









题目:如图数据(user_artist_data.txt):该数据记录的用户播放某首歌的次数。数据包括三个字段,分别为userid(用户ID),artistid(艺术家ID),playcount(播放次数)。

使用Spark SQL相关知识对该数据进行分析,分析目标如下:
(1)统计非重复的用户个数
(2)统计用户听过的歌曲总数
(3)找出ID为“1000002”的用户最喜欢的10首歌(即播放次数最多的10首歌曲)
目录
3. 加载user_artist_data.txt数据为DataFrame
7. 找出 ID 为“1000002”的用户喜欢的 10 首歌曲(即播放次数多的 10 首歌曲)
具体实现步骤代码与解析
1.上传
hdfs dfs -put user_artist_data.txt /user/root/
2.进入spark-shell
/myserver/spark301/bin/spark-shell3. 加载user_artist_data.txt数据为DataFrame
case class UserArtist(userid:Int,artistid:Int,count:Int)
val user_artist_data=sc.textFile("/user/root/user_artist_data.txt").map{x=>val y=x.split(" ");UserArtist(y(0).toInt,y(1).toInt,y(2).toInt)}.toDF()
4. 将user_artist_data注册为临时表
user_artist_data.registerTempTable("user_artist")
5.统计非重复的用户个数
val sqlContext=new org.apache.spark.sql.SQLContext(sc)
sqlContext.sql("select count(distinct userid) from user_artist").show()
6. 统计用户听过的歌曲总数
sqlContext.sql("select userid,count(distinct artistid) from user_artist group by userid").show()
7. 找出 ID 为“1000002”的用户喜欢的 10 首歌曲(即播放次数多的 10 首歌曲)
sqlContext.sql("select artistid,count from user_artist where userid=1000002 order by count desc limit 10").show()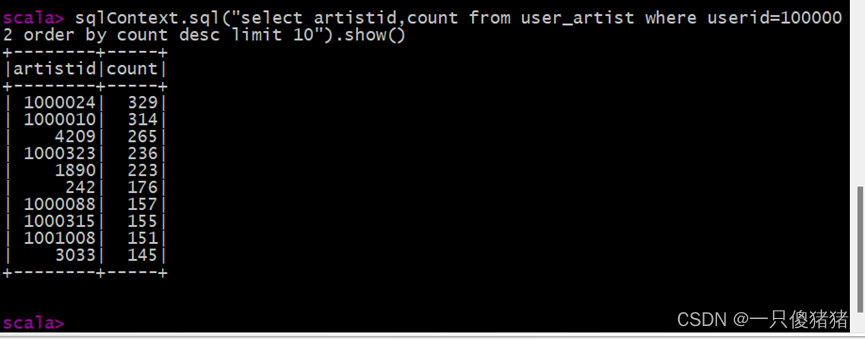















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











