







Spark SQL Dataframe API数据处理(二)
Dataframe API处理
1. 寻找热门电影类型(电影标签、演员、导演
电影数据格式为:

/* 1. 寻找热门电影类型(电影标签、演员、导演)*/
def topMovieGenres(label_type:String,k:Int):Unit = {
// 删除空值,不然会报错
val genres_df = movies_df.select(label_type).na.drop()
// 对label进行分割展平,每一个属性为一行
val res_genres_df = genres_df.flatMap(row => {
val strings = row.getString(0).trim().split("/")
strings
})
// 先转为rdd,再map成(label,1)的形式,最后根据key进行reduce
val res_genres_flat_df = res_genres_df.rdd.map((_,1)).reduceByKey((genre_value_1,genre_value_2) => (genre_value_1 + genre_value_2))
.toDF("genre","count")
// 排序
val res_top_genres = res_genres_flat_df.orderBy(desc("count"))
res_top_genres.show(k)
}
这是结果图
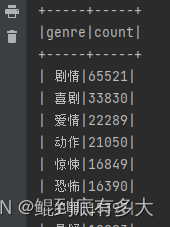
2.建立两个单独的表,分别存储电影类型与电影标签
/* 2. 建立两个单独的表,分别存储电影类型与电影标签 */
def createGenresTagsTable(label_type:String) = {
// 在写入数据库的操作中,会自动创建表
// 首先将电影类型与电影标签都拿出来,然后去重展平,附上对应的id,最后写入
val genres_df = movies_df.select(label_type).na.drop()
val flat_genres_df = genres_df.flatMap(row => {
val strings = row.getString(0).trim().split("/")
strings
}).toDF(label_type).dropDuplicates()
// zipWithIndex是构建全局唯一自增id,还有zipWithUniqueId
val label_type_index = flat_genres_df.rdd.zipWithIndex()
// 拼接id与字段
val res_label_type = label_type_index.map(e => {Row.merge(e._1,Row(e._2))})
val new_schema = flat_genres_df.schema.add(label_type+"_id",LongType)
val res_genres_df = spark.createDataFrame(res_label_type,new_schema)
res_genres_df.show(5)
res_genres_df.write.jdbc(url,label_type,prop)
}
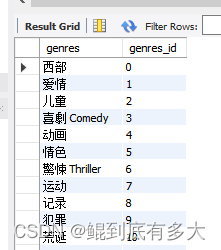
3. 过滤不合法电影名字
/* 3. 过滤不合法电影名字 */
// 有的电影名字是“天下无贼 - 电影”,后面多出了一部分,需要删除
def filterIllegalName() = {
def conver2illegal:UserDefinedFunction = udf((str:String) => {
val v = str.split("-").apply(0).trim()
v
})
val movie_ill_df = movies_df.select("movie_id","name")
.withColumn("illegal_name",conver2illegal(col("name")))
movie_ill_df.show(5)
}
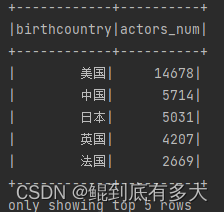
4.找出每个国家对应的演员数量
此数据在person数据表里,格式为
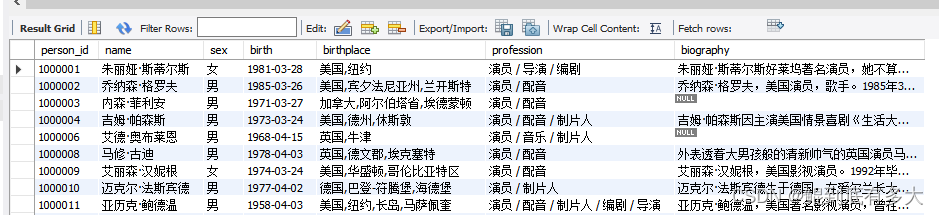
// 1. 找出每个国家对应的演员数量
// 过滤birthplace,再进行分组计数就可
def countryActors(): Unit ={
def birthCountry:UserDefinedFunction = udf((str:String) => {
val v = str.split(",").apply(0).trim()
v
})
val res_country_actor_df = person_df.select("birthplace")
.filter("birthplace is not null")
.withColumn("birthcountry",birthCountry(col("birthplace")))
.groupBy("birthcountry")
.agg(count("birthcountry").as("actors_num"))
.orderBy(desc("actors_num"))
res_country_actor_df.show(5)
}
5.每个用户对电影的平均打分和打分次数,判断用户的打分爱好
此数据在ratings表中,格式为

// 1. 每个用户对电影的平均打分和打分次数,判断用户的打分爱好
def userAvgRatingAndCount(): Unit ={
val user_avg_count_df = ratings_df
.drop("rating_time")
.groupBy("user_md5")
.agg(avg("rating"),count("rating"))
user_avg_count_df.show(5)
}
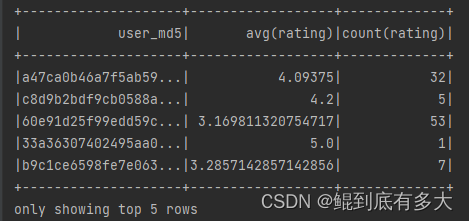
6.每部电影的平均打分,判断电影的整体评价
// 2. 每部电影的平均打分,判断电影的整体评价
def movieAvgRating(): Unit ={
val movie_avgrat_df = ratings_df.select("movie_id","rating")
.groupBy("movie_id")
.agg(avg("rating"))
movie_avgrat_df.show(5)
}
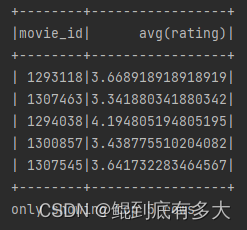
7.找出每个用户最早最晚打分时间,判断用户是否为长/短期用户
// 3. 找出每个用户最早最晚打分时间,判断用户是否为长/短期用户
// 也可以使用to_timestamp,然后转为时间戳相见再转为时间
// 参考链接:https://blog.51cto.com/u_15127692/3317805
def userRatTime(): Unit ={
val user_rat_time_df = ratings_df.select("user_md5","rating_time")
.groupBy("user_md5")
.agg(max("rating_time").as("last_time"),min("rating_time").as("pre_time"))
.withColumn("data_diff(day)",datediff(col("last_time"),col("pre_time")))
user_rat_time_df.show(10)
}
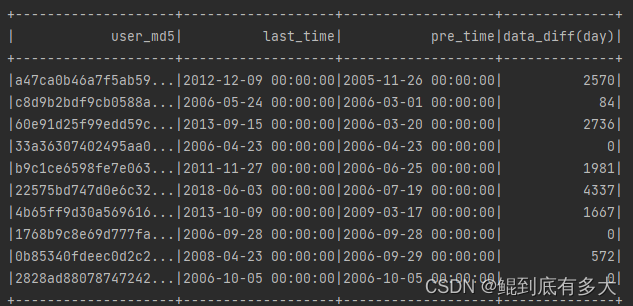
**8.找出每个用户最喜欢的电影类型(标签、导演、演员)
多表联合查询,需要连接users表,ratings表以及movies表
/* 1 找出每个用户最喜欢的电影类型
* 1. ratings与users join,用user_id替换点user_md5,sample_ratings得到
* 2. 用sample_ratings与movies join,补充电影的genres信息,得到ratings_genres
* 3. 先将ratings_genres的genres分割展平,以user_id和genre为键聚合计数,再以user_id分组对点击数进行排序,最后取出每一个用户排名那个最高的那一行
* 4. 参考链接:https://blog.csdn.net/wx1528159409/article/details/103939171
* 5. spark,url,prop是连接数据库的参数
* */
def userFavoriteGen(spark:SparkSession,url:String,prop:Properties): Unit ={
import spark.implicits._
val ratings_df = RatingsAny(spark,url,prop).ratings_df
.select("user_md5","movie_id","rating")
.filter("rating > 3") // 多个分区
val movies_df = MoviesAny(spark,url,prop).movies_df
.select("movie_id","genres") // 1个分区
val users_df = UsersAny(spark,url,prop).users_df
.select("user_id","user_md5") // 1个分区
// https://blog.csdn.net/sparkexpert/article/details/52837269/?ops_request_misc=&request_id=&biz_id=102&utm_term=spark%20%20Reference%20%27movie_id%27%20is&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-52837269.142^v73^wechat_v2,201^v4^add_ask,239^v2^insert_chatgpt&spm=1018.2226.3001.4187
// 较耗费时间
val sample_ratings_df = ratings_df.join(users_df,Seq("user_md5"),"inner")
.select("user_id","movie_id")
val rating_genres_df = sample_ratings_df.join(movies_df,Seq("movie_id") ,"inner")
.select("user_id","genres")
.filter("genres is not null")
// https://blog.csdn.net/weixin_46300771/article/details/123364722
// 有可能有空指针的错误,需要判断null值
val res_rdd = rating_genres_df
.flatMap(row => {
val uid = row.getLong(0)
val genre = row.getString(1)
if (row != null && genre != null) {
val genres = genre.trim().split("/")
for (str <- genres) yield {(uid,str,1)}
}else null
})
.rdd // (uid,genre,1)
.map(item => ((item._1,item._2),item._3)) // ((uid,genre),1)
.reduceByKey(_+_) // ((uid,genre),num)
.map(item => (item._1._1,(item._1._2,item._2 ))) // (uid,genre,num)
.groupByKey() // (uid:Long,(genre,num):Iterator)
.map(group => {
val uid = group._1
val rawRows = group._2.toBuffer
val sort_raws = rawRows.sortBy(_._2)
sort_raws.remove(0,sort_raws.length - 1) // 留下每一个用户的最后(点击次数最高)的一行
(uid,sort_raws.toIterator) // 只剩一项
})
val res_df = res_rdd.flatMap(item => {
for(ele <- item._2) yield {(item._1,ele._1,ele._2)} // group展平为RDD
}).toDF("user_id","genre","num") // 再转为DF
res_df.show(10)
}
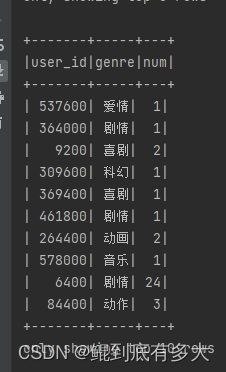
9.找出每部电影的top评论
/* 2 找出每部电影的top评论
* 1. 对于每一部电影,根据电影进行votes进行排序,再取出topk即可
* 2. 取首与尾也可以用head,tail,take,limit函数
* 特别注意null
* */
def movieTopComments(K:Int,spark:SparkSession,url:String,prop:Properties): Unit ={
import spark.implicits._
val comments_df = CommentsAny(spark,url,prop).comments_df
.select("movie_id","content","votes")
.filter("movie_id is not null")
.filter("votes is not null")
val res_rdd = comments_df
.rdd
.map(row => {(row.getLong(0),(row.getString(1),row.getInt(2)))})
.groupByKey()
.sortBy(_._2,true)
.map(group => {
val movie_id = group._1
val content_votes = group._2.toBuffer
if (content_votes.length > K) content_votes.remove(0,content_votes.length - K)
(movie_id,content_votes.toIterator)
})
val res_df = res_rdd.flatMap(item => {
val movie_id = item._1
val content_votes = item._2
for(ele <- content_votes) yield {(movie_id,ele._1,ele._2)}
}).toDF("movie_id","content","votes")
res_df.show(10)
}
乱码了,别介意















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









