







文章目录
Helm和相关组件
Helm
Helm 官方文档:https://helm.sh/zh/docs/
概述
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂,helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理。
Helm 本质就是让 K8s 的应用管理(Deployment,Service 等 ) 可配置,能动态生成。通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署。
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。Helm 有两个重要的概念:chart 和 release:
- chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包;
- release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release
Helm 包含两个组件:Helm 客户端和 Tiller 服务器,如下图所示:
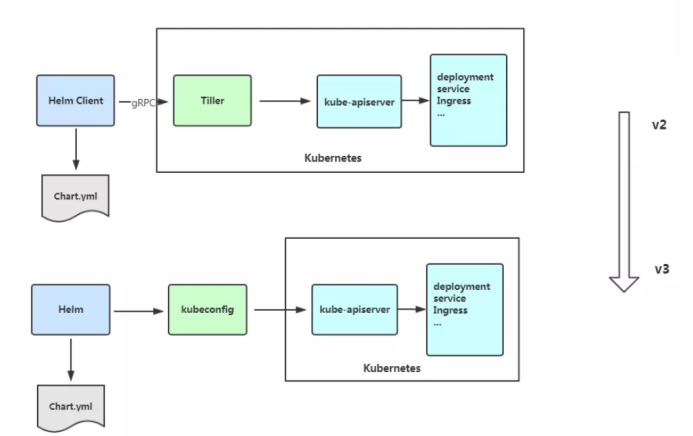
helm:客户端,管理本地chart仓库,管理Chart,与tiller服务器交互,实例查询安装卸载等操作。tiller:服务端,作为pod运行在集群中,接受helm发来的charts与config合并生成release。
Kubernetes 1.6 中开启了 RBAC ,权限控制变得简单了。Helm 也不必与 Kubernetes 做重复的事情,因此 Helm 3 彻底移除了 Tiller 。 移除 Tiller 之后,Helm 的安全模型也变得简单(使用 RBAC 来控制生产环境 Tiller 的权限非常不易于管理)。Helm 3 使用 kubeconfig 鉴权。集群管理员针对应用,可以设置任何所需级别的权限控制,而其他功能保持不变。
部署
越来越多的公司和团队开始使用 Helm 这个 Kubernetes 的包管理器,我们也将使用 Helm 安装 Kubernetes 的常用组件。 Helm 的安装十分简单。 下载 helm 命令行工具到 master 节点的 /usr/local/bin 下,我使用的是 Centos7,这里下载的是 3.4.1 版本:
# 如无需更换版本,直接执行下载
wget https://get.helm.sh/helm-v3.2.4-linux-amd64.tar.gz
# 解压
tar -zxvf helm-v3.2.4-linux-amd64.tar.gz
# 进入到解压后的目录
cd linux-amd64/
cp helm /usr/local/bin/
# 赋予权限
chmod a+x /usr/local/bin/helm
# 查看版本
helm version
其它版本请或者其它系统请移步官网:https://helm.sh/zh/docs/intro/install/
下载和运行应用
-
访问
Helm仓库:https://artifacthub.io/ -
搜索需要的包
-
按照
install步骤操作即可:
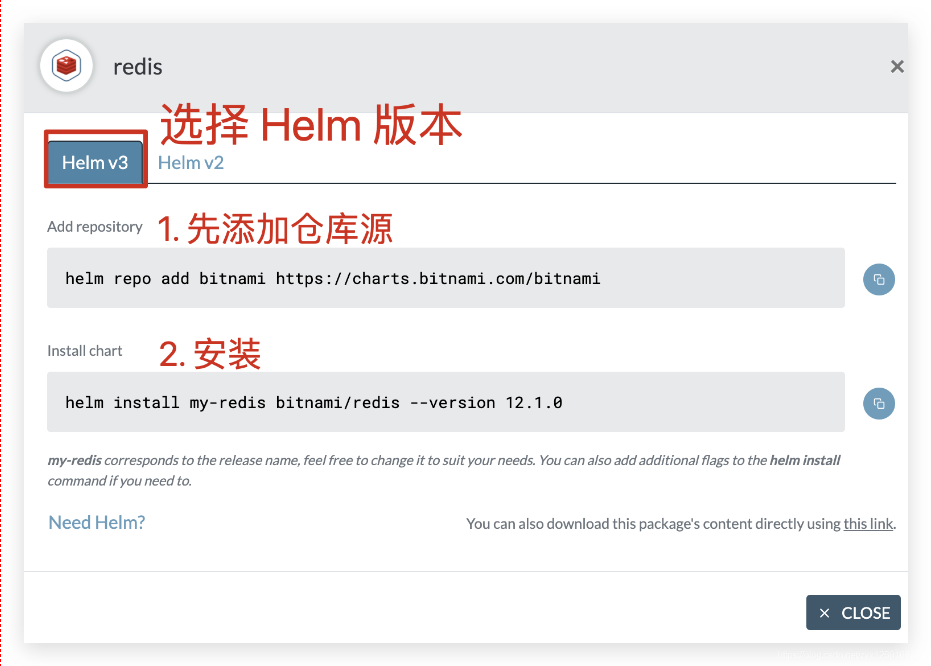
操作命令
-
拉取chart:
helm pull [chart URL | repo/chartname] [...] [flags]pull下来是一个tgz压缩包。
-
安装chart:
helm install [NAME] [CHART] [flags]常用参数:
-f, --values:指定values.yaml文件--set:在命令行中直接设置values的值--dry-run:模拟执行,测试能不能创建,但不创建--debug:允许冗长的输出(输出多余信息)
-
查看信息:
# 查看 releases 列表 $ helm list $ helm ls NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION hello-world default 1 2020-11-18 09:24:37.117596257 +0800 CST deployed hello-world-1.0.0 # 查看 release 状态 $ helm status hello-world -
更新:
helm upgrade [RELEASE] [CHART] [flags]$ helm upgrade hello-world . Release "hello-world" has been upgraded. Happy Helming! NAME: hello-world LAST DEPLOYED: Wed Nov 18 06:03:00 2020 NAMESPACE: default STATUS: deployed REVISION: 2 TEST SUITE: None -
历史版本:
# 查看 releases 历史信息 # helm history RELEASE_NAME [flags] $ helm history hello-world REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION 1 Wed Nov 18 05:40:09 2020 superseded hello-world-1.0.0 Install complete 2 Wed Nov 18 06:03:00 2020 deployed hello-world-1.0.0 Upgrade complete # helm rollback <RELEASE> [REVISION] [flags] $ helm rollback hello-world 1 Rollback was a success! Happy Helming! -
删除:
# helm delete RELEASE_NAME [...] [flags] $ helm delete hello-world release "hello-world" uninstalled
chart结构
chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包。
一个chart可以包含以下文件和目录:
Chart.yaml # 包含了chart信息的YAML文件
LICENSE # 可选: 包含chart许可证的纯文本文件
README.md # 可选: 可读的README文件
values.yaml # chart 默认的配置值
values.schema.json # 可选: 一个使用JSON结构的values.yaml文件
charts/ # 包含chart依赖的其他chart
crds/ # 自定义资源的定义
templates/ # 模板目录, 当和values 结合时,可生成有效的Kubernetes manifest文件
templates/NOTES.txt # 可选: 包含简要使用说明的纯文本文件
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl # 用于保存一些可以在该chart中复用的模板。
│ ├── deployment.yaml
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── tests
│ └── test-connection.yaml
最重要的就是Chart.yaml、values.yaml文件以及templates文件夹。
templates/目录下是模板文件,当Helm需要运行chart时,会渲染该目录下的模板文件,将渲染结果发送给kubernetes。values.yaml文件保存模板的默认值,用户可以在helm install或者helm upgrade可以指定新的值来覆盖默认值。Chart.yaml文件保存chart的基本描述信息,这些描述信息也可以在模板中被引用。
(1)Chart.yaml结构
Chart.yaml 文件是 chart 必需的。包含了以下字段:
apiVersion: chart API 版本 (必需)
name: chart名称 (必需)
version: 版本(必需)
kubeVersion: 兼容Kubernetes版本的语义化版本(可选)
description: 一句话对这个项目的描述(可选)
type: chart类型 (可选)
keywords:
- 关于项目的一组关键字(可选)
home: 项目home页面的URL (可选)
sources:
- 项目源码的URL列表(可选)
dependencies: # chart 必要条件列表 (可选)
- name: chart名称 (nginx)
version: chart版本 ("1.2.3")
repository: 仓库URL ("https://example.com/charts") 或别名 ("@repo-name")
condition: (可选) 解析为布尔值的yaml路径,用于启用/禁用chart (e.g. subchart1.enabled )
tags: # (可选)
- 用于一次启用/禁用 一组chart的tag
enabled: (可选) 决定是否加载chart的布尔值
import-values: # (可选)
- ImportValue 保存源值到导入父键的映射。每项可以是字符串或者一对子/父列表项
alias: (可选) chart中使用的别名。当你要多次添加相同的chart时会很有用
maintainers: # (可选)
- name: 维护者名字 (每个维护者都需要)
email: 维护者邮箱 (每个维护者可选)
url: 维护者URL (每个维护者可选)
icon: 用做icon的SVG或PNG图片URL (可选)
appVersion: 包含的应用版本(可选)。不需要是语义化的
deprecated: 不被推荐的chart (可选,布尔值)
annotations:
example: 按名称输入的批注列表 (可选).
apiVersion:在 Helm3 中,apiVersion=v2;在 Helm3 之前的版本,apiVersion=v1
(2) values.yaml
image:
repository: wangyanglinux/myapp
tag: 'v1'
这个随便举一个例子,values.yaml就相当于这个chart的配置文件,其值会生成一个Values对象,在templates文件夹下的文件中使用,以达到动态生成资源清单。
内置对象
| 对象.属性 | 说明 |
|---|---|
| Values | 通过values.yaml文件创建的一个对象 |
| Release.Name | 版本名称(非chart的) |
| Release.Namespace | 发布的chart版本的命名空间 |
| Release.Service | 组织版本的服务 |
| Release.IsUpgrade | 如果当前操作是升级或回滚,设置为true |
| Release.IsInstall | 如果当前操作是安装,设置为true |
| Chart | Chart.yaml的内容。因此,chart的版本可以从 Chart.Version 获得, 并且维护者在Chart.Maintainers里。 |
Values 对象是为 Chart 模板提供值,这个对象的值有4个来源,后面的可以覆盖前面的:
- chart 包中的 values.yaml 文件;
- 父 chart 包的 values.yaml 文件;
- 通过 helm install 或者 helm upgrade 的 -f 或者 --values 参数传入的自定义的 yaml 文件;
- 通过 --set 参数传入的值
在模板文件中,通过 {{.Values}} 对象来访问设置的值。
(1)定义一个 values.yaml:
image:
repository: wangyanglinux/myapp
tag: 'v1'
(2)在模板文件中就可以通过 {{.Values}} 对象访问到:
apiVersion: v1
kind: Pod
metadata:
name: test
spec:
template:
spec:
containers:
- name: nginx
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
ports:
- containerPort: 80
protocol: TCP
自建一个chart
常见一个chart,主要就是常见Chart.yaml、values.yaml文件,以及templates文件夹下的模板。
(1)创建文件夹
# 创建文件夹
$ mkdir ./hello-world
$ cd ./hello-world
(2)创建Chart.yaml
创建一个 hello-world 的 Chart.yaml,这里只写了必需的字段:
$ cat <<'EOF' > ./Chart.yaml
apiVersion: v2
name: hello-world
version: 1.0.0
EOF
(3)创建values.yaml
文件名如果不是 values.yaml,则需要在 helm install 时,通过 -f 指定 yaml 文件的位置
$ cat <<'EOF' > ./values.yaml
image:
repository: wangyanglinux/myapp
tag: 'v1'
EOF
(4)创建模板文件(templates)
模板文件, 用于生成 Kubernetes 资源清单(manifests)
注意:模板文件所有的目录必须是 templates
$ mkdir ./templates
cat <<'EOF' > ./templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: hello-world
spec:
replicas: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}
ports:
- containerPort: 80
protocol: TCP
EOF
$ cat <<'EOF' > ./templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
app: hello-world
EOF
(5)install创建一个Release
使用命令 helm install RELATIVE_PATH_TO_CHART 创建一次 Release
$ helm install hello-world .
NAME: hello-world
LAST DEPLOYED: Wed Nov 18 05:40:09 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
Dashboard
Dashboard:提供一种B/S GUI的方式对集群资源进行管理,可以获取运行在集群中的应用的信息,也可以创建或者修改 Kubernetes 资源 (如 Deployment,Job,DaemonSet 等等)
安装
仓库地址:https://artifacthub.io/packages/helm/k8s-dashboard/kubernetes-dashboard
(1)添加仓库
helm repo add k8s-dashboard https://kubernetes.github.io/dashboard
(2)下载Chart
helm pull kubernetes-dashboard/kubernetes-dashboard
# 解压
tar -zxvf kubernetes-dashboard-2.8.3.tgz
(3)创建kubenetes-dashboard.yaml
image:
repository: kubernetesui/dashboard
tag: v2.0.4
ingress:
enabled: true
hosts:
- k8s.frognew.com
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
tls:
- secretName: frognew-com-tls-secret
hosts:
- k8s.frognew.com
rbac:
clusterAdminRole: true
(4)安装
helm install kubernetes-dashboard . \
--namespace kube-system \
-f kubernetes-dashboard.yaml
(5)更改SVC类型
$ kubectl edit svc kubernetes-dashboard -n kube-system
将 spec.type 的值修改为 NodePort
# 查看端口(端口为:30354)
$ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.111.147.196 <none> 443:30354/TCP 51m
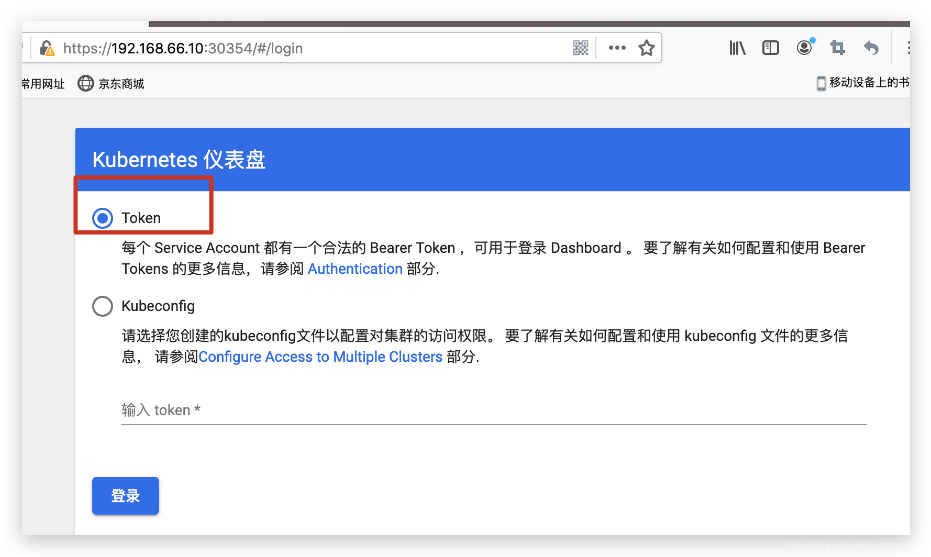
(6)访问
浏览器访问地址:https://192.168.66.10:30354/:
查看 kubernetes-dashboard-token 的名字:
$ kubectl get secret -n kube-system | grep kubernetes-dashboard-token
kubernetes-dashboard-token-9kvm2 kubernetes.io/service-account-token 3 77m
查看该 Secret 中的 Token:
kubectl describe secret kubernetes-dashboard-token-9kvm2 -n kube-system
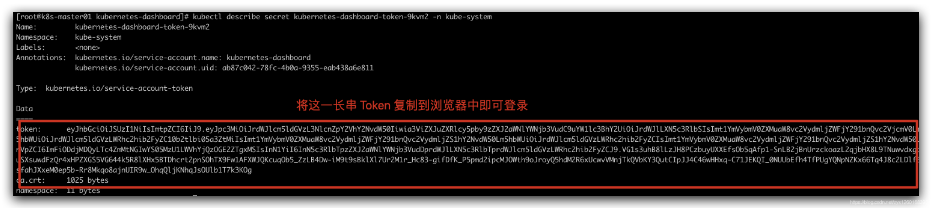
将 Token 复制到浏览器中,即可登录成功。
赋权和访问
登录成功后,进去界面,发现什么资源都显示不了,是因为 dashboard 默认的 serviceaccount 并没有权限,所以我们需要给予它授权。
创建 dashboard-admin.yaml ,内容如下
注意:这里直接赋予了 cluster-admin 权限,也就是集群所有的权限
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
namespace: kube-system
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
应用资源文件 dashboard-admin.yaml:
kubectl apply -f dashboard-admin.yaml
授权成功,可以通过 dashboard 查看到资源:
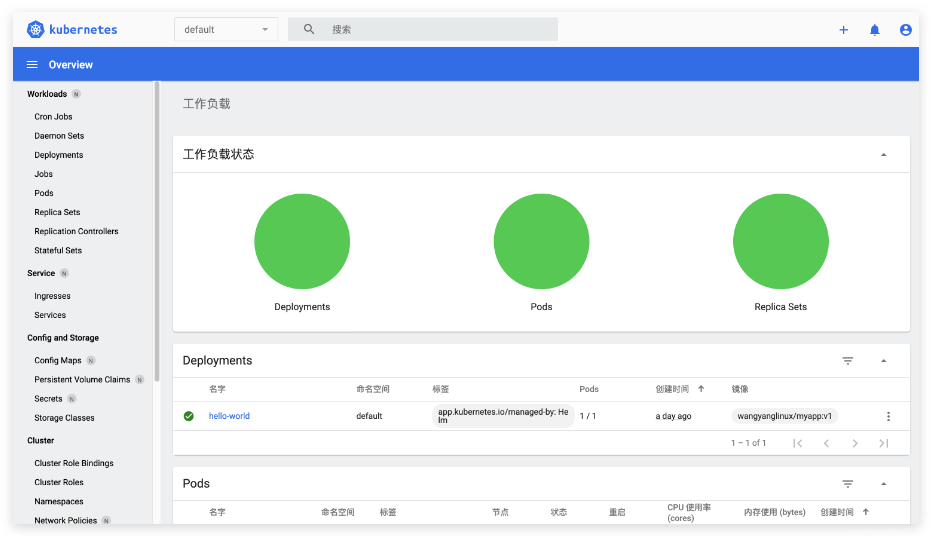
也可以进行Pod的创建:
点击创建部署新应用:
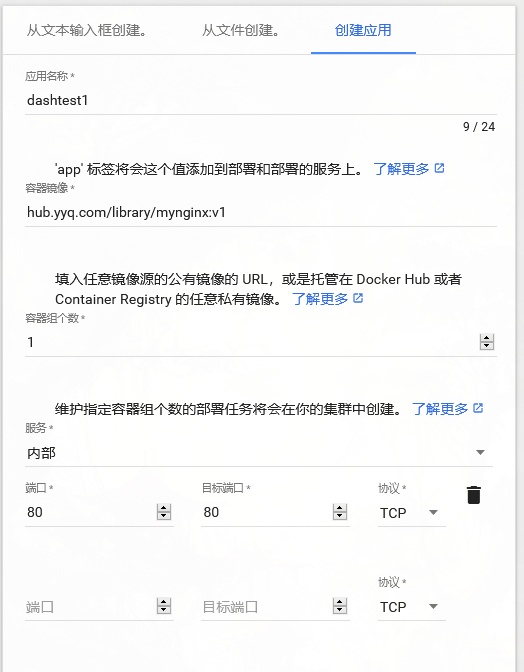
点击部署:
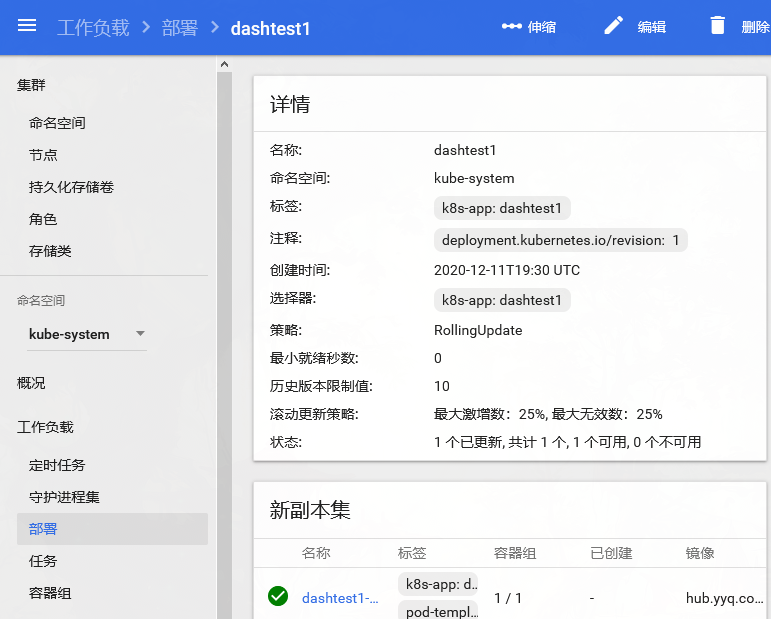
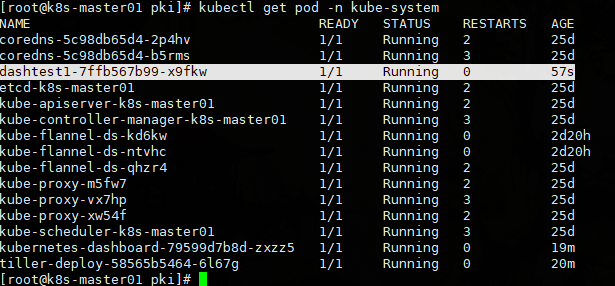
kubectl get pod -n kube-system
Prometheus
Prometheus:不仅是一款时间序列数据库,在整个生态上还是一套完整的监控系统,可以用作对k8s的资源进行监控。
特点:
- 通过PromQL实现多维度数据模型的灵活查询。
- 定义了开放指标数据的标准,自定义探针(如Exporter等),编写简单方便。
- PushGateway组件让这款监控系统可以接收监控数据。
- 提供了VM和容器化的版本。
尤其是第一点,这是很多监控系统望尘莫及的。多维度的数据模型和灵活的查询方式,使监控指标可以关联到多个标签,并对时间序列进行切片和切块,以支持各种图形、表格和告警场景。
Prometheus github 地址:https://github.com/coreos/kube-prometheus
架构
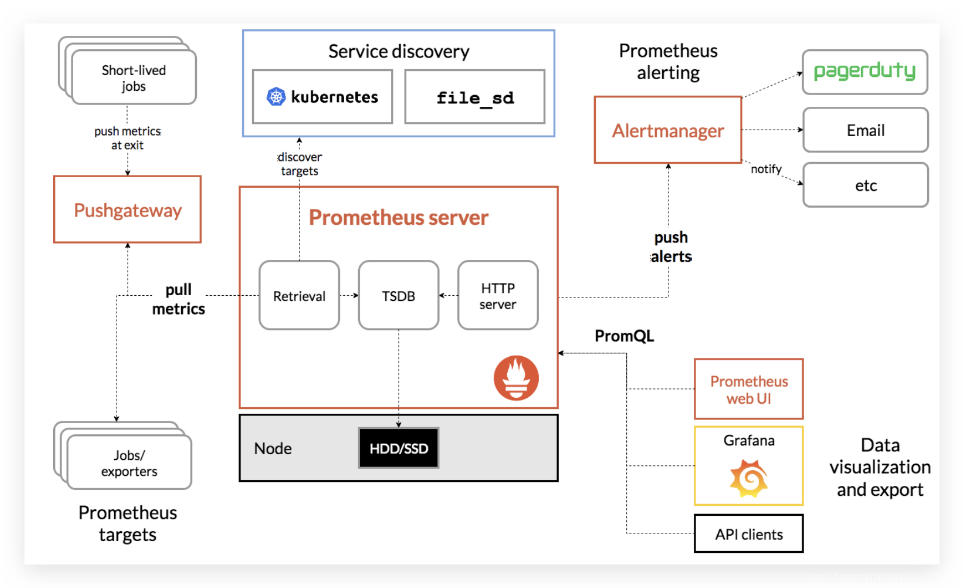
Prometheus主要由Prometheus Server、Pushgateway、Job/Exporter、Service Discovery、Alertmanager、Dashboard这6个核心模块构成。
Prometheus通过Service Discovery(服务发现机制)发现target,这些目标可以是长时间执行的Job,也可以是短时间执行的Job,还可以是通过Exporter监控的第三方应用程序。被抓取的数据会存储起来,通过PromQL语句在dashboard等可视化系统中供查询,或者向Alertmanager发送告警信息,告警会通过页面、电子邮件、钉钉信息或者其他形式呈现。
从上述架构图中可以看到,Prometheus不仅是一款时间序列数据库,在整个生态上还是一套完整的监控系统。对于时间序列数据库,在进行技术选型的时候,往往需要从宽列模型存储、类SQL查询支持、水平扩容、读写分离、高性能等角度进行分析。而监控系统的架构,往往还需要考虑通过减少组件、服务来降低成本和复杂性以及水平扩容等因素。
监控系统使用MQ通信的问题
很多企业自己研发的监控系统中往往会使用消息队列Kafka和Metrics parser、Metrics process server等Metrics解析处理模块,再辅以Spark等流式处理方式。应用程序将Metric推到消息队列(如Kafaka),然后经过Exposer中转,再被Prometheus拉取。之所以会产生这种方案,是因为考虑到有历史包袱、复用现有组件、通过MQ(消息队列)来提高扩展性等因素。这个方案会有如下几个问题。
- 增加了查询组件,比如基础的sum、count、average函数都需要额外进行计算。这一方面多了一层依赖,在查询模块连接失败的情况下会多提供一层故障风险;另一方面,很多基本的查询功能的实现都需要消耗资源。而在Prometheus的架构里,上述这些功能都是得到支持的。
- 抓取时间可能会不同步,延迟的数据将会被标记为陈旧数据。如果通过添加时间戳来标识数据,就会失去对陈旧数据的处理逻辑。
- Prometheus适用于监控大量小目标的场景,而不是监控一个大目标,如果将所有数据都放在Exposer中,那么Prometheus的单个Job拉取就会成为CPU的瓶颈。这个架构设计和Pushgateway类似,因此如果不是特别必要的场景,官方都不建议使用。
- 缺少服务发现和拉取控制机制,Prometheus只能识别Exposer模块,不知道具体是哪些target,也不知道每个target的UP时间,所以无法使用Scrape_*等指标做查询,也无法用scrape_limit做限制。
对于上述这些重度依赖,可以考虑将其优化掉,而Prometheus这种采用以拉模式为主的架构,在这方面的实现是一个很好的参考方向。同理,很多企业的监控系统对于cmdb具有强依赖,通过Prometheus这种架构也可以消除标签对cmdb的依赖。
组件介绍
Job/Exporter
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。因此Promethenux是一种以拉为主的监控系统。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
Pushgateway
Prometheus是拉模式为主的监控系统,它的推模式就是通过Pushgateway组件实现的。Pushgateway是支持临时性Job主动推送指标的中间网关,它本质上是一种用于监控Prometheus服务器无法抓取的资源的解决方案。它也是用Go语言编写的,在Apache 2.0许可证下开源。
Pushgateway作为一个独立的服务,位于被采集监控指标的应用程序和Prometheus服务器之间。应用程序主动推送指标到Pushgateway,Pushgateway接收指标,然后Pushgateway也作为target被Prometheus服务器抓取。它的使用场景主要有如下几种:
- 临时/短作业。
- 批处理作业。
- 应用程序与Prometheus服务器之间有网络隔离,如安全性(防火墙)、连接性(不在一个网段,服务器或应用程序仅允许特定端口或路径访问)。
Pushgateway与网关类似,在Prometheus中被建议作为临时性解决方案,主要用于监控不太方便访问到的资源。它会丢失很多Prometheus服务器提供的功能,比如UP指标和指标过期时进行实例状态监控。
Service Discovery
Prometheus通过服务发现机制对云以及容器环境下的监控场景提供了完善的支持。
服务发现方式:
-
配置文件:
Prometheus会周期性地从文件中读取最新的target信息。
对于支持文件的服务发现,实践场景下可以衍生为与自动化配置管理工具(Ansible、Cron Job、Puppet、SaltStack等)结合使用。
-
通过服务动态感知:
Prometheus还支持多种常见的服务发现组件,如Kubernetes、DNS、Zookeeper、Azure、EC2和GCE等。例如,Prometheus可以使用Kubernetes的API获取容器信息的变化(如容器的创建和删除)来动态更新监控对象。
通过服务发现的方式,管理员可以在不重启Prometheus服务的情况下动态发现需要监控的target实例信息。
Prometheus Server
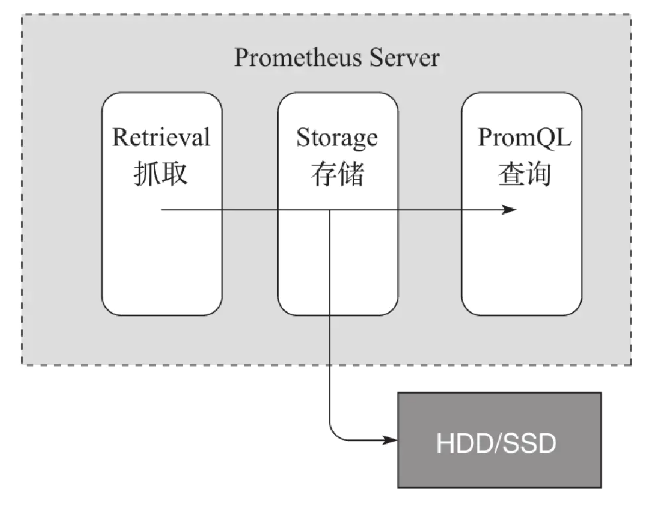
Prometheus服务器是Prometheus最核心的模块。它主要包含抓取、存储和查询这3个功能:
(1)抓取:Prometheus Server通过服务发现组件,周期性地从上面介绍的Job、Exporter、Pushgateway这3个组件中通过HTTP轮询的形式拉取监控指标数据;
(2)存储:抓取到的监控数据通过一定的规则清理和数据整理(抓取前使用服务发现提供的relabel_configs方法,抓取后使用作业内的metrics_relabel_configs方法),把得到的结果存储到新的时间序列中进行持久化。多年来,存储模块经历了多次重新设计,Prometheus 2.0版的存储系统是第三次迭代。该存储系统每秒可以处理数百万个样品的摄入,使得使用一台Prometheus服务器监控数千台机器成为可能。使用的压缩算法可以在真实数据上实现每个样本1.3B。建议使用SSD,但不是严格要求。
Prometheus的存储分为本地存储和远程存储
- 本地存储:会直接保留到本地磁盘,性能上建议使用SSD且不要保存超过一个月的数据。记住,任何版本的Prometheus都不支持NFS。一些实际生产案例告诉我们,Prometheus存储文件如果使用NFS,则有损坏或丢失历史数据的可能。
- 远程存储:适用于存储大量的监控数据。Prometheus支持的远程存储包括OpenTSDB、InfluxDB、Elasticsearch、Graphite、CrateDB、Kakfa、PostgreSQL、TimescaleDB、TiKV等。远程存储需要配合中间层的适配器进行转换,主要涉及Prometheus中的remote_write和remote_read接口。在实际生产中,远程存储会出现各种各样的问题,需要不断地进行优化、压测、架构改造甚至重写上传数据逻辑的模块等工作。
(3)查询:Prometheus持久化数据以后,客户端就可以通过PromQL语句对数据进行查询了。
Dashboard
在Prometheus架构图中提到,Web UI、Grafana、API client可以统一理解为Prometheus的Dashboard。Prometheus服务器除了内置查询语言PromQL以外,还支持表达式浏览器及表达式浏览器上的数据图形界面。实际工作中使用Grafana等作为前端展示界面,用户也可以直接使用Client向Prometheus Server发送请求以获取数据。
Alertmanager
Alertmanager是独立于Prometheus的一个告警组件,需要单独安装部署。Prometheus可以将多个Alertmanager配置为一个集群,通过服务发现动态发现告警集群中节点的上下线从而避免单点问题,Alertmanager也支持集群内多个实例之间的通信。
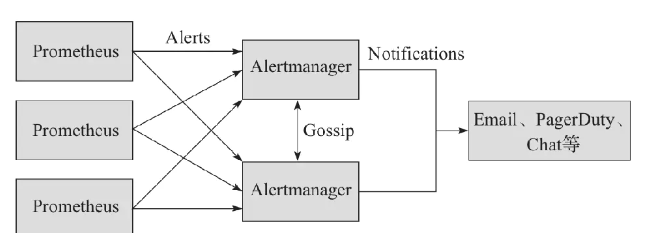
Alertmanager接收Prometheus推送过来的告警,用于管理、整合和分发告警到不同的目的地。Alertmanager提供了多种内置的第三方告警通知方式,同时还提供了对Webhook通知的支持,通过Webhook用户可以完成对告警的更多个性化的扩展。Alertmanager除了提供基本的告警通知能力以外,还提供了如分组、抑制以及静默等告警特性。
Prometheus的3大局限性
Prometheus固然强大,但它还是具有一定局限性的。
- 更多地展示的是趋势性的监控。Prometheus作为一个基于度量的系统,不适合存储事件或者日志等,它更多地展示的是趋势性的监控。如果用户需要数据的精准性,可以考虑ELK或其他日志架构。另外,APM更适用于链路追踪的场景;
- Prometheus本地存储不适合大量历史数据存储。Prometheus认为只有最近的监控数据才有查询的需要,所有Prometheus本地存储的设计初衷只是保存短期(如一个月)的数据,不会针对大量的历史数据进行存储。如果需要历史数据,则建议使用Prometheus的远端存储,如OpenTSDB、M3DB等;
- 成熟度没有InfluxDB高。Prometheus在集群上不论是采用联邦集群还是采用Improbable开源的Thanos等方案,都没有InfluxDB成熟度高,需要解决很多细节上的技术问题(如耗尽CPU、消耗机器资源等问题),这也是开头提到的InfluxDB在时序数据库中排名第一的原因之一。部分互联网公司拥有海量业务,出于集群的原因会考虑对单机免费但是集群收费的InfluxDB进行自主研发。
总之,使用Prometheus一定要了解它的设计理念:它并不是为了解决大容量存储问题,TB级以上数据建议保存到远端TSDB中;它是为运行时正确的监控数据准备的,无法做到100%精准,存在由内核故障、刮擦故障等因素造成的微小误差。
安装
(1)安装 kube-prometheus:
这里要注意一下版本兼容问题,在官网下载对应的版本即可
| kube-prometheus stack | Kubernetes 1.16 | Kubernetes 1.17 | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 |
|---|---|---|---|---|---|
| release-0.4 | ✔ (v1.16.5+) | ✔ | ✗ | ✗ | ✗ |
| release-0.5 | ✗ | ✗ | ✔ | ✗ | ✗ |
| release-0.6 | ✗ | ✗ | ✔ | ✔ | ✗ |
| release-0.7 | ✗ | ✗ | ✗ | ✔ | ✔ |
| HEAD | ✗ | ✗ | ✗ | ✔ | ✔ |
# 克隆相应的分支
git clone -b release-0.3 https://github.com/coreos/kube-prometheus.git
cd kube-prometheus/manifest
(2)修改 grafana-service.yaml:
$ vim grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
spec:
type: NodePort # 添加内容
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 #添加内容
selector:
app: grafana
(3)修改 prometheus-service.yaml:
$ vim prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort # 添加
ports:
- name: web
port: 9090
targetPort: web
nodePort: 30200 # 添加
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
(4)安装
# 在 kube-prometheus/manifests 目录下执行
# 创建名称空间,prometheus 组件都在这个名称空间下
kubectl create namespace monitoring
# 这两个目录下的 yaml 都要创建
kubectl apply -f ./setup
kubectl apply -f .
如果报了下面的错:
unable to recognize "../manifests/alertmanager-alertmanager.yaml": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/alertmanager-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/grafana-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
...
就多执行几遍下面的命令(每次执行前要确保上次执行的 pod 已经 Running):
kubectl apply -f ./setup
kubectl apply -f .
(5)kubectl top 命令查看集群资源
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 93m 4% 1183Mi 62%
k8s-node01 72m 3% 1116Mi 58%
k8s-node02 78m 3% 1151Mi 60%
$ kubectl top pod -n monitoring
NAME CPU(cores) MEMORY(bytes)
alertmanager-main-0 2m 21Mi
alertmanager-main-1 2m 22Mi
访问 prometheus
查看 service:
$ kubectl get svc -o wide -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
alertmanager-main NodePort 10.97.154.146 <none> 9093:30300/TCP 98m alertmanager=main,app=alertmanager
grafana NodePort 10.104.110.200 <none> 3000:30100/TCP 98m app=grafana
prometheus-k8s NodePort 10.104.85.240 <none> 9090:30200/TCP 98m app=prometheus,prometheus=k8s
根据前面安装时候的配置,prometheus 对应的 nodeport 端口为 30200,访问 http://MasterIP:30200。
查看 prometheus 的节点状态:
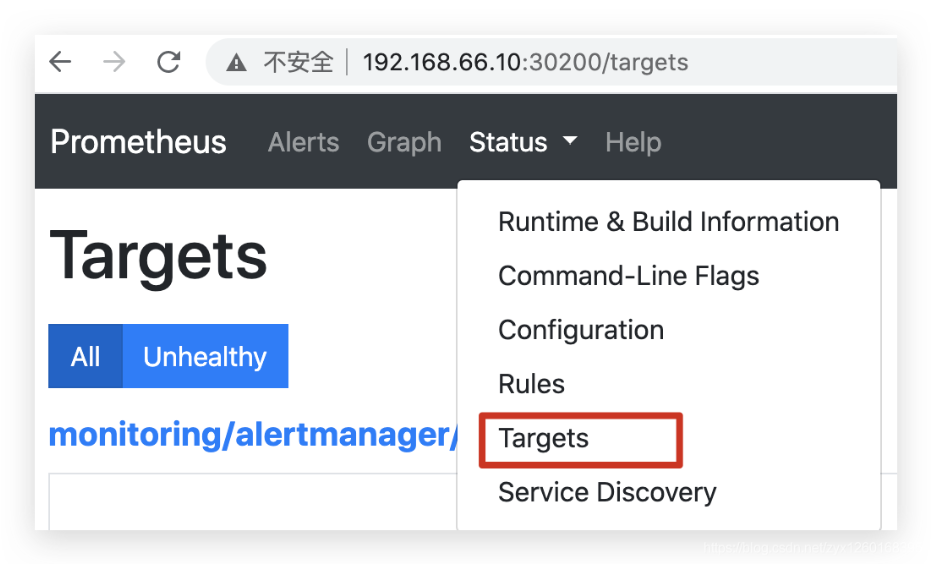
prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 Pod 的 CPU 使用情况,查询条件如下:
sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) )
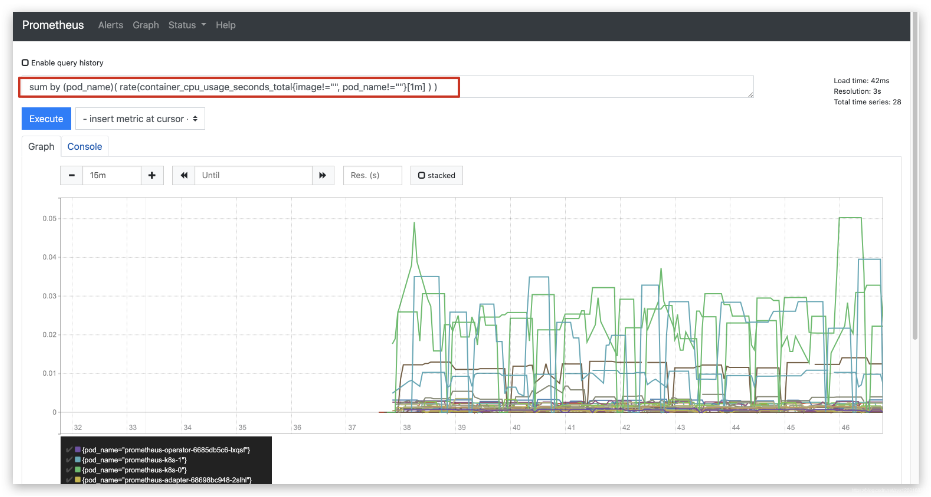
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常,接下来我们就可以部署 grafana 组件,实现更友好的 webui 展示数据了
注意:prometheus 对系统时间的要求比较高,要确保 k8s 每个节点的时间都同步。通过阿里云服务器同步中国上海时间:ntpdate ntp1.aliyun.com
访问 grafana
查看 grafana 服务暴露的端口号:
$ kubectl get service -n monitoring | grep grafana
grafana NodePort 10.98.154.100 <none> 3000:30100/TCP 11h
如上可以看到 grafana 的端口号是 30100,浏览器访问:http://MasterIP:30100,用户名密码默认 admin/admin,第一次登录后会要求修改密码。

添加数据源:
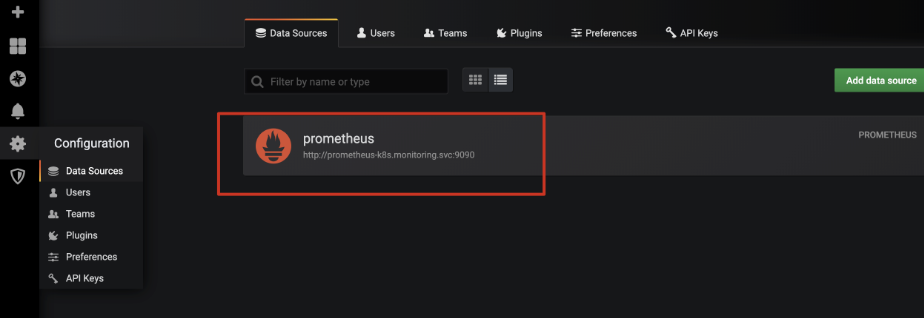
查看apiserver:
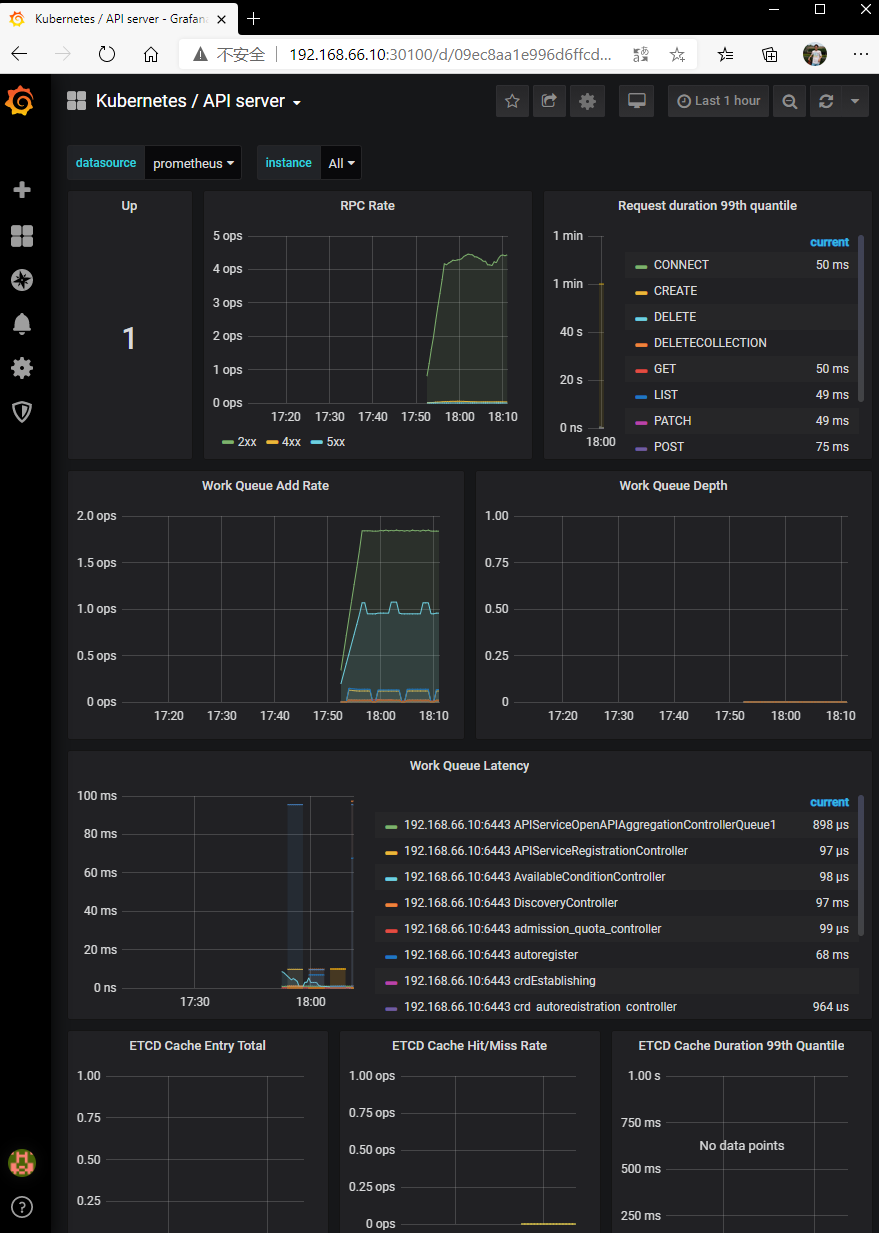
也可以查看其它资源:
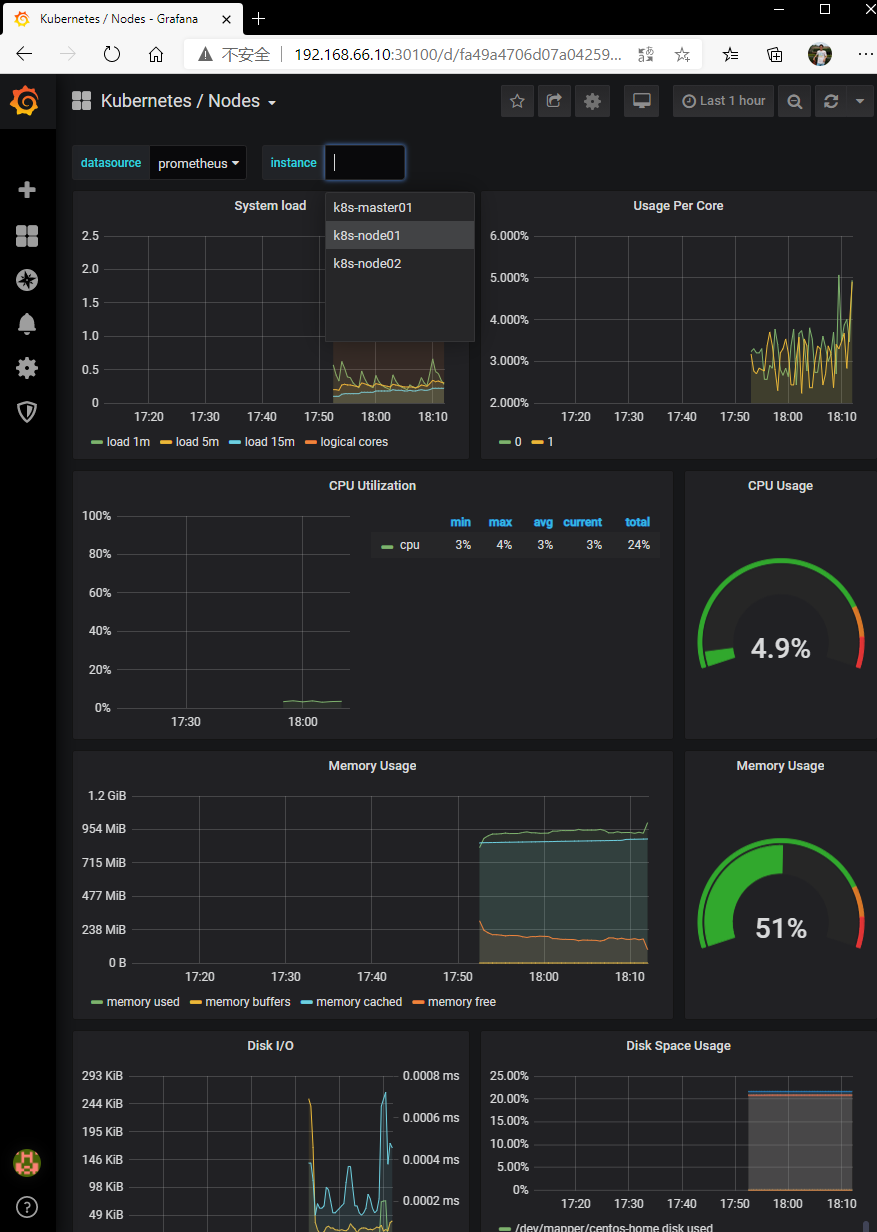
这里选择 Nodes:
Horizontal Pod Autoscaling(HPA)创建
HPA 的全称为(Horizontal Pod Autoscaling)它可以根据当前 pod 资源的使用率(如 CPU、磁盘、内存等),进行副本数的动态的扩容与缩容,以便减轻各个 pod 的压力,可以用于Replication Controller、Deployment 或者Replica Set。当 pod 负载达到一定的阈值后,会根据扩缩容的策略生成更多新的 pod 来分担压力,当 pod 的使用比较空闲时,在稳定空闲一段时间后,还会自动减少 pod 的副本数量。
若要实现自动扩缩容的功能,还需要部署 heapster 服务,用来收集及统计资源的利用率,支持 kubectl top 命令,heapster 服务集成在 prometheus(普罗米修斯) Mertric Server 服务中,所以说,要先安装 prometheus。
(1)创建 php-apache
为了测试 HPA,这里将使用 php-apache 。 php-apache 主要是一个 之后将通过请求访问该 Pod ,用来模拟请求的负载增加和减少,查看 Pod 的数量变化。
kubectl run php-apache --image=gcr.io/google_containers/hpa-example --requests=cpu=200m --expose --port=80
或者自己创建一个deployment和service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: "registry.cn-shenzhen.aliyuncs.com/cookcodeblog/hpa-example:latest"
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
创建 deployment 和 servcie :
# 1. 创建
kubectl apply -f php-apache.yaml
# 2. 查看
kubectl get deployment php-apache
kubectl get svc php-apache
kubectl get pods -l run=php-apache -o wide
(2)创建HPA
为上面创建的 deployment php-apache 创建 HPA,其中最小副本数为 1,最大副本数为 10,保持该 deployment 的所有 Pod 的平均 CPU 使用率不超过 50%。
# 默认创建的HPA名称和需要自动伸缩的对象名一致
# 可以通过--name来指定HPA名称
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
在本例中,deployment 的 pod 的 resources.request.cpu 为 200m (200 milli-cores vCPU),所以 HPA 将保持所有 Pod 的平均 CPU 使用率不超过 100m。可以通过 kubectl top pods 查看 pod 的 CPU 使用情况。
查看HPA:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 25s
如果 TARGETS 列值格式为 /,如果 actual 值总是为 unkown,则表示无法从 Metrics Server 中获取指标值。
-
HPA 默认每15秒从 Metrics Server 取一下指标来判断是否要自动伸缩。通过 --horizontal-pod-autoscaler-sync-period 来设置
-
Metrics Server 采集指标的默认间隔为60秒。可以使用 metrics-resolution 来修改,但不建议设置低于15s的值,因为这是 Kubelet 中计算的度量的分辨率。
(3)增加负载
打开一个新的 Terminal,创建一个临时的 pod load-generator,并在该 pod 中向 php-apache 服务发起不间断循环请求,模拟增加 php-apache 的负载(CPU使用率)。
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never \
-- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
查看 HPA 及 Pod:
# 监控 HPA
$ kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 196%/50% 1 10 4 17m
# 监控 Pod
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
load-generator 1/1 Running 0 16m 10.244.2.82 k8s-node02 <none> <none>
php-apache-5d8c7bfcd5-bsnnj 1/1 Running 0 13m 10.244.1.109 k8s-node01 <none> <none>
php-apache-5d8c7bfcd5-hs6gd 1/1 Running 0 14m 10.244.2.83 k8s-node02 <none> <none>
php-apache-5d8c7bfcd5-jmmpj 1/1 Running 0 53m 10.244.1.108 k8s-node01 <none> <none>
php-apache-5d8c7bfcd5-rdglr 1/1 Running 0 12m 10.244.2.84 k8s-node02 <none> <none>
# 当四个副本都运行之后,CPU 实际使用率已降低到49%
$ kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 49%/50% 1 10 4 30m
可以看到 HPA TARGETS(CPU使用率)的 acutal 值逐渐升高到196% (超过了期望值50%),副本数 REPLICAS 也从 1 自动扩容到了 4。当4个副本都 RUNNING 之后,CPU 使用率降低到了 50% 左右。
HPA 通过自动扩容到 4 个副本,来分摊了负载,使得所有 Pod 的平均 CPU 使用率保持(近似)在目标值。
查看 HPA 自动伸缩事件:
kubectl describe hpa php-apache
(4)减少负载
在运行 load-generator 的 Terminal,按下 Ctrl + C 来终止进程。
过一段时间后来查看 HPA,副本数已经降到了1个:
$ kubectl get hpa php-apache
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 49m
如果观察HPA没有 scale down,需要再等待一段时间。Kuberntes 为了保证缩容时业务不中断,和防止频繁伸缩导致系统抖动,scale down 一次后需要等待一段时间才能再次 scale down,也叫伸缩冷却(cooldown)。默认伸缩冷却时间为5分钟。可以通过参数 --horizontal-pod-autoscaler-downscale-stabilization 修改
资源限制
Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup。
Pod资源限制
默认情况下,Pod 运行没有 CPU 和内存的限额。 这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU 和内存 。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
- requests:要分分配的资源,可以简单理解为初始值;
- limits:为最高请求的资源值,可以简单理解为最大值
spec:
containers: # 在容器模板下进行设置
- image: xxxx
imagePullPolicy: Always
name: auth
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: "4" # 4个cpu
memory: 2Gi
requests:
cpu: 250m #250MHz
memory: 250Mi
名称空间资源限制
当 pod 没有设置资源限制的话,pod 会使用当前名称空间下的最大资源,如果名称空间也没有设置资源限制的话,pod 就可以使用集群的最大资源,就很有可能出现 OOM。
(1)计算资源配额
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: spark-cluster
spec:
hard:
pods: "20" # 创建pod的数量
requests.cpu: "20" # 所有pod加在一起总共20个
requests.memory: 100Gi # 所有pod加在一起总共100G
limits.cpu: "40"
limits.memory: 200Gi
(2)配置对象数量配额限制
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: spark-cluster
spec:
hard:
configmaps: "10" # configmap 最多创建10个
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
(3)配置 CPU 和 内存 LimitRange
LimitRange 是对指定名称空间下 pod 和 container 进行设置:
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default: # 默认最大值
memory: 50Gi # 最大可以用到 50G
cpu: 5 # 最多可以使用 5 个cpu
defaultRequest: # 默认初始值
memory: 1Gi # 内存 1G
cpu: 1 # 一个cpu
type: Container # 类型
EFK
EFK 不是一个软件,而是一套解决方案。EFK 是三个开源软件的缩写,Elasticsearch,Fluentd,Kibana。其中 ELasticsearch 负责日志分析和存储,Fluentd 负责日志收集(这玩意我没有学过,只学过Flume,想来差不多),Kibana 负责界面展示。它们之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志分析系统解决方案。
这里使用helm安装。
(1)添加Google incubator仓库
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
(2)部署ES:
# 创建efk命名空间
kubectl create namespace efk
# fetch es的chart
helm fetch incubator/elasticsearch --version 1.10.2
# 解压chart的压缩包
tar - zxvf elasticsearch-1.10.2.tgz
# 进入该目录
# install
helm install --name els1 --namespace=efk -f values.yaml .
进行测试:
# 创建并运行一个可复制的镜像
kubectl run cirror-$RANDOM --rm -it --image=cirros -- /bin/sh
# 访问结点看看
curl Elasticsearch:Port/_cat/nodes
# 可以看一下地址,再访问
# 看一下地址
kubectl get svc -n efk
curl 10.102.204.238:9200/_cat/nodes
(3)部署Fluentd:
fetch Fluentd的chart:
helm fetch stable/fluentd-elasticsearch --version 2.0.7
解压tar文件后,进入文件夹,修改values.yaml文件,修改一下es的ip地址:
elasticsearch:
host: '10.102.204.238'
install这个chart:
helm install --name flu1 --namespace=efk -f values.yaml .
(4)部署kibana:
fetch kibana的chart:
helm fetch stable/kibana --version 0.14.8
解压tar文件后,进入文件夹,修改values.yaml文件,修改一下es的地址:
files:
kibana.yml:
elasticsearch.url: http://10.102.204.238:9200
install这个chart:
helm install --name kib1 --namespace=efk -f values.yaml .
(5)修改ClusterIP为NodePort方式可以在web直接访问
kubectl edit svc kib1-kibana -n efk
type: NodePort
接下来就可以访问下看看了,通过web访问·:
http://192.168.1.10:31430/















 2386
2386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









