







ShardingSphere-JDBC
简单介绍
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
Sharding-JDBC的主要目的是简化对分库分表之后数据相关操作
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。

环境搭建
maven依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
</dependencies>
yml基本配置
server:
port: 8081
spring:
application:
name: user-service
main:
allow-bean-definition-overriding: true
datasource:
username: jiang
password: jiang
url: jdbc:mysql://localhost:3306/manager?characterEncoding=UTF-8&serverTimezone=UTC
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 30000
validationQuery: select 'x';
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
filters: stat,wall,slf4j
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
useGlobalDataSourceStat: true
mybatis-plus:
global-config:
db-config:
table-prefix: tb_
id-type: assign_id
logic-delete-field: deleted
logic-delete-value: 1
logic-not-delete-value: 0
logging:
level:
test.codekiller.top.testshardingjdbc: debug
水平分表
建表

CREATE TABLE `tb_course_1` (
`id` bigint(64) NOT NULL COMMENT '课程id',
`name` varchar(50) NOT NULL COMMENT '课程名称',
`user_id` bigint(20) NOT NULL COMMENT '课程的用户id',
`status` varchar(10) NOT NULL COMMENT '状态',
`version` bigint(20) DEFAULT '0' COMMENT '版本,乐观锁',
`deleted` tinyint(1) DEFAULT '0' COMMENT '逻辑删除,1删除,0没删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
CREATE TABLE `tb_course_2` (
`id` bigint(64) NOT NULL COMMENT '课程id',
`name` varchar(50) NOT NULL COMMENT '课程名称',
`user_id` bigint(20) NOT NULL COMMENT '课程的用户id',
`status` varchar(10) NOT NULL COMMENT '状态',
`version` bigint(20) DEFAULT '0' COMMENT '版本,乐观锁',
`deleted` tinyint(1) DEFAULT '0' COMMENT '逻辑删除,1删除,0没删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
实体类
/**
* @author codekiller
* @date 2020/7/12 0:44
* @Description 课程实体类
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Course {
@TableId
private Long cid;
private String name;
private Long userId;
private String status;
@Version
private Long version;
private Boolean deleted;
}
mapper
public interface CourseMapper extends BaseMapper<Course1> {
}
分片配置
👉打开官网
#shardingjdbc分片策略
#配置数据源,给数据源配置名字,可配置多个,eg:ds0,ds1
spring.shardingsphere.datasource.names=ds0
#这里因为只有一个数据源,配置一个数据源的信息就行了
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/sharding_sphere?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds0.username=jiang
spring.shardingsphere.datasource.ds0.password=jiang
#指定tb_course表的分布情况,使用行内表达式配置表在哪个数据库里面,表名称是什么。
# 如果有12个,就是${1..12}。如果有两个数据原ds$->{0..1}.t_course_$->{1..2}
spring.shardingsphere.sharding.tables.tb_course.actual-data-nodes=ds0.tb_course_$->{1..2}
#指定course表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_course.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_course.key-generator.type=SNOWFLAKE
# 指定分片策略,约定id值的偶数加到tb_course_1,奇数加到tb_course_2表
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.sharding-column= id
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.algorithm-expression=tb_course_$->{id%2+1}
#代开sql输出日志
spring.shardingsphere.props.sql.show=true
- 我这里只配置了一个数据源,多个数据源配置请看👉分库
- 配置中的ds0是数据源名称,tb_course是表的名称
测试(报错)
插入
@Autowired
private CourseMapper courseMapper;
@Test
void contextLoads() {
Course course = new Course();
course.setId(null);
course.setName("数学");
course.setStatus("3");
course.setUserId(123L);
this.courseMapper.insert(course);
}
点击运行,你会发现报了一个错误

其实报这个错的原因也很好分析,因为我数据库里有两张表,而我们只有一个实体类,造成同一个实体类无法对应两张表。因此需要添加配置
spring.main.allow-bean-definition-overriding=true。
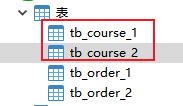
修改好配置后,继续运行。查看结果

- id为偶数的数据在表1中
- id为奇数的数据在表2中
查询
List<Course> courses = this.courseMapper.selectList(new QueryWrapper<Course>().lambda().eq(Course::getName, "数学"));
courses.forEach(course -> System.out.println(course));
结果

删除
int result = this.courseMapper.deleteById(1285130867717615617L);
结果
水平分库

create DATABASE sharding_sphere_2;
use sharding_sphere_2;
CREATE TABLE `tb_course_1` (
`id` bigint(64) NOT NULL COMMENT '课程id',
`name` varchar(50) NOT NULL COMMENT '课程名称',
`user_id` bigint(20) NOT NULL COMMENT '课程的用户id',
`status` varchar(10) NOT NULL COMMENT '状态',
`version` bigint(20) DEFAULT '0' COMMENT '版本,乐观锁',
`deleted` tinyint(1) DEFAULT '0' COMMENT '逻辑删除,1删除,0没删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
CREATE TABLE `tb_course_2` (
`id` bigint(64) NOT NULL COMMENT '课程id',
`name` varchar(50) NOT NULL COMMENT '课程名称',
`user_id` bigint(20) NOT NULL COMMENT '课程的用户id',
`status` varchar(10) NOT NULL COMMENT '状态',
`version` bigint(20) DEFAULT '0' COMMENT '版本,乐观锁',
`deleted` tinyint(1) DEFAULT '0' COMMENT '逻辑删除,1删除,0没删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
分片配置
#shardingjdbc分片策略
#配置数据源,给数据源配置名字,可配置多个,eg:ds0,ds1
spring.shardingsphere.datasource.names=ds1,ds2
#这里因为有两个数据源,需要配置两个数据源的信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/sharding_sphere_1?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=jiang
spring.shardingsphere.datasource.ds1.password=jiang
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/sharding_sphere_2?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=jiang
spring.shardingsphere.datasource.ds2.password=jiang
#指定tb_course表的分布情况,配置表在哪个数据库里面,表名称是什么。
spring.shardingsphere.sharding.tables.tb_course.actual-data-nodes=ds$->{1..2}.tb_course_$->{1..2}
#指定course表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_course.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_course.key-generator.type=SNOWFLAKE
# 指定数据库的分片策略,分库。约定id是偶数添加到ds1,奇数添加到ds2
spring.shardingsphere.sharding.tables.tb_course.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.tb_course.database-strategy.inline.algorithm-expression=ds$->{id%2+1}
# 指定表分片策略,分表,约定id值的偶数加到tb_course_1,奇数加到tb_course_2表
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.sharding-column= id
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.algorithm-expression=tb_course_$->{id%2+1}
#代开sql输出日志
spring.shardingsphere.props.sql.show=true
测试
插入
Course course = new Course();
course.setId(null);
course.setName("数学");
course.setStatus("3");
course.setUserId(123L);
this.courseMapper.insert(course);
结果

查看数据库

因为分片策略的原因,只有两个表会有数据
查询
List<Course> courses = this.courseMapper.selectList(new QueryWrapper<Course>().lambda().eq(Course::getName, "数学"));
结果

<br?
删除
int result = this.courseMapper.deleteById(1285143985013338114L);
结果

垂直分库(专库专表)
建表

CREATE TABLE `tb_user` (
`id` bigint(64) NOT NULL COMMENT '用户id',
`username` varchar(100) NOT NULL COMMENT '用户名',
`status` varchar(50) NOT NULL COMMENT '状态',
`version` bigint(20) DEFAULT '0' COMMENT '版本,乐观锁',
`deleted` tinyint(1) DEFAULT '0' COMMENT '逻辑删除,1删除,0没删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private Long id;
private String username;
private String status;
@Version
private Long version;
private Boolean deleted;
}
mapper
public interface UserMapper extends BaseMapper<User> {
}
配置
#shardingjdbc分片策略
#配置数据源,给数据源配置名字,可配置多个
spring.shardingsphere.datasource.names=ds1,ds2
#这里因为有两个数据源,需要配置两个数据源的信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/sharding_sphere_1?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=jiang
spring.shardingsphere.datasource.ds1.password=jiang
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/sharding_sphere_2?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=jiang
spring.shardingsphere.datasource.ds2.password=jiang
#指定tb_course表的分布情况,配置表在哪个数据库里面,表名称是什么。
spring.shardingsphere.sharding.tables.tb_course.actual-data-nodes=ds$->{1..2}.tb_course_$->{1..2}
#垂直分库,单库单表
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds1.tb_user
#指定course表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_course.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_course.key-generator.type=SNOWFLAKE
#指定user表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_user.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_user.key-generator.type=SNOWFLAKE
# 指定数据库的分片策略,分库。约定id是偶数添加到ds1,奇数添加到ds2
spring.shardingsphere.sharding.tables.tb_course.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.tb_course.database-strategy.inline.algorithm-expression=ds$->{id%2+1}
# 指定表分片策略,分表,约定id值的偶数加到tb_course_1,奇数加到tb_course_2表
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.sharding-column= id
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.algorithm-expression=tb_course_$->{id%2+1}
#代开sql输出日志
spring.shardingsphere.props.sql.show=true
这里和水平分库进行了一个整合
测试
插入
User user=new User();
user.setId(null);
user.setStatus("管理员");
user.setUsername("李四");
this.userMapper.insert(user);
结果
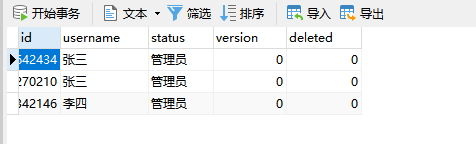
查询

删除
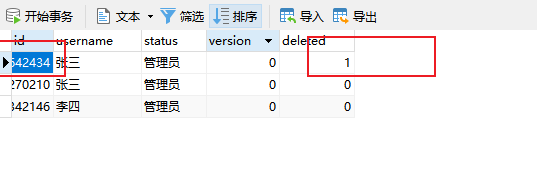
int result = this.userMapper.deleteById(1285152631994642434L);
结果
公共表
(1) 存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
(2) 在每个数据库中创建出相同结构公共表
建表
CREATE TABLE `tb_udict` (
`id` bigint(64) NOT NULL COMMENT '用户id',
`status` varchar(50) NOT NULL COMMENT '状态',
`value` varchar(100) NOT NULL COMMENT '值',
`version` bigint(20) DEFAULT '0' COMMENT '版本,乐观锁',
`deleted` tinyint(1) DEFAULT '0' COMMENT '逻辑删除,1删除,0没删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
配置文件
#shardingjdbc分片策略
#配置数据源,给数据源配置名字,可配置多个
spring.shardingsphere.datasource.names=ds1,ds2
#这里因为有两个数据源,需要配置两个数据源的信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/sharding_sphere_1?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=jiang
spring.shardingsphere.datasource.ds1.password=jiang
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/sharding_sphere_2?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=jiang
spring.shardingsphere.datasource.ds2.password=jiang
#指定tb_course表的分布情况,配置表在哪个数据库里面,表名称是什么。
spring.shardingsphere.sharding.tables.tb_course.actual-data-nodes=ds$->{1..2}.tb_course_$->{1..2}
#垂直分库,单库单表
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ds1.tb_user
#指定course表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_course.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_course.key-generator.type=SNOWFLAKE
#指定user表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_user.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_user.key-generator.type=SNOWFLAKE
#配置公共表
spring.shardingsphere.sharding.binding-tables=tb_udict
spring.shardingsphere.sharding.tables.tb_udict.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_udict.key-generator.type=SNOWFLAKE
# 指定数据库的分片策略,分库。约定id是偶数添加到ds1,奇数添加到ds2
spring.shardingsphere.sharding.tables.tb_course.database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.tb_course.database-strategy.inline.algorithm-expression=ds$->{id%2+1}
# 指定表分片策略,分表,约定id值的偶数加到tb_course_1,奇数加到tb_course_2表
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.sharding-column= id
spring.shardingsphere.sharding.tables.tb_course.table-strategy.inline.algorithm-expression=tb_course_$->{id%2+1}
#代开sql输出日志
spring.shardingsphere.props.sql.show=true
测试
插入
Udict udict=new Udict();
udict.setId(null);
udict.setStatus("1");
udict.setValue("普通用户");
this.udictMapper.insert(udict);
结果
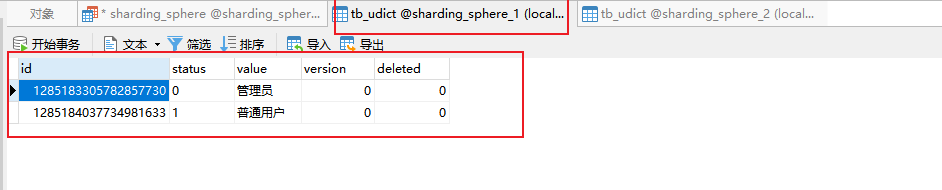
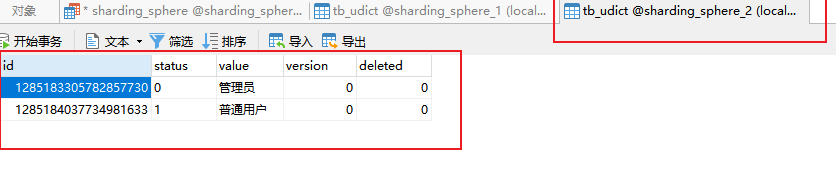
查询
List<Udict> udicts = this.udictMapper.selectList(new QueryWrapper<Udict>().lambda().eq(Udict::getStatus, "1"));
udicts.forEach(udict -> System.out.println(udict));
结果

查询到了两条数据
删除
int result = this.udictMapper.deleteById(1285184037734981633L);
结果

两个表的数据都进行了删除
读写分离
读写分离基本概念
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器;第二台数据库服务器,主要进行读的操作。原理:让主数据库( master )处理事务性增、改、删操作,而从数据库( slave )处理SELECT查询操作。

原理
主从复制:当主服务器有写入(增删改)语句的时候,从服务器自动获取。
读写分离:增删改语句操作一台服务器,查询语句操作另一台服务器

Sharding-JDBC 通过 sql 语句语义分析,实现读写分离过程,不会做数据同步。它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。

操作
启动两台服务器
-
复制之前的mysql文件夹

- 修改复制之后mysql配置文件

- 修改端口

- 修改文件的路径(安装和数据目录)
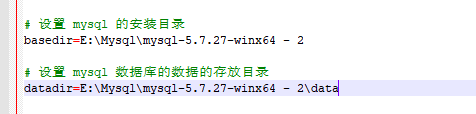
- 在win上面安装服务
mysqld install mysqls1 --defaults-file="E:\Mysql\mysql-5.7.27-winx64 - 2\my.ini"
#如果想删除服务的话,执行
sc delete 服务名称

注意以管理员的身份运行
- 启动服务

配置mysql中的主从复制
- 在主服务器配置文件(my.ini)中配置
- 在最下方增加配置
#开启日志
log-bin = mysql-bin
#设置服务id,主从不能一致
server-id = 1
#设置需要同步的数据库
binlog-do-db=user_db
#屏蔽系统库同步
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
- 在从服务器配置文件(my.ini)中配置
- 在最下方增加配置
#开启日志
log-bin = mysql-bin
#设置服务id,主从不能一致
server-id = 2
#设置需要同步的数据库
replicate_wild_do_table=sharding_sphere.%
#屏蔽系统库同步
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=performance_schema.%
- 重启两台服务器的服务

创建用于主从服务的账号
#切换至主库bin目录,登录主库
mysql ‐h localhost ‐u root ‐p
#授权主备复制专用账号
GRANT REPLICATION SLAVE ON *.* TO 'db_sync'@'%' IDENTIFIED BY 'db_sync';
#刷新权限
FLUSH PRIVILEGES;
#确认位点 记录下文件名以及位点
show master status;

设置从库向主库同步数据、并检查连接
#切换至从库bin目录,登录从库
mysql ‐h localhost ‐P 3307 ‐u root ‐p
#先停止同步
STOP SLAVE;
#修改从库指向到主库,使用上一步记录的文件名以及位点
CHANGE MASTER TO
master_host = 'localhost',
master_user = 'db_sync',
master_password = 'db_sync',
master_log_file = 'mysql‐bin.000034',
master_log_pos = 154;
#启动同步
#查看从库状态Slave_IO_Runing和Slave_SQL_Runing都为Yes说明同步成功,如果不为Yes,请检查error_log,然后排查相关异常。
show slave status\G
#注意 如果之前此备库已有主库指向 需要先执行以下命令清空
STOP SLAVE IO_THREAD FOR CHANNEL '';
reset slave all;
- master_log_file = ‘mysql‐bin.000034’, 是上方截图的File
- master_log_pos = 154;是上方截图的Position
- show slave status\G查看是否是yes

配置文件
#shardingjdbc分片策略
#配置数据源,给数据源配置名字,可配置多个
spring.shardingsphere.datasource.names=ds1,ds2,ds0,s0
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/sharding_sphere?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds0.username=jiang
spring.shardingsphere.datasource.ds0.password=jiang
#ds2数据源的从服务器
spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource
#spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.s0.url=jdbc:mysql://localhost:3307/sharding_sphere?characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.s0.username=root
spring.shardingsphere.datasource.s0.password=jcl5412415845
# 主库从库逻辑数据源定义 (设置主服务器和从服务器,并起名)
spring.shardingsphere.sharding.master‐slave‐rules.ms0.master-data-source-name=ds0
spring.shardingsphere.sharding.master‐slave‐rules.ms0.slave-data-source-names=s0
spring.shardingsphere.sharding.tables.tb_user.actual-data-nodes=ms0.tb_user
#指定user表里面主键id生成策略 雪花算法
spring.shardingsphere.sharding.tables.tb_user.key-generator.column=id
spring.shardingsphere.sharding.tables.tb_user.key-generator.type=SNOWFLAKE
只显示了主要配置















 2290
2290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









