







摘要
我们提出了一个代号为Inception的深度卷积神经网络架构,在ImageNet大型视觉识别挑战赛2014(ILSVRC14)中实现了分类和检测的新技术水平。该架构的主要标志是提高了网络内部计算资源的利用率。通过精心设计,我们增加了网络的深度和宽度,同时保持计算预算不变。为了优化质量,架构的决定是基于Hebbian原则和多尺度处理的直觉。我们为ILSVRC14提交的文件中使用的一个特殊化身被称为GoogLeNet,这是一个22层的深度网络,其质量是在分类和检测的背景下评估的。
一、介绍
在过去的三年里,由于深度学习和卷积网络的进步,我们的物体分类和检测能力得到了极大的提高[10]。
一个令人鼓舞的消息是,大部分的进步不仅仅是更强大的硬件、更大的数据集和更大的模型的结果,而主要是新想法、算法和改进的网络架构的结果。例如,在2014年ILSVRC比赛中,除了用于检测目的的同一比赛的分类数据集外,没有新的数据源被使用。我们提交给ILSVRC 2014的GoogLeNet实际上比两年前Krizhevsky等人[9]的获胜架构使用的参数少了12倍,而准确度却明显更高。在物体检测方面,最大的收获不是来自于天真的应用大基因和更大的深度网络,而是来自于深度架构和经典计算机视觉的协同作用,比如Girshick等人的R-CNN算法[6]。
另一个值得注意的因素是,随着移动和嵌入式计算的不断牵引,我们算法的效率–尤其是它们的功率和内存使用–获得了重要性。值得注意的是,导致本文提出的深度架构设计的考虑因素包括了这一因素,而不是单纯的固定在准确率数字上。在大多数实验中,模型被设计成在推理时保持15亿次的计算预算,这样它们就不会最终成为一个纯粹的学术好奇心,而是可以以合理的成本投入到现实世界中去,甚至在大型数据集上使用。
在本文中,我们将重点讨论一个用于计算机视觉的高效的深度神经网络架构,代号为Inception,其名称来源于Lin等人的Network in network论文[12]和著名的 "我们需要更深入 "的网络流行语[1]。在我们这里,"深入 "这个词有两种不同的含义:首先是指我们以 "Inception模块 "的形式引入了一个新的组织层次,同时也是指更直接的网络深度的增加。总的来说,我们可以把Inception模型看作是[12]的逻辑顶点,同时从Arora等人[2]的理论工作中获得灵感和指导。该架构的优势在ILSVRC 2014的分类和检测挑战中得到了实验验证,它明显优于目前的技术水平。
二、相关工作
从LeNet-5[10]开始,卷积神经网络(CNN)通常有一个标准的结构–堆叠的卷积层(可选择进行对比归一化和最大池化),然后是一个或多个全连接的层。这种基本的设计在图像分类文献中非常普遍,并且迄今为止在MNIST、CIFAR和最引人注目的ImageNet分类挑战中产生了最好的结果[9, 21]。
对于较大的数据集,如Imagenet,最近的趋势是增加层的数量[12]和层的大小[21,14],同时使用dropout[7]来解决过拟合的问题。
尽管人们担心最大集合层会导致准确空间信息的损失,但与[9]相同的卷积网络结构也被成功用于定位[9, 14]、物体检测[6, 14, 18, 5]和人体姿势估计[19]。
受灵长类动物视觉皮层的神经科学模型的启发,Serre等人[15]使用了一系列不同大小的固定Gabor滤波器来处理多个尺度。我们在这里使用了类似的策略。然而,与[15]的固定2层深度模型相反,Inception架构中的所有过滤器都是学习的。此外,Inception层被多次重复,在GoogLeNet模型的情况下,导致了22层的深度模型。
网中网是Lin等人[12]提出的一种方法,目的是为了提高神经网络的代表性。在他们的模型中,额外的1×1卷积层被添加到网络中,增加其深度。
我们在我们的架构中大量使用这种方法。然而,在我们的设置中,1×1卷积层有双重目的:最关键的是,它们主要被用作降维模块,以消除计算瓶颈,否则会限制我们网络的大小。这使得我们不仅可以增加网络的深度,还可以增加网络的宽度,而不会有明显的性能损失。
最后,目前最先进的物体检测方法是Girshick等人提出的卷积神经网络区域法(R-CNN)[6]。R-CNN将整个检测问题分解为两个子问题:利用颜色和纹理等低级线索,以便以类别无关的方式生成物体位置建议,并使用CNN分类器来识别这些位置的物体类别。这种两阶段的方法利用了低级线索的边界盒分割的准确性,以及最先进的CNN的高度强大的分类能力。我们在提交的检测报告中采用了类似的管道,但在这两个阶段都探索了改进措施,如多盒[5]预测以提高物体边界盒的召回率,以及集合方法以更好地对边界盒建议进行分类。
三、动机和高水平的考虑因素
提高深度神经网络性能的最直接的方法是增加其规模。
这包括增加深度–网的数量 图1:ILSVRC 2014年分类挑战的1000个类别中的两个不同类别。区分这些类别需要领域知识。
这包括增加深度–即每个级别的单位数量,以及宽度。这是一个简单而安全的训练更高质量模型的方法,特别是考虑到有大量的标记训练数据。然而,这种简单的解决方案有两个主要缺点。
更大的规模通常意味着更多的参数,这使得扩大后的网络更容易过拟合,特别是在训练集中的标记例子数量有限的情况下。这是一个主要的瓶颈,因为强标记的数据集是费力和昂贵的,往往需要人类专家评分员来区分各种细粒度的视觉类别,如ImageNet中的类别(即使在1000级的ILSVRC子集中),如图1所示。
统一增加网络规模的另一个缺点是对计算资源的使用急剧增加。例如,在一个深度视觉网络中,如果两个卷积层是连锁的,其过滤器数量的任何均匀增加都会导致计算量的二次增长。如果增加的容量被低效地使用(例如,如果大多数权重最终接近于零),那么大部分的计算就被浪费了。由于计算预算总是有限的,计算资源的有效分配比不分青红皂白地增加规模要好,即使主要目标是提高性能的质量。
解决这两个问题的一个基本方法是引入稀疏性,用稀疏层取代全连接层,甚至是在卷积层内。除了模仿生物系统外,由于Arora等人[2]的开创性工作,这也具有更坚实的理论基础的优势。他们的主要结果指出,如果数据集的概率分布可以由一个大型的、非常稀疏的深度神经网络来表示,那么最佳的网络拓扑结构可以通过分析前面几层激活的相关统计数据和对输出高度相关的神经元进行聚类来逐层构建。虽然严格的数学证明需要非常强大的条件,但这一声明与众所周知的Hebbian原则产生了共鸣–神经元一起开火,就会一起布线–这一事实表明,即使在不太严格的条件下,其基本思想也适用于实践中。
不幸的是,今天的计算基础设施在涉及到非均匀稀疏数据结构的数值计算时,效率非常低。即使算术运算的数量减少了100倍,查找和缓存缺失的开销也会占主导地位:改用稀疏矩阵可能不会得到回报。由于使用稳步改进和高度调整的数值库,可以利用底层CPU或GPU硬件的微小细节进行极快的密集矩阵乘法,差距进一步拉大[16, 9]。另外,非均匀稀疏模型需要更复杂的工程和计算基础设施。目前大多数面向视觉的机器学习系统仅仅通过采用卷积的方式在空间领域利用稀疏性。然而,卷积被实现为与前一层中的斑块的密集连接的集合。自[11]以来,ConvNets传统上在特征维度上使用随机和稀疏的连接表,以打破对称性并提高学习效果,然而,为了进一步优化并行计算,趋势从[9]开始变回了全连接。目前最先进的计算机视觉架构具有统一的结构。大量的过滤器和更大的批处理量使得密集计算得到了有效的利用。
这就提出了一个问题,即是否有希望实现下一个中间步骤:如理论所建议的那样,利用滤波器级的稀疏性,但通过利用密集矩阵的计算来利用我们目前的硬件。关于稀疏矩阵计算的大量文献(例如[3])表明,将稀疏矩阵聚类为相对密集的子矩阵,往往会使稀疏矩阵乘法的性能具有竞争力。在不久的将来,类似的方法将被用于非均匀深度学习架构的自动构建,这似乎并不牵强。
Inception架构一开始是一个案例研究,用于评估一个复杂的网络拓扑结构算法的假设输出,该算法试图近似于视觉网络的[2]所暗示的稀疏结构,并通过密集的、现成的组件覆盖假设的结果。
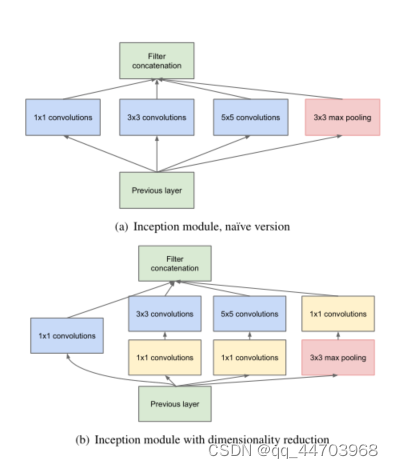
四、结构细节
总结
我们的结果产生了一个确凿的证据,即通过现成的密集构件来接近预期的最佳稀疏结构是一种改善计算机视觉神经网络的可行方法。这种方法的主要优点是,与较浅和较窄的结构相比,在计算要求略有增加的情况下,质量有了明显的提高。
对于分类和检测,预计类似深度和宽度的更昂贵的非Inception型网络也能达到类似的结果质量。尽管如此,我们的方法还是产生了确凿的证据,表明向更稀疏的结构发展是可行的,而且一般来说是有用的想法。这表明未来的工作是在的基础上以自动化的方式创建更稀疏和更精细的结构,以及将Inception架构的见解应用于其他领域。
















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









