






目录
1: 使用RNNcell+onehot vector
# 使用RNN+onehot
import torch
import matplotlib.pyplot as plt
input_size = 4
hidden_size =4
batch_size=1
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] #x_one_hot是list:[[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) #torch.Size([5, 1, 4])
labels = torch.LongTensor(y_data).view(-1,1) #torch.Size([5, 1])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.rnncell = torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
def forward(self,input,hidden):
hidden = self.rnncell(input,hidden)
return hidden
def init_hidden(self): #构建初始的隐层h0 [batch_size,hidden_size]
return torch.zeros(batch_size,hidden_size)
model = Model()
#Construct loss functions and optimizer.................Use Torch API...................................................#
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.1) #lr为学习率,因为0.01太小了,我改成了0.1
#plot
x_axis = []
y_axis = []
for epoch in range(15):
optimizer.zero_grad()
hidden = model.init_hidden() #hidden_size = torch.tensor([1,4])
loss = 0
print('Predicted string:',end='')
for input,label in zip(inputs,labels): #torch.Size([1, 4]) torch.Size([1])
hidden = model(input,hidden) #epoch=1:按seqlen第一次返回h1_1,第二次返回h1_1,h1_2,....返回所有的hidden
loss += criterion(hidden,label) #label 在交叉熵损失中会自动转化为one_hot vector
_,idx = hidden.max(dim=1) #按dim=1就是batch_size或者说按行取最大值和最大值所在的下标索引值,
print(idx2char[idx.item()],end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
x_axis.append(epoch)
y_axis.append(loss.item())
# drawing.....................................................................................................#
plt.figure(figsize=(7, 7), dpi=80) # 创建画布
plt.plot(x_axis, y_axis, color='b', linestyle='-') # 绘制折线图,点划线
plt.xlabel('epoch') # 设置图x轴标签
plt.ylabel('loss rate') # 设置图y轴标签
plt.legend(["loss"], title='loss&epoch', loc='upper right', fontsize=15) # 设置图列
plt.show()
D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\p12.2.py"
Predicted string:ooooo, Epoch [1/15] loss=7.1597
Predicted string:ooooo, Epoch [2/15] loss=5.9397
Predicted string:ooool, Epoch [3/15] loss=5.2407
Predicted string:ollll, Epoch [4/15] loss=4.9466
Predicted string:ollll, Epoch [5/15] loss=4.7458
Predicted string:ollll, Epoch [6/15] loss=4.5285
Predicted string:ohlll, Epoch [7/15] loss=4.2802
Predicted string:ohlll, Epoch [8/15] loss=3.9900
Predicted string:ohlll, Epoch [9/15] loss=3.6928
Predicted string:ohlol, Epoch [10/15] loss=3.4294
Predicted string:ohlol, Epoch [11/15] loss=3.2167
Predicted string:ohlol, Epoch [12/15] loss=3.0618
Predicted string:ohlol, Epoch [13/15] loss=2.9525
Predicted string:ohlol, Epoch [14/15] loss=2.8609
Predicted string:ohlol, Epoch [15/15] loss=2.7697
Process finished with exit code 0
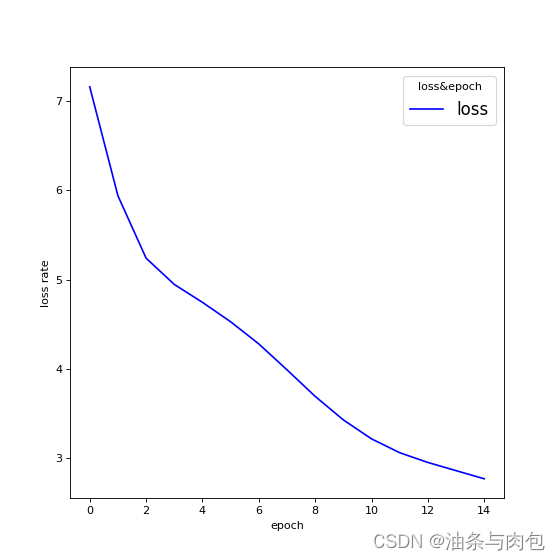
2:RNNcell+embedding层
# 使用RNN+embedding
import torch
import matplotlib.pyplot as plt
input_size = 4
hidden_size =4
batch_size=1
seq_len =5
embyayer_size =2 #2效果会比10好,更稠密
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
emd = torch.nn.Embedding(num_embeddings=seq_len,embedding_dim=embyayer_size) #num_embeddings:输入的词典大小尺寸比如有多少个词或字母,embedding_dim:嵌入向量的维度,即用多少维来表示一个符号
inputs = torch.LongTensor(x_data).view(seq_len,1) #torch.Size([5, 1])
inputs =emd(inputs)
labels = torch.LongTensor(y_data).view(-1,1) #torch.Size([5, 1])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.rnncell = torch.nn.RNNCell(input_size=embyayer_size,hidden_size=hidden_size)
def forward(self,input,hidden):
hidden = self.rnncell(input,hidden)
return hidden
def init_hidden(self): #构建初始的隐层h0 [batch_size,hidden_size]
return torch.zeros(batch_size,hidden_size)
model = Model()
#Construct loss functions and optimizer.................Use Torch API...................................................#
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.1) #lr为学习率,因为0.01太小了,我改成了0.1
#plot
x_axis = []
y_axis = []
for epoch in range(15):
optimizer.zero_grad()
hidden = model.init_hidden() #hidden_size = torch.tensor([1,4])
loss = 0
print('Predicted string:',end='')
for input,label in zip(inputs,labels): #torch.Size([1, 4]) torch.Size([1])
hidden = model(input,hidden) #epoch=1:按seqlen第一次返回h1_1,第二次返回h1_1,h1_2,....返回所有的hidden
loss += criterion(hidden,label) #label 在交叉熵损失中会自动转化为one_hot vector
_,idx = hidden.max(dim=1) #按dim=1就是batch_size或者说按行取最大值和最大值所在的下标索引值,
print(idx2char[idx.item()],end='')
loss.backward(retain_graph=True)
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
x_axis.append(epoch)
y_axis.append(loss.item())
# drawing.....................................................................................................#
plt.figure(figsize=(7, 7), dpi=80) # 创建画布
plt.plot(x_axis, y_axis, color='b', linestyle='-') # 绘制折线图,点划线
plt.xlabel('epoch') # 设置图x轴标签
plt.ylabel('loss rate') # 设置图y轴标签
plt.legend(["loss"], title='loss&epoch', loc='upper right', fontsize=15) # 设置图列
plt.show()
D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\p12.2.py"
Predicted string:lllll, Epoch [1/15] loss=7.0277
Predicted string:lllll, Epoch [2/15] loss=6.1019
Predicted string:ollll, Epoch [3/15] loss=5.2580
Predicted string:ollll, Epoch [4/15] loss=4.5176
Predicted string:ollll, Epoch [5/15] loss=4.0508
Predicted string:ollll, Epoch [6/15] loss=3.7854
Predicted string:ollll, Epoch [7/15] loss=3.5670
Predicted string:ohlll, Epoch [8/15] loss=3.3891
Predicted string:ohlol, Epoch [9/15] loss=3.2595
Predicted string:ohlol, Epoch [10/15] loss=3.1650
Predicted string:ohlol, Epoch [11/15] loss=3.0910
Predicted string:ohlol, Epoch [12/15] loss=3.0279
Predicted string:ohlol, Epoch [13/15] loss=2.9701
Predicted string:ohlol, Epoch [14/15] loss=2.9159
Predicted string:ohlol, Epoch [15/15] loss=2.8680
Process finished with exit code 0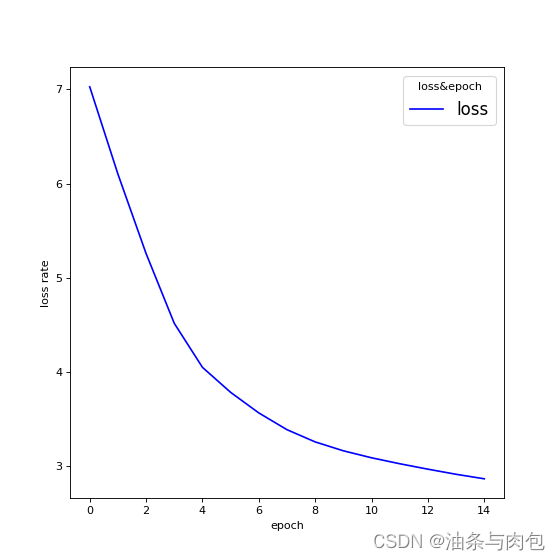
3:RNN+embedding效果不好就不跑了
4:LSTM+onehot vector
#使用LSTM+onehot vector
import torch
import matplotlib.pyplot as plt
batch_size = 1
input_size = 4
hidden_size = 4
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
one_hot_lookup = [[1,0,0,0],
[0,1,0,0],
[0,0,1,0],
[0,0,0,1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] #x_one_hot是list:[[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) #torch.Size([5, 1, 4])
labels = torch.LongTensor(y_data).view(-1,1) #torch.Size([5, 1])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.batch_size = batch_size
self.hidden_size = hidden_size
self.lineari = torch.nn.Linear(4,4)
self.linearf = torch.nn.Linear(4,4)
self.linearg = torch.nn.Linear(4,4)
self.linearo = torch.nn.Linear(4,4)
self.sigmoid = torch.nn.Sigmoid()
self.tanh = torch.nn.Tanh()
def forward(self,input,hidden,c):
i= self.sigmoid(self.lineari(input)+self.lineari(hidden))
f = self.sigmoid(self.linearf(input)+self.linearf(hidden))
g = self.tanh(self.linearg(input)+self.linearg(hidden))
o = self.sigmoid(self.linearo(input)+self.linearo(hidden))
c = f*c+i*g # 候选状态x输入状态+遗忘状态x上一个细胞状态,得到此次细胞状态
hidden = o*self.tanh(c) # 此次得到的细胞状态进行激活后,再乘以输出门,最后得到隐藏层输出
return hidden,c
def init_hidden(self): #构建初始的隐层h0 [batch_size,hidden_size]
return torch.zeros(self.batch_size, self.hidden_size)
model = Model()
#Construct loss functions and optimizer.................Use Torch API...................................................#
criterion = torch.nn.CrossEntropyLoss() #老师使用的是torch.nn.BCELoss(size_average=False)但是我使用这个损失太大了
optimizer = torch.optim.Adam(model.parameters(),lr=0.1) #lr为学习率,因为0.01太小了,我改成了0.1
#plot
x_axis = []
y_axis = []
if __name__ == '__main__':
for epoch in range(30):
optimizer.zero_grad()
hidden = model.init_hidden() # hidden_size = torch.tensor([1,4])
c = model.init_hidden()
loss = 0
print('Predicted string:', end='')
for input, label in zip(inputs, labels): # torch.Size([1, 4]) torch.Size([1])
hidden, c = model(input, hidden, c) # epoch=1:按seqlen第一次返回h1_1,第二次返回h1_1,h1_2,....返回所有的hidden
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1) # 按dim=1就是batch_size或者说按行取最大值和最大值所在的下标索引值,
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
x_axis.append(epoch)
y_axis.append(loss.item())
# drawing.....................................................................................................#
plt.figure(figsize=(7, 7), dpi=80) # 创建画布
plt.plot(x_axis, y_axis, color='b', linestyle='-') # 绘制折线图,点划线
plt.xlabel('epoch') # 设置图x轴标签
plt.ylabel('loss rate') # 设置图y轴标签
plt.legend(["loss"], title='loss&epoch', loc='upper right', fontsize=15) # 设置图列
plt.show()D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\LSTM.py"
Predicted string:hhhho, Epoch [1/15] loss=7.0191
Predicted string:ooooo, Epoch [2/15] loss=6.7005
Predicted string:ooooo, Epoch [3/15] loss=6.4368
Predicted string:ooooo, Epoch [4/15] loss=6.2037
Predicted string:olool, Epoch [5/15] loss=5.9509
Predicted string:olool, Epoch [6/15] loss=5.6828
Predicted string:ololl, Epoch [7/15] loss=5.4362
Predicted string:ololl, Epoch [8/15] loss=5.2400
Predicted string:ohlll, Epoch [9/15] loss=5.0935
Predicted string:ohlll, Epoch [10/15] loss=4.9802
Predicted string:ohlll, Epoch [11/15] loss=4.8838
Predicted string:ohlll, Epoch [12/15] loss=4.7940
Predicted string:ohlll, Epoch [13/15] loss=4.7063
Predicted string:ohlll, Epoch [14/15] loss=4.6191
Predicted string:ohlll, Epoch [15/15] loss=4.5300
Process finished with exit code 0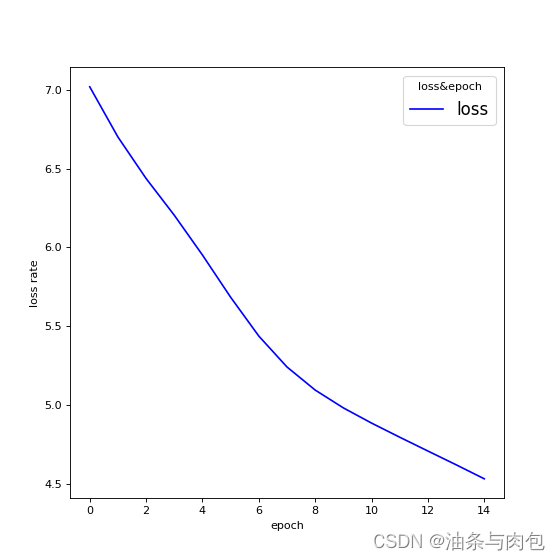
5:LSTM+Embedding
# 使用LSTM+embedding
import torch
import matplotlib.pyplot as plt
input_size = 4
hidden_size =4
batch_size=1
seq_len =5
embyayer_size =2
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
emd = torch.nn.Embedding(num_embeddings=seq_len,embedding_dim=embyayer_size) #num_embeddings:输入的词典大小尺寸比如有多少个词或字母,embedding_dim:嵌入向量的维度,即用多少维来表示一个符号
inputs = torch.LongTensor(x_data).view(seq_len,1) #torch.Size([5, 1])
inputs =emd(inputs)
labels = torch.LongTensor(y_data).view(-1,1) #torch.Size([5, 1])
# 2、定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
# 上一时刻的内部状态g(x),外部状态h(x)
self.linear_ix = torch.nn.Linear(embyayer_size, 4) # 输入门,输入值和上一阶段的外部状态值通过激活函数激活后成为输入值it
self.linear_fx = torch.nn.Linear(embyayer_size, 4) # 遗忘门,输入值和上一阶段的外部状态值通过激活函数激活后成为遗忘值ft
self.linear_gx = torch.nn.Linear(embyayer_size, 4) # 候选变量,输入值和上一阶段的外部状态值通过tanh激活函数激活后成为候选变量值
self.linear_ox = torch.nn.Linear(embyayer_size, 4) # 输出值,输入值和上一阶段的外部状态值通过激活函数激活后成为输出值ot
# 隐藏层的LSTM变换
self.linear_ih = torch.nn.Linear(4, 4)
self.linear_fh = torch.nn.Linear(4, 4)
self.linear_gh = torch.nn.Linear(4, 4)
self.linear_oh = torch.nn.Linear(4, 4)
self.sigmoid = torch.nn.Sigmoid()
self.tanh = torch.nn.Tanh()
self.batch_size = batch_size
self.hidden_size = hidden_size
def forward(self, x, hidden, c):
# 输入值x和外部状态h(x)相结合,再通过激活函数激活得到内部状态的i,f,g(候选状态),o值;
i = self.sigmoid(self.linear_ix(x) + self.linear_ih(hidden))
f = self.sigmoid(self.linear_fx(x) + self.linear_fh(hidden))
g = self.tanh(self.linear_gx(x) + self.linear_gh(hidden))
o = self.sigmoid(self.linear_ox(x) + self.linear_oh(hidden))
# 候选状态g乘以输入值i,再加上上一时刻的内部状态c乘以遗忘值f,得到该时刻的更新的内部状态值c
# 输出元素 o 乘以经过激活函数激活后的该时刻的内部状态值,得到该时刻的外部状态值
c = f * c + i * g # 上一层的结果c通过遗忘门f得到最后的输出值,加上通过输入门的上一层的候选结果g;g是候选变量相比于c,是在激活函数上不同
hidden = o * self.tanh(c) # 上式得到的结果c通过输出门
return hidden, c
def init_hidden(self):
# 生成一个默认的 batchSize * hiddenSize 全0的初始隐层h0
# batchSize 只有在需要构造 h0 的时候才需要
return torch.zeros(self.batch_size, self.hidden_size)
model = Model()
#Construct loss functions and optimizer.................Use Torch API...................................................#
criterion = torch.nn.CrossEntropyLoss() #老师使用的是torch.nn.BCELoss(size_average=False)但是我使用这个损失太大了
optimizer = torch.optim.Adam(model.parameters(),lr=0.1) #lr为学习率,因为0.01太小了,我改成了0.1
#plot
x_axis = []
y_axis = []
if __name__ == '__main__':
for epoch in range(15):
optimizer.zero_grad()
hidden = model.init_hidden() # hidden_size = torch.tensor([1,4])
c = model.init_hidden()
loss = 0
print('Predicted string:', end='')
for input, label in zip(inputs, labels): # torch.Size([1, 4]) torch.Size([1])
hidden, c = model(input, hidden, c) # epoch=1:按seqlen第一次返回h1_1,第二次返回h1_1,h1_2,....返回所有的hidden
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1) # 按dim=1就是batch_size或者说按行取最大值和最大值所在的下标索引值,
print(idx2char[idx.item()], end='')
loss.backward(retain_graph=True) # 反向传播两次,梯度相加
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
x_axis.append(epoch)
y_axis.append(loss.item())
# drawing........................................................................................................#
plt.figure(figsize=(7, 7), dpi=80) # 创建画布
plt.plot(x_axis, y_axis, color='b', linestyle='-') # 绘制折线图,点划线
plt.xlabel('epoch') # 设置图x轴标签
plt.ylabel('loss rate') # 设置图y轴标签
plt.legend(["loss"], title='loss&epoch', loc='upper right', fontsize=15) # 设置图列
plt.show()D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\LSTM+embedding.py"
Predicted string:hoooo, Epoch [1/15] loss=7.1062
Predicted string:ooooo, Epoch [2/15] loss=6.7458
Predicted string:ooooo, Epoch [3/15] loss=6.4541
Predicted string:olool, Epoch [4/15] loss=6.1653
Predicted string:ollll, Epoch [5/15] loss=5.8890
Predicted string:ollll, Epoch [6/15] loss=5.6467
Predicted string:ollll, Epoch [7/15] loss=5.4476
Predicted string:ollll, Epoch [8/15] loss=5.2873
Predicted string:ollll, Epoch [9/15] loss=5.1538
Predicted string:ollll, Epoch [10/15] loss=5.0270
Predicted string:ollll, Epoch [11/15] loss=4.8944
Predicted string:ollll, Epoch [12/15] loss=4.7780
Predicted string:ollll, Epoch [13/15] loss=4.6758
Predicted string:ollll, Epoch [14/15] loss=4.5636
Predicted string:ollll, Epoch [15/15] loss=4.4749
Process finished with exit code 0

D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\RNN.py"
Predicted string:hhlll, Epoch [1/15] loss=6.1681
Predicted string:ohlll, Epoch [2/15] loss=4.8423
Predicted string:ohlll, Epoch [3/15] loss=4.1269
Predicted string:ohlll, Epoch [4/15] loss=3.7155
Predicted string:ohlll, Epoch [5/15] loss=3.4525
Predicted string:ohlll, Epoch [6/15] loss=3.2515
Predicted string:ohlll, Epoch [7/15] loss=3.0837
Predicted string:ohlll, Epoch [8/15] loss=2.9788
Predicted string:ohlll, Epoch [9/15] loss=2.8968
Predicted string:ohlll, Epoch [10/15] loss=2.8212
Predicted string:ohlll, Epoch [11/15] loss=2.7717
Predicted string:ohllo, Epoch [12/15] loss=2.7414
Predicted string:ohllo, Epoch [13/15] loss=2.7204
Predicted string:ohlll, Epoch [14/15] loss=2.7047
Predicted string:ohlll, Epoch [15/15] loss=2.6928
Process finished with exit code 0
6:使用GRUcell+embedding
# 使用GRU+embedding
import torch
import matplotlib.pyplot as plt
nput_size = 4
hidden_size =4
batch_size=1
seq_len =5
embyayer_size =10
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
emd = torch.nn.Embedding(num_embeddings=seq_len,embedding_dim=embyayer_size) #num_embeddings:输入的词典大小尺寸比如有多少个词或字母,embedding_dim:嵌入向量的维度,即用多少维来表示一个符号
inputs = torch.LongTensor(x_data).view(seq_len,1) #torch.Size([5, 1])
inputs =emd(inputs)
labels = torch.LongTensor(y_data).view(-1,1) #torch.Size([5, 1]))
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.grucell = torch.nn.GRUCell(input_size=embyayer_size,hidden_size=hidden_size,)
def forward(self,input,hidden):
hidden = self.grucell(input,hidden)
return hidden
def init_hidden(self): #构建初始的隐层h0 [batch_size,hidden_size]
return torch.zeros(1,4)
model = Model()
#Construct loss functions and optimizer.................Use Torch API...................................................#
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
#plot
x_axis = []
y_axis = []
for epoch in range(15):
optimizer.zero_grad()
hidden = model.init_hidden() #hidden_size = torch.tensor([1,4])
loss = 0
print('Predicted string:',end='')
for input,label in zip(inputs,labels): #torch.Size([1, 4]) torch.Size([1])
hidden = model(input,hidden) #epoch=1:按seqlen第一次返回h1_1,第二次返回h1_1,h1_2,....返回所有的hidden
loss += criterion(hidden,label) #label 在交叉熵损失中会自动转化为one_hot vector
_,idx = hidden.max(dim=1) #按dim=1就是batch_size或者说按行取最大值和最大值所在的下标索引值,
print(idx2char[idx.item()],end='')
loss.backward(retain_graph=True)
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
x_axis.append(epoch)
y_axis.append(loss.item())
# drawing.....................................................................................................#
plt.figure(figsize=(7, 7), dpi=80) # 创建画布
plt.plot(x_axis, y_axis, color='b', linestyle='-') # 绘制折线图,点划线
plt.xlabel('epoch') # 设置图x轴标签
plt.ylabel('loss rate') # 设置图y轴标签
plt.legend(["loss"], title='loss&epoch', loc='upper right', fontsize=15) # 设置图列
plt.show()
D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\GRUcell.py"
Predicted string:eeeel, Epoch [1/15] loss=6.7737
Predicted string:oeeel, Epoch [2/15] loss=6.5993
Predicted string:oeeel, Epoch [3/15] loss=6.4274
Predicted string:olell, Epoch [4/15] loss=6.2608
Predicted string:ollll, Epoch [5/15] loss=6.1029
Predicted string:ollll, Epoch [6/15] loss=5.9564
Predicted string:ollll, Epoch [7/15] loss=5.8229
Predicted string:ollll, Epoch [8/15] loss=5.7020
Predicted string:ollll, Epoch [9/15] loss=5.5918
Predicted string:ollll, Epoch [10/15] loss=5.4892
Predicted string:ollll, Epoch [11/15] loss=5.3917
Predicted string:ollol, Epoch [12/15] loss=5.2974
Predicted string:ohlol, Epoch [13/15] loss=5.2050
Predicted string:ohool, Epoch [14/15] loss=5.1135
Predicted string:ohool, Epoch [15/15] loss=5.0224
Process finished with exit code 0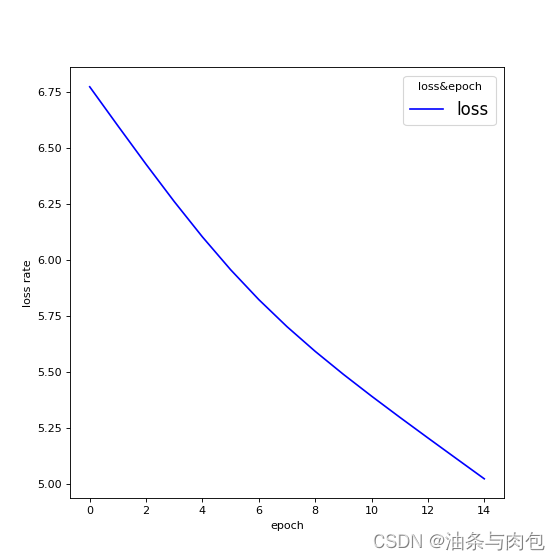
7:使用GRU +embedding
# 使用GRU+embedding
import torch
import matplotlib.pyplot as plt
batch_size =1
seq_len =5
input_size=4
hidden_size=4
num_layer =1
emblayer_size =10
idx2char = ['e','h','l','o']
x_data = [1,0,2,2,3] #hello
y_data = [3,1,2,3,2] #ohlol
emd = torch.nn.Embedding( seq_len,emblayer_size)
inputs = torch.LongTensor(x_data).view(seq_len,1) #torch.Size([5, 1, 10])
inputs = emd(inputs)
labels = torch.LongTensor(y_data).view(-1,1) #torch.Size([5, 1])
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.gru = torch.nn.GRU(input_size=emblayer_size,hidden_size=hidden_size,num_layers=num_layer,bias=True,bidirectional=False)
def forward(self,inputs,hidden):
hidden = self.gru(inputs,hidden)
return hidden
def init_hidden(self): #构建初始的隐层h0 [batch_size,hidden_size]
return torch.zeros(num_layer,batch_size,hidden_size)
model = Model()
#Construct loss functions and optimizer.................Use Torch API...................................................#
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.1) #lr为学习率,因为0.01太小了,我改成了0.1
#plot
x_axis = []
y_axis = []
for epoch in range(15):
optimizer.zero_grad()
hidden = model.init_hidden() #hidden_size = torch.tensor([1,4])
loss = 0
print('Predicted string:',end='')
out,_ = model(inputs,hidden) #根据词典尺寸,返回所有的hidden 和最后一个hidden
for hidden,label in zip(out,labels):
loss += criterion(hidden,label) #label 在交叉熵损失中会自动转化为one_hot vector
_,idx = hidden.max(dim=1) #按dim=1就是batch_size或者说按行取最大值和最大值所在的下标索引值,
print(idx2char[idx.item()],end='')
loss.backward(retain_graph=True)
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1,loss.item()))
x_axis.append(epoch)
y_axis.append(loss.item())
# drawing.....................................................................................................#
plt.figure(figsize=(7, 7), dpi=80) # 创建画布
plt.plot(x_axis, y_axis, color='b', linestyle='-') # 绘制折线图,点划线
plt.xlabel('epoch') # 设置图x轴标签
plt.ylabel('loss rate') # 设置图y轴标签
plt.legend(["loss"], title='loss&epoch', loc='upper right', fontsize=15) # 设置图列
plt.show()
D:\Anaconda\envs\study\python.exe "D:\python pycharm learning\刘二大人课程\P\GRU.py"
Predicted string:hhhhl, Epoch [1/15] loss=7.2308
Predicted string:hhool, Epoch [2/15] loss=5.4074
Predicted string:hholl, Epoch [3/15] loss=4.8057
Predicted string:hhlll, Epoch [4/15] loss=4.5004
Predicted string:hhlll, Epoch [5/15] loss=4.2753
Predicted string:hhlll, Epoch [6/15] loss=4.0504
Predicted string:hhlll, Epoch [7/15] loss=3.8148
Predicted string:hhlll, Epoch [8/15] loss=3.6016
Predicted string:hhlll, Epoch [9/15] loss=3.4599
Predicted string:hhlll, Epoch [10/15] loss=3.3889
Predicted string:hhlll, Epoch [11/15] loss=3.3540
Predicted string:hhlll, Epoch [12/15] loss=3.3296
Predicted string:hhlll, Epoch [13/15] loss=3.3052
Predicted string:hhlll, Epoch [14/15] loss=3.2784
Predicted string:hhlll, Epoch [15/15] loss=3.2516
Process finished with exit code 0
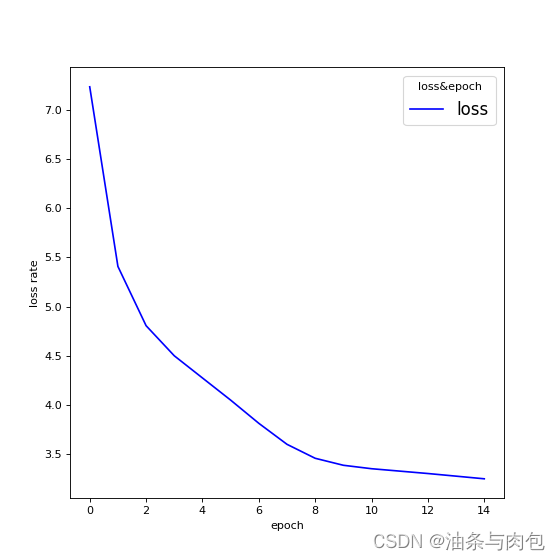
8:总结:
GRUcell+embedding方法效果看起来并没有RNN+onehot vector 或者RNNcell+embedding更优
可能和参数或者是embedding层的输出维度设置有关,这里不做探究了。















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









