







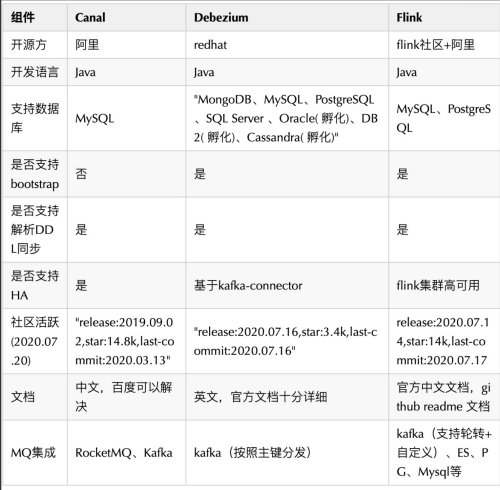
Sqoop
介绍
Sqoop : SQL-to-Hadoop(Apache已经终止Sqoop项目)
用途:把关系型数据库的数据转移到HDFS(Hive、Hbase)(重点使用的场景);Hadoop中的数据转移到关系型数据库中。Sqoop是java语言开发的,底层使用mapreduce。
需要注意的是,Sqoop主要使用的是Map,是数据块的转移,没有使用到reduce任务。
Sqoop支持全量数据导入和增量数据导入(增量数据导入分两种,一是基于递增列的增量数据导入(Append方式)。二是基于时间列的增量数据导入(LastModified方式)),同时可以指定数据是否以并发形式导入。

使用要点
下图描述了Sqoop的主要使用命令:
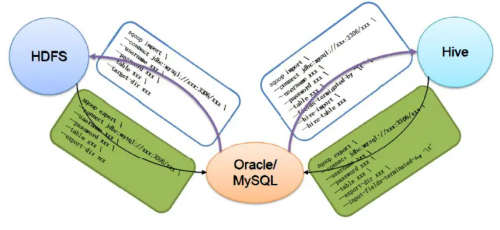
上图中,有2个主要的命令,即export 和 import,导入导出。
这里的导入和导出是相对于HDFS来讲的。例如,从RDBMS中导入到Hive中,就是导入(import);从Hive导入到Mysql中,就是导出(export)。
导入
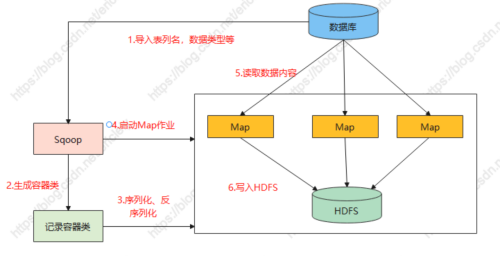
- Sqoop通过JDBC读取数据元数据信息,例如表列名,数据类型等。
- Sqoop获取元数据信息,并生成以一个与表名相同的容器类。
- Sqoop生成的容器类完成数据的序列化和反序列化,保存表的每一行数据。
- Sqoop生成的记录容器类向Hadoop的Map作业提供序列化和反序列化的功能,然后sqoop启动Map作业。
- 在Sqoop启动Map作业过程中,Map利用Sqoop生成的记录容器类提供的反序列化功能,通过JDBC读取数据库中的内容。
- Map作业将读取的数据写入HDFS,此时Sqoop生成的记录容器类提供序列化功能。
导出
Sqoop数据导出过程:将通过MapReduce或Hive分析后得出的数据结果导出到关系型数据库,供其他业务查看或生成报表使用。
Sqoop export 是将一组文件从HDFS导出回RDBMS的工具。 前提条件是,在数据库中,目标表必须已经存在。 根据用户指定的分隔符将输入文件读取并解析为一组记录。

此过程与Sqoop数据导入类似,只是在导出数据之前,需要在RDBMS中建立目标表,Sqoop读取该表的元数据信息,为Map作业读取HDFS数据提供序列化及反序列化的功能,最后通过一批INSERT语句写入目标数据库中。
Sqoop安装
(1)下载并解压
下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
(2)上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop102的/opt/software路径中
(3)解压sqoop安装包到指定目录,如:
[atguigu@hadoop102 software]$ tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
(4)解压sqoop安装包到指定目录,如:
[atguigu@hadoop102 module]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
(4)修改配置文件
-
进入到/opt/module/sqoop/conf目录,重命名配置文件
[atguigu@hadoop102 conf]$ mv sqoop-env-template.sh sqoop-env.sh -
修改配置文件
[atguigu@hadoop102 conf]$ vim sqoop-env.sh 增加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3 export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3 export HIVE_HOME=/opt/module/hive export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7 export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf
(5)拷贝JDBC驱动
-
将mysql-connector-java-5.1.48.jar 上传到/opt/software路径
-
进入到/opt/software/路径,拷贝jdbc驱动到sqoop的lib目录下
[atguigu@hadoop102 software]$ cp mysql-connector-java-5.1.48.jar /opt/module/sqoop/lib/
(6)验证Sqoop
-
我们可以通过某一个command来验证sqoop配置是否正确:
[atguigu@hadoop102 sqoop]$ bin/sqoop help -
出现一些Warning警告(警告信息已省略),并伴随着帮助命令的输出:
Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information
(7)测试Sqoop是否能够成功连接数据库
[atguigu@hadoop102 sqoop]$ bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password 000000
出现如下输出:
information_schema
metastore
mysql
oozie
performance_schema
mysql->HDFS
sqoop从mysql数据库抽取数据到hive,使用import命令。主要需要2个步骤:(1)收集元数据;(2)提交只包含map的job。

将mysql中user_info表数据导入到HDFS的/test路径:
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/gmall \
--username root \
--password 000000 \
--table user_info \
--columns id,login_name \
--where "id>=10 and id<=30" \
--target-dir /test \
--delete-target-dir \
--fields-terminated-by '\t' \
--num-mappers 2 \
--split-by id
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
--table user_info \
--columns id,login_name \
--where "id>=10 and id<=30" \
可以替换为($CONDITIONS相当于一个占位符,在获取数据时可以根据id进行过滤,条件$CONDITIONS必须添加,而且$还要做转义,否则会报错):
--query ‘select id,login_name from user_info where id >= 1 and id <= 20 and \$CONDITIONS’
-
num-mappers 2: 指定mapper的数量是2
-
target-dir:为import操作指定目标目录,也就是需要将数据import到哪个目录下
-
delete-target-dir:指定了该参数后,如果hdfs的目标路径已经存在了的话,就先删除该目录,再进行import(会重新创建该目录)
-
ields-terminated-by:来修改字段分隔符,默认情况下,import导入hdfs的文件,字段分隔符是逗号
-
as-parquetfile : 指定文件的导出格式为parquet,默认情况下,导出的文件格式是textfile
-
compress : 表示对文件压缩,默认情况下,文件不压缩
-
compression-codec:压缩类型
-
null-string、null-non-string:–null-string含义是 string类型的字段,当Value是NULL,替换成指定的字符\N;–null-non-string 含义是非string类型的字段,当Value是NULL,替换成指定字符\N。
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用–input-null-string和–input-null-non-string两个参数。导入数据时采用–null-string和–null-non-string。
也可以增量导入:
- check_column:是指定增量的字段,通过id字段获取增量数据。
- incremental:指定导入的方式,追加。
- last-value:从哪行开始导入。
当使用增量导入时,选项–delete-target-dir 不可以使用,否则报错
mysql->HIVE
前边导入的目标是hdfs目录,如果想导入到hive表中,使用参数–hive-table 和 --hive-import两个选项,例如下边的例子,将cities表导入到hive的hive_cities表中:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \
--username root \
--password 123456 \
--table cities \
--delete-target-dir \
--hive-import \
--hive-table hive_cities \
--hive-database testdb \
--fields-terminated-by '\t'
从mysql导入到hive时,先将mysql数据导出放在hdfs目录:/user/natty/cities下,然后在load到hive表里去。所以上边再次导入这个表到hive另一张表时,需要指定选项–delete-target-dir,否则报错:
Output directory hdfs://hadoop-senior01.pmpa.com:8020/user/natty/cities already exists
HDFS/HIVE->RDBMS
从hdfs export导出到RDBMS的应用相对少一些。使用export命令实现。
bin/sqoop export \
--connect jdbc:mysql://hadoop-senior01.pmpa.com:3306/pma_test \
--username root \
--password 123456 \
--table hdfs2mysql \
--export-dir /user/hive/warehouse/testdb.db/cities/ \
--input-fields-terminated-by ','
-
export-dir : 从hdfs上的哪个路径上导出
-
input-fields-terminated-by ‘,’ : 这项需要非常注意,我们先确定hdfs上的文件是以什么符号作为字段分隔符的,然后指定这项。这项跟import的不同,是input-xxx属性,输入文件的分隔符。
从Hive表导入到Mysql表: 实质上就是从HDFS导入到RDBMS,没有特殊的选项参数。
脚本执行Sqoop
#!/bin/bash
sqoop=/opt/module/sqoop/bin/sqoop
$sqoop import \
--connect jdbc:mysql://hadoop102:3306/mall \
--username root \
--password 000000 \
--target-dir /origin_data/mall/db/user/2022-06-02 \
--delete-target-dir \
--query "select * from user where \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
DataX
介绍
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
为了解决异构数据源同步问题,DataX 将复杂的网状的同步链路变成了星型数据链路,DataX 作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到 DataX,便能跟已有的数据源做到无缝数据同步。

DataX 目前已经有了比较全面的插件体系,主流的 RDBMS 数据库、NOSQL、大数据计算系统都已经接入。
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 阿里云图数据库 | GDB | √ | √ | 读 、写 |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | 写 | ||
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
框架设计和原理
框架:

- Reader:数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
原理:

- Job:单个作业的管理节点,负责数据清理、子任务划分、TaskGroup监控管理。
- Task:由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule:将Task组成TaskGroup,单个TaskGroup的并发数量为5。
- TaskGroup:负责启动Task。
详细解说:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。
- 每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5(DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL=5)。每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务.
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
并发数=taskGroup的数量*每一个TaskGroup并发执行的Task数 (默认单个任务组的并发数量为5,DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL=5)
举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张分表的 mysql 数据同步到 odps 里面。 DataX 的调度决策思路是:
- DataXJob 根据分库分表切分成了 100 个 Task。
- 根据 20 个并发,DataX 计算共需要分配 4 个 TaskGroup。 (20 ÷ 5 = 4)
- 4 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责以 5 个并发共计运行 25 个 Task。
优势
-
强劲的同步性能:DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
除比较大的表之外,速度明显比sqoop快
-
日志相比于sqoop比较完善和人性化
-
精准的速度控制:Datax的速度可以配置,可以根据我们的实际情况控制,配置"speed"
job.setting. "speed": { "channel": 5, //通道数,并发数 "byte": 1048576, //全局配置channel的byte限速 "record": 10000 //全局配置channel的record限速 } core.transport.channel.speed.record:单channel的record限速 core.transport.channel.speed.byte:单channel的byte限速Channel并发有三种配置方式:
- 配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速
- 配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速
- 直接配置Channel个数,只有在上面两种未设置才生效,上面两个同时设置是取值小的作为最终的 channel 数。
-
丰富的数据转换功能:DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。
-
健壮的容错机制:DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。
-
可靠的数据质量监控:
① 完美解决数据传输个别类型失真问题:DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
②提供作业全链路的流量、数据量运行时监控:DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
③提供脏数据探测:在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式。
Job支持用户对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值),当Job传输过程出现的脏数据大于用户指定的数量/百分比,DataX Job报错退出。
图中的配置的意思是当脏数据大于10条,或者脏数据比例达到0.05%,任务就会报错:
"errorLimit": { "record": 10, "percentage": 0.05 }
安装
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址:https://github.com/alibaba/DataX
(1)将下载好的 datax.tar.gz 上传到 hadoop102 的/opt/software
(2)解压 datax.tar.gz 到/opt/module
tar -zxvf datax.tar.gz -C /opt/module/
(3)运行自检脚本
cd /opt/module/datax/bin/
python datax.py /opt/module/datax/job/job.json
使用案列
stream流 -> 控制台
(1)查看配置模板
python datax.py -r streamreader -w streamwriter
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
} }
(2)根据模板编写配置文件
vim stream2stream.json
填写以下内容:
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
} }
(3)运行
/opt/module/datax/bin/datax.py /opt/module/datax/job/stream2stream.json
MySQL -> HDFS
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [ //column:需要同步的列名集合,使用JSON数组描述自带信息,*代表所有列
"id",
"name"
],
"connection": [
{
"jdbcUrl": [ //jdbeUrl:对数据库的JDBC连接信息,使用JSON数组描述,支持多个连接地址
"jdbc:mysql://hadoop102:3306/datax"
],
"table": [ //table:需要同步的表,支持多个
"student"
],
"querySql": [] //querySql:可选,自定义SQL,配置它后,mysglreader直接忽略table、 column、 where
}
],
"username": "root",
"password": "000000"
"where": "" //where: 可选,筛选条件
"splitPK": "" //splitPK:可选,数据分片字段,一般是主键,仅支持整型
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [ //column:写入数据的字段,其中name指定字段名,type指定类型
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"compress": "" //compress: 可选,hdfs文件压缩类型,默认不填写意味着没有压缩
"defaultFS": "hdfs://hadoop102:9000", //defautFS:hdfs文件系统namenode节点地址,格式:hdfs://ip:端口
"fieldDelimiter": "\t", //fieldDelimiter: 字段分隔符
"fileName": "student.txt", //fileName: 写入文件名
"fileType": "text", //fileType:文件的类型,目前只支持用户配置为"text"或"orc"
"path": "/", //path:存储到Hadoop hdfs文件系统的路径信息
"writeMode": "append" //writeMode: hdfswriter写入前数据清理处理模式:①append: 写入前不做任何处理,Datax hafswriter直接使用filename写入,并保证文件名不冲突;②nonConflict:如果目录下有fileName前缀的文件,直接报错
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
} }
关于 HA 的支持:
"hadoopConfig":{
"dfs.nameservices": "ns",
"dfs.ha.namenodes.ns": "nn1,nn2",
"dfs.namenode.rpc-address.ns.nn1": "主机名:端口",
"dfs.namenode.rpc-address.ns.nn2": "主机名:端口",
"dfs.client.failover.proxy.provider.ns":
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
执行任务:
bin/datax.py job/mysql2hdfs.json
2019-05-17 16:02:16.581 [job-0] INFO JobContainer -
任务启动时刻 : 2019-05-17 16:02:04
任务结束时刻 : 2019-05-17 16:02:16
任务总计耗时 : 12s
任务平均流量 : 3B/s
记录写入速度 : 0rec/s
读出记录总数 : 3
读写失败总数 : 0
注意:HdfsWriter 实际执行时会在该文件名后添加随机的后缀作为每个线程写入实际文件名。
HDFS -> MySQL
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": ["*"],
"defaultFS": "hdfs://hadoop102:9000",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "text",
"path": "/student.txt"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student2"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
} }
Oracle -> MySQL
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@hadoop102:1521:orcl"],
"table": ["student"]
}
],
"password": "000000",
"username": "atguigu"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/oracle",
"table": ["student"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
} }
Oracle -> HDFS
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@hadoop102:1521:orcl"],
"table": ["student"]
}
],
"password": "000000",
"username": "atguigu"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "oracle.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
} }
MongoDB -> HDFS
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["127.0.0.1:27017"],
"collectionName": "atguigu",
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName": "test",
"splitter": ""
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "mongo.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
- address: MongoDB的数据地址信息,因为MonogDB可能是个集群,则ip端口信息需要以Json数组的形式给出。【必填】
- userName:MongoDB的用户名。【选填】
- userPassword: MongoDB的密码。【选填】
- authDb: MongoDB认证数据库【选填】
- collectionName: MonogoDB的集合名。【必填】
- column:MongoDB的文档列名。【必填】
- name:Column的名字。【必填】
- type:Column的类型。【选填】
- splitter:因为MongoDB支持数组类型,但是Datax框架本身不支持数组类型,所以mongoDB读出来的数组类型要通过这个分隔符合并成字符串。【选填】
- query: MongoDB的额外查询条件。【选填】
MongoDB -> MySQL
{
"job": {
"content": [
{
"reader": {
"name": "mongodbreader",
"parameter": {
"address": ["127.0.0.1:27017"],
"collectionName": "atguigu",
"column": [
{
"name":"name",
"type":"string"
},
{
"name":"url",
"type":"string"
}
],
"dbName": "test",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/test",
"table": ["atguigu"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
} }
SQLServer -> HDFS
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:sqlserver://hadoop2:1433;DatabaseName=datax"
],
"table": [
"student"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "sqlserver.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
} }
SQLServer -> MySQL
{
"job": {
"content": [
{
"reader": {
"name": "sqlserverreader",
"parameter": {
"column": [
"id",
"name"
],
"connection": [
{
"jdbcUrl": [
"jdbc:sqlserver://hadoop2:1433;DatabaseName=datax"
],
"table": [
"student"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
} }
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
DB2 -> HDFS(注册驱动)
datax 暂时没有独立插件支持 db2,需要使用通用的使用 rdbmsreader 或 rdbmswriter。
-
注册 reader 的 db2 驱动
vim /opt/module/datax/plugin/reader/rdbmsreader/plugin.json #在 drivers 里添加 db2 的驱动类 "drivers":["dm.jdbc.driver.DmDriver", "com.sybase.jdbc3.jdbc.SybDriver", "com.edb.Driver","com.ibm.db2.jcc.DB2Driver"] -
注册 writer 的 db2 驱动
vim /opt/module/datax/plugin/writer/rdbmswriter/plugin.json #在 drivers 里添加 db2 的驱动类 "drivers":["dm.jdbc.driver.DmDriver", "com.sybase.jdbc3.jdbc.SybDriver", "com.edb.Driver","com.ibm.db2.jcc.DB2Driver"]
{
"job": {
"content": [
{
"reader": {
"name": "rdbmsreader",
"parameter": {
"column": [
"ID",
"NAME"
],
"connection": [
{
"jdbcUrl": [
"jdbc:db2://hadoop2:50000/sample"
],
"table": [
"STUDENT"
]
}
],
"username": "db2inst1",
"password": "atguigu"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"defaultFS": "hdfs://hadoop102:9000",
"fieldDelimiter": "\t",
"fileName": "db2.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
DB2 -> MySQL
{
"job": {
"content": [
{
"reader": {
"name": "rdbmsreader",
"parameter": {
"column": [
"ID",
"NAME"
],
"connection": [
{
"jdbcUrl": [
"jdbc:db2://hadoop2:50000/sample"
],
"table": [
"STUDENT"
]
}
],
"username": "db2inst1",
"password": "atguigu"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop102:3306/datax",
"table": ["student"]
}
],
"password": "000000",
"username": "root",
"writeMode": "insert"
} }
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
MySQL -> Doris(DorisWriter)
DorisWriter 支持将大批量数据写入 Doris 中。DorisWriter 通过 Doris 原生支持 Stream load 方式导入数据,
DorisWriter 会将 reader 读取的数据进行缓存在内存中,拼接成 Json 文本,然后批量导入至 Doris。
DorisWriter需要进行编译后得到插件添加到Datax中,才能进行使用。可以自己编译,也可以直接使用编译好的包:
(1)进入之前的容器环境
docker run -it \ -v /opt/software/.m2:/root/.m2 \ -v /opt/software/apache-doris-0.15.0-incubating-src/:/root/apache-doris-0.15.0-incubating-src/ \
apache/incubator-doris:build-env-for-0.15.0
(2)运行 init-env.sh
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX
sh init-env.sh
主要做了下面几件事,减少了繁杂的操作:
-
将 DataX 代码库 clone 到本地。
-
将 doriswriter/ 目录软链到 DataX/doriswriter 目录。
这个目录是 doriswriter 插件的代码目录。这个目录中的所有代码,都托管在 Apache Doris 的代码库中。
-
在 DataX/pom.xml 文件中添加 doriswriter 模块。
-
将 DataX/core/pom.xml 文件中的 httpclient 版本从 4.5 改为 4.5.13(因为有bug)
(3)手动上传依赖alibaba-datax-maven-m2-20210928.tar.gz
在编译的时候如果没有这个依赖,可能汇报错:
Could not find artifact com.alibaba.datax:datax-all:pom:0.0.1-SNAPSHOT ...
可尝试以下方式解决:
-
解压:
tar -zxvf alibaba-datax-maven-m2-20210928.tar.gz -C /opt/software -
拷贝解压后的文件到 maven 仓库:
sudo cp -r /opt/software/alibaba/datax/ /opt/software/.m2/repository/com/alibaba/
(4)编译 doriswriter
-
单独编译 doriswriter 插件:
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX/DataX mvn clean install -pl plugin-rdbms-util,doriswriter -DskipTests -
编译整个 DataX 项目:
cd /root/apache-doris-0.15.0-incubating-src/extension/DataX/DataX mvn package assembly:assembly -Dmaven.test.skip=true
产出在 target/datax/datax/.
hdfsreader, hdfswriter and oscarwriter 这三个插件需要额外的 jar 包。如果你并不需要这些插件,可以在 DataX/pom.xml 中删除这些插件的模块。
(5)拷贝编译好的插件到 DataX
Sudo cp -r /opt/software/apache-doris-0.15.0-incubating-src/extension/DataX/doriswriter/target/datax/plugin/writer/dorisw
riter /opt/module/datax/plugin/writer
使用:
# MySQL 建表、插入测试数据
CREATE TABLE `sensor` (
`id` varchar(255) NOT NULL,
`ts` bigint(255) DEFAULT NULL,
`vc` int(255) DEFAULT NULL,
PRIMARY KEY (`id`)
)
insert into sensor values('s_2',3,3),('s_9',9,9);
# Doris 建表
CREATE TABLE `sensor` (
`id` varchar(255) NOT NULL,
`ts` bigint(255) DEFAULT NULL,
`vc` int(255) DEFAULT NULL
)
DISTRIBUTED BY HASH(`id`) BUCKETS 10;
vim mysql2doris.json
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"ts",
"vc"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop1:3306/test"
],
"table": [
"sensor"
]
}
],
"username": "root",
"password": "000000"
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"feLoadUrl": ["hadoop1:8030", "hadoop2:8030",
"hadoop3:8030"],
"beLoadUrl": ["hadoop1:8040", "hadoop2:8040",
"hadoop3:8040"],
"jdbcUrl": "jdbc:mysql://hadoop1:9030/",
"database": "test_db",
"table": "sensor",
"column": ["id", "ts", "vc"],
"username": "test",
"password": "test",
"postSql": [],
"preSql": [],
"loadProps": {
},
"maxBatchRows" : 500000,
"maxBatchByteSize" : 104857600,
"labelPrefix": "my_prefix",
"lineDelimiter": "\n"
}
}
}
]
} }
参数说明:
-
jdbcUrl
描述:Doris 的 JDBC 连接串,用户执行 preSql 或 postSQL。
必选:是
默认值:无
-
feLoadUrl
描述:和 beLoadUrl 二选一。作为 Stream Load 的连接目标。格式为 “ip:port”。其中IP 是 FE 节点 IP,port 是 FE 节点的 http_port。可以填写多个,doriswriter 将以轮询的方式访问。
必选:否
默认值:无
-
beLoadUrl
描述:和 feLoadUrl 二选一。作为 Stream Load 的连接目标。格式为 “ip:port”。其中 IP 是 BE 节点 IP,port 是 BE 节点的 webserver_port。可以填写多个,doriswriter 将以轮询的方式访问。
必选:否
默认值:无
-
username
描述:访问 Doris 数据库的用户名
必选:是
默认值:无
-
password
描述:访问 Doris 数据库的密码
必选:否
默认值:空
-
database
描述:需要写入的 Doris 数据库名称。
必选:是
默认值:无
-
table
描述:需要写入的 Doris 表名称。
必选:是
默认值:无
-
column
描述:目的表需要写入数据的字段,这些字段将作为生成的 Json 数据的字段名。字段之间用英文逗号分隔。例如: “column”: [“id”,“name”,“age”]。
必选:是
默认值:否
-
preSql
描述:写入数据到目的表前,会先执行这里的标准语句。
必选:否
默认值:无
-
postSql
描述:写入数据到目的表后,会执行这里的标准语句。
必选:否
默认值:无
-
maxBatchRows
描述:每批次导入数据的最大行数。和 maxBatchByteSize 共同控制每批次的导入数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
必选:否
默认值:500000
-
maxBatchByteSize
描述:每批次导入数据的最大数据量。和 maxBatchRows 共同控制每批次的导入数量。每批次数据达到两个阈值之一,即开始导入这一批次的数据。
必选:否
默认值:104857600
-
labelPrefix
描述:每批次导入任务的 label 前缀。最终的 label 将有 labelPrefix + UUID + 序号 组 成
必选:否
默认值:datax_doris_writer_
-
lineDelimiter
描述:每批次数据包含多行,每行为 Json 格式,每行的的分隔符即为 lineDelimiter。支持多个字节, 例如’\x02\x03’。
必选:否
默认值:\n
-
loadProps
描述:StreamLoad 的请求参数,详情参照 StreamLoad 介绍页面。
必选:否
默认值:无
-
connectTimeout
描述:StreamLoad 单次请求的超时时间, 单位毫秒(ms)。
必选:否
默认值:-1
执行流程

-
解析配置,包括job.json、core.json、plugin.json三个配置
-
设置jobId到configuration当中
-
启动Engine,通过Engine.start()进入启动程序
-
设置RUNTIME_MODE到configuration当中
-
通过JobContainer的start()方法启动
-
依次执行job的preHandler()、init()、prepare()、split()、schedule()、- post()、postHandle()等方法:
-
init()方法涉及到根据configuration来初始化reader和writer插件,这里涉及到jar包热加载以及调用插件init()操作方法,同时设置reader和writer的configuration信息
-
prepare()方法涉及到初始化reader和writer插件的初始化,通过调用插件的prepare()方法实现,每个插件都有自己的jarLoader,通过集成URLClassloader实现而来
-
split()方法通过adjustChannelNumber()方法调整channel个数,同时执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,达到切分后数目相等,才能满足1:1的通道模型
channel的计数主要是根据byte和record的限速来实现的(如果自己没有设置了channel的个数),在split()的函数中第一步就是计算channel的大小。
split()方法reader插件会根据channel的值进行拆分,但是有些reader插件可能不会参考channel的值,例如mysql postgresql oracle 这种 task的数量=channel数*5+1,但是hdfsreader这种 设置channel数多少也不起作用;writer插件会完全根据reader的插件1:1进行返回(reader拆分传入的是needChannelNumber,writer拆分入参是taskNumber)。
split()方法内部的mergeReaderAndWriterTaskConfigs()负责合并reader、writer、以及transformer三者关系,生成task的配置,并且重写job.content的配置。
-
schedule()方法首先通过assignFairly()获得每个taskGroup需要运行哪些tasks任务,这里就是计算taskGroup有多少个task,其实就是:
(int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup)schdule()内部通过AbstractScheduler的schedule()执行,继续执行startAllTaskGroup()方法创建所有的TaskGroupContainer组织相关的task,TaskGroupContainerRunner负责运行TaskGroupContainer执行分配的task。
taskGroupContainerExecutorService启动固定的线程池用以执行TaskGroupContainerRunner对象,TaskGroupContainerRunner的run()方法调用taskGroupContainer.start()方法,针对每个channel创建一个TaskExecutor,通过taskExecutor.doStart()启动任务。
-
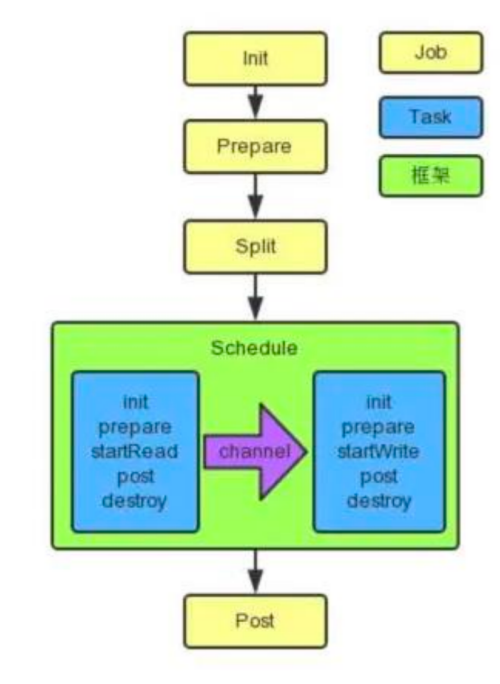
- 黄色: Job 部分的执行阶段,
- 蓝色: Task 部分的执行阶段,
- 绿色:框架执行阶段。
源码解析
程序入口
datax.py:
……
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params}
com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (
DEFAULT_PROPERTY_CONF, CLASS_PATH)
……
Engine.java
public void start(Configuration allConf) {
//……
int channelNumber =0;
AbstractContainer container;
long instanceId;
int taskGroupId = -1;
if (isJob) {
allConf.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE,
RUNTIME_MODE);
container = new JobContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID, 0);
} else {
container = new TaskGroupContainer(allConf);
instanceId = allConf.getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
taskGroupId = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID);
channelNumber = allConf.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL);
}
//……
container.start();
}
JobContainer.java
/**
* jobContainer 主要负责的工作全部在 start()里面,包括 init、prepare、split、 scheduler、
* post 以及 destroy 和 statistics
*/
@Override
public void start() {
LOG.info("DataX jobContainer starts job.");
boolean hasException = false;
boolean isDryRun = false;
try {
this.startTimeStamp = System.currentTimeMillis();
isDryRun =
configuration.getBool(CoreConstant.DATAX_JOB_SETTING_DRYRUN, false);
if(isDryRun) {
LOG.info("jobContainer starts to do preCheck ...");
this.preCheck();
} else {
userConf = configuration.clone();
LOG.debug("jobContainer starts to do preHandle ...");
//Job 前置操作
this.preHandle();
LOG.debug("jobContainer starts to do init ...");
//初始化 reader 和 writer
this.init();
LOG.info("jobContainer starts to do prepare ...");
//全局准备工作,比如 odpswriter 清空目标表
this.prepare();
LOG.info("jobContainer starts to do split ...");
//拆分 Task
this.totalStage = this.split();
LOG.info("jobContainer starts to do schedule ...");
this.schedule();
LOG.debug("jobContainer starts to do post ...");
this.post();
LOG.debug("jobContainer starts to do postHandle ...");
this.postHandle();
LOG.info("DataX jobId [{}] completed successfully.", this.jobId);
this.invokeHooks();
}
} ……
}
Task 切分逻辑
JobContainer.java
private int split() {
this.adjustChannelNumber(); //确认并发数
if (this.needChannelNumber <= 0) {
this.needChannelNumber = 1;
}
List<Configuration> readerTaskConfigs = this
.doReaderSplit(this.needChannelNumber);
int taskNumber = readerTaskConfigs.size();
List<Configuration> writerTaskConfigs = this
.doWriterSplit(taskNumber);
List<Configuration> transformerList =
this.configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT_TRANSF
ORMER);
LOG.debug("transformer configuration: "+ JSON.toJSONString(transformerList));
/**
* 输入是 reader 和 writer 的 parameter list,输出是 content 下面元素的 list
*/
List<Configuration> contentConfig = mergeReaderAndWriterTaskConfigs(
readerTaskConfigs, writerTaskConfigs, transformerList);
LOG.debug("contentConfig configuration: "+
JSON.toJSONString(contentConfig));
this.configuration.set(CoreConstant.DATAX_JOB_CONTENT, contentConfig);
return contentConfig.size();
}
split()方法通过adjustChannelNumber()方法调整channel个数,同时执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,达到切分后数目相等,才能满足1:1的通道模型
channel的计数主要是根据byte和record的限速来实现的(如果自己没有设置了channel的个数),在split()的函数中第一步就是计算channel的大小。
split()方法reader插件会根据channel的值进行拆分,但是有些reader插件可能不会参考channel的值,例如mysql postgresql oracle 这种 task的数量=channel数*5+1,但是hdfsreader这种 设置channel数多少也不起作用;writer插件会完全根据reader的插件1:1进行返回(reader拆分传入的是needChannelNumber,writer拆分入参是taskNumber)。
split()方法内部的mergeReaderAndWriterTaskConfigs()负责合并reader、writer、以及transformer三者关系,生成task的配置,并且重写job.content的配置。
并发数确认,Channel并发有三种配置方式:
- 配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速
- 配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速
- 直接配置Channel个数.
private void adjustChannelNumber() {
int needChannelNumberByByte = Integer.MAX_VALUE;
int needChannelNumberByRecord = Integer.MAX_VALUE;
boolean isByteLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 0) > 0);
if (isByteLimit) {
long globalLimitedByteSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_BYTE, 10 * 1024 * 1024);
// 在 byte 流控情况下,单个 Channel 流量最大值必须设置,否则报错!
Long channelLimitedByteSpeed = this.configuration
.getLong(CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_BYTE);
if (channelLimitedByteSpeed == null || channelLimitedByteSpeed <= 0) {
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,"在有总 bps 限速条件下,单个 channel 的 bps 值不能为空,也不能为非正数");
}
needChannelNumberByByte =
(int) (globalLimitedByteSpeed / channelLimitedByteSpeed);
needChannelNumberByByte =
needChannelNumberByByte > 0 ? needChannelNumberByByte : 1;
LOG.info("Job set Max-Byte-Speed to " + globalLimitedByteSpeed + " bytes.");
}
boolean isRecordLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD, 0)) > 0;
if (isRecordLimit) {
long globalLimitedRecordSpeed = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_RECORD,
100000);
Long channelLimitedRecordSpeed = this.configuration.getLong(
CoreConstant.DATAX_CORE_TRANSPORT_CHANNEL_SPEED_RECORD);
if (channelLimitedRecordSpeed == null || channelLimitedRecordSpeed <= 0)
{
throw
DataXException.asDataXException(FrameworkErrorCode.CONFIG_ERROR,
"在有总 tps 限速条件下,单个 channel 的 tps 值不能为空,也不能为非正数");
}
needChannelNumberByRecord =
(int) (globalLimitedRecordSpeed / channelLimitedRecordSpeed);
needChannelNumberByRecord =
needChannelNumberByRecord > 0 ?
needChannelNumberByRecord : 1;
LOG.info("Job set Max-Record-Speed to " + globalLimitedRecordSpeed + " records.");
}
// 取较小值
this.needChannelNumber = needChannelNumberByByte <
needChannelNumberByRecord ?
needChannelNumberByByte : needChannelNumberByRecord;
// 如果从 byte 或 record 上设置了 needChannelNumber 则退出
if (this.needChannelNumber < Integer.MAX_VALUE) {
return;
}
boolean isChannelLimit = (this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL, 0) > 0);
if (isChannelLimit) {
this.needChannelNumber = this.configuration.getInt(
CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);
LOG.info("Job set Channel-Number to " + this.needChannelNumber
+ " channels.");
return;
}
throw DataXException.asDataXException(
FrameworkErrorCode.CONFIG_ERROR,
"Job 运行速度必须设置");
}
调度
JobContainer.java
private void schedule() {
/**
* 这里的全局 speed 和每个 channel 的速度设置为 B/s
*/
int channelsPerTaskGroup = this.configuration.getInt(
CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_CHANNEL, 5);
//这个获取的json里的job.content 的个数,比如split里已经set了51个task 这里=51
int taskNumber = this.configuration.getList(
CoreConstant.DATAX_JOB_CONTENT).size();
//确定的 channel 数和切分的 task 数取最小值,避免浪费,比如needChannelNumber=10 taskNumber=51 所以这里=10
this.needChannelNumber = Math.min(this.needChannelNumber, taskNumber);
PerfTrace.getInstance().setChannelNumber(needChannelNumber);
/**
* 通过获取配置信息得到每个taskGroup需要运行哪些tasks任务
*/
//这里就是计算taskGroup有多少个task 其实就是(int) Math.ceil(1.0 * 10/ 5)=2;
//其实这里面很复杂,写这个方法的人考虑到不同的reader,比如mysql的task1和oracle的task1总不能放到一个group里把。所以简单的来看就是 channels/ 5 向上取整。
//然后将task组装放到了taskGroup里,此时就是2个group 一个有25个task 一个有26个task
//同时还将channel数也拆分了 每个group 有5个channel
List<Configuration> taskGroupConfigs =
JobAssignUtil.assignFairly(this.configuration,
this.needChannelNumber, channelsPerTaskGroup);
LOG.info("Scheduler starts [{}] taskGroups.", taskGroupConfigs.size());
ExecuteMode executeMode = null;
AbstractScheduler scheduler;
try {
//可以看到 3.0 进行了阉割,只有 STANDALONE 模式
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
//设置 executeMode
for (Configuration taskGroupConfig : taskGroupConfigs) {
taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE,
executeMode.getValue());
}
if (executeMode == ExecuteMode.LOCAL || executeMode ==
ExecuteMode.DISTRIBUTE) {
if (this.jobId <= 0) {
throw
DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,
"在[ local | distribute ]模式下必须设置 jobId,并且其值 > 0 .");
}
}
LOG.info("Running by {} Mode.", executeMode);
this.startTransferTimeStamp = System.currentTimeMillis();
//执行
scheduler.schedule(taskGroupConfigs);
this.endTransferTimeStamp = System.currentTimeMillis();
} catch (Exception e) {
LOG.error("运行 scheduler 模式[{}]出错.", executeMode);
this.endTransferTimeStamp = System.currentTimeMillis();
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
/**
* 检查任务执行情况
*/
this.checkLimit();
}
-
schedule()方法首先通过assignFairly()获得每个taskGroup需要运行哪些tasks任务,这里就是计算taskGroup有多少个task,其实就是:
(int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup) -
schdule()内部通过AbstractScheduler的schedule()执行,继续执行startAllTaskGroup()方法创建所有的TaskGroupContainer组织相关的task,TaskGroupContainerRunner负责运行TaskGroupContainer执行分配的task。
-
taskGroupContainerExecutorService启动固定的线程池用以执行TaskGroupContainerRunner对象,TaskGroupContainerRunner的run()方法调用taskGroupContainer.start()方法,针对每个channel创建一个TaskExecutor,通过taskExecutor.doStart()启动任务。
assignFairly 方法:
public static List<Configuration> assignFairly(Configuration configuration, int
channelNumber, int channelsPerTaskGroup) {
Validate.isTrue(configuration != null, "框架获得的 Job 不能为 null.");
List<Configuration> contentConfig =
configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);
Validate.isTrue(contentConfig.size() > 0, "框架获得的切分后的 Job 无内容.");
Validate.isTrue(channelNumber > 0 && channelsPerTaskGroup > 0,
"每个 channel 的平均 task 数[averTaskPerChannel],channel 数目[channelNumber],每个 taskGroup 的平均 channel 数[channelsPerTaskGroup]都应该为正数");
//TODO 确定 taskgroup 的数量
int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber /
channelsPerTaskGroup);
Configuration aTaskConfig = contentConfig.get(0);
String readerResourceMark =
aTaskConfig.getString(CoreConstant.JOB_READER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK);
String writerResourceMark =
aTaskConfig.getString(CoreConstant.JOB_WRITER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK);
boolean hasLoadBalanceResourceMark =
StringUtils.isNotBlank(readerResourceMark) ||
StringUtils.isNotBlank(writerResourceMark);
if (!hasLoadBalanceResourceMark) {
// fake 一个固定的 key 作为资源标识(在 reader 或者 writer 上均可,此处选择在 reader 上进行 fake)
for (Configuration conf : contentConfig) {
conf.set(CoreConstant.JOB_READER_PARAMETER + "." +
CommonConstant.LOAD_BALANCE_RESOURCE_MARK,
"aFakeResourceMarkForLoadBalance");
}
// 是为了避免某些插件没有设置 资源标识 而进行了一次随机打乱操作
Collections.shuffle(contentConfig, new
Random(System.currentTimeMillis()));
}
LinkedHashMap<String, List<Integer>> resourceMarkAndTaskIdMap =
parseAndGetResourceMarkAndTaskIdMap(contentConfig);
List<Configuration> taskGroupConfig = doAssign(resourceMarkAndTaskIdMap,
configuration, taskGroupNumber);
// 调整 每个 taskGroup 对应的 Channel 个数(属于优化范畴)
adjustChannelNumPerTaskGroup(taskGroupConfig, channelNumber);
return taskGroupConfig;
}
AbstractScheduler.java:
public void schedule(List<Configuration> configurations) {
Validate.notNull(configurations,"scheduler 配置不能为空");
int jobReportIntervalInMillSec = configurations.get(0).getInt(
CoreConstant.DATAX_CORE_CONTAINER_JOB_REPORTINTERVAL, 30000);
int jobSleepIntervalInMillSec = configurations.get(0).getInt(
CoreConstant.DATAX_CORE_CONTAINER_JOB_SLEEPINTERVAL,
10000);
this.jobId = configurations.get(0).getLong(
CoreConstant.DATAX_CORE_CONTAINER_JOB_ID);
errorLimit = new ErrorRecordChecker(configurations.get(0));
/**
* 给 taskGroupContainer 的 Communication 注册
*/
this.containerCommunicator.registerCommunication(configurations);
int totalTasks = calculateTaskCount(configurations);
//创建
startAllTaskGroup(configurations);
Communication lastJobContainerCommunication = new Communication();
long lastReportTimeStamp = System.currentTimeMillis();
try {
while (true) {
/**
* step 1: collect job stat
* step 2: getReport info, then report it
* step 3: errorLimit do check
* step 4: dealSucceedStat();
* step 5: dealKillingStat();
* step 6: dealFailedStat();
* step 7: refresh last job stat, and then sleep for next while
*
* above steps, some ones should report info to DS
*
*/
……
}
}
……
}
ProcessInnerScheduler.java:
public void startAllTaskGroup(List<Configuration> configurations) {
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
//创建所有的taskGroupContainerRunner,负责运行taskGroupContainer执行分配的task
//taskGroupContainerExecutorService启动固定的线程池用以执行TaskGroupContainerRunner对象,TaskGroupContainerRunner的run()方法调用taskGroupContainer.start()方法,针对每个channel创建一个TaskExecutor,通过taskExecutor.doStart()启动任务
for (Configuration taskGroupConfiguration : configurations) {
TaskGroupContainerRunner taskGroupContainerRunner =
newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
this.taskGroupContainerExecutorService.shutdown();
}
数据传输
TaskGroupContainer.start()-> taskExecutor.doStart(),可以看到调用插件的 start 方法
public void doStart() {
this.writerThread.start();
// reader 没有起来,writer 不可能结束
if (!this.writerThread.isAlive() || this.taskCommunication.getState() == State.FAILED) {
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR,
this.taskCommunication.getThrowable());
}
this.readerThread.start();
……
}
ReaderRunner.java:
public void run() {
//……
try {
channelWaitWrite.start();
//……
initPerfRecord.start();
taskReader.init();
initPerfRecord.end();
//……
preparePerfRecord.start();
taskReader.prepare();
preparePerfRecord.end();
//……
dataPerfRecord.start();
taskReader.startRead(recordSender);
recordSender.terminate();
//……
postPerfRecord.start();
taskReader.post();
postPerfRecord.end();
// automatic flush
// super.markSuccess(); 这里不能标记为成功,成功的标志由writerRunner 来标志(否则可能导致 reader 先结束,而 writer 还没有结束的严重bug)
} catch (Throwable e) {
LOG.error("Reader runner Received Exceptions:", e);
super.markFail(e);
} finally {
LOG.debug("task reader starts to do destroy ...");
PerfRecord desPerfRecord = new PerfRecord(getTaskGroupId(), getTaskId(),
PerfRecord.PHASE.READ_TASK_DESTROY);
desPerfRecord.start();
super.destroy();
desPerfRecord.end();
channelWaitWrite.end(super.getRunnerCommunication().getLongCounter(CommunicationTo
ol.WAIT_WRITER_TIME));
long transformerUsedTime =
super.getRunnerCommunication().getLongCounter(CommunicationTool.TRANSFORMER_
USED_TIME);
if (transformerUsedTime > 0) {
PerfRecord transformerRecord = new PerfRecord(getTaskGroupId(),
getTaskId(), PerfRecord.PHASE.TRANSFORMER_TIME);
transformerRecord.start();
transformerRecord.end(transformerUsedTime);
}
}
}
限速的实现
比如看 MysqlReader 的 startReader 方法-》CommonRdbmsReaderTask.startRead() -》transportOneRecord() -》sendToWriter() -》BufferedRecordExchanger. flush()-》Channel.pushAll() -》Channel. statPush()
private void statPush(long recordSize, long byteSize) {
currentCommunication.increaseCounter(CommunicationTool.READ_SUCCEED_RECORDS,recordSize);
currentCommunication.increaseCounter(CommunicationTool.READ_SUCCEED_BYTES,byteSize);
//在读的时候进行统计 waitCounter 即可,因为写(pull)的时候可能正在阻塞,但读的时候已经能读到这个阻塞的 counter 数
currentCommunication.setLongCounter(CommunicationTool.WAIT_READER_TIME,
waitReaderTime);
currentCommunication.setLongCounter(CommunicationTool.WAIT_WRITER_TIME,
waitWriterTime);
boolean isChannelByteSpeedLimit = (this.byteSpeed > 0);
boolean isChannelRecordSpeedLimit = (this.recordSpeed > 0);
if (!isChannelByteSpeedLimit && !isChannelRecordSpeedLimit) {
return;
}
long lastTimestamp = lastCommunication.getTimestamp();
long nowTimestamp = System.currentTimeMillis();
long interval = nowTimestamp - lastTimestamp;
if (interval - this.flowControlInterval >= 0) {
long byteLimitSleepTime = 0;
long recordLimitSleepTime = 0;
if (isChannelByteSpeedLimit) {
long currentByteSpeed =
(CommunicationTool.getTotalReadBytes(currentCommunication) -
CommunicationTool.getTotalReadBytes(lastCommunication)) *
1000 / interval;
if (currentByteSpeed > this.byteSpeed) {
// 计算根据 byteLimit 得到的休眠时间
byteLimitSleepTime = currentByteSpeed * interval / this.byteSpeed
- interval;
}
}
if (isChannelRecordSpeedLimit) {
long currentRecordSpeed =
(CommunicationTool.getTotalReadRecords(currentCommunication) -
CommunicationTool.getTotalReadRecords(lastCommunication)) *
1000 / interval;
if (currentRecordSpeed > this.recordSpeed) {
// 计算根据 recordLimit 得到的休眠时间
recordLimitSleepTime = currentRecordSpeed * interval /
this.recordSpeed
- interval;
}
}
// 休眠时间取较大值
long sleepTime = byteLimitSleepTime < recordLimitSleepTime ?
recordLimitSleepTime : byteLimitSleepTime;
if (sleepTime > 0) {
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
……
} }
DataX 使用优化
- job.setting.speed.channel : channel 并发数
- job.setting.speed.record : 2 全局配置 channel 的 record 限速
- job.setting.speed.byte:全局配置 channel 的 byte 限速
- core.transport.channel.speed.record:单个 channel 的 record 限速
- core.transport.channel.speed.byte:单个 channel 的 byte 限速
(1)优化 1:提升每个 channel 的速度
在 DataX 内部对每个 Channel 会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是 1MB/s,可以根据具体硬件情况设置这个 byte 速度或者 record 速度,一般设置 byte 速度,比如:我们可以把单个 Channel 的速度上限配置为 5MB。
(2)优化 2:提升 DataX Job 内 Channel 并发数
并发数 = taskGroup 的数量 * 每个 TaskGroup 并发执行的 Task 数 (默认为 5)。提升 job 内 Channel 并发有三种配置方式:
-
配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速
{ "core": { "transport": { "channel": { "speed": { "byte": 1048576 } } } }, "job": { "setting": { "speed": { "byte" : 5242880 } }, //... } } -
配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速
{ "core": { "transport": { "channel": { "speed": { "record": 100 } } } }, "job": { "setting": { "speed": { "record" : 500 } }, //... } } -
直接配置Channel个数:
{ "job": { "setting": { "speed": { "channel" : 5 } }, //... } }只有在上面两种未设置才生效,上面两个同时设置是取值小的作为最终的 channel 数。
(3)提高 JVM 堆内存
当提升 DataX Job 内 Channel 并发数时,内存的占用会显著增加,因为 DataX 作为数据交换通道,在内存中会缓存较多的数据。例如 Channel 中会有一个 Buffer,作为临时的数据交换的缓冲区,而在部分 Reader 和 Writer 的中,也会存在一些 Buffer,为了防止 OOM 等错误,调大 JVM 的堆内存。
建议将内存设置为 4G 或者 8G,这个也可以根据实际情况来调整。调整 JVM xms xmx 参数的两种方式:一种是直接更改 datax.py 脚本;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json
Canal
介绍
阿里巴巴 B2B 公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了同步杭州和美国异地机房的需求,从 2010 年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
Canal 是用 Java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前。Canal 主要支持了 MySQL 的 Binlog 解析,解析完成后才利用 Canal Client 来处理获得的相关数据。(数据库同步需要阿里的 Otter 中间件,基于 Canal)。
原理
MySQL 主从复制过程:
- Master 主库将改变记录,写到二进制日志(Binary Log)中;
- Slave 从库向 MySQL Master 发送 dump 协议,将 Master 主库的 binary log events 拷贝到它的中继日志(relay log);
- Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库。

Canal 的工作原理:很简单,就是把自己伪装成 Slave,假装从 Master 复制数据。
- 模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议;
- mysql master收到dump请求,开始推送binary log给slave(也就是canal);
- 解析binary log对象(原始为byte流)
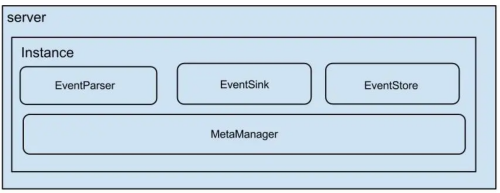
- server代表一个canal运行实例,对应与一个jvm;
- instance对应于一个数据队列(1个server对应1…n个instance).
instance下的子模块:
- eventParser: 数据源接入,模拟slave协议和master进行交互,协议解析;
- eventSink: parser和store链接器,进行数据的过滤,加工和分发工作;
- eventStore: 数据存储;
- metaManager: 增量订阅&消费信息管理器.
EventParser
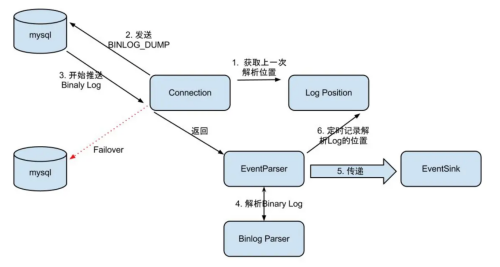
整个parser过程大致可分为几部:
- Connection获取上一次解析成功的位置(如果第一次启动,则获取初始制定的位置或者是当前数据库的binlog位点);
- Connection建立连接,发生BINLOG_DUMP命令
- Mysql开始推送Binary Log;
- 接收到的Binary Log通过Binlog parser进行协议解析,补充一些特定信息;
- 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功;
- 存储成功后,定时记录Binary Log位置。
EventSink
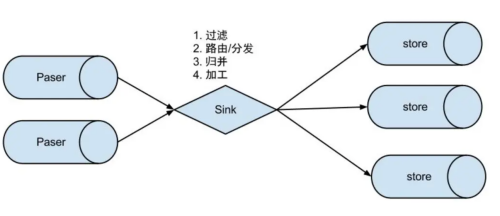
- 数据过滤:支持通配符的过滤模式,表名,字段内容等;
- 数据路由/分发:解决1:n (1个parser对应多个store的模式);
- 数据归并:解决n:1 (多个parser对应1个store);
- 数据加工:在进入store之前进行额外的处理,比如join。
EventStore设计
目前canal实现了memory内存、本地file存储以及持久化到zookeeper以保障数据集群共享。memory内存的RingBuffer设计如下图:

定义了3个cursor:
- Put : Sink模块进行数据存储的最后一次写入位置
- Get : 数据订阅获取的最后一次提取位置
- Ack : 数据消费成功的最后一次消费位置
增量订阅、消费设计

get/ack/rollback协议介绍:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id(唯一标识)和entries(具体的数据对象),具体格式后面会进行介绍。
- void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作;
- void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
- canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
- get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能);
- get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化.
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [发生的变更]
schemaName
tableName
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组]
Column
index
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
HA机制设计
Canal的部署也是支持集群的,需要配合ZooKeeper进行集群管理。
canal的HA机制主要是依赖zookeeper的特性,共分为canal server和canal client两部分:
- canal server:为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
- canal client:为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序.
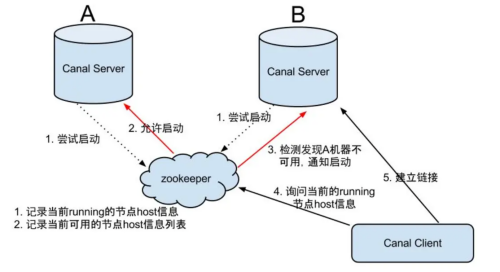
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.
- Canal Client的方式和canal server方式类似,也是利用zokeeper的抢占EPHEMERAL节点的方式进行控制.
使用场景
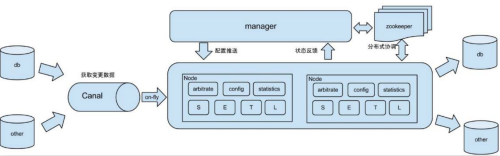
-
原始场景: 阿里 Otter 中间件的一部分
Otter 是阿里用于进行异地数据库之间的同步框架,Canal 是其中一部分。
-
常见场景 1:更新缓存

-
常见场景 2:抓取业务表的新增变化数据,用于制作实时统计(我们就是这种场景)
安装
下载并解压 Jar 包:https://github.com/alibaba/canal/releases
我们直接/2.资料下的 canal.deployer-1.1.2.tar.gz 拷贝到/opt/sortware 目录下,然后解压到/opt/module/canal 包下。
注意:canal 解压后是分散的,我们在指定解压目录的时候需要将 canal 指定上。
mkdir /opt/module/canal
tar -zxvf canal.deployer-1.1.2.tar.gz -C /opt/module/canal
修改 canal.properties 的配置:
vim canal.properties
#################################################
######### common argument #############
#################################################
canal.id = 1
canal.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
说明:这个文件是 canal 的基本通用配置,canal 端口号默认就是 11111,修改 canal 的输出 model,默认 tcp,改为输出到 kafka
多实例配置如果创建多个实例,通过前面 canal 架构,我们可以知道,一个 canal 服务中可以有多个 instance,conf/下的每一个 example 即是一个实例,每个实例下面都有独立的配置文件。默认只有一个实例 example,如果需要多个实例处理不同的 MySQL 数据的话,直接拷贝出多个 example,并对其重新命名,命名和配置文件中指定的名称一致,然后修改canal.properties 中的 canal.destinations=实例 1,实例 2,实例 3。
#################################################
######### destinations #############
#################################################
canal.destinations = example
修改 instance.properties:
我们这里只读取一个 MySQL 数据,所以只有一个实例,这个实例的配置文件在conf/example 目录下:
vim instance.properties
-
配置 MySQL 服务器地址
################################################# ## mysql serverId , v1.0.26+ will autoGen canal.instance.mysql.slaveId=20 # enable gtid use true/false canal.instance.gtidon=false # position info canal.instance.master.address=hadoop102:3306 -
配置连接 MySQL 的用户名和密码,默认就是我们前面授权的 canal
# username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 canal.instance.defaultDatabaseName =test # enable druid Decrypt database password canal.instance.enableDruid=false
TCP 模式测试
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
</dependencies>
(1)通用监视类 –CanalClient
Canal 封装的数据结构:

import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.atguigu.constants.GmallConstants;
import com.atguigu.utils.MyKafkaSender;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.Random;
public class CanalClient {
public static void main(String[] args) throws
InvalidProtocolBufferException {
//1.获取 canal 连接对象
CanalConnector canalConnector =
CanalConnectors.newSingleConnector(new InetSocketAddress("hadoop102", 11111), "example", "", "");
while (true) {
//2.获取连接
canalConnector.connect();
//3.指定要监控的数据库
canalConnector.subscribe("gmall.*");
//4.获取 Message
Message message = canalConnector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
System.out.println("没有数据,休息一会");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
for (CanalEntry.Entry entry : entries) {
//TODO 获取表名
String tableName =
entry.getHeader().getTableName();
// TODO Entry 类型
CanalEntry.EntryType entryType =
entry.getEntryType();
// TODO 判断 entryType 是否为 ROWDATA
if
(CanalEntry.EntryType.ROWDATA.equals(entryType)) {
// TODO 序列化数据
ByteString storeValue = entry.getStoreValue();
// TODO 反序列化
CanalEntry.RowChange rowChange =
CanalEntry.RowChange.parseFrom(storeValue);
//TODO 获取事件类型
CanalEntry.EventType eventType =
rowChange.getEventType();
//TODO 获取具体的数据
List<CanalEntry.RowData> rowDatasList =
rowChange.getRowDatasList();
//TODO 遍历并打印数据
for (CanalEntry.RowData rowData : rowDatasList)
{
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
JSONObject beforeData = new JSONObject();
for (CanalEntry.Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<CanalEntry.Column> afterColumnsList =
rowData.getAfterColumnsList();
for (CanalEntry.Column column :
afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
System.out.println("TableName:" + tableName
+
",EventType:" + eventType +
",After:" + beforeData +
",After:" + afterData);
}
}
}
}
}
} }
Kafka 模式测试
(1)修改 canal.properties 中 canal 的输出 model,默认 tcp,改为输出到 kafka
#################################################
######### common argument #############
#################################################
canal.id = 1
canal.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
(2)修改 Kafka 集群的地址:
##################################################
######### MQ #############
##################################################
canal.mq.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
(3)修改 instance.properties 输出到 Kafka 的主题以及分区数:
# mq config
canal.mq.topic=canal_test
canal.mq.partitionsNum=1
# hash partition config
#canal.mq.partition=0
#canal.mq.partitionHash=mytest.person:id,mytest.role:id
注意:默认还是输出到指定 Kafka 主题的一个 kafka 分区,因为多个分区并行可能会打乱 binlog 的顺序 , 如 果 要 提 高 并 行 度 , 首 先 设 置 kafka 的 分 区 数 >1, 然 后 设 置canal.mq.partitionHash 属性。
(4)启动 Canal:
cd /opt/module/canal/
bin/startup.sh
(5)看到 CanalLauncher 你表示启动成功,同时会创建 canal_test 主题
jps
2269 Jps
2253 CanalLauncher
(6)启动 Kafka 消费客户端测试,查看消费情况
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic canal_test
(7)向 MySQL 中插入数据后查看消费者控制台
插入数据:
INSERT INTO user_info VALUES('1001','zhangsan','male'),('1002','lisi','female');
Kafka 消费者控制台:
{"data":[{"id":"1001","name":"zhangsan","sex":"male"},{"id":"1002","name":"lisi","sex":"female"}],"database":"gmall-2021","es":1639360729000,"id":1,"isDdl":false,"mysqlType":{"id":"varchar(255)","name":"varchar(255)","sex":"varchar(255)"},"old":null,"sql":"","sqlType":{"id":12,"name":12,"sex":12},"table":"user_info","ts":1639361038454,"type":"INSERT"}
MaxWell
介绍
MaxwelQ是由美国Zendesk开源,使用Java编写的MysQL实时抓取工具,可以实时读取MysQL二进制日志binlog,并生成 JSON 格式
的消息,作为生产者发送给 Kalka, Kinesis、 RabbitMQ、 Redis、 Google Cloud Pub/Sub、文件或其它平台的应用程序。它设计的初衷是实时采集Mysql数据到Kafka。支持全表load数据,支持自动断点还原,支持按照列将数据发送到Kafka不同分区。
Maxwel/工作原理与 Canal工作原理一样,都是把自己伪装成MySQL gslave从库,同步binlog数据,来达到同步MysQL数据,与Canal
相比,更加轻量。同样使用Maxwell也需要开启MySQL binlog日志。Maxwell要求Binlog采用Row-based模式。
安装和增量同步
(1)下载Maxwell (https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz)
(2)解压安装到指定目录
tar -zxvf maxwell-1.29.2.tar.gz -C /opt/module/
(3)切换至Maxwell目录并修改Maxwell配置文件名称
cp config.properties.example config.properties
(4)修改Maxwell配置文件config.properties
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
#目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=maxwell
#MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
(5)依次启动hadoop集群、zookeeper、kafka
(6)启动maxwell
启动前先在kafka中创建好maxwell主题,否则会报错。可以在日志文件中查看。
/opt/module/maxwell/bin/maxwell --config /opt/module/maxwell/config.properties --daemon
(7)停止maxwell
ps -ef | grep maxwell | grep -v grep | grep maxwell | awk '{print $2}' | xargs kill -9
(8)启动 Kafka 消费客户端测试,查看消费情况
kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic maxwell
全量同步
我们在进行增量同步之前,先进行一次历史数据的全量同步。这样就能保证得到一个完整的数据集。Maxwell提供了bootstrap功能来进行历史数据的全量同步。
/opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/module/maxwell/config.properties
bootstrap数据格式:
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-start",
"ts": 1450557744,
"data": {}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-insert",
"ts": 1450557744,
"data": {
"txt": "hello"
}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-insert",
"ts": 1450557744,
"data": {
"txt": "bootstrap!"
}
}
{
"database": "fooDB",
"table": "barTable",
"type": "bootstrap-complete",
"ts": 1450557744,
"data": {}
}
- 第一条type为bootstrap-start和最后一条type为bootstrap-complete的数据,是bootstrap开始和结束的标志,不包含数据,中间的type为bootstrap-insert的数据才包含数据。
- 一次bootstrap输出的所有记录的ts都相同,为bootstrap开始的时间。
Flink CDC
简介
介绍
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
Flink-CDC
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。
目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors
Flink CDC Connector 是ApacheFlink的一组数据源连接器,CDC(变化数据捕获 change data capture)用于捕捉数据库表的增删改查操作,可以从 MySQL、PostgreSQL 数据直接读取全量数据和增量数据的 Source Connectors,是目前非常成熟的同步数据库变更方案。
Flink CDC 支持全增量一体化同步,为用户提供实时一致性快照。比如一张表里有历史的全量数据,也有新增的实时变更数据,增量数据不断地往 Binlog 日志文件里写,Flink CDC 会先同步全量历史数据,再无缝切换到同步增量数据,增量同步时,如果是新增的插入数据(上图中蓝色小块),会追加到实时一致性快照中;如果是更新的数据(上图中黄色小块),则会在已有历史数据里做更新。
Flink CDC连接器将Debezium集成为引擎来捕获数据变更。因此,它可以充分利用Debezium的功能,利用其抽取日志获取变更的能力,将 changelog 转换为 Flink SQL 认识的 RowData 数据。(以下右侧是 Debezium 的数据格式,左侧是 Flink 的 RowData 数据格式)

RowData 代表了一行的数据,在 RowData 上面会有一个元数据的信息 RowKind,RowKind 里面包括了插入(+I)、更新前(-U)、更新后(+U)、删除(-D),这样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的数据,包含了旧数据(before)和新数据行(after)以及原数据信息(source),op 的 u 表示是 update 更新操作标识符(op 字段的值 c,u,d,r 分别对应 create,update,delete,reade),ts_ms 表示同步的时间戳。
特点:
- 支持读取数据库快照,并且能够持续读取数据库的变更日志,即使发生故障,也支持exactly-once 的处理语义
- 对于DataStream API的CDC connector,用户无需部署Debezium和Kafka,即可在单个作业中使用多个数据库和表上的变更数据。
- 对于Table/SQL API 的CDC connector,用户可以使用SQL DDL创建CDC数据源,来监视单个表上的数据变更。
使用场景:
- 数据库之间的增量数据同步
- 审计日志
- 数据库之上的实时物化视图
- 基于CDC的维表join
- …
三种数据同步方案:
(1)方案一:Debezium+Kafka+计算程序+存储系统
采用 Debezium 订阅 MySQL 的 Binlog 传输到 Kafka,后端是由计算程序从 Kafka 里消费,最后将数据写入到其他存储,架构类似如下:
这种方案中利用 Kafka 消息队列做解耦,Change Log 可供任何其他业务系统使用,消费端可采用 Kafka Sink Connector 或者自定义消费程序,但是由于原生 Debezium 中的 Producer 端未采用幂等特性,因此消息可能存在重复,另外 Kafka Sink Connector(比如 JDBC Sink Connector 只能保证 At least once)或者自定义消费程序在保证数据的一致性上也有难度。
(2)方案二:Debezium+Kafka+Flink SQL+存储系统
我们知道 Flink SQL 具备解析 Kafka 中 debezium-json 和 canal-json 格式的 Change Log 能力,我们可以采用如下同步架构:
与方案一的区别就是,采用 Flink 通过创建 Kafka 表,指定 format 格式为 debezium-json,然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统。方案二和方案一类似,组件多维护繁杂,而前述我们知道 Flink 1.11 中 CDC Connectors 内置了 Debezium 引擎,可以替换 Debezium+Kafka 方案,因此有了更简化的方案三。
(3)方案三:Flink SQL CDC + JDBC Connector
从官方的描述中,通过 Flink CDC connectors 替换 Debezium+Kafka 的数据采集模块,实现 Flink SQL 采集+计算+传输(ETL)一体化,优点很多:
- 开箱即用,简单易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯
Flink CDC 案例实操
DataStream 方式的应用
(1)导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)编写代码
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Properties;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点续传,需要从 Checkpoint 或者 Savepoint 启动程序
//2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次 CK 数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckp
ointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从 CK 自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
//2.5 设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC"));
//2.6 设置访问 HDFS 的用户名
System.setProperty("HADOOP_USER_NAME", "atguigu");
//3.创建 Flink-MySQL-CDC 的 Source
//initial (default): Performs an initial snapshot on the monitored database tables upon first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first startup, just read from the end of the binlog which means only have the changes since the connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified timestamp. The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon first startup, and directly read binlog from the specified offset.
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-flink")
.tableList("gmall-flink.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
.deserializer(new StringDebeziumDeserializationSchema())
.build();
//4.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//5.打印数据
mysqlDS.print();
//6.执行任务
env.execute();
}
}
(3)测试
-
打包并上传至 Linux
-
开启 MySQL Binlog 并重启 MySQL
-
启动 Flink 集群
bin/start-cluster.sh -
启动 HDFS 集群
start-dfs.sh -
启动程序
bin/flink run -c com.atguigu.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar -
在 MySQL 的 gmall-flink.z_user_info 表中添加、修改或者删除数据
-
给当前的 Flink 程序创建 Savepoint
bin/flink savepoint JobId hdfs://hadoop102:8020/flink/save -
关闭程序以后从 Savepoint 重启程序
bin/flink run -s hdfs://hadoop102:8020/flink/save/... -c com.atguigu.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar
FlinkSQL 方式的应用
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkSQL_CDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info (" +
" id INT," +
" name STRING," +
" phone_num STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'hadoop102'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '000000'," +
" 'database-name' = 'gmall-flink'," +
" 'table-name' = 'z_user_info'" +
")");
tableEnv.executeSql("select * from user_info").print();
env.execute();
} }
自定义反序列化器
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.Properties;
public class Flink_CDCWithCustomerSchema {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.创建 Flink-MySQL-CDC 的 Source
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-flink")
.tableList("gmall-flink.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
.deserializer(new DebeziumDeserializationSchema<String>() { //自定义数据解析器
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String>
collector) throws Exception {
//获取主题信息,包含着数据库和表名
mysql_binlog_source.gmall-flink.z_user_info
String topic = sourceRecord.topic();
String[] arr = topic.split("\\.");
String db = arr[1];
String tableName = arr[2];
//获取操作类型 READ DELETE UPDATE CREATE
Envelope.Operation operation =
Envelope.operationFor(sourceRecord);
//获取值信息并转换为 Struct 类型
Struct value = (Struct) sourceRecord.value();
//获取变化后的数据
Struct after = value.getStruct("after");
//创建 JSON 对象用于存储数据信息
JSONObject data = new JSONObject();
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
//创建 JSON 对象用于封装最终返回值数据信息
JSONObject result = new JSONObject();
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
//发送数据至下游
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
//3.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//4.打印数据
mysqlDS.print();
//5.执行任务
env.execute();
}
}
Flink-CDC 2.0
Flink CDC 痛点
MySQL CDC 是 Flink CDC 中使用最多也是最重要的 Connector。
随着 Flink CDC 项目的发展,得到了很多用户在社区的反馈,主要归纳为三个:

- 全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。
- 不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
- 全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
Debezium 锁分析
Flink CDC 底层封装了 Debezium, Debezium 同步一张表分为两个阶段:
- **全量阶段:**查询当前表中所有记录;
- **增量阶段:**从 binlog 消费变更数据。
大部分用户使用的场景都是全量 + 增量同步,加锁是发生在全量阶段,目的是为了确定全量阶段的初始位点,保证增量 + 全量实现一条不多,一条不少,从而保证数据一致性。从下图中我们可以分析全局锁和表锁的一些加锁流程,左边红色线条是锁的生命周期,右边是 MySQL 开启可重复读事务的生命周期。

以全局锁为例,首先是获取一个锁,然后再去开启可重复读的事务。这里锁住操作是读取 binlog 的起始位置和当前表的 schema。这样做的目的是保证 binlog 的起始位置和读取到的当前 schema 是可以对应上的,因为表的 schema 是会改变的,比如如删除列或者增加列。在读取这两个信息后,SnapshotReader 会在可重复读事务里读取全量数据,在全量数据读取完成后,会启动 BinlogReader 从读取的 binlog 起始位置开始增量读取,从而保证全量数据 + 增量数据的无缝衔接。
表锁是全局锁的退化版,因为全局锁的权限会比较高,因此在某些场景,用户只有表锁。表锁锁的时间会更长,因为表锁有个特征:锁提前释放了可重复读的事务默认会提交,所以锁需要等到全量数据读完后才能释放。
经过上面分析,接下来看看这些锁到底会造成怎样严重的后果:

Flink CDC 1.x 可以不加锁,能够满足大部分场景,但牺牲了一定的数据准确性。Flink CDC 1.x 默认加全局锁,虽然能保证数据一致性,但存在上述 hang 住数据的风险。
Flink CDC 2.0 设计 ( 以 MySQL 为例)
通过上面的分析,可以知道 2.0 的设计方案,核心要解决上述的三个问题,即支持无锁、水平扩展、checkpoint。

DBlog 这篇论文里描述的无锁算法如下图所示:

左边是 Chunk 的切分算法描述,Chunk 的切分算法其实和很多数据库的分库分表原理类似,通过表的主键对表中的数据进行分片。假设每个 Chunk 的步长为 10,按照这个规则进行切分,只需要把这些 Chunk 的区间做成左开右闭或者左闭右开的区间,保证衔接后的区间能够等于表的主键区间即可。
右边是每个 Chunk 的无锁读算法描述,该算法的核心思想是在划分了 Chunk 后,对于每个 Chunk 的全量读取和增量读取,在不用锁的条件下完成一致性的合并。Chunk 的切分如下图所示:

因为每个 chunk 只负责自己主键范围内的数据,不难推导,只要能够保证每个 Chunk 读取的一致性,就能保证整张表读取的一致性,这便是无锁算法的基本原理。
Netflix 的 DBLog 论文中 Chunk 读取算法是通过在 DB 维护一张信号表,再通过信号表在 binlog 文件中打点,记录每个 chunk 读取前的 Low Position (低位点) 和读取结束之后 High Position (高位点) ,在低位点和高位点之间去查询该 Chunk 的全量数据。在读取出这一部分 Chunk 的数据之后,再将这 2 个位点之间的 binlog 增量数据合并到 chunk 所属的全量数据,从而得到高位点时刻,该 chunk 对应的全量数据。
Flink CDC 结合自身的情况,在 Chunk 读取算法上做了去信号表的改进,不需要额外维护信号表,通过直接读取 binlog 位点替代在 binlog 中做标记的功能,整体的 chunk 读算法描述如下图所示:

比如正在读取 Chunk-1,Chunk 的区间是 [K1, K10],首先直接将该区间内的数据 select 出来并把它存在 buffer 中,在 select 之前记录 binlog 的一个位点 (低位点),select 完成后记录 binlog 的一个位点 (高位点)。然后开始增量部分,消费从低位点到高位点的 binlog。
- 图中的 - ( k2,100 ) + ( k2,108 ) 记录表示这条数据的值从 100 更新到 108;
- 第二条记录是删除 k3;
- 第三条记录是更新 k2 为 119;
- 第四条记录是 k5 的数据由原来的 77 变更为 100。
观察图片中右下角最终的输出,会发现在消费该 chunk 的 binlog 时,出现的 key 是k2、k3、k5,我们前往 buffer 将这些 key 做标记。
- 对于 k1、k4、k6、k7 来说,在高位点读取完毕之后,这些记录没有变化过,所以这些数据是可以直接输出的;
- 对于改变过的数据,则需要将增量的数据合并到全量的数据中,只保留合并后的最终数据。例如,k2 最终的结果是 119 ,那么只需要输出 +(k2,119),而不需要中间发生过改变的数据。
通过这种方式,Chunk 最终的输出就是在高位点是 chunk 中最新的数据。
上图描述的是单个 Chunk 的一致性读,但是如果有多个表分了很多不同的 Chunk,且这些 Chunk 分发到了不同的 task 中,那么如何分发 Chunk 并保证全局一致性读呢?
这个就是基于 FLIP-27 来优雅地实现的,通过下图可以看到有 SourceEnumerator 的组件,这个组件主要用于 Chunk 的划分,划分好的 Chunk 会提供给下游的 SourceReader 去读取,通过把 chunk 分发给不同的 SourceReader 便实现了并发读取 Snapshot Chunk 的过程,同时基于 FLIP-27 我们能较为方便地做到 chunk 粒度的 checkpoint。
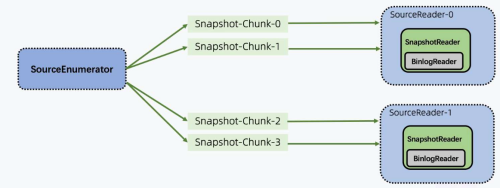
当 Snapshot Chunk 读取完成之后,需要有一个汇报的流程,如下图中橘色的汇报信息,将 Snapshot Chunk 完成信息汇报给 SourceEnumerator。
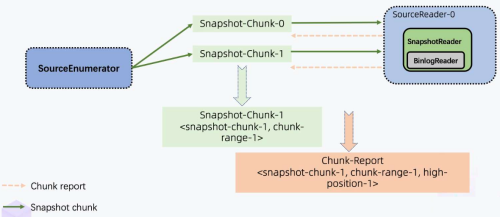
汇报的主要目的是为了后续分发 binlog chunk (如下图)。因为 Flink CDC 支持全量 + 增量同步,所以当所有 Snapshot Chunk 读取完成之后,还需要消费增量的 binlog,这是通过下发一个 binlog chunk 给任意一个 Source Reader 进行单并发读取实现的。

整体流程可以概括为,首先通过主键对表进行 Snapshot Chunk 划分,再将 Snapshot Chunk 分发给多个 SourceReader,每个 Snapshot Chunk 读取时通过算法实现无锁条件下的一致性读,SourceReader 读取时支持 chunk 粒度的 checkpoint,在所有 Snapshot Chunk 读取完成后,下发一个 binlog chunk 进行增量部分的 binlog 读取,这便是 Flink CDC 2.0 的整体流程,如下图所示:
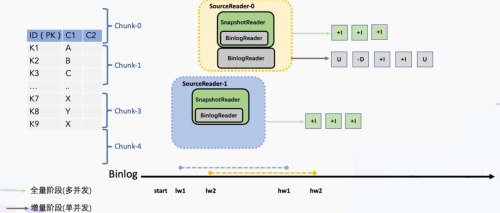
CDC 的种类
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:
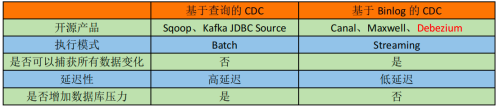
- 一类是基于查询的 CDC 技术 ,比如 DataX,Sqoop。随着当下场景对实时性要求越来越高,此类技术的缺陷也逐渐凸显。离线调度和批处理的模式导致延迟较高;基于离线调度做切片,因而无法保障数据的一致性;另外,也无法保障实时性。
- 一类是基于日志的 CDC 技术,比如 Debezium、Canal、 Flink CDC。这种 CDC 技术能够实时消费数据库的日志,流式处理的模式可以保障数据的一致性,提供实时的数据,可以满足当下越来越实时的业务需求。
对比
数据同步工具种类繁多,大致可分为两类,一类是以DataX、Sqoop为代表的基于Select查询的离线、批量同步工具,另一类是以Maxwell、Canal为代表的基于数据库数据变更日志(例如MySQL的binlog,其会实时记录所有的insert、update以及delete操作)的实时流式同步工具。
- 全量同步通常使用DataX、Sqoop等基于查询的离线同步工具。
- 而增量同步既可以使用DataX、Sqoop等工具,也可使用Maxwell、Canal等工具,cannal只支持mysql,下面对增量同步不同方案进行简要对比。

当然还有kettle和Nifi:
- Kettle:纯java编写,可以实现全量、增量数据同步。**缺点是通过定时运行,实时性相对较差。**通过图形界面设计实现做什么业务,无需写代码去实现。
- Nifi:为了自动化系统之间的数据流而构建的
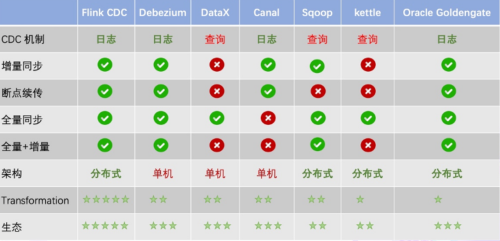
- 对比增量同步能力,
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查询的方式是很难做到增量同步的。
- 对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
- 而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
- 在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- 但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
- 另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
DataX VS Sqoop

-
由于RMDB和HDFS的局限,sqoop和DataX的数据格式仅支持SQL表和hdfs中的结构化数据。
-
sqoop只支持官方提供的指定几种关系型数据库和hadoop组件之间的数据交换,而在datax中,用户只需根据自身需求修改文件,生成相应rpm包,自行安装之后就可以使用自己定制的插件;
-
sqoop采用map-reduce计算框架进行导入导出,而datax仅仅在运行datax的单台机器上进行数据的抽取和加载,速度比sqoop慢了许多;
-
sqoop只可以在关系型数据库和hadoop组件之间进行数据迁移,而在hadoop相关组件之间,比如hive和hbase之间就无法使用。sqoop互相导入导出数据,同时在关系型数据库之间,比如mysql和oracle之间也无法通过sqoop导入导出数据。
与之相反,datax能够分别实现关系型数据库hadoop组件之间、关系型数据库之间、hadoop组件之间的数据迁移;
-
Sqoop是专门为hadoop而生,对hadoop支持度好,而datax可能会出现不支持高版本hadoop的现象;
Canal VS MaxWell
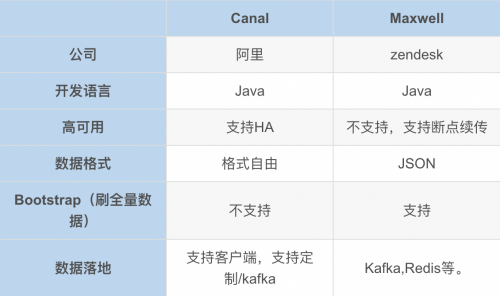
- Canal是阿里公司使用Java开发,Maxwell是zendesk公司使用Java开发。
- Canal支持高可用HA,支持断点续传。Maxwel不支持HA,但是支持断点续传,要想支持HA需要自己实现。
- canal上游只支持mysql(MariaDB)、下游支持的中间件可以定制,一般是kafka,Maxwell与canal一样上游只支持mysql,但是不可定制,只支持kafka等。
- Canal由于有Client消费数据,针对binlog数据可以使用Client自定义数据格式,Maxwell支持Json数据写出到Kafka或Redis。
- Canal只能获取MySQL最新数据,Maxwell支持Bootstrap,可以支持获取MySQL中历史数据。
- Canal采用Server+client模式,Maxwell没有采用这种模式,直接将数据发送到Kafka或者Redis等。
总体来看,MaxWell更加轻量。















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









