







U-Net
论文:U-Net: Convolutional Networks for Biomedical Image Segmentation
Abstract:
在本文中,我们提出了一种网络和训练策略,该策略依赖于数据增强的强力使用来更有效地使用可用的带注释样本。 该架构由捕获上下文的收缩路径和实现精确定位的对称扩展路径组成。
Introduction
在过去的两年里,深度卷积网络在许多视觉识别任务中都超越了最先进的技术,例如视觉识别任务。 虽然卷积网络已经存在很长时间了,但由于可用训练集的大小和所考虑的网络的大小,它们的成功受到限制。 Krizhevsky 等人的突破是由于在具有 100 万张训练图像的ImageNet 数据集上对具有 8 层和数百万个参数的大型网络进行了监督训练。 从那时起,更大、更深的网络开始被训练。
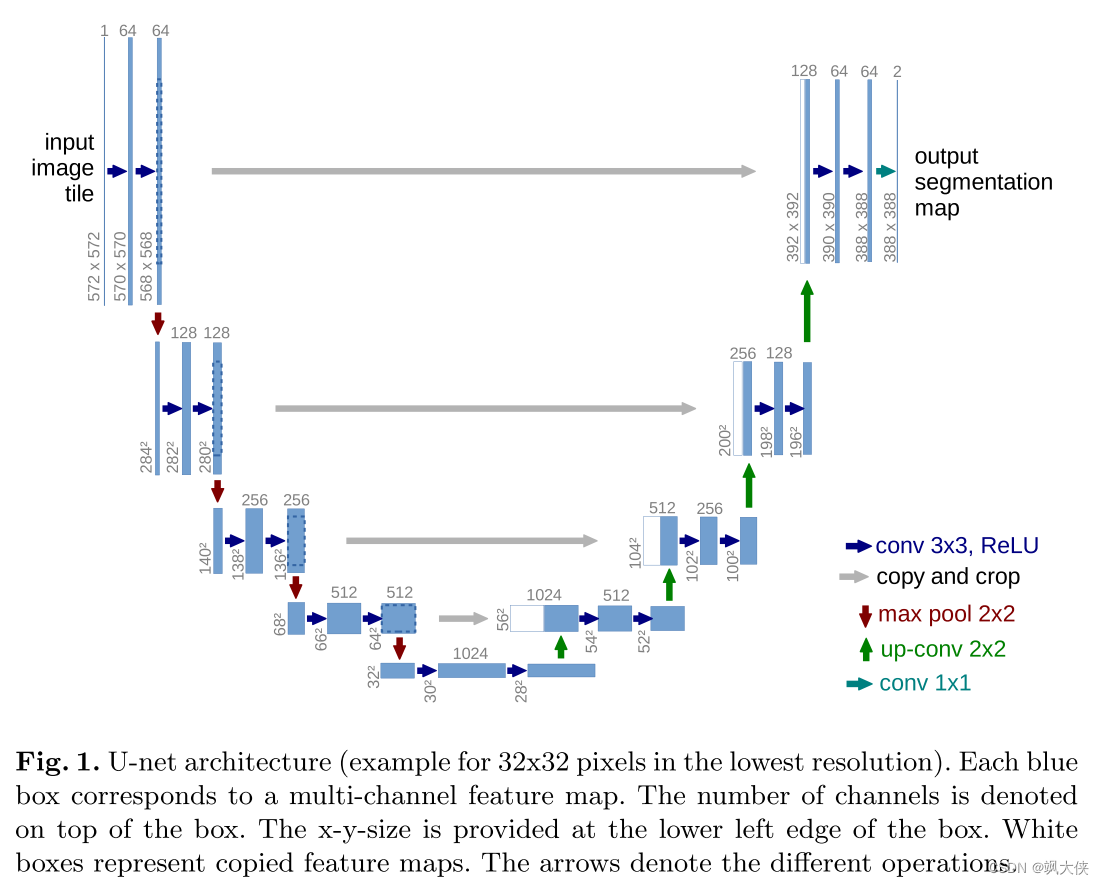 图 1. U-net 架构(最低分辨率下 32x32 像素的示例)。 每个蓝色框对应一个多通道特征图。 通道数显示在框的顶部。 x-y-尺寸位于框的左下边缘。 白框代表复制的特征图。 箭头表示不同的操作。
图 1. U-net 架构(最低分辨率下 32x32 像素的示例)。 每个蓝色框对应一个多通道特征图。 通道数显示在框的顶部。 x-y-尺寸位于框的左下边缘。 白框代表复制的特征图。 箭头表示不同的操作。
在本文中,我们构建了一种更优雅的架构,即所谓的“全卷积网络”。 我们修改和扩展了这种架构,使其能够使用很少的训练图像并产生更精确的分割; 请参见图1中的主要思想是通过连续的层来补充通常的契约网络,其中池化算子被上采样算子取代。 因此,这些层提高了输出的分辨率。 为了定位,来自收缩路径的高分辨率特征与上采样输出相结合。 然后,连续的卷积层可以学习根据这些信息组合更精确的输出。
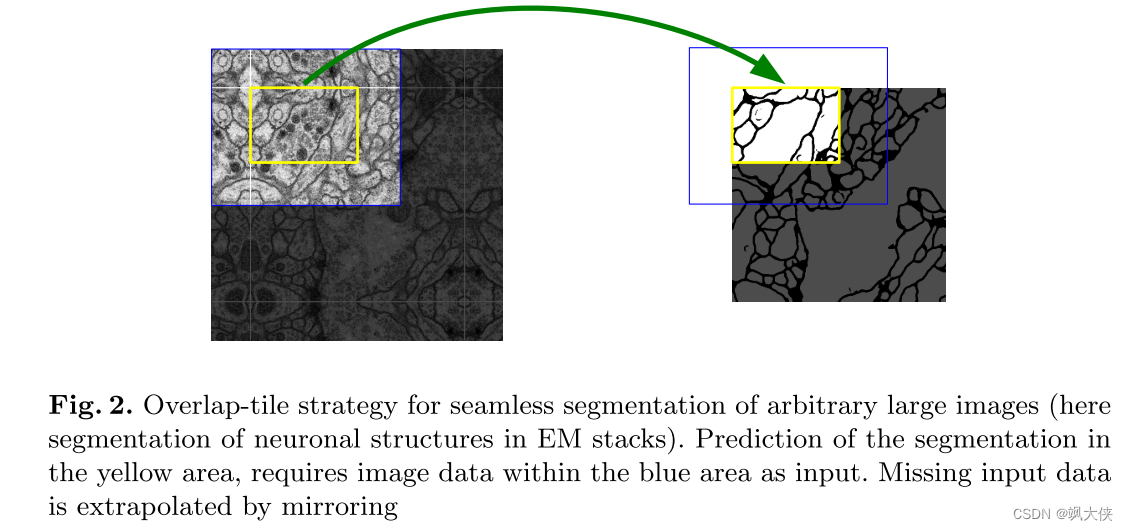
图 2. 用于任意大图像无缝分割的重叠平铺策略(此处是 EM 堆栈中神经元结构的分割)。 黄色区域分割的预测需要蓝色区域内的图像数据作为输入。 通过镜像推断丢失的输入数据
我们架构中的一个重要修改是,在上采样部分,我们还有大量特征通道,这允许网络将上下文信息传播到更高分辨率的层。 因此,扩张路径或多或少与收缩路径对称,并产生 U 形架构。 该网络没有任何完全连接的层,仅使用每个卷积的有效部分,即分割图仅包含输入图像中可用的完整上下文的像素。 该策略允许通过重叠平铺策略对任意大图像进行无缝分割(见图 2)。 为了预测图像边界区域中的像素,通过镜像输入图像来推断丢失的上下文。 这种平铺策略对于将网络应用于大图像非常重要,否则分辨率将受到 GPU 内存的限制。
Network Architecture
网络架构如图1所示。它由收缩路径(左侧)和扩展路径(右侧)组成。 收缩路径遵循卷积网络的典型架构。 它由两个 3x3 卷积(未填充卷积)的重复应用组成,每个卷积后跟一个修正线性单元 (ReLU) 和一个步长为 2 的 2x2 最大池化操作,用于下采样。在每个下采样步骤中,我们将特征通道的数量加倍。 扩展路径中的每一步都包含对特征图进行上采样,然后进行 2x2 卷积(“上卷积”),将特征通道数量减半,与收缩路径中相应裁剪的特征图进行串联,以及两个 3x3 卷积,每个卷积后跟一个 ReLU。由于每次卷积都会丢失边界像素,因此需要进行裁剪。 在最后一层,使用 1x1 卷积将每个 64 分量特征向量映射到所需数量的类。 该网络总共有 23 个卷积层。
为了实现输出分割图的无缝平铺(参见图 2),选择输入平铺大小非常重要,以便将所有 2x2 最大池操作应用于具有均匀 x 和 y 大小的层。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











