







0 算法来源
GitHub - xy-guo/MVSNet_pytorch: PyTorch Implementation of MVSNet
小于8g的显存是跑不了的!!!连test都跑不了,过不了cost volume这一关。
1 算法理解
1.1 宏观把握
输入:一些已知相机内参、外参的图片(往往这时候已经用colmap等做过一遍sfm,从而获取到了相机的内参和外参)
过程:1)把图片重新分组,1 reference image + N source image ,source image是为了与测reference image的,最终输出的深度图对应reference image;2)将source homograph(变换)到reference上(在不同深度下),理论上,对于某一个像素来说,如果深度正确(其中一个深度),不同图像(不同特征体)上的像素值是相同的 3)相当于就能看到同一点在不同图像上的像素坐标对应关系,从而解算出每一点的深度
理论上,如果深度正确,这两张图片应该是完全相同的?
这句话正确吗???应该怎么理解homograph的目的。
输出:图片的深度图,在rgb之外,还加入了第四维的depth信息。
1.2 具体过程细节
1.2.1 从论文的角度来理解算法
 https://blog.csdn.net/qq_43027065/article/details/116641932
https://blog.csdn.net/qq_43027065/article/details/116641932 https://blog.csdn.net/weixin_43013761/article/details/102869562
https://blog.csdn.net/weixin_43013761/article/details/102869562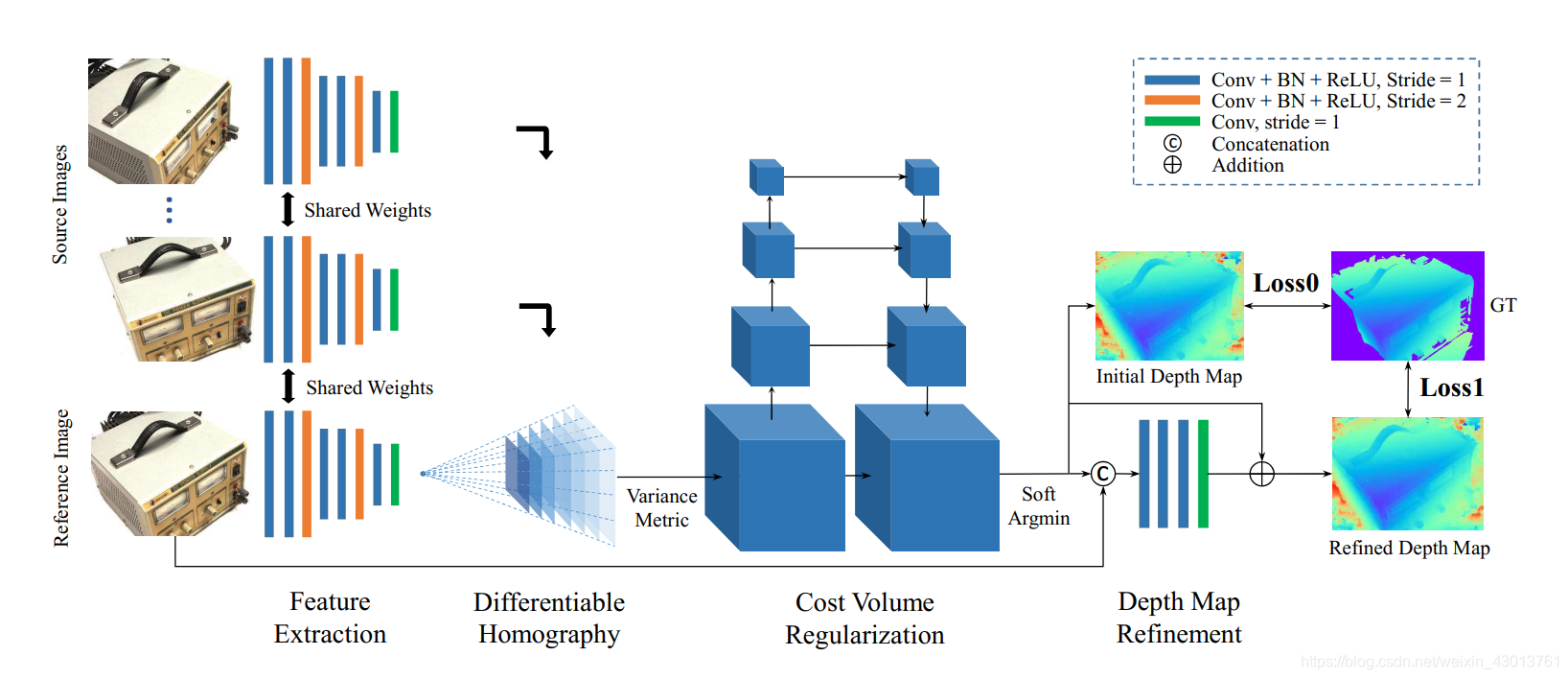
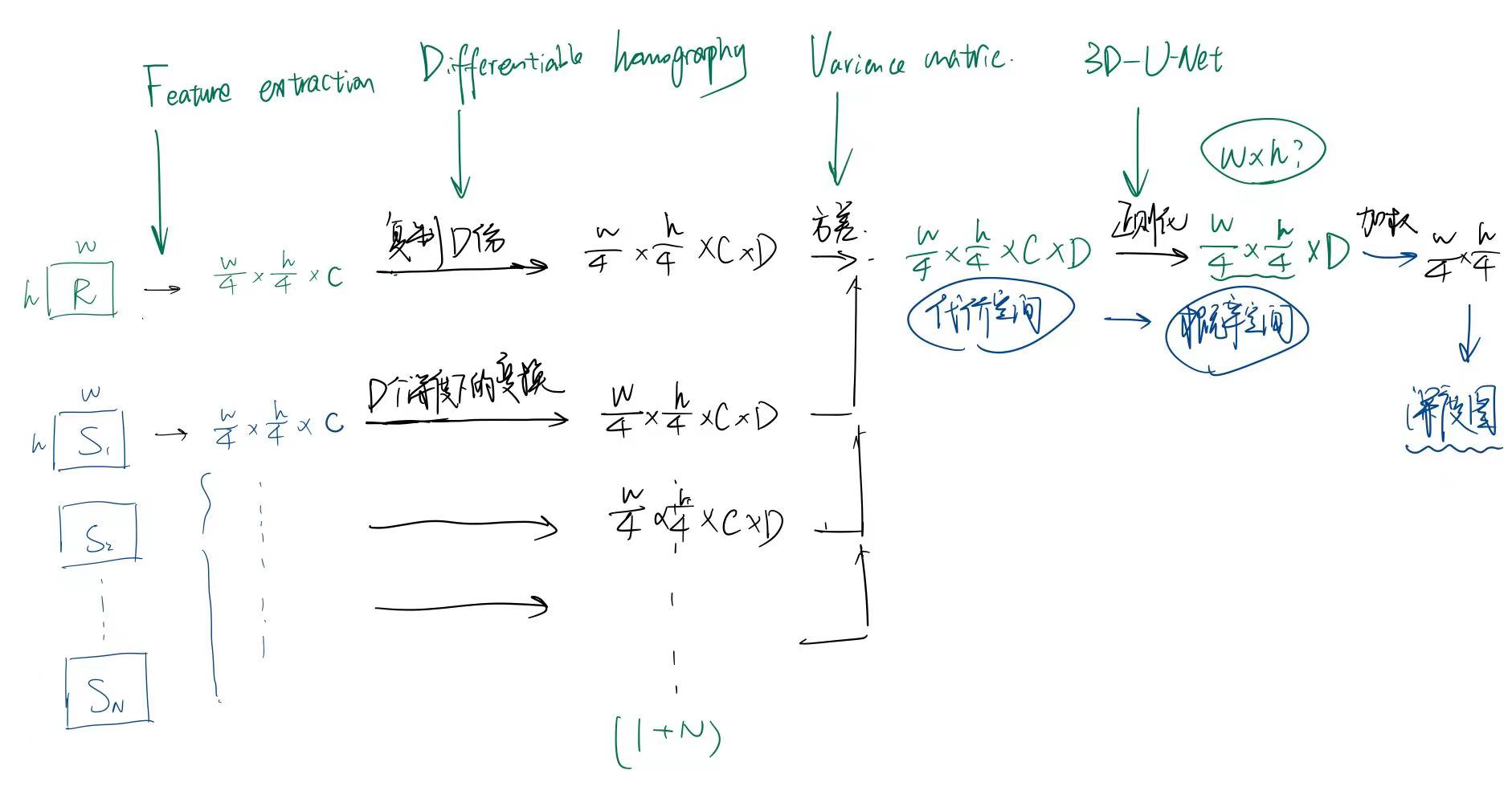
最开始先说明和depth相关的哪些内容,怎么给出D个深度下的变换,这D个深度怎么来。
D = [depth_min, depth_min + depth_interval, depth_min + 2 * depth_interval, ...],共有ndepths。
其中depth_interval还需要乘以interval_scale(意义是什么,似乎没啥意义)
(1)Feature extraction
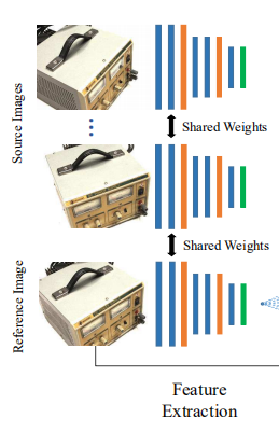
输入:1+N张图像(图像尺寸相同)假设为W*H
通过7层卷积,用stride=1保证粒度(提取不同级别的图片特征),用stride=2降低粒度,最终得到可以得到三个尺寸的特征图,原大小(3channel to 8 channel)、1/2原大小(8 channel to 16 channel),1/4原大小(16 channel to 32 channel)。在减小大小的同时扩大channel数。
由于在这里图片尺寸变为了原来的1/4。那么相应的相机内参 - 焦距和光心坐标也应该缩小为1/4,变成K/4。(图片等比例的改变大小,必须要同时调整内参(内参的前两列),这样才能够保证相对应关系。
为什么:1、图片小了,相当于图片离镜头近了 (从相似三角形的角度来看) 2、图片小了,光心坐标也应该调整
如果只裁剪图片下方局部,图片没有拉近,光心坐标没有变,内参不用改。(相对于左上角的坐标原点)
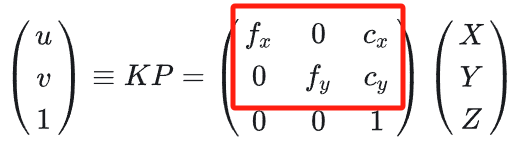
(2)Differentiable homography
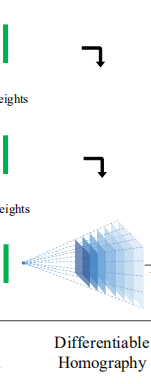
可微分的单应性变换(为什么要可微分,因为要做到端到端的深度学习训练)
目标:将所有的source image都换到reference image图像的视角下。从而可以让这些同一视角下的特征图来计算视差。
单应性矩阵描述了source image和 reference image对应点的像素变换关系。
输入:1+N个view下的1+N个特征图(W/4,H/4,C)(此时每张图片的视角是不同的)
输出:通过单应性变换,生成同一锥形立体空间下的1+N个特征体(W/4,H/4,C,D)
为什么还有个D,因为每个深度都会对应一个单应性矩阵。也就是假设图上的点可能在D个深度下,为什么D个深度就可以估计一个连续的空间呢,因为每个深度的概率是不一样的,所以加权之后就是一个连续的空间了。
这样一个特征图通过D个单应性变换,就会生成D个特征图,他们统一被称作一个特征体,
这样一个特征体在实际上是分布在一个视角下的锥形立体空间中的,但实际上每张图的像素尺寸都是一样的,所以从数据上看,是一个长方体。
********** 这一部分的内容没有特别融会贯通 *************
这里还用到了双线性插值,对于找不到的对应点(对应点超出了特征图宽高边界),用插值填充。为了尽量减少找不到对应点的情况,图像的重叠度应该比较高,所以不可以用太多的source image,太多了对应点就不好找了。
对于reference image feature,其实就是复制D份。为后续的代价度量做准备。
(3)Variance metric(方差计算)
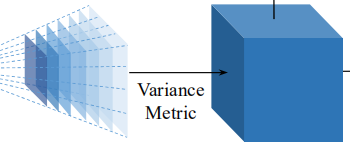
目标:将1+N个特征体合并为一个特征体,这个特征体能够度量1+N个特征体之间的差异。进一步来说,就是度量一个特征图的所有点在D个深度上的相似度。
想法缘起:
如果假设深度接近实际深度值,那么找到的对应点更准确,所有特征图在同一位置的特征相似性高,反之相似性低。即特征的相似性度量可以判断深度假设接近实际深度值的程度。
那么怎么衡量相似度呢?可以用方差。方差反映了一组数据的波动情况,即数据越相似,方差越小。

(4)cost volume regularization 代价空间正则化
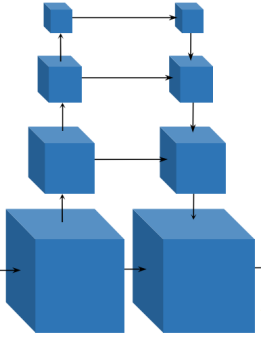
目标:从代价空间C得到概率空间P,也就是把channel这个维度压缩掉。变成(W/4,H/4,D)
为什么要用这么一个U-NET一样的架构呢,因为他其实只是个最简单的编解码器,编解码能够实现什么效果?就是让信息从一种状态变成另一种状态。如果我们希望让数据换一种分布,或者产生出一种新信息(比如说逐点像素的类别概率——这就是最经典的unet分割算法)。通过skip connection(直接加起来)能够跨层传递信息,让解码的时候能够获得一些之前的信息,否则从小到大会有很多空白信息要预测,就很不准。还能够从一个大的感受野聚集相邻的信息。
总共做了三步:
1)通过三维卷积对代价空间正则化,让深度的取值集中起来,变成单峰分布。
2)在三维卷积的最后一步是把channel=1(原来的channel是32),这个时候,在哪个D上的值最小(方差最小,就认为他是最可能属于这个深度)
3)沿D方向做一个概率归一化(类似softmax),这样就得到了最终的概率空间P
(5)深度图初始估计
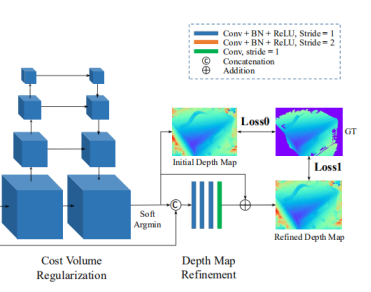
目标:从概率空间P中获取深度图(变成W,H,1)
也就是沿D方向计算期望,就是D*概率,做一个加权。期望值就是该点的深度估计。

(6)获取概率图(对深度图进行过滤,滤去那些估计不准的点)
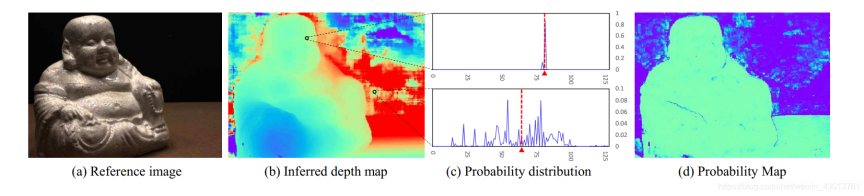
计算方式:对概率空间,沿深度维度计算每四个邻域的概率和,再沿深度维度取最大的概率和。(可能就是准则?)
概率图上的点概率越高,越表示更单峰一些,那么就说明这个位置深度估计的有效性越高。
(7)深度图优化(主要是对边界处的深度预测更准一些)
因为取了期望,所以边缘会比较平滑。
所以把参考图像拿过来,加一些初始的残差进去,可能会克服边缘的过于平滑的问题,但似乎最终在其他实验上被证明是意义不大的。
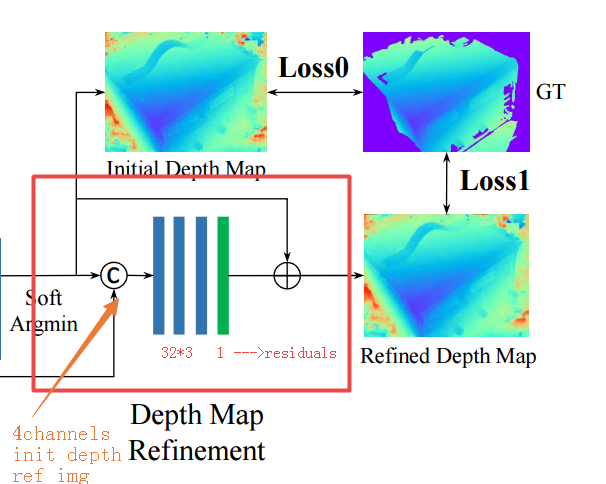
原始图像和原始深度叠加在一起,然后过卷积层,转换一下特征空间,形成深度图的残差。
这时候再和初始深度图加一起,形成了最终的优化后深度图。
此外,为了保证特定的深度尺度,初始深度的幅度被归一化到0-1,而在refine后被重新变换回来。
深度尺度的问题?????????
1.2.2 从代码的角度来理解算法
【代码精读】开山之作MVSNet PyTorch版本超详细分析【三维深度学习】多视角立体视觉 MVSNet代码解读_hitrjj的博客-CSDN博客_mvsnet
(1)总的理解:数据输入与处理
对于DTU数据集,输入图像会被减小32倍,包括了初始的下采样和构建特征图的下采样。
首先将图像从1600x1200变为800x600,而后裁剪成640x512。(所以这时候才需要内参变成1/4)。 ---- 这一部分可能是DTU的问题(因为内存占用的太高),因为R-MVSNet是high resolution的
参考视角上生成了256个深度[425mm:2mm:935mm].
(2)/datasets/dataset(train).py 用于读取训练的数据集
注意和测试数据集的不同:
这里assert的model可以是train、val、test等。
- 有不同的光照,DTU数据集中有7种,因此,meta变成scan,light_idx, ref_views, src_views。多了light的分类。
- intrinsics不用除以4.
- 这里还有mask_file(仅仅用于ref_img深度预测的图片,mask以外的可能就不需要预测了?大概这个意思吧,不需要进行训练(可能误差太大?)。
(3)/datasets/dataset_eval.py 用于读取测试的数据集
大标题是MVSDataset(Dataset) 就是用这样的方式来加载mvsnet数据集,并做成一个类。
- build_list(),读取pair.txt,生成ref和src的对应关系列表(做成一个metas?)
- read_cam_file(),读取相机文件的外参与内参文件,并且得到depth相关的信息,最小值和interval,似乎最小值和interval是一样的。内参会除以4(因为图像大小改变)
- read_img() ,读取img,先把rgb从255到1,必须要求大小是1200*1600,然后会crop到1184,1600(应该是可以被32整除)
- read_depth(),读取深度图
- __len__(),让外部能够直接用len()来访问这个数据集,总共有多少个meta,需要对几张图片预测深度?
- __getitem__(),可以像列表一样按序号访问数据集。然后根据id取访问image,访问相机内参外参等。 外参直接组成P;对于ref view,生成深度信息范围。(其实就是平均的从depth_min开始有ndepth个深度。
depth_values = np.arange(depth_min, depth_interval * (self.ndepths - 0.5) + depth_min, depth_interval,dtype=np.float32)(4)/datasets/data_io.py 深度图的保存与读取
深度图的scale表达了什么?
scale 参数代表缩放深度值的比例因子。因为深度值的范围可能很大,所以需要缩放让深度值落在合理的区间内 / 便于PFM文件存储。
endian表示字节顺序?反正不是很重要
(5)/datasets/__init__.py
提供了查询dataset 属性的接口 (一个defination函数)
(6) lists/
输入不同的list,用于输入不同的scan,来区分训练集、验证集和测试集。
(7)models/__init__.py
会提供外部访问内部子函数的接口,比如说MVSNet, mvsnet_loss这两个函数(或者类)
(8) models/ module.py
提供了基本的一些模块
- ConvBnReLU ConvBn ConvBnReLU3D ConvBn3D(3D用于处理3D体,因为此时会有视差或者多张图叠在一起)
- BasicBlock,是resnet的基本模块,特征直接往下传。里面的downsample是让跳接往下传的x能够适应特征图分辨率,因为resnet自己会有stride=2的情况(相当于分辨率降了),所以要适应这种情况,判断往下传的x是否需要下采样降分辨率。
参考:ResNet的小感想(二)· downsample详解 - 知乎 (zhihu.com)
- Hourglass3d 类似一个沙漏的模块(有点像unet)
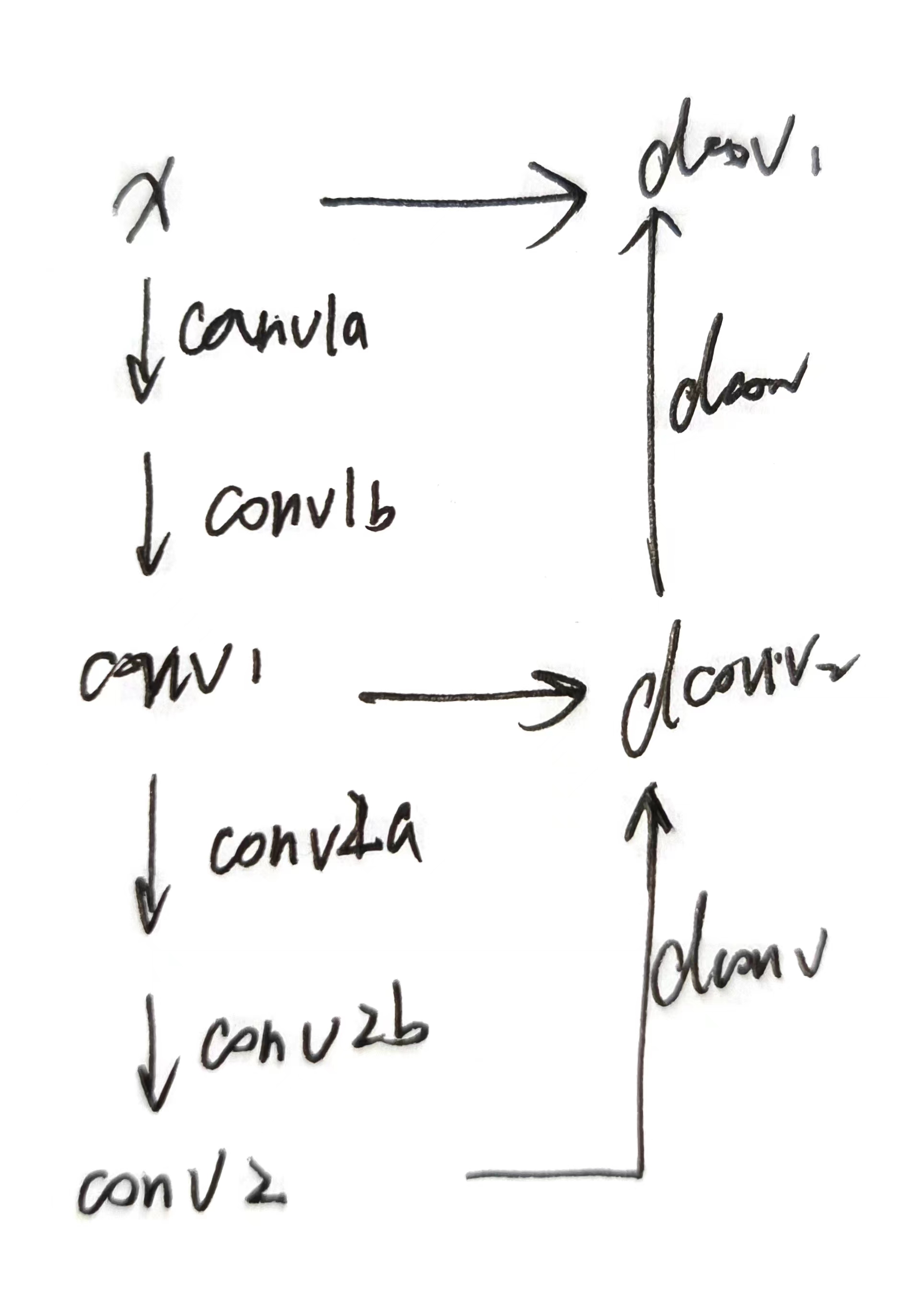
- homowarping
其实就是把src的图像特征向ref来wrap,在每个channel,每个深度层,每个像素位置,都有插值得到的特征值。
在不同深度下,投影矩阵是不一样的,所以像素位置是不一样的,所以将src特征放到ref图像上(不同深度下的矩阵),插值得到的特征是不一样的。其实每个点会对应一个固定的wrap(固定的深度)。但现在我们可以做N次,这样就相当于所有情况都考虑了。
- depth_regression
通过每个深度层上的概率对深度层加权,得到明确的每个BATCH下,每个像素(共H*W个)上的深度值。
(9)models/mvsnet.py
- FeatureNet, 就是通过卷积等操作加深channel, 图像分辨率缩小4倍
- costregnet 用3D-UNet来做归一化等操作,让不同的图像特征能够最终搞出来一个概率体。
(10)models/mvsnet.py中整体过程 MVSNet
- 特征提取,用feature net,所有图都是用这个
- 构建代价体,原始ref自己复制构建特征体,然后别的src直接wrap过来相加,最终形成整个特征体,然后计算方差,作为代价体。
- 代价体归一化,输出回归的深度值和光学概率。其中的深度值就是概率体*深度序列。光学概率是将概率体平滑之后(avg_pool3d),然后用对应的那个深度值的index(比如10.2),直接输出对应的概率体的概率,作为光学概率。
- refine,深度图要refine,但后来似乎证明用处不大?光学一致性概率不变。
(11)train.py
- 提供了resume训练
- 提供了较好的学习率调度策略:
MultiStepLR是PyTorch中一种常用的学习率调度器,它会在指定的milestone epoch时,将当前学习率乘以gamma。例如,如果初始学习率为0.1,在第10和20个epoch时,学习率会分别变为0.01和0.001。这种策略可以帮助模型逐步减小学习率,防止在后期过度振荡,从而提高收敛性和性能。 - abs_depth_error 直接将预测的深度图和gt深度图做abs减法,
(12) eval.py
预测完深度图之后,要通过如下步骤:
局外点滤波和深度图融合得到最终的结果。
利用了光度和几何的连续性来对局外点进行剔除。
光度连续性:在模型中概率小于0.8的点被视为局外点。(wrap到一起的点一不一样)
几何连续性:通过重投影误差的计算,只有满足![]() 才能满足连续性的要求,将大多数局外点剔除在最终的结果外,保证结果精度。 先把ref通过深度形成三维点A放到src下,再根据src的深度形成三维点B放到ref下,图像和三维点均求差。
才能满足连续性的要求,将大多数局外点剔除在最终的结果外,保证结果精度。 先把ref通过深度形成三维点A放到src下,再根据src的深度形成三维点B放到ref下,图像和三维点均求差。
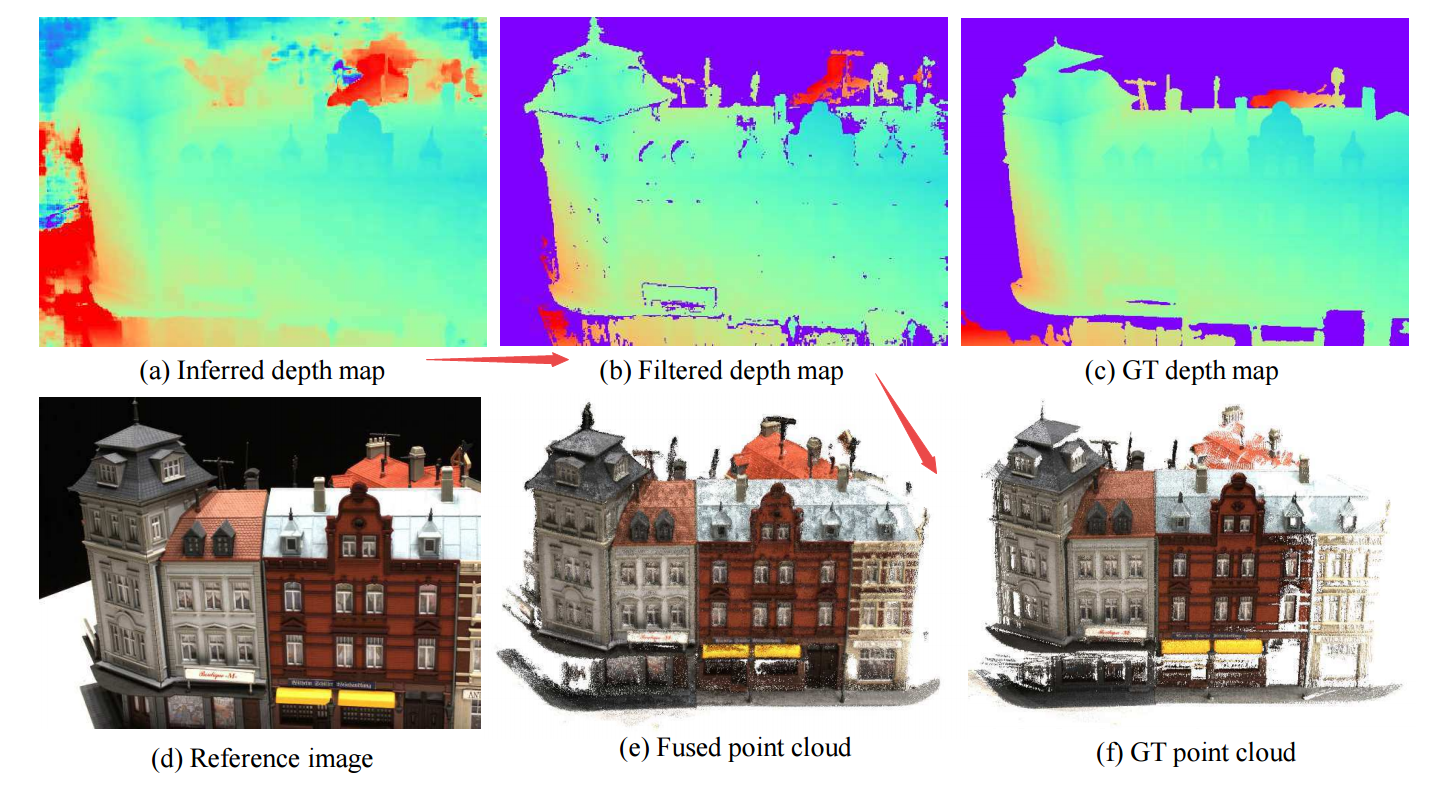
用photomask和geomask来两次过滤。
为什么要sample?
eval的时候到底有没有减小图片尺寸?到底为什么eval的intri要变成1/4?
(n-2) 能否保证 / 如何保证深度图的尺度的问题
原有从colmap pipeline来的经验:sfm尺度正确,深度图尺度即正确。
实际MVSNet中,在深度图的后处理阶段的结果。
(n-1) evaluations/dtu
DTU自己给了比较完整的用matlab写的一系列验证的代码。
(n)深度图的后处理阶段
2 算法实操
2.1 环境配置
(pytorch版本高了会有warning,问题不大)
python3.6+pytorch1.10(cu113)+torchvision0.11.1(cu113)
tensorboard + tensorboardX,直接pip install就好了,主要是为了可视化查看训练过程的。
cv2(opencv-python)
2.2 demo过程
2.2.1 demo eval使用
1)定位到dtu的测试集路径
- DTU_TEST
- SCAN1 # 某个对象的倾斜摄影图像集
- IMAGES # 存放n个view(49个)
- CAM # 存放每个view的相机信息
- pair # 存放source image和reference image的对应情况
- SCAN2 # 第二个对象2)具体代码(可写成eval.sh,从而直接用bash运行)
DATASET_ROOT="/D/data/zt/3d/DTU_TESTING" # dtu测试集的位置
CUDA_VISIBLE_DEVICES=0 python eval.py \
--dataset=dtu_yao_eval \ # 定义加载数据的方法(比如说一张source对应几张reference)
--batch_size=1 \
--testpath=$DATASET_ROOT \
--testlist="lists/dtu/test.txt" \ # 需要被测试的scan的名称
--outdir="./outputs/baseline_0/" \ # 存放着重建得到的结果
--loadckpt="./checkpoints/baseline/model_000000.ckpt" $@
3)过程问题与解决:
3.1)运行显示找不到深度图什么的。因为eval.py的逻辑就是,先把每个view的深度图都通过MVSNet生成完,然后再根据需求去融合深度图生成ply点云。
所以需要先运行save_depth()这一步(想生成scan1的ply就得先把scan1每张图的深度图生成完毕)
3.2) DataLoader worker (pid(s) 20472) exited unexpectedly
主要是num_worker太大了,对于windows电脑而言,不能执行多线程,所以设置num_worker=0就可以了。但是对于ubuntu系统,可以设置num_worker=4。
3.3)cuda out of memory
在构建损失体cost volume的时候显存不够,这也是常有提到的问题(算法本身的弊端)。
MVSNet本身对显存的占用太大了。
尝试一下rtx3090的显卡,可以了。
可以生成ply格式的点云模型了。
4)结果
scan009,scan015,scan023,scan024,scan029都是跟建筑相关的小场景。
可以拿过来先跟colmap做个简单的对比。
2.2.2 demo train使用
可以跑的,只不过非常占显存。把batch_size调小一点就能跑了,
也是直接运行train.sh。
2.3 自己的数据
1)关键问题
如何提供mvsnet所需格式的输入,可以用colmap来做
【colmap】稀疏重建转为MVSNet格式输入 - 达可奈特_Darknet - 博客园 (cnblogs.com)
2)


















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









