







Robots协议
网络爬虫的问题
在讲python网络爬虫之前,先来看看网络爬虫的一些问题以及robots协议。首先python爬虫功能主要使用的库有Requests库和Scrapy库。他们的区别如下:

正常情况下Web服务器默认接收人类访问,受限于编写水平和目的,网络爬虫将会带来一些问题:
1、性能骚扰:为Web服务器带来巨大的资源开销;
2、法律风险:服务器上的数据有产权归属网络爬虫获取数据后牟利将带来法律风险;
3、隐私泄露:网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。
网络爬虫的限制
1、来源审查:判断User‐Agent进行限制。检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问。
2、发布公告:Robots协议。告知所有爬虫网站的爬取策略,要求爬虫遵守。
Robots协议:Robots Exclusion Standard,网络爬虫排除标准。作用:网站告知网络爬虫哪些页面可以抓取,哪些不行。形式:在网站根目录下的robots.txt文件。
例如下面一些真实的robots协议文件:
http://www.baidu.com/robots.txt
http://news.sina.com.cn/robots.txt
http://www.moe.edu.cn/robots.txt (页面不存在,表示带网站没有robots协议,所以它对爬虫默认没有任何限制)。
我们访问http://www.jd.com/robots.txt,可以得到如下的内容:
User‐agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User‐agent: EtaoSpider
Disallow: /
User‐agent: HuihuiSpider
Disallow: /
User‐agent: GwdangSpider
Disallow: /
User‐agent: WochachaSpider
Disallow: /
Robots协议基本语法:
# 注释,*代表所有,/代表根目录
User‐agent: *
Disallow: /
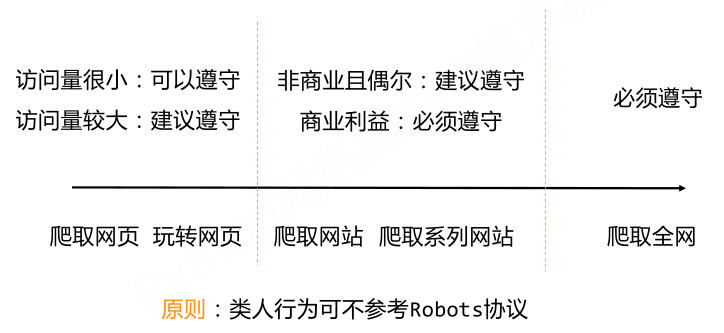
那么在实际的应用中,我们该如何使用robots协议呢?网络爬虫首先应该自动或人工识别robots.txt,再进行内容爬取。需要注意的是:robots协议的约束性:Robots协议是建议但非约束性,网络爬虫可以不遵守,但可能存在法律风险。下面的使用原则可以参考:
Http协议
我们要进行网络内容的获取,必须首先对HTTP协议有一个简单的了解。HTTP,Hypertext Transfer Protocol,超文本传输协议。HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]。
host: 合法的Internet主机域名或IP地址;
port: 端口号,缺省端口为80;
path: 请求资源的路径。
HTTP URL实例:
http://www.bit.edu.cn
http://220.181.111.188/duty
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









