









文章目录
任务介绍
MIT6.830的lab3中,我们主要需要实现一个基于cost的查询优化模块,这个模块的主要作用是在SimpleDB处理Join等SQL语句的时候可以对输入的SQL查询进行优化,并且我们这里实现的是最简单的基于cost的查询优化模块,这里的cost会根据SimpleDB中数据表的统计信息计算出来,而这种统计信息就来自于之前实现的存储模块。
SimpleDB中,整个查询优化模块的架构如下图所示:
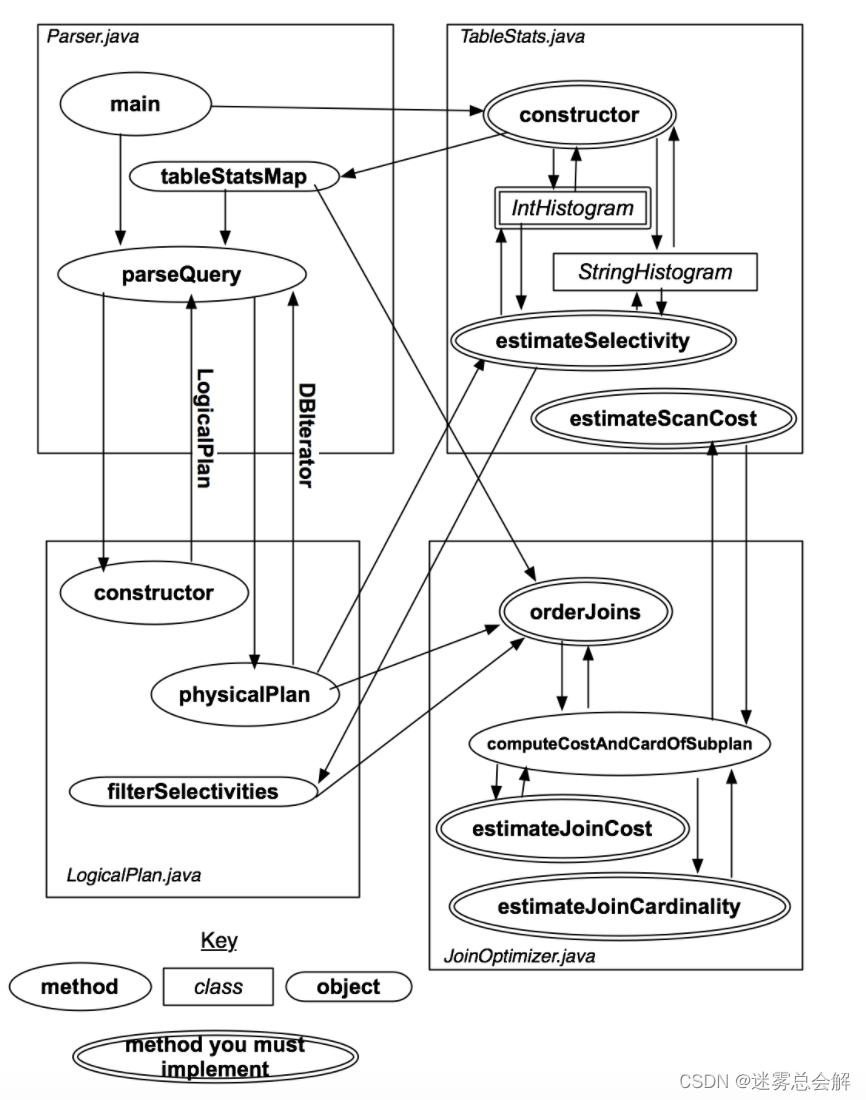
实验主要内容如下:
- 实现TableStats类中的方法,使得可以估计过滤器的选择率和遍历的代价,使用直方图或者你发明的其他方式展示结果。
- 实现JoinOptimizer类中的方法,使得可以估计cost和join的选择率
- 实现JoinOptimizer类中的orderJoins方法。这个方法会根据前两步计算出的数据,生成一个最佳的joins顺序
RBO & CBO
在学习本次实验之前,需要了解查询优化器的一些相关知识。SQL优化的发展,则可以分为两个阶段,即RBO(Rule Base Optimization),和CBO(Cost Base Optimization)。
RBO,RBO主要是开发人员在使用SQL的过程中,有些发现有些通用的规则,可以显著提高SQL执行的效率。
例如,我们都知道join是非常耗时的一个操作,且性能与join双方数据量大小呈线性关系(通常情况下)。那么很自然的一个优化,就是尽可能减少join左右双方的数据量,于是就想到了先filter再join这样一个rule。而非常多个类似的rule,就构成了RBO。
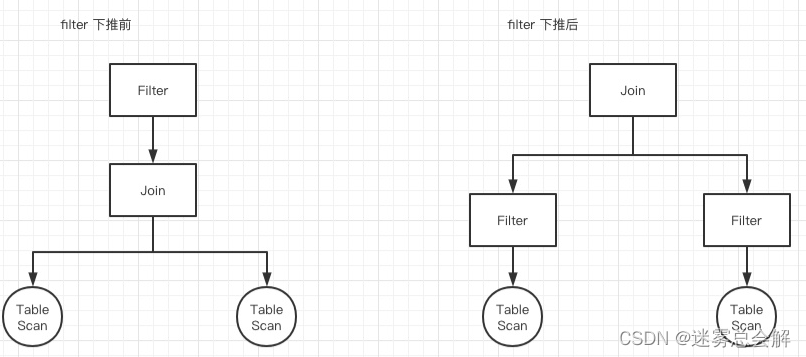
CBO:
- 利用关于表的统计数据,来估计不同查询计划的cost。通常来说,cost与join、selection的基数、filter的选择率和join的谓词有关。
- 使用数据来对join和select进行排序,并选择最佳的实现方式。
exercise 1 - IntHistogram
我们首先要来实现统计一个直方图类IntHistogram和StringHistogram,用来统计一个表的一列的数据分布情况,然后用每个列对应的这个统计表来组成整个数据表的统计信息TableStats
直方图类的实现方式其实非常朴素,我们首先假设一个数据表的某个属性(也可以叫做Field)的值是离散分布的,然后就可以统计出这个Field的每个值对应的元组个数,并形成下面这样一张直方图:
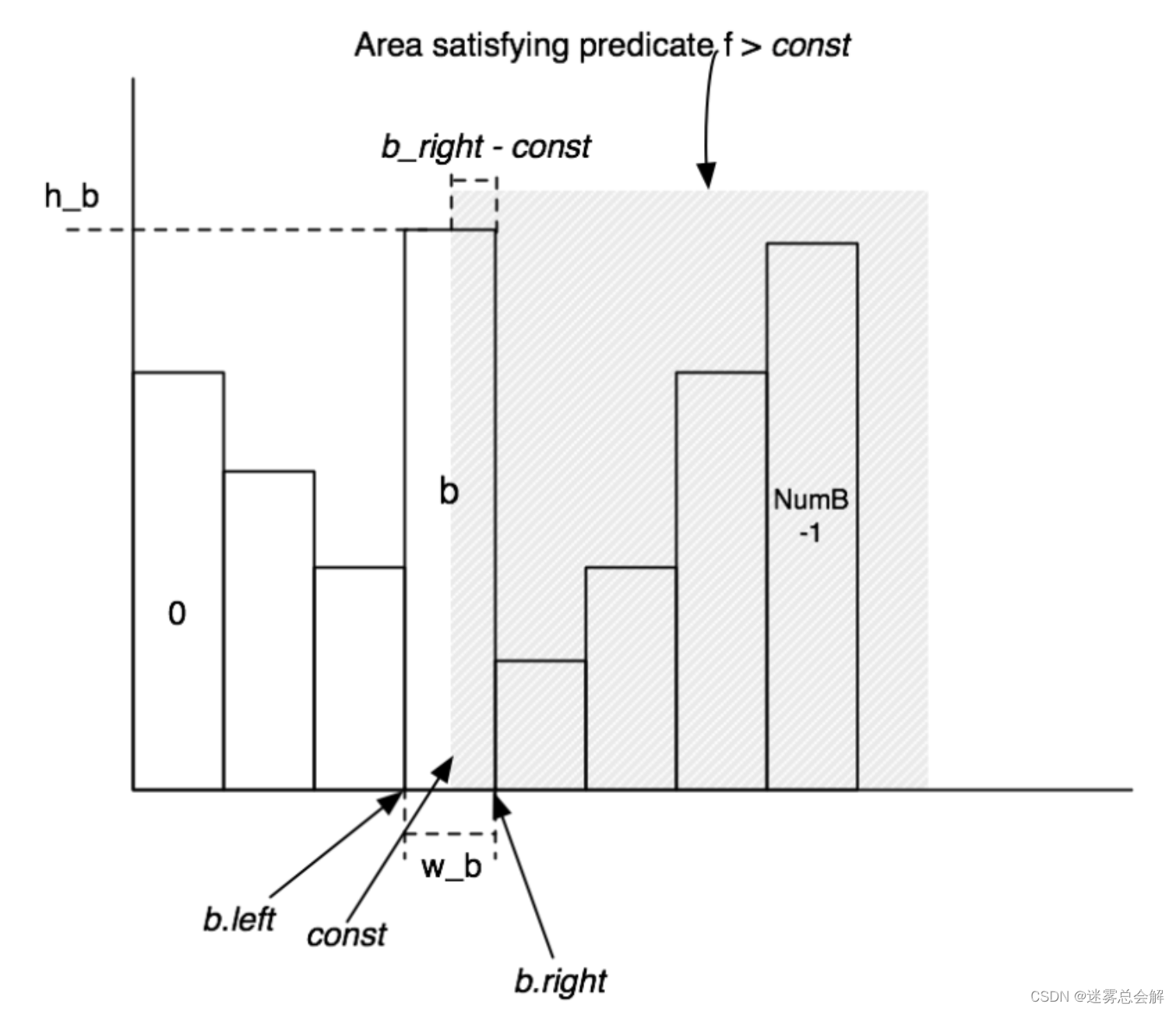
然后,我们在执行Join操作的时候往往需要用到Filter操作对元组进行过滤,而Filter又可以分为等于,不等于,大于,大于等于,小于和小于等于这样几种,并且它们是两两互补的(即每两个一对,占总数据的比例加起来等于1),实际上我们只要实现其中一半的Filter就可以了。
而计算Filter的结果主要是需要我们计算过滤后得到的元组数量占全部的比例,这个时候就可以用直方图对应区域的面积来表示这部分元组所占的比例,我们在代码实现中只要想个办法来估算直方图中的面积就可以了。同时要注意的是,每种Filter的占比对应的面积是不同的,比如大于是分界点右边的面积,小于则是左边的面积,而等于则是在分界点所在的这一块里面用平均值来估算,比如我有一段对应的值有3,4,5三个,而这一段区域对应的元组数是30,那么在估计该Field值为4的元组数量的时候,就是30/3=10个。
先看下成员变量:
private int buckets; //桶数量
private int min; //当前field最小值
private int max; //当前field最大值
private double avg; //平均每个桶表示的值数量,其实是一个整数
private MyGram[] myGrams; //每一个桶
private int ntups; //一共的tuple数量
public class MyGram{
private double left; //当前gram左边界
private double right; //当前gram右边界
private double w; //当前gram宽度
private int count; //当前gram的tuple个数
...
}
每次新增一个tuple,只需要在对应的gram中count+1即可:
public void addValue(int v) {
// some code goes here
int target = binarySearch(v);
if(target!=-1){
myGrams[target].count++;
ntups++;
}
}
然后我们只需要花时间来实现一下public double estimateSelectivity(Predicate.Op op, int v) 这个方法就可以了:
public double estimateSelectivity(Predicate.Op op, int v) {
int target = binarySearch(v);
MyGram cur;
if(target!=-1){
cur = myGrams[target];
}else{
cur = null;
}
if(op == Predicate.Op.EQUALS){
if(cur==null){
return 0.0;
}
return (cur.count/cur.w)/(ntups*1.0);
}else if(op == Predicate.Op.GREATER_THAN){
if(v<min){
return 1.0;
}else if(v>=max){
return 0.0;
}else if(cur!=null){
double res = ((cur.right-v)/cur.w)*(cur.count*1.0)/(ntups*1.0);
for(int i =target+1;i<buckets;i++){
res += (myGrams[i].count *1.0)/(ntups*1.0);
}
return res;
}
}else if(op == Predicate.Op.LESS_THAN){
if(v<=min){
return 0.0;
}else if(v >max){
return 1.0;
}else if (cur!=null){
double res = ((v-cur.left)/cur.w)*(cur.count*1.0)/(ntups*1.0);
for(int i=0;i<target;i++){
res += (myGrams[i].count*1.0)/(ntups*1.0);
}
return res;
}
}else if(op == Predicate.Op.NOT_EQUALS){
if(cur==null){
return 1.0;
}
return 1-((cur.count/cur.w)/(ntups*1.0));
}else if(op == Predicate.Op.GREATER_THAN_OR_EQ){
if(v<=min){
return 1.0;
}else if(v>max){
return 0.0;
}else if(cur!=null){
double res = ((cur.right-v+1)/cur.w)*(cur.count*1.0)/(ntups*1.0);
for(int i =target+1;i<buckets;i++){
res += (myGrams[i].count *1.0)/(ntups*1.0);
}
return res;
}
}else if(op == Predicate.Op.LESS_THAN_OR_EQ){
if(v<min){
return 0.0;
}else if(v >=max){
return 1.0;
}else if (cur!=null){
double res = ((v-cur.left+1)/cur.w)*(cur.count*1.0)/(ntups*1.0);
for(int i=0;i<target;i++){
res += (myGrams[i].count*1.0)/(ntups*1.0);
}
return res;
}
}
return 0.0;
}
在数据库中,字符串大小的比较本质上还是数字类型的比较,比如这里StringHistoram是基于IntHistogram间接实现的,那么我们可以取String的高四位,按照相同位置的字符的ASCII码值的大小进行排序的,并不需要每位进行ASCII码值比较,可以使用移位来进行实现,高位的ASCII码值移位到左边,这样越大的String其得到的值也越大。看下代码:
private int stringToInt(String s) {
int i;
int v = 0;
for (i = 3; i >= 0; i--) {
if (s.length() > 3 - i) {
int ci = s.charAt(3 - i);
v += (ci) << (i * 8);
}
}
...
return v;
}
举个例子:
codek:
ci: 99 111 100 101
v: 1660944384 1668218880 1668244480 1668244581
iller:
ci: 105 108 108 101
v: 1761607680 1768685568 1768713216 1768713317
v(codek)<v(iller) ==> "codek"<"iller"
exercise 2 - TableStats
实现对特定表的统计,本质就是基于Exercise 1,对表的每个列建立直方图,然后就可以用建好的每个列的直方图来进行运算的代价和数量的估计。
先来看看成员变量:
private static final ConcurrentMap<String, TableStats> statsMap = new ConcurrentHashMap<>();
static final int IOCOSTPERPAGE = 1000;
private int tableId;
private int ioCostPerPage;
private BufferPool bufferPool = Database.getBufferPool();
private Catalog catalog = Database.getCatalog();
private TupleDesc tupleDesc;
private DbFileIterator dbFileIterator; //所有tuple
private int numPages;
private int total = 0;
private int[] max; //每一个字段的max
private int[] min; //每一个字段的min
private IntHistogram[] intHistograms; //每一个字段的直方图
- statsMap是一个静态变量,可以获取所有table的TableStats;
对表中的每个列建立直方图需要对表中元素进行两次迭代,第一遍迭代找出最大最小的值,第二遍迭代对每个字段对应的直方图进行addValue,建立直方图。代码如下所示:
try {
this.dbFileIterator.open();
while(dbFileIterator.hasNext()){
this.total++;
Tuple tuple = dbFileIterator.next();
for(int i=0;i<max.length;i++){
Type fieldType = tuple.getField(i).getType();
if(fieldType.equals(Type.INT_TYPE)){
IntField field = (IntField)tuple.getField(i);
int value = field.getValue();
if(value>max[i]){
max[i] = value;
}
if(value<min[i]){
min[i] =value;
}
}
}
}
} catch (DbException e) {
e.printStackTrace();
} catch (TransactionAbortedException e) {
e.printStackTrace();
}
for(int i=0;i<tupleDesc.numFields();i++){
Type fieldType = tupleDesc.getFieldType(i);
if(fieldType.equals(Type.STRING_TYPE)){
continue;
}
this.intHistograms[i] =new IntHistogram(100,min[i],max[i]);
try {
this.dbFileIterator.rewind();
while(dbFileIterator.hasNext()){
Tuple tuple = dbFileIterator.next();
IntField field = (IntField)tuple.getField(i);
this.intHistograms[i].addValue(field.getValue());
}
} catch (DbException e) {
e.printStackTrace();
} catch (TransactionAbortedException e) {
e.printStackTrace();
}
}
还要注意一下几种数值计算:
-
表的扫描代价 = 表的页数 * 单个页的IO代价
public double estimateScanCost() { return this.numPages*ioCostPerPage; } -
表的基数 = 表的tuple数 * 选择性因子
public int estimateTableCardinality(double selectivityFactor) { return (int)(totalTuples()*selectivityFactor); }
exercise 3 - Join Cost Estimation
Exercise 3代码量比较小,核心点就两个:
- estimateJoinCost(LogicalJoinNode j, int card1, int card2, double cost1, double cost2):理解并推导出两表Join的代价公式(基于嵌套循环连接),推导并不难,实验说明里给出了,自己能手推一遍更好,思考清楚分分钟就能完成。
- estimateJoinCardinality(LogicalJoinNode j, int card1, int card2, boolean t1pkey, boolean t2pkey):表连接的基数,这块感觉比较浅显,只是根据实验说明给出的3个优化规则,照着写就完事了。应该有基于直方图估算的算法,但实验简化了。
两表join的代价估算:
joincost(t1 join t2) = scancost(t1) + ntups(t1) x scancost(t2) //IO cost
+ ntups(t1) x ntups(t2) //CPU cost
代码如下:
public double estimateJoinCost(LogicalJoinNode j, int card1, int card2,
double cost1, double cost2) {
if (j instanceof LogicalSubplanJoinNode) {
// A LogicalSubplanJoinNode represents a subquery.
// You do not need to implement proper support for these for Lab 3.
return card1 + cost1 + cost2;
} else {
// Insert your code here.
// HINT: You may need to use the variable "j" if you implemented
// a join algorithm that's more complicated than a basic
// nested-loops join.
return cost1+card1*cost2+card1*card2;
}
}
计算基数,也是使用讲义中简化后的估算方法
-
对于equality joins
当一个属性是primary key,由表连接产生的tuples数量不能大于non-primary key属性的选择数。
对于没有primary key的equality joins,很难说连接输出的大小是多少,可以是两表被选择数的乘积(如果两表的所有tuples都有相同的值),或者也可以是0。
-
对于范围scans,很难说清楚明确的数量。
输出的数量应该与输入的数量是成比例的,可以预估一个固定的分数代表range scans产生的向量叉积(cross-product),比如30%。总的来说,range join的开销应该大于相同大小两表的non-primary key equality join开销。
代码如下:
public int estimateJoinCardinality(LogicalJoinNode j, int card1, int card2,
boolean t1pkey, boolean t2pkey, Map<String, TableStats> stats) {
if (j instanceof LogicalSubplanJoinNode) {
// A LogicalSubplanJoinNode represents a subquery.
// You do not need to implement proper support for these for Lab 3.
return card1;
} else {
return estimateTableJoinCardinality(j.p, j.t1Alias, j.t2Alias,
j.f1PureName, j.f2PureName, card1, card2, t1pkey, t2pkey,
stats, p.getTableAliasToIdMapping());
}
}
public static int estimateTableJoinCardinality(Predicate.Op joinOp,
String table1Alias, String table2Alias, String field1PureName,
String field2PureName, int card1, int card2, boolean t1pkey,
boolean t2pkey, Map<String, TableStats> stats,
Map<String, Integer> tableAliasToId) {
int card = 1;
// some code goes here
if(joinOp.equals(Predicate.Op.EQUALS)){
if(!t1pkey&&!t2pkey){
return Math.max(card1,card2);
}else if(!t2pkey){
return card2;
}else if(!t1pkey){
return card1;
}else{
return Math.min(card1,card2);
}
}else if(joinOp.equals(Predicate.Op.NOT_EQUALS)){
if(!t1pkey && !t2pkey){
return card1 * card2 - Math.max(card1,card2);
}else if (!t2pkey){
return card2*card1 - card2;
}else if(!t1pkey){
return card1*card2 - card1;
}else{
return card1*card2 - Math.min(card1,card2);
}
}
//如果不是=或!=,是很难估计基数的
//输出的数量应该与输入的数量是成比例的,可以预估一个固定的分数代表range scans产生的向量叉积,比如30%
return (int)(0.3 * card1 * card2);
}
exercise 4 - Join Ordering
最后我们要实现Join的优化,这个方法的定义如下:
List<LogicalJoinNode> orderJoins(Map<String, TableStats> stats,
Map<String, Double> filterSelectivities,
boolean explain)
也就是通过该方法获取一个cost最小的查询顺序。
再说具体实现之前,我们必须了解一下大概算法和这个lab中的相关源码。
Join Order 算法
执行计划优化中有一个非常重要的问题,就是连接顺序(Join Order)。简单来说,当用户执行一个查询需要Join多张表时,优化器需要决定按照什么样的顺序将这些表连接在一起,而这个“顺序”我们称为Join Order。在很多时候,Join Order对于执行效率的影响是决定性的,在最佳的Join Order中,哪怕改变其中一部分,也有可能引起数量级的执行时间变化,可谓失之毫厘谬以千里。因此,不管数据库如何发展,Join Order始终是一个非常重要的话题。
那么多表连接算法(Join Order)需要解决两个问题:
- 多表连接的顺序: 表的不同的连接顺序,会产生许多不同的连接路径;不同的连接路径有不同的效率。
- 多表连接的搜索空间:因为多表连接的顺序不同,产生的连接组合会有多种,如果这个组合的数目巨大,连接次数会达到一个很高的数量级,最大可能的连接次数 是 N !(N 的阶乘)。比如,N=5,连接次数是 120 ; N=10,连接次数是 3 628 800 ; N=20,连接次数是 2 432 902 008 176 640 000。所有的连接可能构成一个巨大的“搜索空间”。如何将搜索空间限制在一个可接受的时间范围内,并高效地生成查询执行 计划将成为一个难点。
贪心算法
目前 TiDB 中使用的算法是 Join Reorder 算法,又称贪心算法。简单描述下贪心算法的过程。
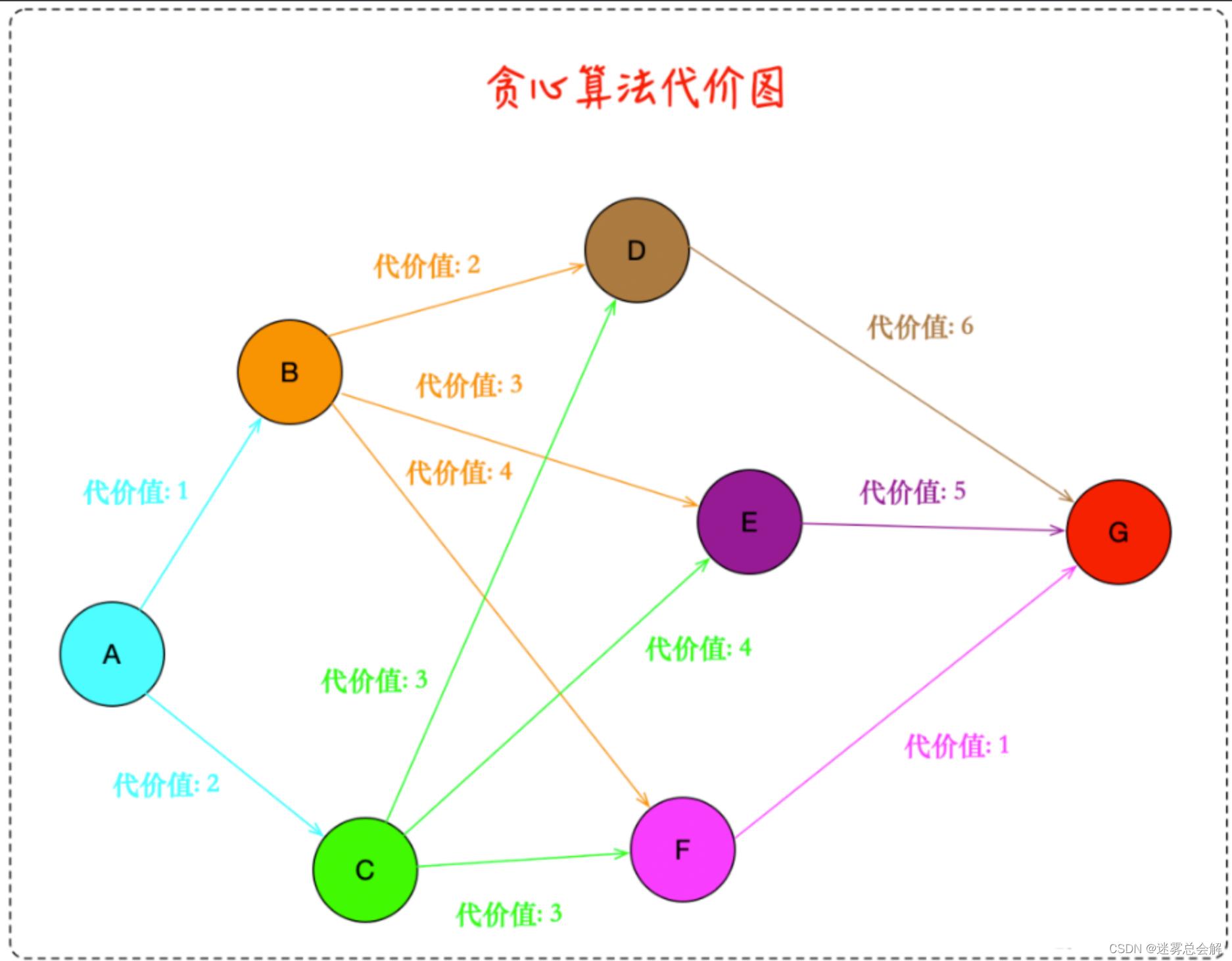
贪心算法的前提是确定源点,只找当前步骤的最优解,是一种深度优先的解法,算法复杂度是O(n²)找到后继续深入下一层,直至达到终点。
比如上图从A到G,使用贪心算法的路径是A->B->D->G算法,代价是1+2+6=9,很明显这并不是最优解,最优解我们肉眼可以看出来是A->C->F->G,代价是2+3+1=6。所以我们看贪心算法并不是全局最优的,但是优点是算法复杂度低,不会将时间都浪费在计算代价上了,因为如果关联的表特别多,那么代价的计算是指数级增长,所以贪心算法虽然不是最优解,但是在连接表的数量很大的情况下具有一定优势。
举一个实际的SQL案例说明如下所示:
SELECT
*
FROM
A,
B,
C
WHERE
A.a = B.a
AND C.a = B.a
以三个表 A、B、C 的 Join 为例。
**第一步、**首先获取所有参与 Join 的节点,将所有节点按照行数多少,从少到多进行排序。
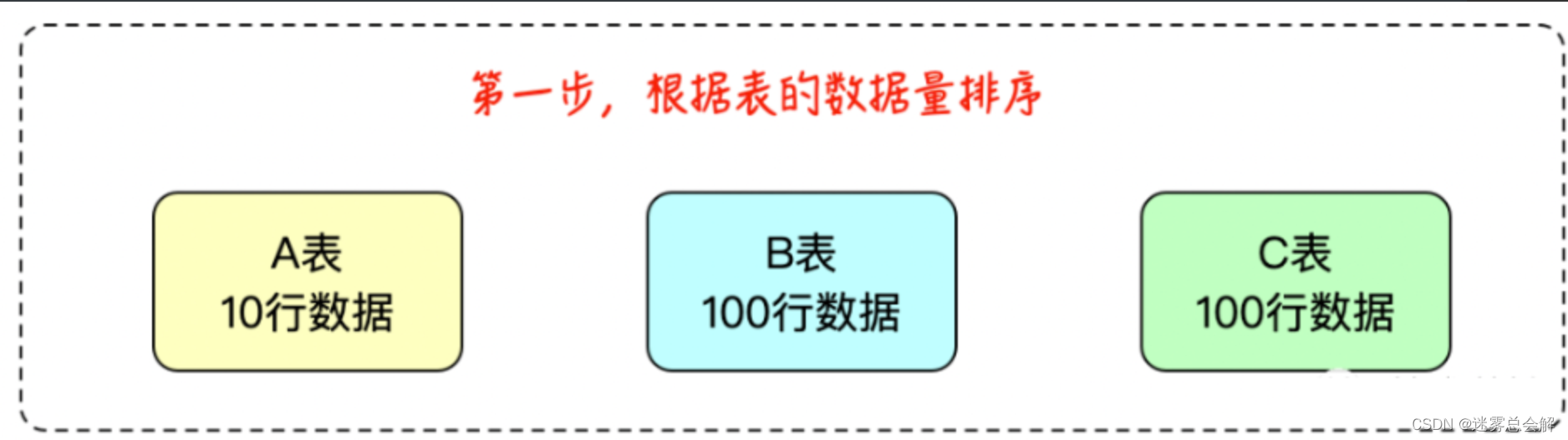
**第二步、**选定其中最小的表,将其与其他两个表分别做一次 Join,观察输出的结果集大小,选择其中结果更小的一对。
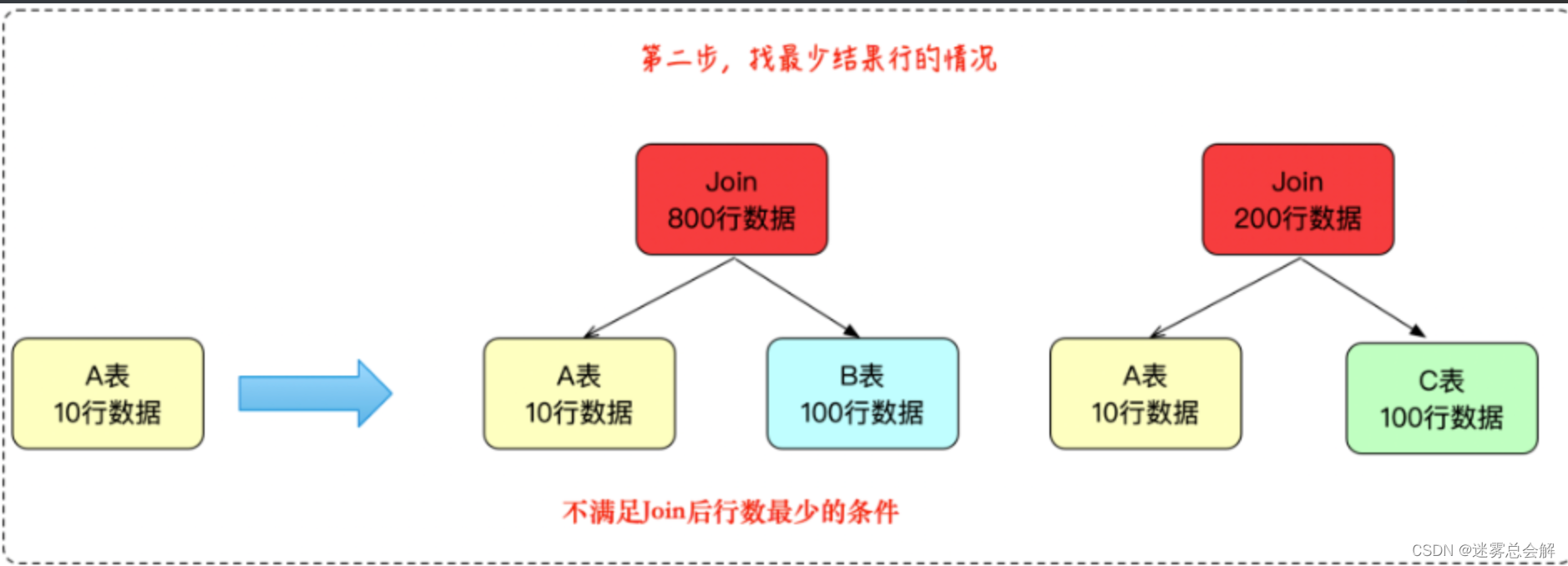
**第三步、**进入下一轮的选择,如果这时是四个表,那么就继续比较输出结果集的大小,进行选择。这里只有三个表,因此就直接得到了最终的 Join 结果。
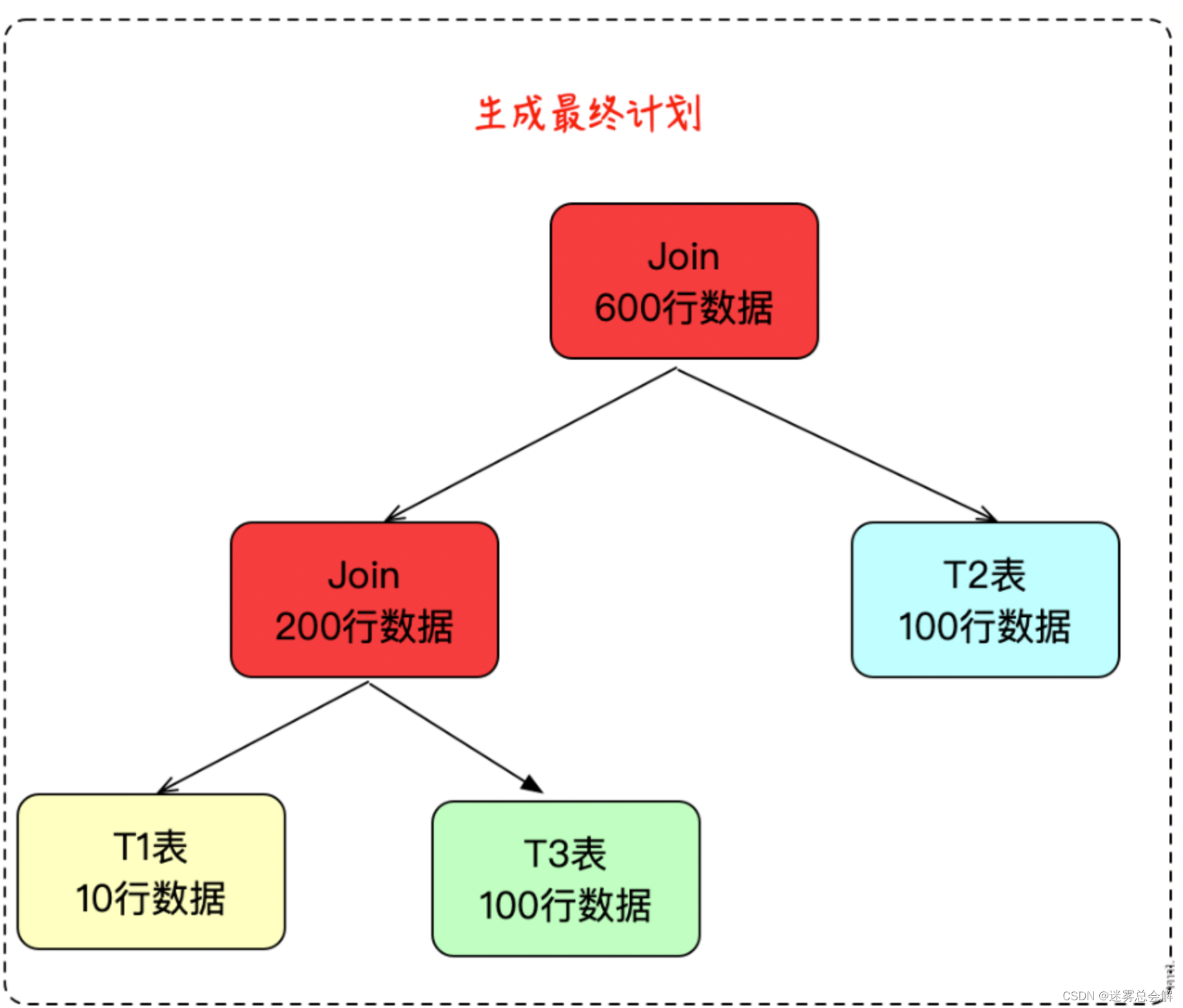
以上就是当前 TiDB 中使用的 Join Reorder 算法。Mysql数据库对于多表关联也采用的是贪心算法。
贪心的缺点
贪心算法只能保证局部最优,但是没有办法保证全局最优。例如下面的案例:
A JOIN B JOIN C
原始表数据如下所示:
- A有1000条数据
- B有100条
- C有10条数据
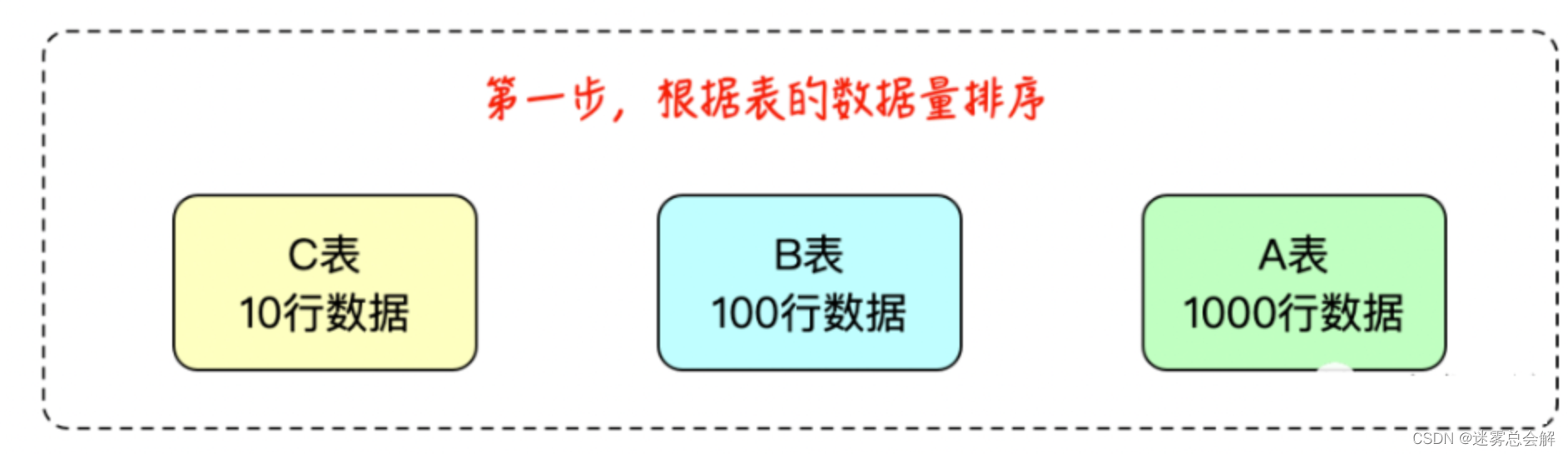
利用贪心算法只查找Join结果行数最少的方式,未必是结果最优的。例如
三个表之间存在一定的Join谓词使得
- A JOIN B返回10000条数据
- B JOIN C返回200条数据
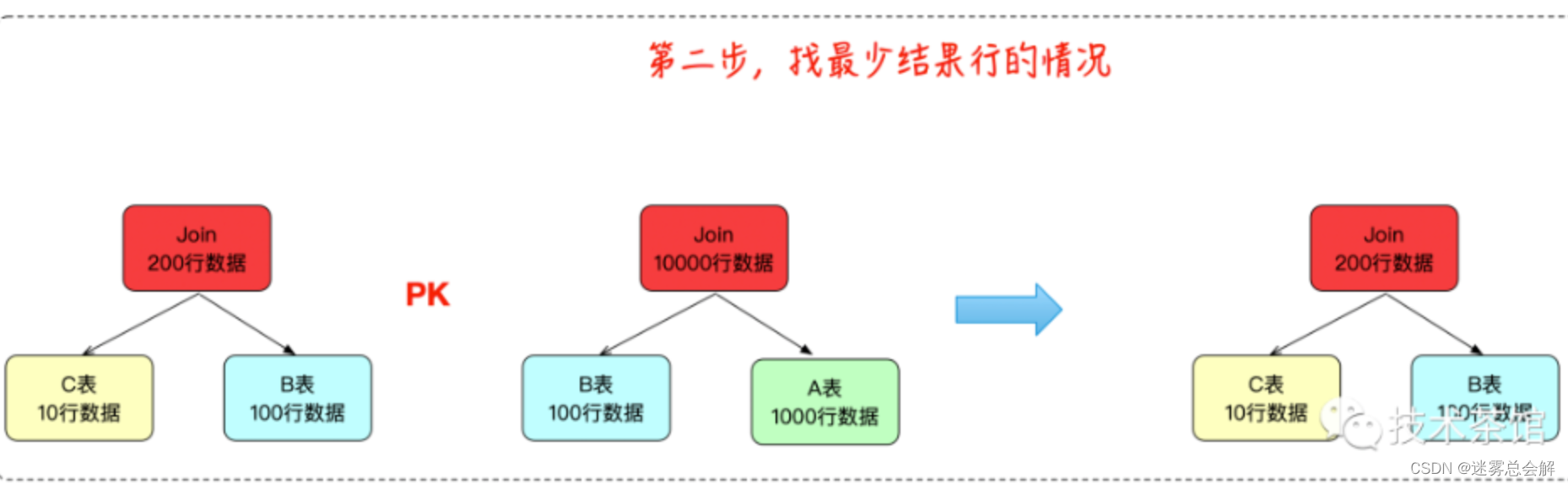
如果采用最朴素的NestLoop Join算法,
- 第一个执行计划需要处理100 * 10 + 200 * 1000 = 200100次循环
- 第二个执行计划需要处理1000 * 100 + 10000 * 10 = 200000次循环
因此第二个执行计划会更优一点。贪心算法没有找到合适的解。
动态规划算法
从底向上进行的,即从叶子(单个表)开始算作一层,然后由底层开始对每层的关系做两两连接 (如果满足内连接则两两连接,不满足内连接则不可对全部表进行两两连接操作),构造出上层,逐次递推到树根。
下面介绍具体步骤。
- 初始状态。构造第一层关系,即叶子结点,每个叶子对应一个单表。
- 归纳。当层数从第1到n-1,假设已经生成,则如何求解第n层的关系? 方法为:将第n-1层的关系(有多个关系)与第一层中的每个关系连接,生成新的关系,放于第n层,且每一个新关系,均求解其最优路径。
以上虽然分为两步,但实际上步骤2多次执行,每一次执行后生成的结果被下一次使用,即每层路径的生成都是基于上层生成的最优路径的,这满足最优化原理的要求。
动态规划算法与System R算法相比,增加了中间关系的大小估算。还有的改进算法,在生成第n层的时候,除了通过第 n-1 层和第一层连接外,还可以通过第n-2层和第2层连接,通过第n-3层和第3层连接…
传统多表连接树有如下形态:
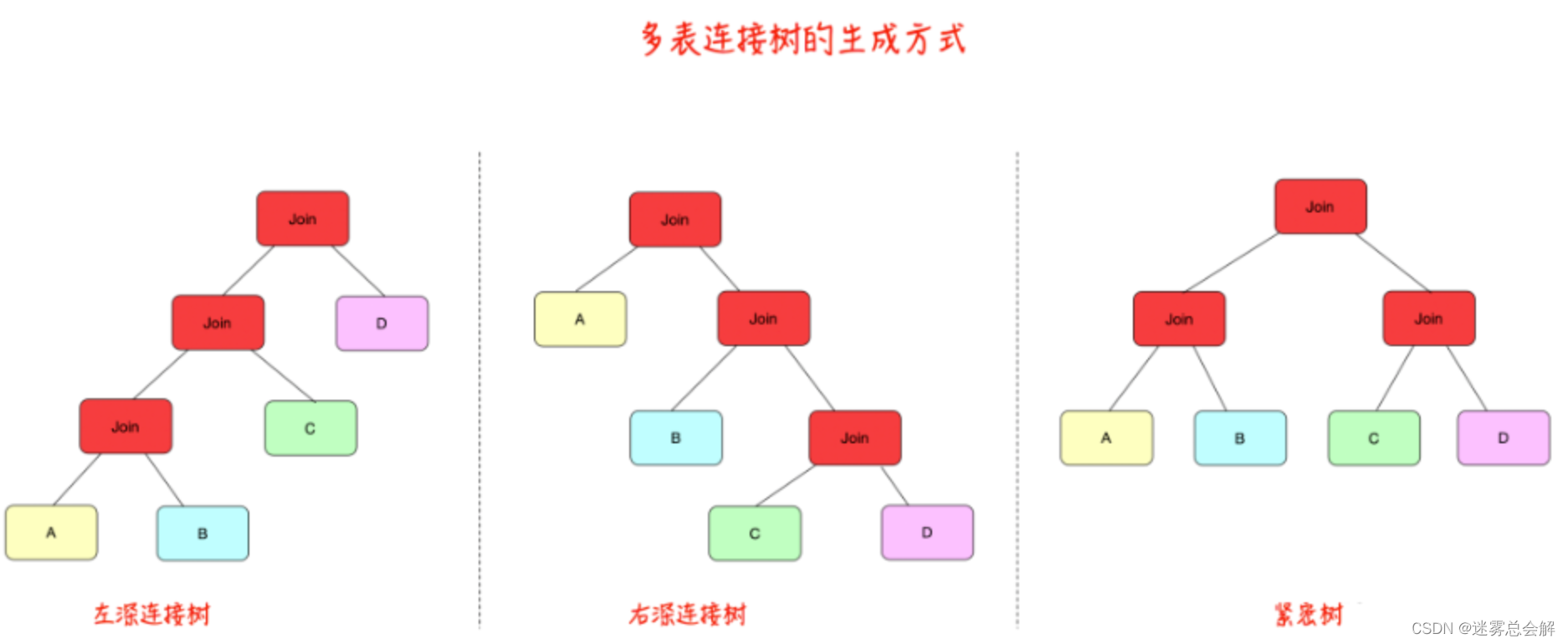
举一个实际的SQL案例说明如下所示:
SELECT
*
FROM
A,
B,
C,
D
WHERE
A.col = B.col
AND A.col = C.col
AND A.col = D.col
上面的查询语句生成最优查询计划的过程如下:
**第一步、**构建第一层树叶,初始化层。

**第二步、**构建第二层数据;使用第一层和第一层连接得到。

**第三步、**构建第三层数据;使用第二层和第一层连接得到。

第四步、
<1> 构建第四层数据;使用第三层和第一层连接得到。

<2> 构建第四层数据;使用第二层和第二层连接得到(紧密树)。

使用图表表示,动态规划运行过程表:
| 层级 | 说明 | 产生的结果 |
|---|---|---|
| 4 | 第四层通过第三层与第一层关联和第二层与第二层关联得到 | {A, B, C, D}, {A, B, D, C} {B, A, C, D}, {B, A, D, C} {A, C, B, D}, {A, C, D, B} {C, A, B, D}, {C, A, D, B} {A, D, B, C}, {A, D, C, B} {D, A, B, C}, {D, A, C, B} {B, C, A, D}, {B, C, D, A} {C, B, A, D}, {C, B, D, A} {B, D, A, C}, {B, D, C, A} {D, B, A, C}, {D, B, C, A} {C, D, B, A}, {C, D, A, B} {D, C, B, A}, {D, C, A, B}, {A, B} |
| 3 | 第三层通过第二层与第一层关联得到 | {A, B, C}, {A, B, D} {B, A, C}, {B, A, D} {A, C, B}, {A, C, D} {C, A, B}, {C, A, D} {A, D, B}, {A, D, C} {D, A, B}, {D, A, C} {B, C, A}, {B, C, D} {C, B, A}, {C, B, D} {B, D, A}, {B, D, C} {D, B, A}, {D, B, C} {C, D, B}, {C, D, A} {D, C, B}, {D, C, A} |
| 2 | 第二层通过第一层关联得到 | {A, B}, {B, A}, {A, C}, {C, A}, {A, D}, {D, A}, {B, C}, {C, B}, {B, D}, {D, B}, {C, D}, {D, C} |
| 1 | 树叶,初始层 | {A}, {B}, {C}, {D} |
然后通过代价估算找出最优的查询计划。
综上,tidb或者mysql使用贪心算法只能得到局部最优执行计划,但是计算最优解所消耗的代价较小,而postgreSQL使用动态规划能够得到最优执行计划,但是计算最优解算法复杂度较高,代价较大。
算法对比
除了上述的贪心算法和动态规划算法,还有其他的一些算法,都可以用于查询优化多表连接的生成,如爬山法、分支界定枚 举法、随机算法、遗传算法、模拟退火算法或多种算法相结合等。
多表连接算法整理如下表所示:
| 算法名称 | 特点和适用范围 | 缺点 |
|---|---|---|
| 启发式算法 | 适用于任何范围,与其他算法结合,能有效提高整体效率 | 不知道得到的解是否最优 |
| 贪婪算法 | 非穷举类型的算法。适合解决较多关系的搜索 | 得到局部最优解 |
| 爬山法 | 适合查询中包含较多关系的搜索,基于贪婪算法 | 随机性强,得到局部最优解 |
| 遗传算法 | 非穷举类型的算法。适合解决较多关系的搜索 | 得到局部最优解 |
| 动态规划算法 | 穷举类型的算法。适合查询中包含较少关系的搜索, 可得到全局最优解 | 搜索空间随关系个数增长呈指数增长 |
| System R 优化 | 基于自底向上的动态规划算法,为上层提供更多可 能的备选路径,可得到全局最优解 | 搜索空间可能比动态规划算法更大一些 |
源码解读
在完成这部分任务之前,我们有必要看下所涉及到的源码。
enumerateSubsets
public <T> Set<Set<T>> enumerateSubsets(List<T> v, int size) {
Set<Set<T>> els = new HashSet<>();
els.add(new HashSet<>());
// Iterator<Set> it;
// long start = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
Set<Set<T>> newels = new HashSet<>();
for (Set<T> s : els) {
for (T t : v) {
Set<T> news = new HashSet<>(s);
if (news.add(t))
newels.add(news);
}
}
els = newels;
}
return els;
}
这个方法就是从一个List中获取指定size的子集,举两个例子:
- list=[1,2,3,4],size=2:[[1, 2], [1, 3], [1, 4], [2, 3], [2, 4], [3, 4]]
- list=[1,2,3,4],size=3:[[1, 2, 3], [1, 2, 4], [1, 3, 4], [2, 3, 4]]
但是这个生成子集的方法复杂度是不是有点高?可以进行一下优化:
public <T> Set<Set<T>> enumerateSubsetsO(List<T> v,int size){
Set<Set<T>> els = new HashSet<>();
List<Boolean> used = new ArrayList<>();
for(int i=0;i<v.size();i++){
used.add(false);
}
enumerateSubsetsDFS(els,v,used,size,0,0);
return els;
}
public <T> void enumerateSubsetsDFS(Set<Set<T>> els,List<T> v,List<Boolean> used,int size,int count,int next){
if(count==size){
Set<T> res = new HashSet<>();
for(int i=0;i<v.size();i++){
if(used.get(i)){
res.add(v.get(i));
}
}
els.add(res);
return;
}
for(int i=next;i<v.size()-(size-count-1);i++){
used.set(i,true);
enumerateSubsetsDFS(els,v,used,size,count+1,i+1);
used.set(i,false);
}
}
大概就是采用dfs回溯的思想来获取子集。
computeCostAndCardOfSubplan
这个方法是计算一个连接方案的最佳代价,其实只需要关注joinToRemove和joinSet这两个的关系就可以弄懂整个代码逻辑了。
joinSet是包括joinToRemove这个节点的,我们要做的是从PlanCache中获取除去joinToRemove的joinSet的子最佳方案,然后计算并得到该子最佳方案和该joinToRemove节点进行连接的一个最佳方案。这就是我们前面所说的动态规划Join Order算法。
算法大概流程就是:
-
获取joinToRemove节点的基本信息;
-
生成一个连接方案:
-
当只有一个joinToRemove节点时,该节点本身就是一个连接方案;
-
当有多个节点时,先获取删除了joinToRemove节点后的joinSet的子最佳方案,然后再生成joinToRemove节点的表与子最佳方案进行连接的方案:
(1)如果joinToRemove节点左表在子最佳方案中,左表=子最佳方案,右表=joinToRemove节点右表;
(2)否则如果joinToRemove节点右表在最佳方案中,左表=joinToRemove节点左表,右表=子最佳方案。
-
-
计算当前连接方案的cost;
-
交换一次join两边顺序,再计算cost,并比较两次的cost得到最佳方案;
-
生成最终结果。
举两个例子:
(1)一个节点。
joinToRemove(t1=“student”,t2=“teacher”)
joinSet{ node1(t1=“student”,t2=“teacher”) }
最终的方案要么是student⋈teacher,要么是teacher⋈student
(2)多个节点。
joinToRemove(t1=“student”,t2=“teacher”)
joinSet{ node1(t1=“student”,t2=“teacher”) ,node2(t1=“student”,t2=“class”),node3(t1=“class”,t2=“college”)}
算法中会获取node2和node3的一个子最佳方案,设为prevBest,那么最终方案要么是student⋈prevBest,要么是prevBest⋈student。
看代码:
private CostCard computeCostAndCardOfSubplan(
Map<String, TableStats> stats,
Map<String, Double> filterSelectivities,
LogicalJoinNode joinToRemove, Set<LogicalJoinNode> joinSet,
double bestCostSoFar, PlanCache pc) throws ParsingException {
LogicalJoinNode j = joinToRemove;
List<LogicalJoinNode> prevBest;
if (this.p.getTableId(j.t1Alias) == null)
throw new ParsingException("Unknown table " + j.t1Alias);
if (this.p.getTableId(j.t2Alias) == null)
throw new ParsingException("Unknown table " + j.t2Alias);
//1. 获取joinToRemove节点的基本信息
String table1Name = Database.getCatalog().getTableName(
this.p.getTableId(j.t1Alias));
String table2Name = Database.getCatalog().getTableName(
this.p.getTableId(j.t2Alias));
String table1Alias = j.t1Alias;
String table2Alias = j.t2Alias;
Set<LogicalJoinNode> news = new HashSet<>(joinSet);
news.remove(j);
double t1cost, t2cost;
int t1card, t2card;
boolean leftPkey, rightPkey;
//2. 生成一个连接方案
if (news.isEmpty()) { // base case -- both are base relations
//2.1 当只有一个joinToRemove节点时,该节点本身就是一个连接方案
prevBest = new ArrayList<>();
t1cost = stats.get(table1Name).estimateScanCost();
t1card = stats.get(table1Name).estimateTableCardinality(
filterSelectivities.get(j.t1Alias));
leftPkey = isPkey(j.t1Alias, j.f1PureName);
t2cost = table2Alias == null ? 0 : stats.get(table2Name)
.estimateScanCost();
t2card = table2Alias == null ? 0 : stats.get(table2Name)
.estimateTableCardinality(
filterSelectivities.get(j.t2Alias));
rightPkey = table2Alias != null && isPkey(table2Alias,
j.f2PureName);
} else {
//2.2 当有多个节点时,先获取删除了joinToRemove节点后的joinSet的子最佳方案
// news is not empty -- figure best way to join j to news
prevBest = pc.getOrder(news);
// possible that we have not cached an answer, if subset
// includes a cross product
if (prevBest == null) {
return null;
}
double prevBestCost = pc.getCost(news);
int bestCard = pc.getCard(news);
// 然后再生成joinToRemove节点的表与子最佳方案进行连接的方案
// 如果joinToRemove节点左表在子最佳方案中,左表=子最佳方案,右表=joinToRemove节点右表
// 否则如果joinToRemove节点右表在最佳方案中,左表=joinToRemove节点左表,右表=子最佳方案
// estimate cost of right subtree
if (doesJoin(prevBest, table1Alias)) { // j.t1 is in prevBest
//当joinToRemove的t1在prevBest中
t1cost = prevBestCost; // left side just has cost of whatever
// left
// subtree is
t1card = bestCard;
leftPkey = hasPkey(prevBest);
t2cost = j.t2Alias == null ? 0 : stats.get(table2Name)
.estimateScanCost();
t2card = j.t2Alias == null ? 0 : stats.get(table2Name)
.estimateTableCardinality(
filterSelectivities.get(j.t2Alias));
rightPkey = j.t2Alias != null && isPkey(j.t2Alias,
j.f2PureName);
} else if (doesJoin(prevBest, j.t2Alias)) { // j.t2 is in prevbest
//当joinToRemove的t2在prevBest中
// (both
// shouldn't be)
t2cost = prevBestCost; // left side just has cost of whatever
// left
// subtree is
t2card = bestCard;
rightPkey = hasPkey(prevBest);
t1cost = stats.get(table1Name).estimateScanCost();
t1card = stats.get(table1Name).estimateTableCardinality(
filterSelectivities.get(j.t1Alias));
leftPkey = isPkey(j.t1Alias, j.f1PureName);
} else {
// don't consider this plan if one of j.t1 or j.t2
// isn't a table joined in prevBest (cross product)
return null;
}
}
// case where prevbest is left
//3. 计算当前连接方案的cost
double cost1 = estimateJoinCost(j, t1card, t2card, t1cost, t2cost);
//4. 交换一次join两边顺序,再计算cost,并比较两次的cost得到最佳方案
LogicalJoinNode j2 = j.swapInnerOuter();
double cost2 = estimateJoinCost(j2, t2card, t1card, t2cost, t1cost);
if (cost2 < cost1) {
boolean tmp;
j = j2;
cost1 = cost2;
tmp = rightPkey;
rightPkey = leftPkey;
leftPkey = tmp;
}
if (cost1 >= bestCostSoFar)
return null;
//5. 生成最终结果
CostCard cc = new CostCard();
cc.card = estimateJoinCardinality(j, t1card, t2card, leftPkey,
rightPkey, stats);
cc.cost = cost1;
cc.plan = new ArrayList<>(prevBest);
cc.plan.add(j); // prevbest is left -- add new join to end
return cc;
}
任务解决
接下来正式开始orderJoins函数的设计。核心就是翻译这段伪代码:
j = set of join nodes
for (i in 1...|j|):
for s in {all length i subsets of j}
bestPlan = {}
for s' in {all length d-1 subsets of s}
subplan = optjoin(s')
plan = best way to join (s-s') to subplan
if (cost(plan) < cost(bestPlan))
bestPlan = plan
optjoin(s) = bestPlan
return optjoin(j)
这里使用到了一个十分巧妙的动态规划算法,课件上的描述如下:

我看有些文档说这段实现动态规划的伪代码没有《数据库系统概念》写得好,我就找来看了一下,这里贴出:

其实大体思想差不多。我们采用的实现方式非常简单,就是暴力遍历所有可能的Join排列,然后分别估计它们的总的Cost,然后选出总Cost最小的一组作为查询优化的结果。
- 事实上SimpleDB已经给我们提供了一个方法
enumerateSubsets来帮助我们实现子集的搜索,我们只要调用这个方法,就不用自己再写一个对Join进行搜索的过程; - 而根据连接的长度size,会依次计算1~size长度的所有子集的最优方案,每一个长度的子集都要借助于前一个长度的子集来寻找最优方案,我们只需要调用方法
computeCostAndCardOfSubplan就可以得到该子集的一种最优方案了; - 在搜索的过程中,我们要用一个提供的类PlanCache来存储搜索过程中的中间数据,我们要将当前子集的最优方案记录到这个PlanCache中。
public List<LogicalJoinNode> orderJoins(
Map<String, TableStats> stats,
Map<String, Double> filterSelectivities, boolean explain)
throws ParsingException {
// some code goes here
//Replace the following
int size = joins.size();
PlanCache planCache = new PlanCache();
CostCard bestCostCard = null;
for(int i=1;i<=size;i++){
//得到固定长度i的子集,并遍历每一个子集
for(Set<LogicalJoinNode> s: enumerateSubsetsO(joins,i)){
//遍历集合中的集合,得到集合中的每个集合的最小
double bestCost = Double.MAX_VALUE;
bestCostCard = new CostCard();
for(LogicalJoinNode logicalJoinNode:s){
//计算 logicalJoinNode 与 其他node(s中的其它node)的join 结果
CostCard costCard = computeCostAndCardOfSubplan(stats, filterSelectivities, logicalJoinNode, s, bestCost, planCache);
if(costCard==null){
continue;
}
if(costCard.cost<bestCost){
bestCost = costCard.cost;
bestCostCard = costCard;
}
}
planCache.addPlan(s,bestCost,bestCostCard.card,bestCostCard.plan);
}
}
//是否解释其查询计划
if(explain){
assert bestCostCard!=null;
printJoins(bestCostCard.plan,planCache,stats,filterSelectivities);
}
assert bestCostCard!=null;
return bestCostCard.plan;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









