




P2P信贷平台业务数据分析 @lbhfox
数据集地址:https://pan.baidu.com/s/1OfENKFNvWu7TCtQLHc_VXQ
提取码:zpsi
1.LC数据集初步分析
首先我们来分析一下LC.csv数据集,LC (Loan Characteristics) 表为标的特征表,每支标一条记录。共有21个字段,包括一个主键(listingid)、7个标的特征和13个成交当时的借款人信息,全部为成交当时可以获得的信息。信息的维度比较广,大致可以分为基本信息,认证信息,信用信息,借款信息。
基本信息:年龄、性别;
认证信息:手机认证、户口认证、视频认证、征信认证、淘宝认证;
信用信息:初始评级、历史正常还款期数、历史逾期还款期数;
借款信息:历史成功借款金额、历史成功借款次数、借款金额、借款期限、借款成功日期
对于LC数据集我们提出以下四个问题:
1.用户画像,包含使用平台贷款业务的用户的性别比例,学历水平,是否为旧有用户,年龄分布等信息。
2.资金储备,每日借款金额大概多少?波动有多大?从而公司每日需准备多少资金可以保证不会出现资金短缺?
3.用户逾期率,借款人的初始评级、借款类型、性别、年龄等特征对于逾期还款的概率有无显著影响?哪些群体逾期还款率明显较高?
4.借款利率,哪些群体更愿意接受较高的借款利率?
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
LC = pd.read_csv(’/home/kesci/input/ppdai2017/LC.csv’)
LP = pd.read_csv(’/home/kesci/input/ppdai2017/LP.csv’)
对数据进行清洗
依次检查重复值、缺失值的处理,一致化以及异常值,数据集很干净。
#LC.info()
#LC.describe()
#观察一下年龄分布,最小17岁,最大56岁,平均年龄29岁,33岁以下的占比超过了75%。说明用户整体还是中青年。
#将年龄分为’15-20’, ‘20-25’, ‘25-30’, ‘30-35’, ‘35-40’, '40+'比较合理
#观察一下借款金额分布,最小借款金额为100元,最大为50万元,平均值为4424元,低于5230的借款金额占到了75%。
#说明应该是小额借款比较多。将借款金额分为0-2000,2000-3000,3000-4000,4000-5000,5000-6000,6000以上比较合理
#LC[‘ListingId’].value_counts()
LP.info()
LP.describe()
LP = LP.dropna(how=‘any’)
LP.info()
LC = LC.dropna(how=‘any’)
数据很干净
1.分析用户画像(性别、学历、年龄、是否首标)
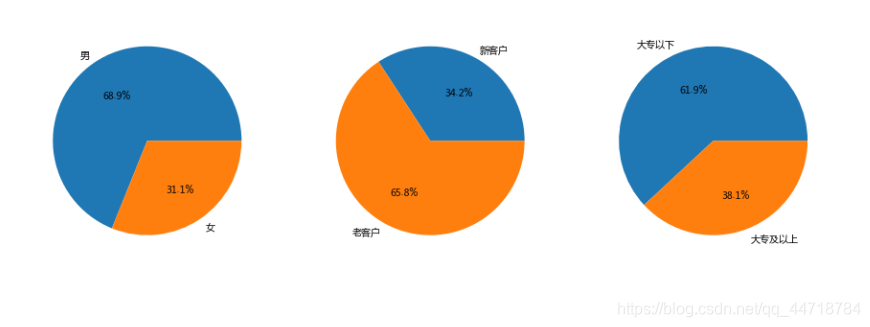
按‘性别’、‘年龄’、‘是否首标’、‘学历认证’字段对‘借款金额’进行加总,用饼图或柱状图将结果可视化
#性别分析
male = LC[LC[‘性别’] == ‘男’]
female = LC[LC[‘性别’] == ‘女’]
sex = (male,female)
sex_data = (male[‘借款金额’].sum(), female[‘借款金额’].sum())
sex_idx = (‘男’, ‘女’)
plt.figure(figsize=(15, 6))
plt.subplot(1,3,1)
plt.pie(sex_data, labels=sex_idx, autopct=’%.1f%%’)
#新老客户分析
new = LC[LC[‘是否首标’] == ‘是’]
old = LC[LC[‘是否首标’] == ‘否’]
newold_data = (new[‘借款金额’].sum(), old[‘借款金额’].sum())
newold_idx = (‘新客户’, ‘老客户’)
plt.subplot(1,3,2)
plt.pie(newold_data, labels=newold_idx, autopct=’%.1f%%’)
#学历分析
ungraduate = LC[LC[‘学历认证’] == ‘未成功认证’]
graduate = LC[LC[‘学历认证’] == ‘成功认证’]
education_data = (ungraduate[‘借款金额’].sum(), graduate[‘借款金额’].sum())
education_idx = (‘大专以下’, ‘大专及以上’)
plt.subplot(1,3,3)
plt.pie(education_data, labels=education_idx, autopct=’%.1f%%’)
plt.show()
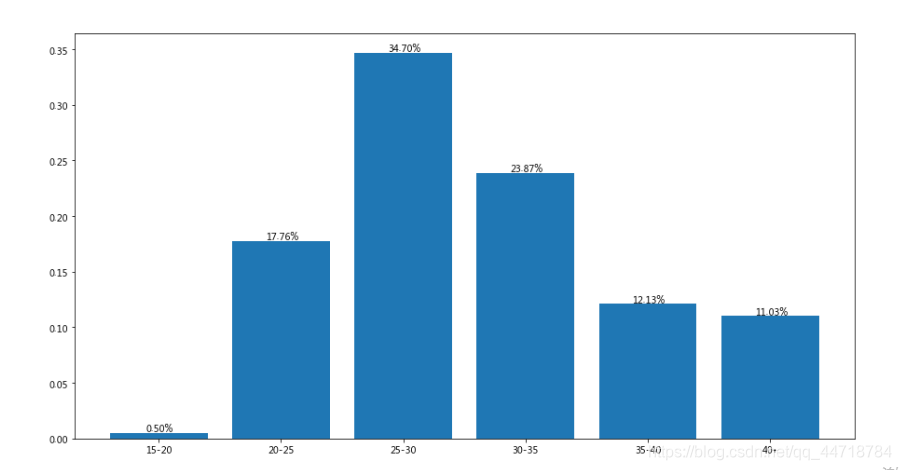
#年龄分析
ageA = LC.loc[(LC[‘年龄’] >= 15) & (LC[‘年龄’] < 20)]
ageB = LC.loc[(LC[‘年龄’] >= 20) & (LC[‘年龄’] < 25)]
ageC = LC.loc[(LC[‘年龄’] >= 25) & (LC[‘年龄’] < 30)]
ageD = LC.loc[(LC[‘年龄’] >= 30) & (LC[‘年龄’] < 35)]
ageE = LC.loc[(LC[‘年龄’] >= 35) & (LC[‘年龄’] < 40)]
ageF = LC.loc[LC[‘年龄’] >= 40]
age = (ageA, ageB, ageC, ageD, ageE, ageF)
age_total = 0
age_percent =[]
for i in age:
tmp = i[‘借款金额’].sum()
age_percent.append(tmp)
age_total += tmp
age_percent /= age_total
age_idx = [‘15-20’, ‘20-25’, ‘25-30’, ‘30-35’, ‘35-40’, ‘40+’]
plt.figure(figsize=(15, 8))
plt.bar(age_idx, age_percent)
for (a, b) in zip(age_idx, age_percent):
plt.text(a, b+0.001, ‘%.2f%%’ % (b * 100), ha=‘center’, va=‘bottom’, fontsize=10)
plt.show()
结论:
1.男性客户的贡献的贷款金额占到了69%,可能的原因是男性更倾向于提前消费且贷款金额较大。
2.非首标的金额占比达到66%,说明用户倾向于多次使用,产品粘性较高。
3.大专以下学历的贷款金额更多,但是由于可能有很多用户并未认证学历,所以数据存在出入。
4.年龄段在25-30岁之间的借款金额最多,而20-35岁的人群占比超过75%,是该产品的主力消费人群。
2.分析资金储备
每日的借款金额大概多少?波动有多大?公司每日需要准备多少资金可以保证不会出现资金短缺?
from datetime import datetime
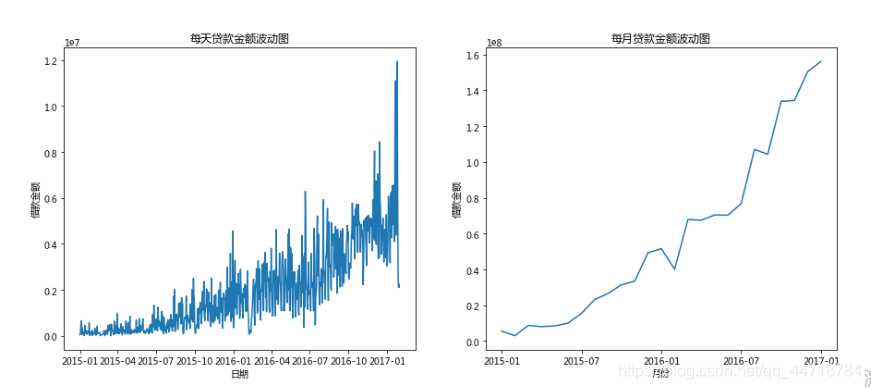
#分析每日贷款金额的走势
loan = LC[[‘借款成功日期’, ‘借款金额’]].copy()
loan[‘借款日期’] = pd.to_datetime(loan[‘借款成功日期’])
loan1 = loan.pivot_table(index=‘借款日期’, aggfunc=‘sum’).copy()
plt.figure(figsize=(15, 6))
plt.subplot(1,2,1)
plt.plot(loan1)
plt.xlabel(‘日期’)
plt.ylabel(‘借款金额’)
plt.title(‘每天贷款金额波动图’)
#分析每月贷款金额的走势
loan[‘借款成功月份’] = [datetime.strftime(x, ‘%Y-%m’) for x in loan[‘借款日期’]]
loan2 = loan.pivot_table(index=‘借款成功月份’, aggfunc=‘sum’).copy()
plt.subplot(1,2,2)
plt.plot(loan2)
plt.xlabel(‘月份’)
plt.xticks([‘2015-01’,‘2015-07’,‘2016-01’,‘2016-07’,‘2017-01’])
plt.ylabel(‘借款金额’)
plt.title(‘每月贷款金额波动图’)
plt.show()
对2017年1月的数据继续进行分析,并求出平均值和标准差
loan3 = loan1.loc[‘2017-01’]
avg = loan3[‘借款金额’].mean()
std = loan3[‘借款金额’].std()
print(avg, std)
5204663.8 2203394.1435809094
结论:
1.每日贷款金额呈现的是一个往上的趋势,但是每天的波动较大。
2.每月贷款分析结论:从2015年1月到2017年1月,月度贷款金额呈现上升趋势,上升速度随着时间增快。
3.2017年1月每日的借款金额达到5204664元,标准差为2203394,根据3σ原则,想使每日借款金额充足的概率达到99.9%,则每日公式账上需准备5204664+2203394×3=11814846元。
3.分析逾期还款率(借款人的初始评级、借款类型、性别、年龄、借款金额等特征)
逾期还款率 = 历史逾期还款期数/(历史逾期还款期数+历史正常还款期数)
#初始评级的数据划分
level_idx = (‘A’,‘B’,‘C’,‘D’,‘E’,‘F’)
lev = []
for i in level_idx:
temp = LC[LC[‘初始评级’] == i]
lev.append(temp)
#借款类型的数据划分
kind_idx = (‘电商’, ‘APP闪电’,‘普通’, ‘其他’)
kind = []
for i in kind_idx:
temp = LC[LC[‘借款类型’] == i]
kind.append(temp)
#不同借款金额的数据划分
amount_idx = (‘0-2000’, ‘2000-3000’, ‘3000-4000’, ‘4000-5000’, ‘5000-6000’, ‘6000+’)
amountA = LC.loc[(LC[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









