






python之鸢尾花–KNN
方案一:引用sklearn.neighbors import KNeighborsClassifier库
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 分出训练数据和测试数据
def train_test_split(X, y, test_radio, seed=None):
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_radio <= 1.0, \
"test_radio must between 0.0 and 1"
if seed is not None:
np.random.seed(seed)
test_size = int(len(X) * test_radio)
shuffle_index = np.random.permutation(len(X))
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_test = X[test_index]
y_test = y[test_index]
X_train = X[train_index]
y_train = y[train_index]
return X_test, X_train, y_test, y_train
X_test, X_train, y_test, y_train = train_test_split(X, y, test_radio=0.2, seed=656)
# knn算法
skl_knn = KNeighborsClassifier(n_neighbors=7)
skl_knn.fit(X_train, y_train)
skl_predict = skl_knn.predict(X_test)
precision = np.sum(skl_predict == y_test)/len(y_test)
# dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
print(iris.feature_names)
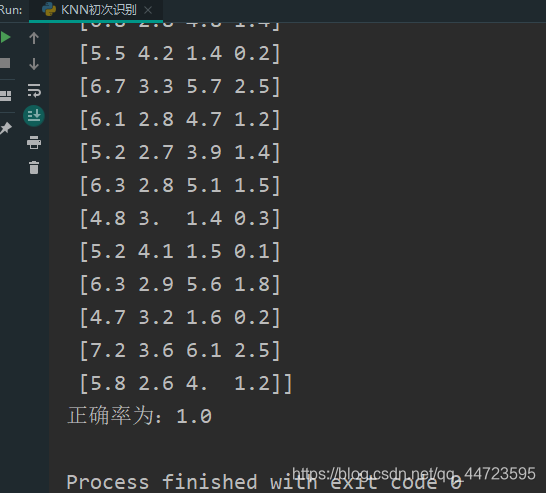
print(X_test)
print(f'正确率为:{precision}')
方案二:自定义knn
from collections import Counter
from math import sqrt
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
class My_KNN_classifier:
def __init__(self, k):
assert k >= 1 and k % 2 != 0, \
"k必须是一个大于1,并且不为偶数的数"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X, y):
assert self.k <= X_train.shape[0], \
'k必须小于X_train.shape[0]'
self._X_train = X
self._y_train = y
return self
def predict(self, X_predict):
assert self._X_train.shape[0] == self._y_train.shape[0], \
"特征与所属类别的数据大小必须一一对应"
assert X_predict.ndim == 2, \
'X_predict.ndim == 2'
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
distance = [sqrt(np.sum((x_i - x) ** 2)) for x_i in self._X_train]
nearest = np.argsort(distance)[:self.k]
topK_y = self._y_train[nearest]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
# 分出训练数据和测试数据
def train_test_split(X, y, test_radio, seed=None):
assert X.shape[0] == y.shape[0], \
"the size of X must be equal to the size of y"
assert 0.0 <= test_radio <= 1.0, \
"test_radio must between 0.0 and 1"
if seed is not None:
np.random.seed(seed)
test_size = int(len(X) * test_radio)
shuffle_index = np.random.permutation(len(X))
test_index = shuffle_index[:test_size]
train_index = shuffle_index[test_size:]
X_test = X[test_index]
y_test = y[test_index]
X_train = X[train_index]
y_train = y[train_index]
return X_test, X_train, y_test, y_train
X_test, X_train, y_test, y_train = train_test_split(X, y, test_radio=0.2, seed=656)
# knn算法
my_knn = My_KNN_classifier(k=9)
my_knn.fit(X_train, y_train)
my_predict = my_knn.predict(X_test)
precision = np.sum(my_predict == y_test) / len(y_test)
print(iris.feature_names)
print(X_test)
print(f'正确率为:{precision}')















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









