






requests库的安装
在命令行输入命令: pip install requests
requests库的七个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,是下面6个请求的基础 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页的头部,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交PATCH请求,对应于HTTP请求的PATCH |
| requests.delete() | 向HTML网页提交DELETE请求,对应于HTTP请求的DELETE |
其中,requests.get()方法最为常用,requests.request()方法是其它六个方法的基础
requests.get()
requests.get()会构造一个request对象请求服务器,并返回一个response对象
requests.get(url,param=None,**kwargs)的参数如下:
- url : 拟获取页面的url链接
- params : url中的额外参数,字典或字节流格式,可选
- **kwargs: 12个控制访问的参数
response对象的属性:
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
其中,r.encoding和r.apparent_encoding的区别:
- r.encoding:如果header中不存在charset,则认为编码为ISO‐8859‐1(r.text根据r.encoding显示内容,如果r.encoding的编码方式错误,显示内容可能会乱码)
- r.apparent_encoding:根据网页内容分析出的编码方式
可以看作是r.encoding的备选
requests库可能产生的异常如下:
 因此,使用requests时要注意异常的处理。
因此,使用requests时要注意异常的处理。
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
# 状态码不是200,则抛出HTTPError
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '抛出异常'
HTTP协议
- HTTP,Hypertext Transfer Protocol,超文本传输协议
- HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
- HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path] - host: 合法的Internet主机域名或IP地址
- port: 端口号,缺省端口为80
- path: 请求资源的路径
- HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
HTTP协议对资源的操作
 注意理解PUT和PATCH的区别:PUT将会覆盖掉URL位置的资源,而PATCH只是更新局部内容
注意理解PUT和PATCH的区别:PUT将会覆盖掉URL位置的资源,而PATCH只是更新局部内容
举个简单的例子:
如果url指向的资源存储了如下的信息:
{
“userID” : “123456789”
“userName” : “wyy”
“userPasswd” : “****”
}
若想要更改userName字段的信息(假设改为w),如果通过PUT请求,因为PUT会覆盖掉原来的信息,所以通过PUT发送请求所需要携带的数据是所有的数据
{
“userID” : “123456789”
“userName” : “w”
“userPasswd” : “****”
}
通过PATCH发送请求则只需要发送userName所对应的数据即可,
{
“userName” : “w”
}
当文件较大时,通过PATCH请求可以更加的节约流量
requests库的head()方法
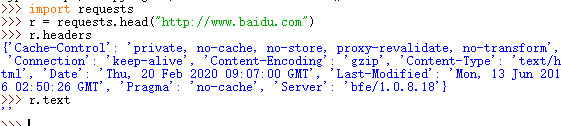 从上图可以看到,使用head()方法请求服务器,服务器会返回响应头和空的响应头,head()方法主要用于当文件很大,我们可以通过只获取响应的头部而判断出文件的具体内容是什么。
从上图可以看到,使用head()方法请求服务器,服务器会返回响应头和空的响应头,head()方法主要用于当文件很大,我们可以通过只获取响应的头部而判断出文件的具体内容是什么。
requests库的request()方法
request()方法是其他六个方法的基础,说白了,其他六个方法只不过是在request()方法进行更进一步的封装,更方便于我们的使用。
requests.request(method, url, **kwargs)参数详解:
- method(即请求方法)
- r = requests.request(‘GET’, url, **kwargs)
- r = requests.request(‘HEAD’, url, **kwargs)
- r = requests.request(‘POST’, url, **kwargs)
- r = requests.request(‘PUT’, url, **kwargs)
- r = requests.request(‘PATCH’, url, **kwargs)
- r = requests.request(‘delete’, url, **kwargs)
- r = requests.request(‘OPTIONS’, url, **kwargs)
- url:即url链接
- **kwargs: 控制访问的参数,均为可选项
- params : 字典或字节序列,作为参数增加到url中
- data : 字典、字节序列或文件对象,作为Request的内容
- json : JSON格式的数据,作为Request的内容
- headers : 字典,HTTP定制头
- cookies : 字典或CookieJar,Request中的cookie
- auth : 元组,支持HTTP认证功能
- files : 字典类型,传输文件
- timeout : 设定超时时间,秒为单位
- proxies : 字典类型,设定访问代理服务器,可以增加登录认证
- allow_redirects : True/False,默认为True,重定向开关
- stream : True/False,默认为True,获取内容立即下载开关
- verify : True/False,默认为True,认证SSL证书开关
- cert : 本地SSL证书路径
有13个可选的关键字参数,其余六个方法,都是从request()方法封装而来
两个简单的爬虫实例
- 爬取百度首页: https://www.baidu.com

首先在IDLE环境下导入requests库,接着通过requests.get()方法获取返回的response对象,查看返回的状态码,即r.status_code,状态码为200,表示成功返回数据,接着查看其编码,是"ISO-8859-1"?
接着,我们查看返回的文本内容:
 我们发现,是乱码!!!我们可以通过apparent_encoding这个属性来查看requests库通过文本分析出来的编码格式
我们发现,是乱码!!!我们可以通过apparent_encoding这个属性来查看requests库通过文本分析出来的编码格式
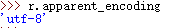 由此可见,这段文本的编码格式应该是utf-8。所以,我们应该通过更改r.encoding属性来更改编码格式
由此可见,这段文本的编码格式应该是utf-8。所以,我们应该通过更改r.encoding属性来更改编码格式
 现在,文本内容就不会乱码了
现在,文本内容就不会乱码了
r.encoding是根据响应头的信息来推断编码方式,如果服务器没有编码格式的要求,那么响应头可能就没有相应的charset(即编码格式),那么r.encoding就会采用默认的编码格式’ISO8859-1’,而r.apparent_encoding是通过文本内容分析文本的编码格式,因此更为可靠。
爬取百度首页的完整代码如下:
import requests
try:
r = requests.get("https://www.baidu.com")
# 如果状态码不是200,则抛出异常
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print("异常")
- 爬取亚马逊某一商品网页的信息
url:https://www.amazon.cn/dp/B017J9KKJ0?ref_=Oct_DLandingS_D_112308e2_60&smid=A2EDK7H33M5FFG
 状态码居然是503!!!为什么呢?这是因为亚马逊的服务器通过请求头的user-agent字段判断出我们不是浏览器访问,因此拒绝了我们的访问,我们可以通过r.request.headers这个属性来查看我们的请求头
状态码居然是503!!!为什么呢?这是因为亚马逊的服务器通过请求头的user-agent字段判断出我们不是浏览器访问,因此拒绝了我们的访问,我们可以通过r.request.headers这个属性来查看我们的请求头
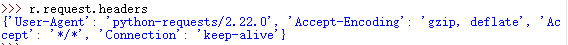 我们可以看到,User-Agent这个字段对应的值是python-requests/2.22.0,因此亚马逊的服务器可以通过这个来判断我们并不是通过浏览器访问网页。我们可以更改请求头User-Agent的值来冒充浏览器访问该网页。
我们可以看到,User-Agent这个字段对应的值是python-requests/2.22.0,因此亚马逊的服务器可以通过这个来判断我们并不是通过浏览器访问网页。我们可以更改请求头User-Agent的值来冒充浏览器访问该网页。
 我们使用了requests.get()方法中headers可选关键字参数,将请求头的user-agent的值改为Mozilla/5.0达到冒充服务器的效果
我们使用了requests.get()方法中headers可选关键字参数,将请求头的user-agent的值改为Mozilla/5.0达到冒充服务器的效果
完整代码如下:
import requests
try:
r = requests.get('https://www.amazon.cn/dp/B017J9KKJ0?ref_=Oct_DLandingS_D_112308e2_60&smid=A2EDK7H33M5FFG', headers = {'user-agent' : 'Mozilla/5.0'})
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print('抛出异常')















 4100
4100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









