









条件
采用64位Oracle Linux 6.4, JDK:1.8.0_131 64位, Hadoop:2.7.3
Spark集群实验环境共包含3台服务器,每台机器的主要参数如表所示:
| 服务器 | HOSTNAME | IP | 功能 |
|---|---|---|---|
| spark1 | spark1 | 92.16.17.1 | NN/DN/RM Master/Worker |
| spark2 | spark2 | 92.16.17.2 | DN/NM/Worker |
| spark3 | spark3 | 92.16.17.3 | DN/NM/Worker |
过程
- 格式化NameNode节点
Hadoop集群第一次运行需要先格式化 NameNode 节点, 使用如所示命令:

- 启动HDFS文件系统
切换到启动脚本所在的 $HADOOP_HOME/sbin 目录,执行 start-dfs.sh 脚本:
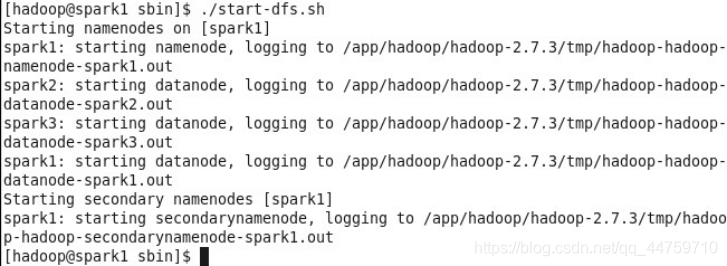
分别在三台主机上使用jps命令验证NameNode和各DataNode:

- 启动YARN
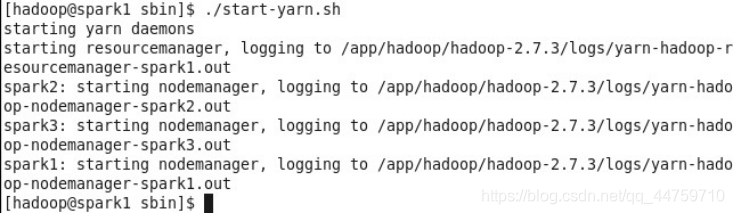
此时,在 spark1 上运行的进程有 NameNode, SecondaryNameNode, DataNode, ResourceManager, NodeManager:
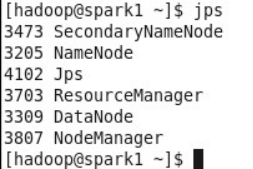
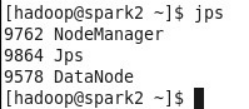
在spark2和spark3上运行的进程有DataNode和NodeManager:















 9026
9026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









