






目录
哈夫曼树和哈夫曼编码表定义
//哈夫曼树结点类型定义
struct HTNode
{
double weight; //结点的权值
int parent, lch, rch; //结点的双亲,左孩子,右孩子
};
typedef HTNode* HuffmanTree; //动态分配数组存储哈夫曼树
typedef char** HuffmanCode; //动态分配数组存储哈夫曼编码表(char* cd[start])
构造哈夫曼树
//构造哈夫曼树
void CreateHuffmanTree(HuffmanTree& HT, int n)
{
//1.初始化哈夫曼树
if (n <= 1) //如果n<=1不在继续向下执行
{
return;
}
int m = 2 * n - 1; //数组共2n-1个元素
HT = new HTNode[m + 1]; //0号单元未使用,HT[m]表示根结点
//将m个元素的lch、rch、parent置为0
for (int i = 1; i <= m; i++)
{
HT[i].parent = 0;
HT[i].lch = 0;
HT[i].rch = 0;
}
//输入前n个元素的weigth值
for (int i = 1; i <= n; i++)
{
cout << "请输入第" << i << "个元素的权值:" << endl;
cin >> HT[i].weight;
}
//2.初始化结束,构建哈夫曼树
for (int i = n + 1; i <= m; i++) //合并产生n-1个结点
{
//在HT[k](1<=k<=i-1)中选择两个其双亲域为0
//且权值最小的结点,并返回它们在HT中的序号s1和s2
int s1 = 0, s2 = 0;
Selete(HT, i - 1, s1, s2);
HT[s1].parent = i; //s1、s2的双亲为i
HT[s2].parent = i;
HT[i].lch = s1; //s1、s2分别作为i的左右孩子
HT[i].rch = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight; //i的权值为左右孩子权值的和
}
}select函数寻找双亲节点不为0的权重最小的2个节点
//在HT[k](1<=k<=i-1)中选择两个其双亲域为0,且权值最小的结点,并返回它们在HT中的序号s1和s2
void Selete(HuffmanTree HT, int i, int &s1, int &s2)
{
double min = INT_MAX; //INT_MAX是一个很大的数,要使用头文件limits
for (int j = 1; j <= i; j++)
{
//如果第j个元素的weight值小于min,且第j个元素的双亲值为0
//则将该值赋给min,j赋值给是s1
if ( min > HT[j].weight && HT[j].parent == 0)
{
min = HT[j].weight;
s1 = j;
}
}
min = INT_MAX; //重新给min赋值
for (int j = 1; j <= i; j++)
{
//如果第j个元素的weight值小于min,且j不等于s1,且第j个元素的双亲值为0
//则将该值赋给min,j赋值给是s2
if (min > HT[j].weight && j != s1 && HT[j].parent == 0)
{
min = HT[j].weight;
s2 = j;
}
}
}哈夫曼编码算法实现
//哈夫曼编码
void CreateHuffmanCode(HuffmanTree HT, HuffmanCode& HC, int n)
{
HC = new char* [n + 1];//分配n个字符编码的头指针矢量,从1号位置开始,0号位置不使用
char* cd = new char[n];//分配临时存放编码的动态数组空间
cd[n - 1] = '\0'; //数组末尾存放结束符
for (int i = 1; i <= n; i++) //逐个字符求哈夫曼编码
{
int start = n - 1;//start开始时指向最后,即编码结束符的位置
int c = i;//c用于记录从叶子结点向上回溯至根结点所经过的结点下标
int f = HT[i].parent;//f指向结点c的双亲结点
while (f != 0)//从叶子结点开始向上回溯,直到根结点
{
--start;//回溯一次,start向前一个位置
if (HT[f].lch == c)
{
cd[start] = '0'; //结点c时f的左孩子,则生成代码0
}
else
{
cd[start] = '1'; //结点c时f的右孩子,则生成代码1
}
//继续向上回溯
c = f;
f = HT[f].parent;
}
HC[i] = new char[n - start];//为第i个字符编码分配空间
strcpy(HC[i], &cd[start]);//将求得的编码从临时空间cd复制到HC的当前行中
}
delete[] cd;//释放零时空间
}测试代码
int main()
{
//例:设n=7,w={0.4,0.3,0.15,0.05,0.04,0.03,0.03}构造哈夫曼树
HuffmanTree HT;
int n = 7;
CreateHuffmanTree(HT, n);
//输出
cout << "下标" << "\t" << "weight" << "\t" << "parent"
<< "\t" << "lch" << "\t" << "rch" << endl;
for (int i = 1; i <= 2 * n - 1; i++)
{
cout << i << "\t" << HT[i].weight << "\t" << HT[i].parent
<< "\t" << HT[i].lch << "\t" << HT[i].rch << endl;
}
cout << endl;
//设计Huffman code(哈夫曼编码)
HuffmanCode HC;
CreateHuffmanCode(HT, HC, n);
for (int i = 1; i <= n; i++)
{
cout << "第" << i << "个字符的编码为:" << HC[i] << endl;
}
system("pause");
return 0;
}测试结果
例:设n=7,w={0.4,0.3,0.15,0.05,0.04,0.03,0.03}构造哈夫曼树,并求哈夫曼编码
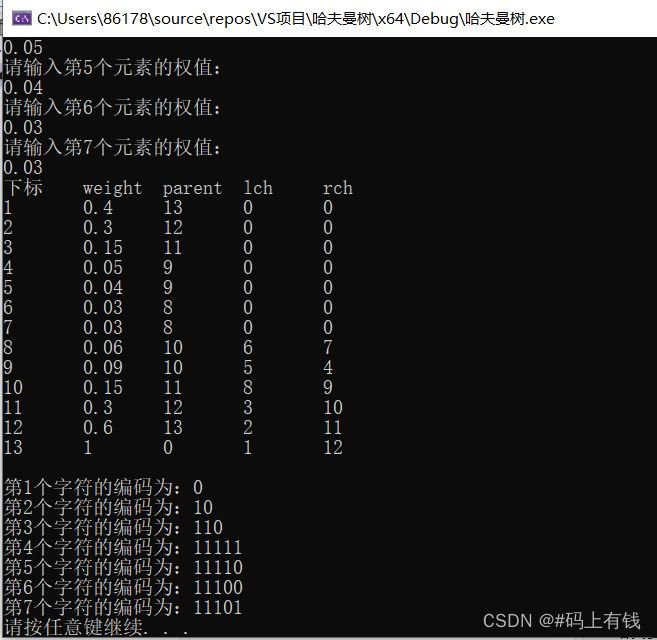
完整代码
#define _CRT_SECURE_NO_WARNINGS //VS使用strcopy函数要加这个常量
#include<iostream>
using namespace std;
#include<limits>
//哈夫曼树结点类型定义
struct HTNode
{
double weight; //结点的权值
int parent, lch, rch; //结点的双亲,左孩子,右孩子
};
typedef HTNode* HuffmanTree; //动态分配数组存储哈夫曼树
typedef char** HuffmanCode; //动态分配数组存储哈夫曼编码表(char* cd[start])
//声明
void Selete(HuffmanTree HT, int i, int& s1, int& s2);
//构造哈夫曼树
void CreateHuffmanTree(HuffmanTree& HT, int n)
{
//1.初始化哈夫曼树
if (n <= 1) //如果n<=1不在继续向下执行
{
return;
}
int m = 2 * n - 1; //数组共2n-1个元素
HT = new HTNode[m + 1]; //0号单元未使用,HT[m]表示根结点
//将m个元素的lch、rch、parent置为0
for (int i = 1; i <= m; i++)
{
HT[i].parent = 0;
HT[i].lch = 0;
HT[i].rch = 0;
}
//输入前n个元素的weigth值
for (int i = 1; i <= n; i++)
{
cout << "请输入第" << i << "个元素的权值:" << endl;
cin >> HT[i].weight;
}
//2.初始化结束,构建哈夫曼树
for (int i = n + 1; i <= m; i++) //合并产生n-1个结点
{
//在HT[k](1<=k<=i-1)中选择两个其双亲域为0
//且权值最小的结点,并返回它们在HT中的序号s1和s2
int s1 = 0, s2 = 0;
Selete(HT, i - 1, s1, s2);
HT[s1].parent = i; //s1、s2的双亲为i
HT[s2].parent = i;
HT[i].lch = s1; //s1、s2分别作为i的左右孩子
HT[i].rch = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight; //i的权值为左右孩子权值的和
}
}
//在HT[k](1<=k<=i-1)中选择两个其双亲域为0,且权值最小的结点,并返回它们在HT中的序号s1和s2
void Selete(HuffmanTree HT, int i, int &s1, int &s2)
{
double min = INT_MAX; //INT_MAX是一个很大的数,要使用头文件limits
for (int j = 1; j <= i; j++)
{
//如果第j个元素的weight值小于min,且第j个元素的双亲值为0
//则将该值赋给min,j赋值给是s1
if ( min > HT[j].weight && HT[j].parent == 0)
{
min = HT[j].weight;
s1 = j;
}
}
min = INT_MAX; //重新给min赋值
for (int j = 1; j <= i; j++)
{
//如果第j个元素的weight值小于min,且j不等于s1,且第j个元素的双亲值为0
//则将该值赋给min,j赋值给是s2
if (min > HT[j].weight && j != s1 && HT[j].parent == 0)
{
min = HT[j].weight;
s2 = j;
}
}
}
//哈夫曼编码
void CreateHuffmanCode(HuffmanTree HT, HuffmanCode& HC, int n)
{
HC = new char* [n + 1];//分配n个字符编码的头指针矢量,从1号位置开始,0号位置不使用
char* cd = new char[n];//分配临时存放编码的动态数组空间
cd[n - 1] = '\0'; //数组末尾存放结束符
for (int i = 1; i <= n; i++) //逐个字符求哈夫曼编码
{
int start = n - 1;//start开始时指向最后,即编码结束符的位置
int c = i;//c用于记录从叶子结点向上回溯至根结点所经过的结点下标
int f = HT[i].parent;//f指向结点c的双亲结点
while (f != 0)//从叶子结点开始向上回溯,直到根结点
{
--start;//回溯一次,start向前一个位置
if (HT[f].lch == c)
{
cd[start] = '0'; //结点c时f的左孩子,则生成代码0
}
else
{
cd[start] = '1'; //结点c时f的右孩子,则生成代码1
}
//继续向上回溯
c = f;
f = HT[f].parent;
}
HC[i] = new char[n - start];//为第i个字符编码分配空间
strcpy(HC[i], &cd[start]);//将求得的编码从临时空间cd复制到HC的当前行中
}
delete[] cd;//释放零时空间
}
int main()
{
//例:设n=7,w={0.4,0.3,0.15,0.05,0.04,0.03,0.03}构造哈夫曼树
HuffmanTree HT;
int n = 7;
CreateHuffmanTree(HT, n);
//输出
cout << "下标" << "\t" << "weight" << "\t" << "parent"
<< "\t" << "lch" << "\t" << "rch" << endl;
for (int i = 1; i <= 2 * n - 1; i++)
{
cout << i << "\t" << HT[i].weight << "\t" << HT[i].parent
<< "\t" << HT[i].lch << "\t" << HT[i].rch << endl;
}
cout << endl;
//设计Huffman code(哈夫曼编码)
HuffmanCode HC;
CreateHuffmanCode(HT, HC, n);
for (int i = 1; i <= n; i++)
{
cout << "第" << i << "个字符的编码为:" << HC[i] << endl;
}
system("pause");
return 0;
}














 9758
9758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









