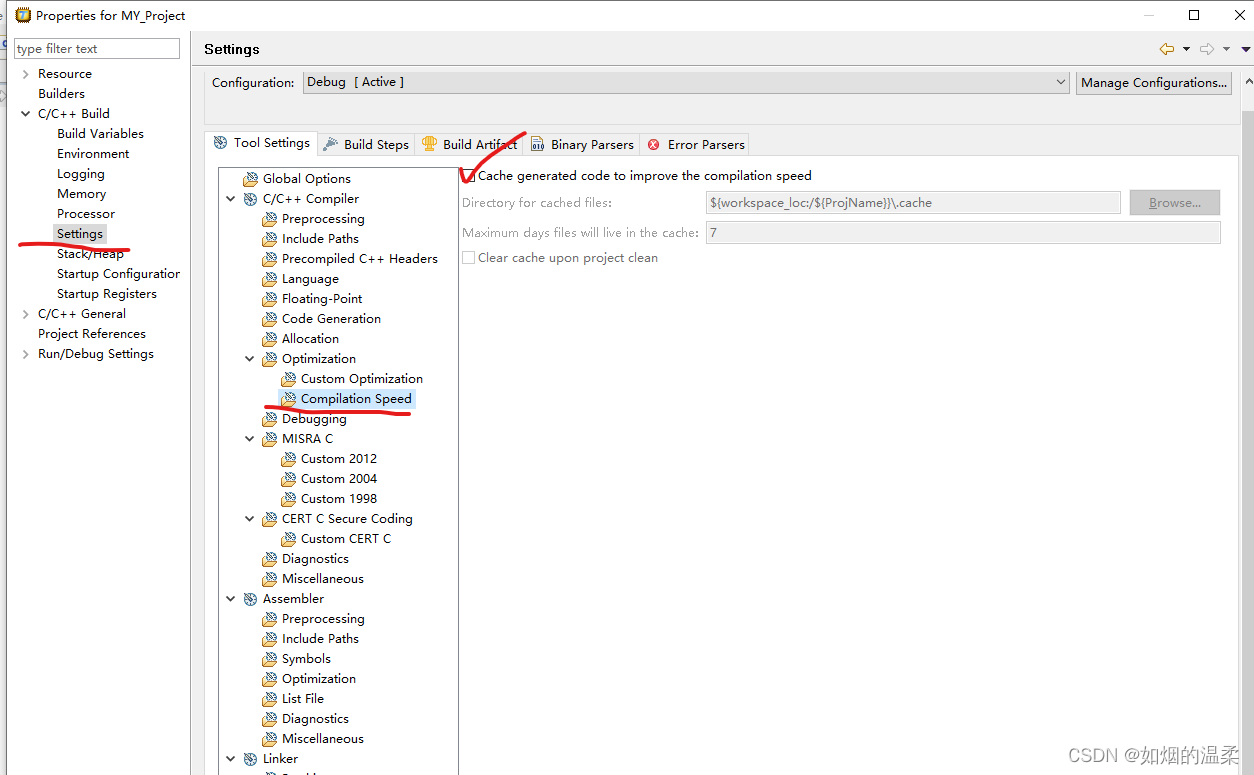
- 1、从工程路径选择Properties
- 2、选择C/C++ Build下的 Setting选项
- 3、找到C/C++ Compiler下的 Optimization
4、 选择Compilaton Speed
5、勾选如图选项,原理是第一次编译完之后给你生成缓存文件,后面再编直接使用缓存文件,就无需重复编译,加快了编译速度;
6、你可以指定缓存文件在缓存中存在的最大天数
原理:Eclipse使用选项——cache调用C编译器。缓存目录可以被共享,例如通过将其放在网络驱动器上。编译器在指定的目录下创建一个目录ctccache。
当使用缓存中的结果时,C编译器会在程序集源文件中生成注释行来通知它。在这种情况下,请注意:
每次编译导致缓存丢失的文件时,都会在缓存中存储一个新文件。旧文件不会自动从缓存中删除,因为这会大大降低编译器的速度。要保持缓存大小合理,请指定文件在缓存中存在的最大天数
1.2 Influencing the Build Time
SFR File(勾了可能会报错,好像得配合include一起用,暂未研究清除,仅供参考)
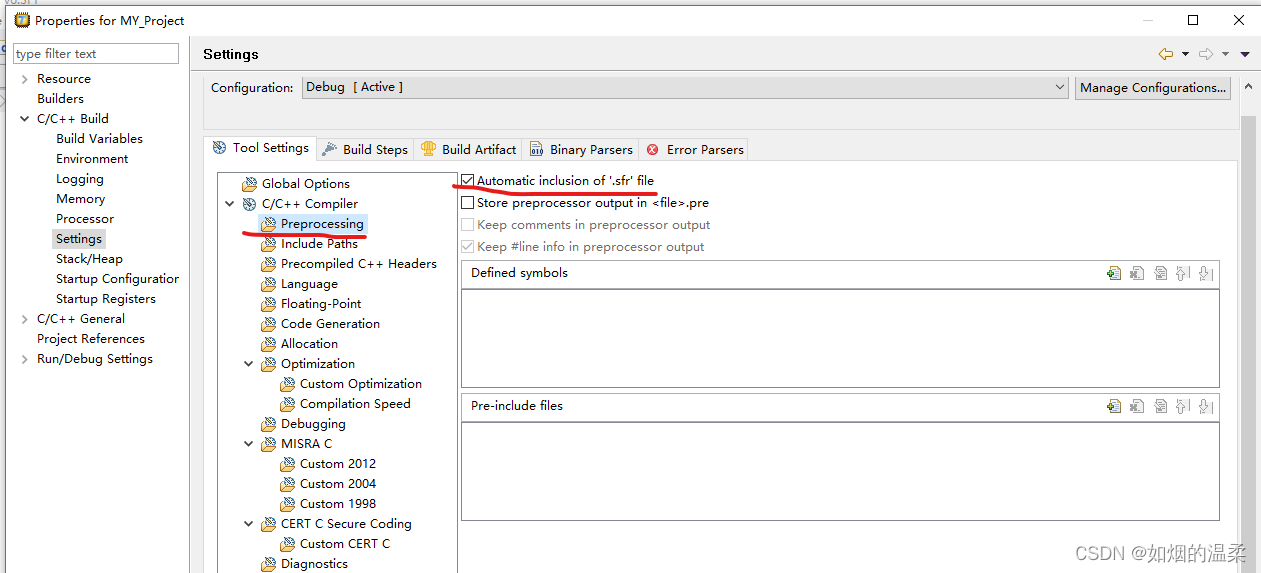
SFR文件可以定义大量的SFR,以至于仅编译SFR文件就已经占用了构建时间的很大一部分。
要减少构建时间:
•默认情况下,工具不自动包含SFR文件。您应该只在使用SFR的源模块中包含SFR文件,并使用#include指令。在Eclipse中,确保禁用自动包含选项。你可以在“C/ c++编译器”上找到这个选项
“预处理”和“汇编器»预处理”页面。
当您在源代码中包含SFR文件时,请注意SFR文件位于包含文件的SFR子目录中,因此您必须使用:#include < SFR /regtc1796b.sfr>
MIL Linking(选build faster)
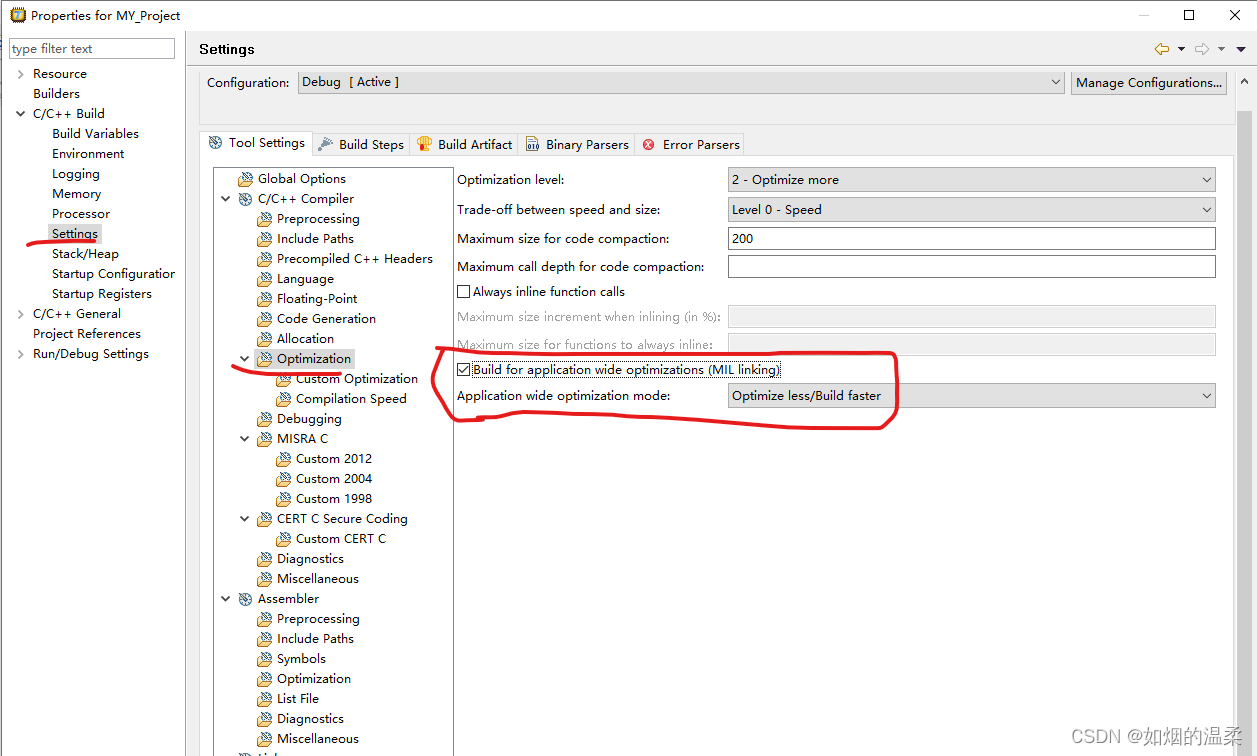
**原理介绍:**使用MIL链接(参见第4.6.1节,泛型优化(前端)),可以让编译器在应用范围内应用优化。这可以产生显著的优化改进,但构建时间也会明显延长。MIL链接本身可能需要大量的时间,而且更改的构建过程也意味着更长的构建时间。Eclipse中的MIL链接设置为:
- 构建应用程序范围的优化(MIL链接)Build for application wide optimizations (MIL linking)
勾选之后这将启用MIL链接。构建过程发生了变化:C文件被转换为中间代码
(MIL文件)和整个项目生成的MIL文件通过C编译器链接在一起。下一步取决于下面选项的设置。
有下面两个选择:
一般来说,如果您不需要代码压缩,例如,因为您正在为速度进行全面优化,那么建议选择Optimize less/Build faster
• Application wide optimization mode: Optimize more/Build slower
当启用此选项时,编译器将立即在完全链接的对象上运行代码生成器
MIL流,它代表整个应用程序。通过这种方式,代码生成器可以在应用程序范围内执行一些优化,例如“代码压 缩”。但这也需要更多的内存和更多的时间来生成代码。除此之外,增量构建也不再可能了。对于每个构建,必须完成完整的MIL链接阶段和代码生成,即使是在正常构建(不是MIL链接)中只需要5分钟的最小更改
• Application wide optimization mode: Optimize less/Build faster
当该选项被禁用时,编译器会在MIL链接后将MIL流拆分为单独的模块。
这允许只对修改后的模块执行代码生成,因此比启用其他选项要快。尽管MIL流在之后被分割为单独的模块
MIL链接,它仍然可能发生修改单个C源文件导致多个MIL文件。这是全局优化的自然结果,其中为多个模块生成的代码受到更改的影响。
Optimization Options
一般来说,任何优化都可能需要编译器做更多的工作。但这并不意味着禁用所有优化(级别0)可以获得最快的编译时间。禁用优化可能会导致生成更多代码,从而导致编译器的其他部分(例如寄存器分配器)承担更多工作
Automatic Inlining
自动内联是一种优化,它可能导致更长的构建时间。整体函数将变得更大,通常可以进行更多的优化。但也经常导致在一个函数中使用更多的寄存器,给寄存器分配一个更困难的工作。
Code Compaction
当禁用代码压缩优化时,构建时间可能会更短。当然,当使用MIL链接时,整个应用程序作为单个MIL流传递给代码生成。然而,代码压缩是一种优化,在优化代码大小时可以产生巨大的差异。
当大小很重要时,禁用此选项没有意义。当你选择优化速度(——tradeoff=0)代码压缩被自动禁用
Header Files
许多应用程序在每个模块中包含所有头文件,通常将它们全部包含在一个包含文件中。处理头文件需要时间。只包含模块中真正需要的头文件是一个很好的编程实践,因为:
模块使用哪些接口是很清楚的
•修改头文件后的增量构建导致需要重新构建的模块更少
•减少编译时间
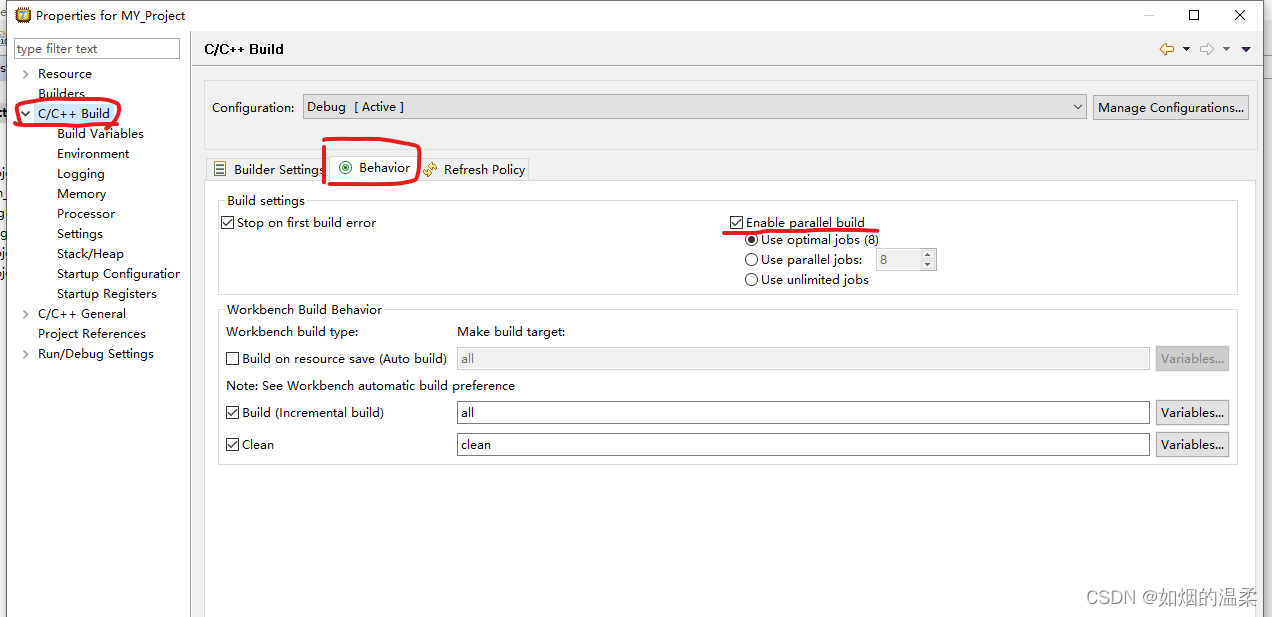
Parallel Build(并行编译)-- 这个一般是默认开启,检查一下就行。
Section Concatenation
默认情况下,链接器不会将具有相同名称的节合并为一个节。对于汇编程序选项——concatenate-sections,汇编程序使用section属性concat,指示链接器合并具有相同名称的section。区段串联的优点是定位速度更快,因为需要定位的区段更少。节连接的缺点是内存使用效率较低,因为(顺序连接的)节之间存在对齐间隙。
二、优化代码大小或执行速度Compiler Optimizations
1、一般选level2
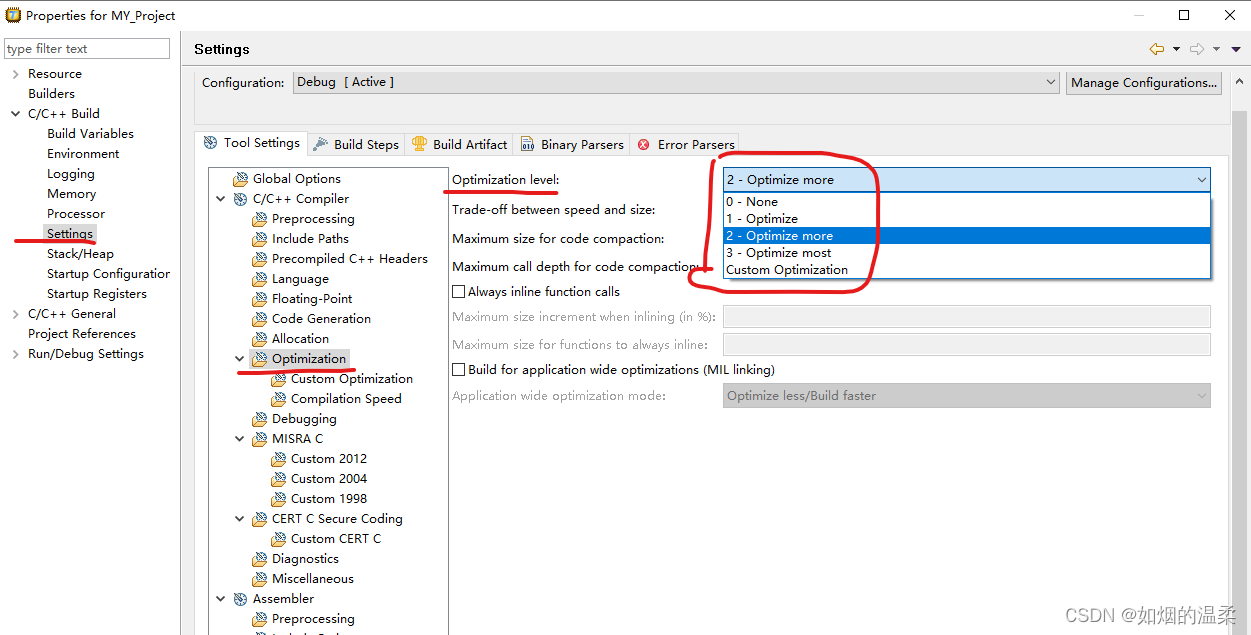
TASKING C编译器提供了四个优化级别和一个自定义级别,在每个级别上都启用了一组特定的优化。
-
Level 0 - Nooptimization:不执行任何优化。编译器试图在源代码和生成的代码之间实现1:1的相似性。表达式按照源代码中编写的顺序求值,不使用关联和交换性质。
Level 1 - Optimize:启用不影响源代码可调试性的优化。当您在使用优化级别2调试源代码时遇到问题时,请使用此级别。
Level 2 - Optimize more (default): 支持更多优化以减少内存占用和/或执行时间。这是默认的优化级别
Level 3 - Optimize most:这是最高的优化级别。当您的程序/硬件变得太慢而无法满足您的实时需求时,请使用此级别。
Custom optimization:您可以在自定义优化页面上启用/禁用特定的优化
如果指定了某种优化,则模块中的所有代码都服从该优化。在C源文件中,您可以使用#pragma optimize flag和#pragma endoptimize来否决C编译器的优化选项。允许嵌套:
例子:
#pragma optimize e /* Enable expression
… simplification /
… C source …
…
#pragma optimize c / Enable common expression
… elimination. Expression
… C source … simplification still enabled /
…
#pragma endoptimize / Disable common expression
… elimination /
#pragma endoptimize / Disable expression
… simplification */
编译器按照指定的方式优化编译对之间的代码。
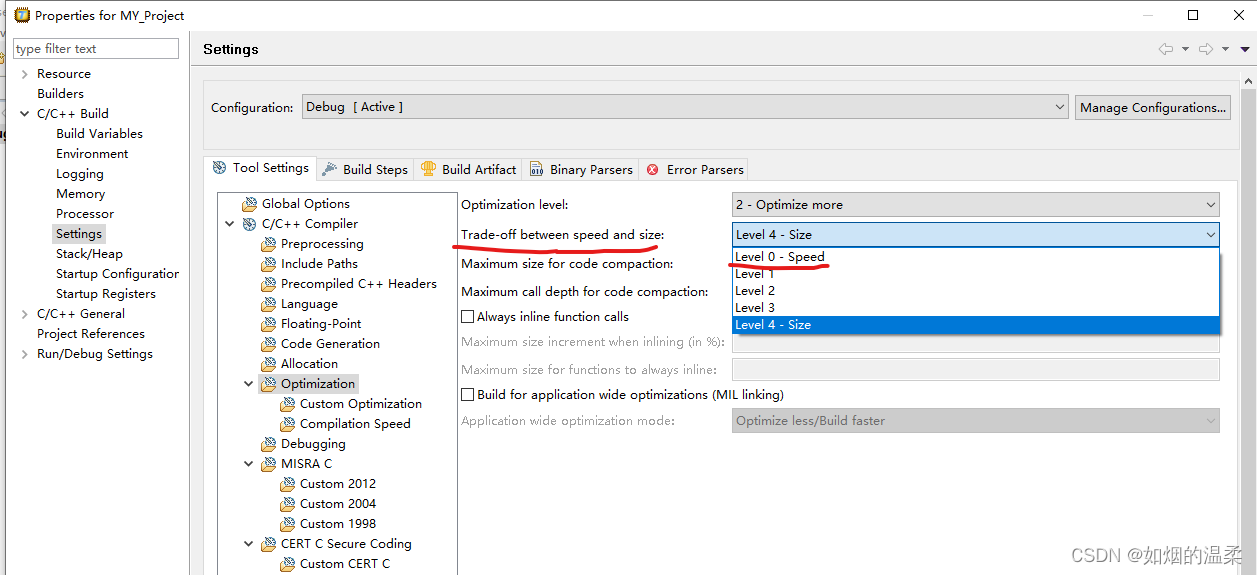
2.Optimize for Code Size or Execution Speed
您可以告诉编译器在优化期间关注执行速度或代码大小。您可以通过指定从0(速度)到4(大小)的大小/速度权衡级别来实现这一点。这种权衡不会打开或关闭优化阶段。相反,它的级别是一个权重因子,在不同的优化阶段使用它来影响启发式。级别越高,编译器就越关注代码大小的优化。
注意:代码优化会影响编译器编译产生的汇编语言,可能会导致报错;我一般选的Lever1;
要选择一个权衡值,请阅读下面的描述,了解哪些优化会受到影响,以及不同权衡值的影响。
总结
没写完的,有些原理还没研究清除;埋个坑;















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









