







哈夫曼树(Huffman Tree)是一种带权路径长度最短的二叉树,也称为最优二叉树。它的构建基于哈夫曼编码,是一种广泛应用于数据压缩的算法。在哈夫曼树中,权重高的节点离根节点较近,而权重低的节点离根节点较远,从而使得整棵树的带权路径长度最小。
带权路径长度(Weighted Path Length, WPL)是指树中所有叶子节点的权值乘以其到根节点的路径长度(即边数)之和。哈夫曼树的目标就是构造一棵具有最小WPL的树。
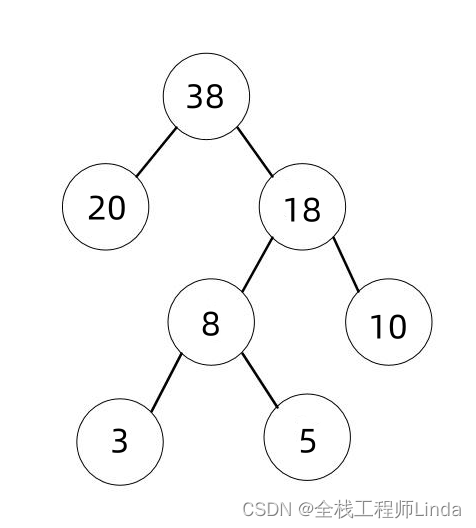
哈夫曼树的构建过程可以概括为以下步骤:
1. 创建一个优先队列(最小堆),用于存放待处理的节点。每个节点包含权值和指向其子节点的指针(初始时均为空)。
2. 将所有叶子节点(即原始数据)的权值作为初始节点加入优先队列。
3. 从优先队列中取出权值最小的两个节点A和B,作为新节点的左右子节点,新节点的权值为A和B的权值之和。
4. 将新节点加入优先队列。
5. 重复步骤3和4,直到优先队列中只剩下一个节点,这个节点就是根节点,整棵树构建完成。
下面是一个用C++实现哈夫曼树构建的简单示例,代码如下:
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
struct Node {
int weight;
Node* left;
Node* right;
Node(int w) : weight(w), left(nullptr), right(nullptr) {}
};
struct cmp {
bool operator()(Node* a, Node* b) {
return a->weight > b->weight;
}
};
Node* buildHuffmanTree(vector<int>& weights) {
priority_queue<Node*, vector<Node*>, cmp> pq;
for (int weight : weights) {
pq.push(new Node(weight));
}
while (pq.size() > 1) {
Node* left = pq.top(); pq.pop();
Node* right = pq.top(); pq.pop();
Node* parent = new Node(left->weight + right->weight);
parent->left = left;
parent->right = right;
pq.push(parent);
}
return pq.top(); // 返回根节点
}
void printCodes(Node* root, string str, vector<string>& codes) {
if (root->left == nullptr && root->right == nullptr) {
codes.push_back(str);
return;
}
printCodes(root->left, str + "0", codes);
printCodes(root->right, str + "1", codes);
}
int main() {
vector<int> weights = {5, 9, 12, 13, 16, 45}; // 示例权值
Node* root = buildHuffmanTree(weights);
vector<string> codes;
printCodes(root, "", codes);
for (int i = 0; i < weights.size(); ++i) {
cout << "Weight " << weights[i] << ": Huffman code " << codes[i] << endl;
}
// 注意:在实际应用中,还需要实现释放内存的代码,这里为了简洁省略了。
return 0;
}运行结果如下图所示。
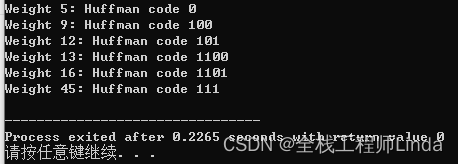
上述代码中,我们首先定义了一个`Node`结构体表示哈夫曼树的节点,包含一个权值、左子节点和右子节点。然后,我们使用C++的`priority_queue`容器(优先队列)来实现最小堆,并定义了比较函数`cmp`用于比较节点的权值。在`buildHuffmanTree`函数中,我们按照哈夫曼树的构建过程逐步构建整棵树,并返回根节点。最后,在`printCodes`函数中,我们使用递归的方式遍历哈夫曼树,生成每个叶子节点的哈夫曼编码,并存储在`codes`向量中。在`main`函数中,我们调用这些函数并输出每个叶子节点的权值和对应的哈夫曼编码。
哈夫曼树在数据压缩领域有着广泛的应用。哈夫曼编码是一种非常有效的数据压缩方法,它根据字符出现的频率来构建哈夫曼树,并给每个字符分配一个唯一的二进制编码。字符频率越高,其编码越短,反之则越长。这种变长编码方法可以有效地减少数据冗余,实现数据的高效压缩。
下面是一个简单的C++程序,它使用哈夫曼树(Huffman Tree)来构建哈夫曼编码,并编码一段文本。这个例子会创建一个哈夫曼树,然后使用该树对给定的文本进行编码。代码如下。
#include <iostream>
#include <string>
#include <unordered_map>
#include <queue>
#include <vector>
// TreeNode 表示哈夫曼树中的节点
struct TreeNode {
char data; // 字符
unsigned freq; // 频率
TreeNode* left; // 左子节点
TreeNode* right; // 右子节点
TreeNode(char data, unsigned freq) : data(data), freq(freq), left(nullptr), right(nullptr) {}
};
// Compare 用于定义优先队列的比较方式
struct Compare {
bool operator()(TreeNode* l, TreeNode* r) {
return l->freq > r->freq;
}
};
// getHuffmanCode 递归函数,用于生成哈夫曼编码
void getHuffmanCode(TreeNode* root, std::string code, std::unordered_map<char, std::string>& huffmanCodes) {
if (root == nullptr) {
return;
}
if (root->data != '$') {
huffmanCodes[root->data] = code;
}
getHuffmanCode(root->left, code + "0", huffmanCodes);
getHuffmanCode(root->right, code + "1", huffmanCodes);
}
// buildHuffmanTree 根据字符频率构建哈夫曼树
std::priority_queue<TreeNode*, std::vector<TreeNode*>, Compare> buildHuffmanTree(const std::unordered_map<char, int>& freqMap) {
std::priority_queue<TreeNode*, std::vector<TreeNode*>, Compare> pq;
for (const auto& pair : freqMap) {
pq.push(new TreeNode(pair.first, pair.second));
}
while (pq.size() > 1) {
TreeNode* left = pq.top(); pq.pop();
TreeNode* right = pq.top(); pq.pop();
TreeNode* parent = new TreeNode('$', left->freq + right->freq);
parent->left = left;
parent->right = right;
pq.push(parent);
}
return pq;
}
int main() {
std::string text = "this is an example for huffman encoding";
std::unordered_map<char, int> freqMap;
// 计算字符频率
for (char ch : text) {
freqMap[ch]++;
}
// 构建哈夫曼树
std::priority_queue<TreeNode*, std::vector<TreeNode*>, Compare> huffmanTree = buildHuffmanTree(freqMap);
// 获取哈夫曼编码
std::unordered_map<char, std::string> huffmanCodes;
getHuffmanCode(huffmanTree.top(), "", huffmanCodes);
// 打印哈夫曼编码
std::cout << "Character\tFrequency\tHuffman Code" << std::endl;
for (const auto& pair : freqMap) {
std::cout << pair.first << "\t\t" << pair.second << "\t\t" << huffmanCodes[pair.first] << std::endl;
}
// 释放哈夫曼树的内存
TreeNode* root = huffmanTree.top();
while (root != nullptr) {
if (root->left != nullptr) {
delete root->left;
root->left = nullptr;
}
if (root->right != nullptr) {
delete root->right;
root->right = nullptr;
}
TreeNode* temp = root;
root = root->left; // 随意设置为left或right,因为其他子节点已被删除
delete temp;
}
return 0;
}运行结果如下。
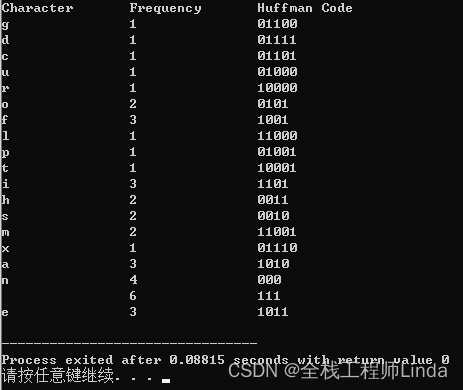
上述代码中,我们首先计算输入文本中每个字符的频率,然后构建哈夫曼树。接着,它遍历哈夫曼树以获取每个字符的哈夫曼编码,并打印出字符、频率和对应的哈夫曼编码。最后,它释放了哈夫曼树占用的内存。
请注意,这个程序没有实现哈夫曼编码的解码功能,也没有考虑特殊字符(如空格、标点符号等)和字符的大小写。在实际项目中,你可能需要更复杂的逻辑来处理这些情况。但是,这个简单的例子应该足以展示如何使用C++来构建和使用哈夫曼树。















 4034
4034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











