







一、MVSNet一些操作
1、MVSNet 构建特征体
参考图像的一个pixel(记作x)(r image),在其拍摄方向给定的深度(d_i)对应着一个三维点(x_i)即世界坐标值,它投影到matching image会打在某个pixel(x_i)(相机坐标系–>归一化得到像素坐标)的位置。x与x_i的匹配代价或者说是相似程度,就是cost volume记录的内容。这个cost volume通过多个3D卷积得到一个初始的深度图。最后这个初始深度图(initial depth map)和reference image共同作用,去改善边界范围的准确率。
从参考视角到去找源视角的像素坐标对应点的计算过程,可以用单应性矩阵来描述。
连接变换后的特征Vi(d)和第i个视角图像特征Fi的是与参考相机视角下深度d相关的仿射变换。
这里得到的是N+1个特征体,特征体类似一摞书,长、宽、页数表示32通道,深度可以用第几本书表示。

2、构建代价体
将N+1个特征体聚合为一个统一的代价空间,将N+1摞书转换为一摞书
代价体的方差聚合可以融合多视角的信息,就是比较对应点的特征相似程度,相似度越高,说明这个平面对应的深度越接近真实深度。
特征体都是重叠放置在一起的,将每摞书第一页(有32个channel)左上角的点都取出来,然后计算方差,得到输出的那摞书的第一页左上角的点。对每个空间点都进行这样的计算,得到输出的一摞书,即最终的代价空间,每一本代表一个深度
3、构建概率体
一摞书变成一本书,三维卷积的最后将通道降为1,也就是把每本书都变成一页纸,一张纸代表一个深度,对于书页((W,H)平面)上的每一个点,若它在第三页的值最大,那么这个点的深度就为第三页的取值。使用一个3D U-Net结构来将代价 cost 转化为概率,即对于(W,H)平面上的每个点,沿D方向的概率合为1.,这便得到最终的概率空间P。视角图像中的每一个像素在参考相机坐标系下的深度的概率
生成的概率体既可以用于逐像素的深度估计,同时可用于测量估计的置信度
这里参考了一些文章
https://zhuanlan.zhihu.com/p/571631019
https://zhuanlan.zhihu.com/p/148569782
博客1
二、R-MVSNet
基本流程是和MVSNet基本类似,平面扫面转换视角构建代价体,正则化的时候使用循环神经网络RNN进行序列化处理,用2D的卷积加上GNU(门控循环单元)来处理每一张特征图。
1、循环神经网络
有些任务需要更好的处理序列信息,前面的输入和后面的输入有关系。每次会得到当前隐藏层的输出以及传递给下一节点的隐藏状态

这是一个简单的循环神经网络,隐藏层中的值S不仅取决于本次的输入X,还取决于上一次隐藏层的值S’,权重矩阵W就是隐藏层上一次的值作为这一次的输入所占的权重,W相当于是参数乘以S’输入S中。

GRU是RNN的一种,,可以解决RNN中不能长期记忆和反向传播中的梯度等问题。
这里学习了这篇博客

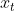 :表示当前时刻输入数据
:表示当前时刻输入数据
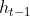 :表示上一时刻的隐藏状态,包含了前面的记忆。
:表示上一时刻的隐藏状态,包含了前面的记忆。
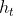 :传递到下一时刻的隐藏状态
:传递到下一时刻的隐藏状态
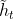 :候选隐藏状态
:候选隐藏状态
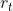 :重置门
:重置门
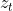 :更新门
:更新门
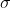 :sigmoid函数,将数据映射到[0,1]范围内。
:sigmoid函数,将数据映射到[0,1]范围内。
tanh : tanh函数,将数据映射到[-1,1]范围内。

公式推导可以参考链接的博客
候选隐藏信息是通过当前信息的输入以及重置门乘上一时刻的来的;最终的隐藏状态会因为更新门获得上一时刻的某些信息,并加入当前节点的候选隐藏状态的一些信息。

2、代价体正则化
沿着深度防线,顺序逐步处理代价体,在内存占用方面要优于使用3D CNN,提升了模型的精度和效率,使得高分辨率的深度图/立体重建成为可能。
GRU+Softmax
在文章中,R-MVSNet首先采用一个CNN将32通道的深度特征映射到16通道的深度特征,然后使用一个三层堆栈式GRU结构对代价图进行过滤(下图b)。深度优化。每一层GRU输出作为下一层的输入,输出channel数为16、4、1的损失图。

这里的输入是代价体,假设设置的深度是1—256,这里就是256个三维代价图,表示的是ref image的每一个像素点在不同深度下的代价。
GRU的每一个cmp(1)输入都是代价体中的每一个深度对应的长×宽×通道的三维代价图。这里每次计算都会根据上一状态的隐藏状态进行对本次输出的修改,所以下图(c)只需要当前状态的前状态就可以计算得到该像素在该深度的概率。最终输出的是一个三维的概率体,长×宽×深度(256)

下图是在网上找的一个更为专业的解释。

R-MVSNet利用堆栈卷积神经网络通过在深度方向抓取前后深度信息,然后每个代价图经过GRU的过滤,最后整合形成一个过滤后代价体Cr,再经过SoftMax处理生成表示深度置信概率的概率体P,与MVSNet类似,以深度期望值作为参考影像的深度图。














 4647
4647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









