







本文为Multi-Grained Spatio-Temporal Features Perceived Network for Event-Based Lip-Reading的记录,原文见cvf。
来源:CVPR2022
作者单位:中国科学技术大学
摘要
1.本文介绍基于事件相机的唇读。
2.事件相机有更高的时间分辨率,更少的视觉冗余信息,更小的计算量。
3.本文提出MSTP提取微秒级细粒度特征。
4.MSTP包含两个帧率不同的分支。
5.低帧率提取空间信息,高帧率提取时间信息。
6.使用融合模块得到同时包含时空信息的特征。
7.提出的方法和事件相机比视频方法更优。
介绍
1.唇语识别是xxxxxxx可以xxxxxx。
2.本文使用事件相机,记录毫秒级变化,使网络可以提取细粒度时空特征。
3.目前有很多基于事件的动作识别研究。时间可以当做点云和图结构处理,但会损失细粒度时空信息。还可以用脉冲神经网络处理异步信息,但效果不好。目前的基于cnn的方法将事件数据转为定帧格式,但同样会损失细粒度时空信息。综上,唇读需要细粒度时空信息,但目前的方法不能满足。
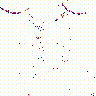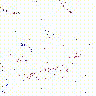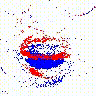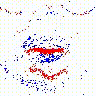
4.本文提出将事件数据转化为多粒度事件帧如图1所示(tsne为降维工具,将每帧高维特征图降至两个二维点)。
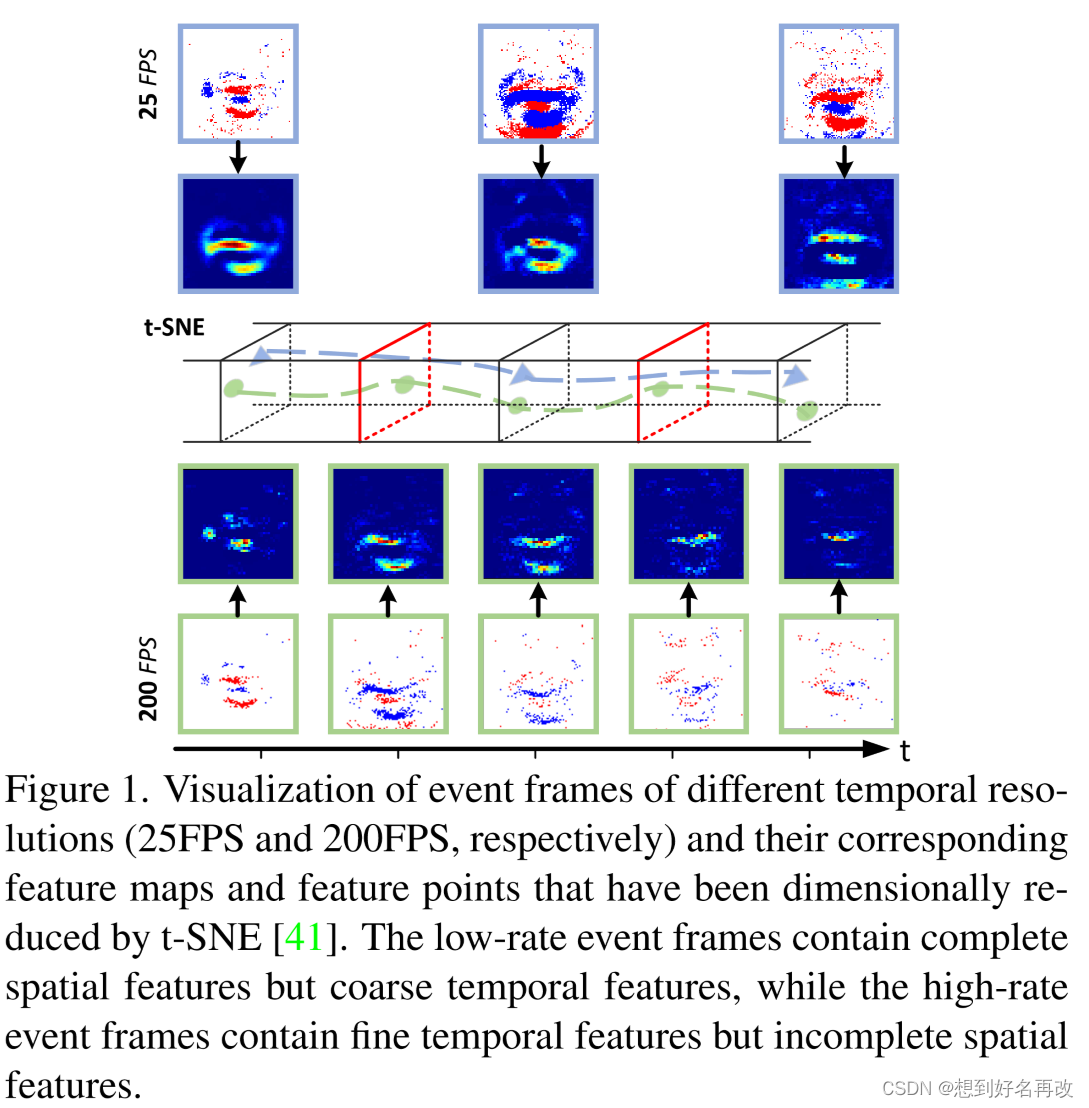
为了更好的利用细粒度事件信息,本文提出MSTP,包含高帧率和低帧率两个分支,使用MFM进行特征融合,学习更好的时空特征。
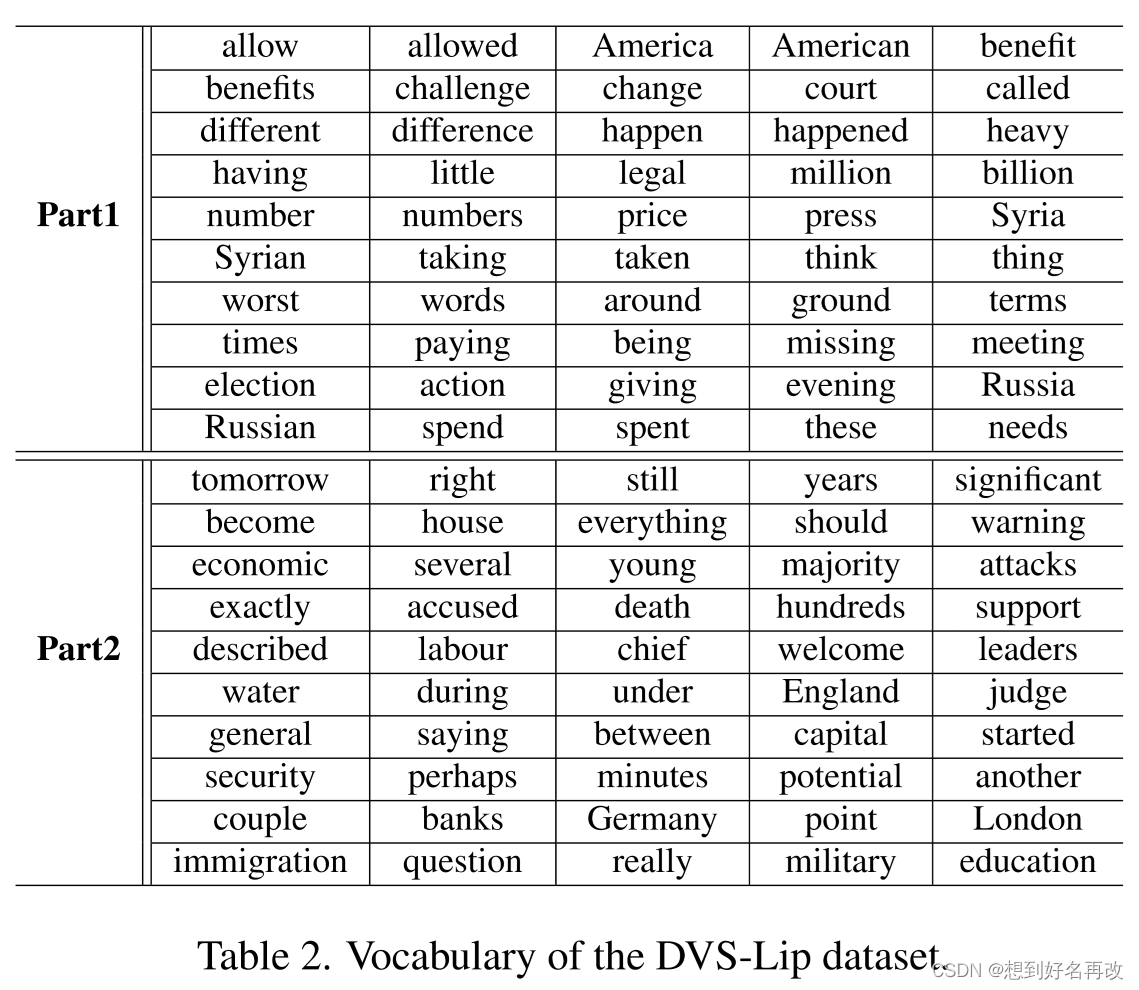
5.本文收集了一个事件唇读数据集DVS-LIP,包含19871个样本。为了研究网络细粒度特征提取能力,数据集标签包含两部分,第一部分是LRW数据集500个单词中25对视觉近似的单词,共50个。第二部分是随机选取的50个。共100个单词,具体信息如下表所示。
6.实验表明,MSTP精度比其他基于事件的动作识别sota高,且比使用视频的sota唇读高。
相关工作
1.唇读数据集:LRW,LRW-1000,LRS2,LRS3,xxxxxx。
2.唇读模型:MSTCN,BiGRU,xxxxxx。
3.事件相机:davis346。
4.基于事件的动作识别:点云,图,脉冲神经网络,cnn。
方法
事件数据
三维1×t×w×h时空散点数据
框架
事件表示
1.点云,图结点,脉冲神经网络不适合唇语识别,本文使用逐帧表示。
2.使用格栅下采样将原始时间流采样到多个帧率。
网络结构
1.双分支网络,一个帧率高一个帧率低,保留细粒度动作信息和空间外观信息。结构如下图所示。
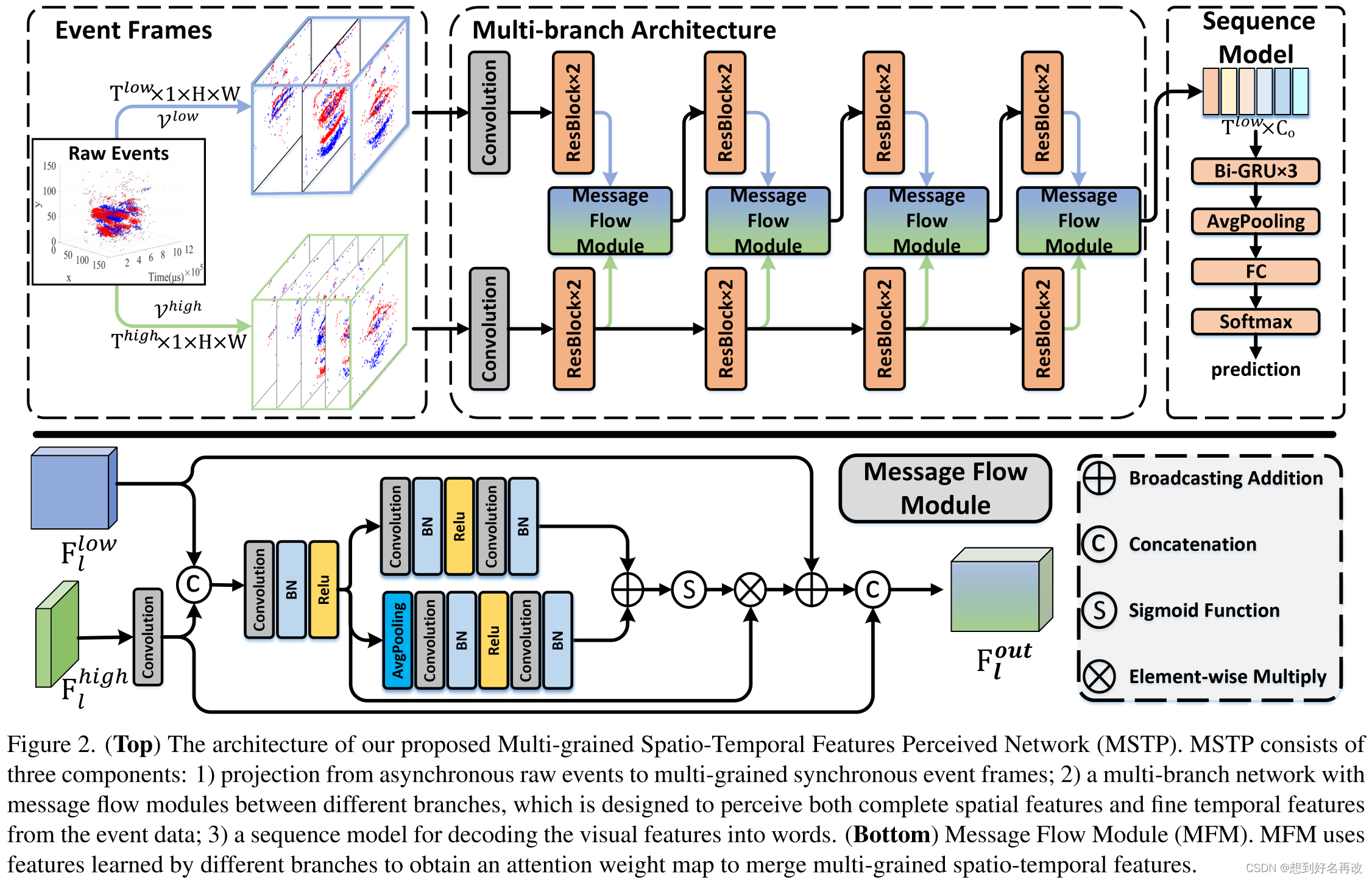
2.两个分支前端结构相似,使用3D + 2D ResNet18,提取特征过程中时间分辨率不变,高帧率分支通道数较小,为低帧率流的四分之一(更小的通道数可以提升时序建模能力,减弱空间建模能力)。
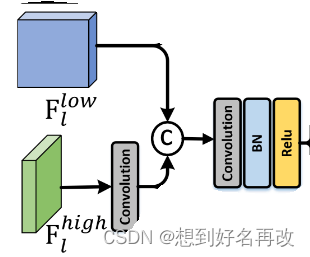
3.两个流中间层的输出格式为均为t×c×w×h,但t和c不同,高帧率流的t大c小。融合模块首先通过时间维度1d卷积将高帧率流的特征进行时间维度下采样,到帧率和低帧率流一样,并在特征维度拼接。该部分操作如下图,输出表示为
F
f
u
s
e
F^{fuse}
Ffuse,与低帧率流的输出格式相同,通道数变为2倍。
4.然后计算一个局部空间注意力,结构如下图。

卷积层通道数先减小为原来的1/4后恢复,输出格式与输入相同,为t×c×w×h。
5.再计算一个上下文注意力,结构如下图。
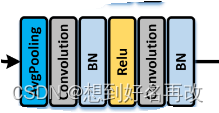
与局部空间注意力区别仅在于先进行GAP,使空间维度变成1,输出格式为t×c×1×1。
6.之后将两个注意力特征图相加,输入sigmoid,结构如下图。
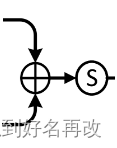
输出格式与局部注意力特征图相同。
7.然后用注意力权重和融合特征相乘并与低帧率特征相加,如下图。
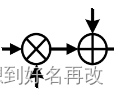
得到输出与输入格式相同,维度扩大2倍。
8.最后和下采样后的高帧率特征进行特征拼接,图下图所示。
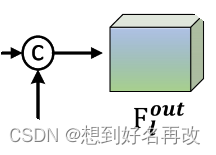
最终输出格式与低帧率相同,通道数为低帧率和高帧率相加。
序列模型
3层BiGRU
实验
数据收集
1.数据集由40个志愿者,每人读5个包含顺序不同的100个单词的序列,共产生20000个样本。使用Montreal forced aligner获取序列中每个单词的起止时间。将所有样本裁切刀128×128的大小。
2.去除问题样本,得到19871个样本,30个测试者的14896个样本训练,10个测试者的4975个样本测试。
实现细节
1.原尺寸128×128中心裁切到96×96,随机裁切到88×88,加上概率为0.5得水平翻转。视频数据如果每个单词多于30帧,则线性采样到30帧,若少于则zero padding到30。
2.pytorch实现,adam优化器,余弦学习率,3e-4到5e-6,80epoch,batchsize32.
实验结果
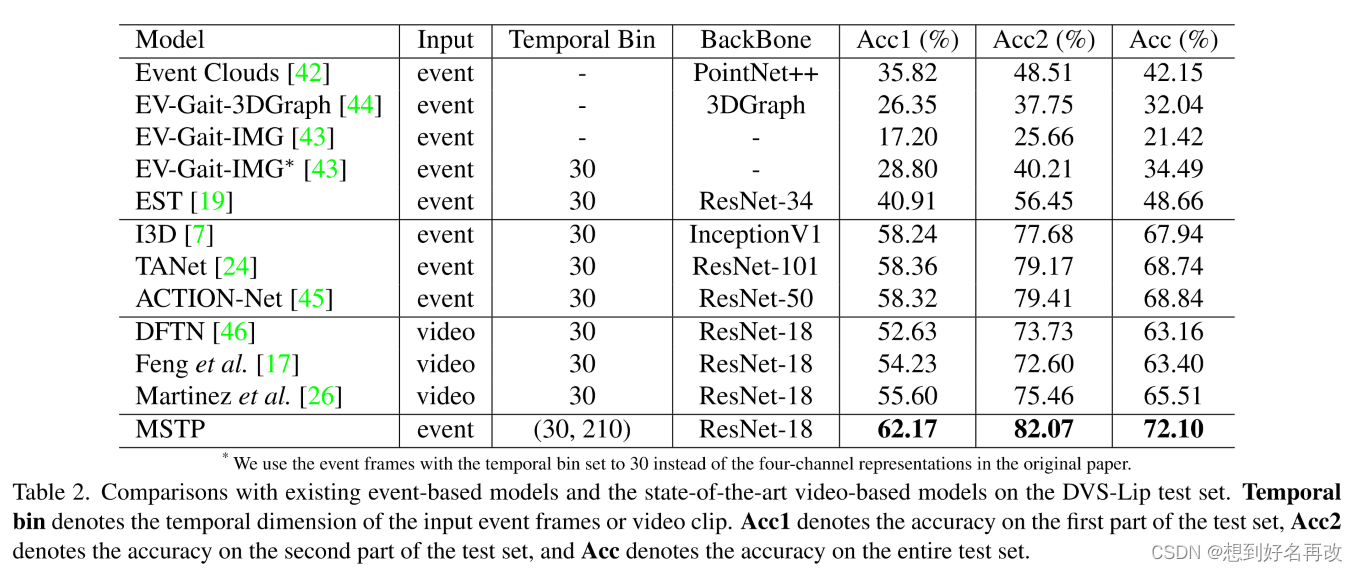
1.主要结果:MSTP取得最高精度。MSTP比事件动作识别模型的精度高。MSTP比传统模型在视频模态精度高
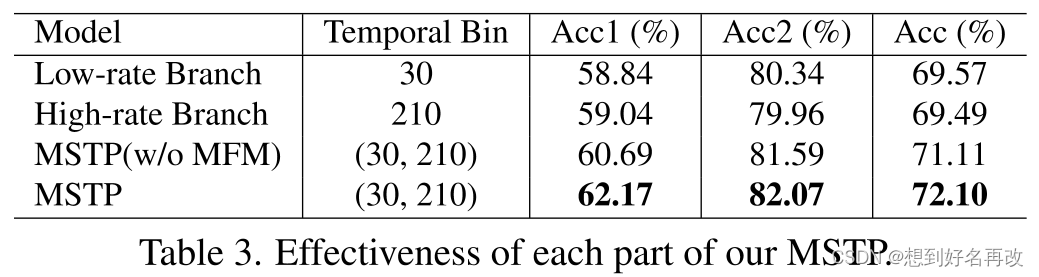
2.融合消融实验:单独的高低帧率流精度相近,直接横向融合得到较小提升,使用融合模块获得较大提升。
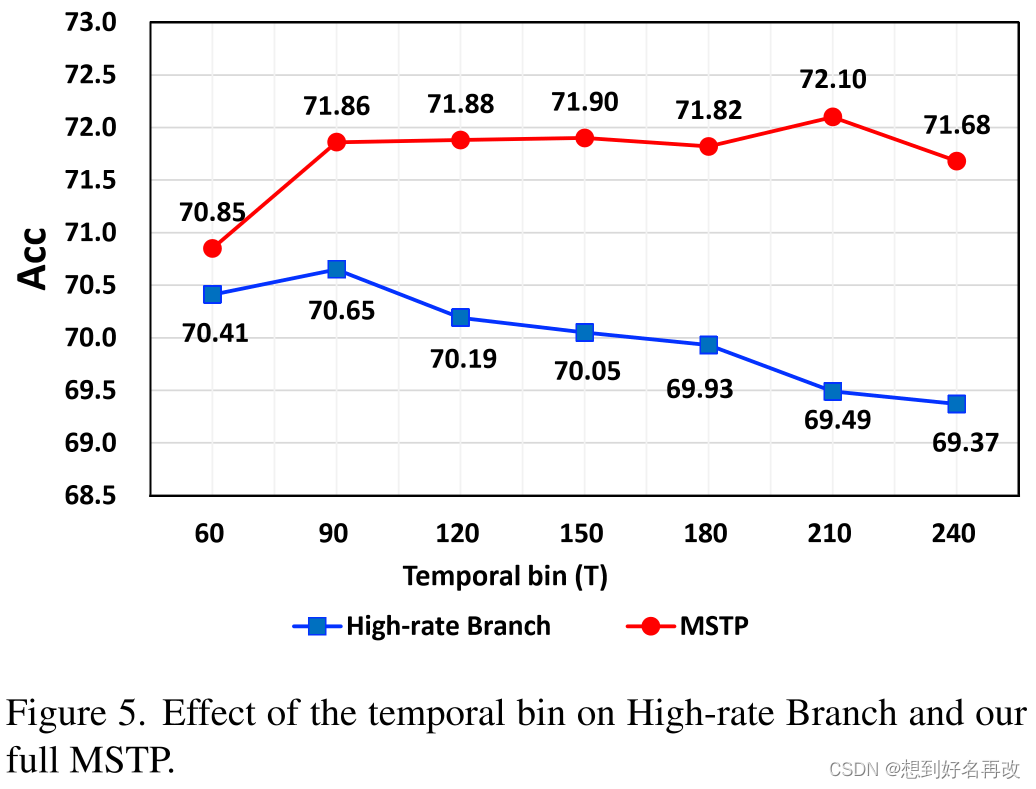
3.帧率消融实验:高帧率流不同帧率选择对精度的影响,当30和210组合时精度最高。
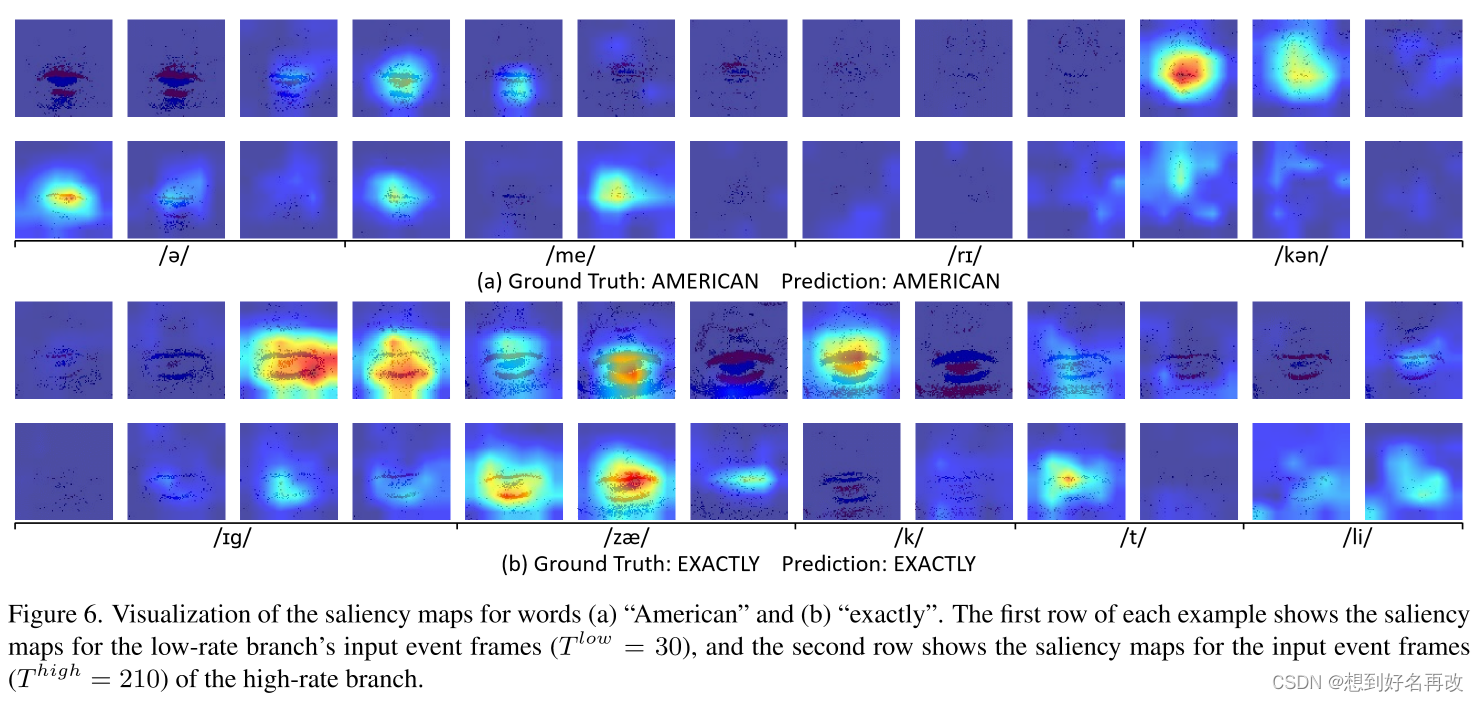
4.热力图可视化:奇数行为低帧率流,偶数行为高帧率流。两个流的注意区域不同,表示对时空信息不同的关注度,信息互补可以更好地提升识别精度。
补充材料
several
million
billion

tomorrow

happen

american

america



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









