







文章目录
介绍
概述
Apache Superset是一个开源的、现代的、轻量级BI分析工具,由Python语言为主,能够对接多种数据源、拥有丰富的图表展示形式、支持自定义仪表盘,且拥有友好的用户界面,十分易用。
- 官网 :https://superset.apache.org/
- github :https://github.com/apache/superset
- 国内支持的镜像站 :阿里云:http://mirrors.aliyun.com/pypi/simple/、豆瓣:https://pypi.douban.com/simple/ 等
- 开发语言:Python为主
BI VS 报表工具
报表工具是数据展示工具,而BI(商业智能)是数据分析工具。
- 报表工具可以制作各类数据报表、图形报表的工具,甚至还可以制作电子发票联、流程单、收据等。
- BI可以将数据进行模型构建,制作成Dashboard,相比于报表,侧重点在于分析,操作简单、数据处理量大。常常基于企业搭建的数据平台,连接数据仓库进行分析。
应用场景
由于Superset能够对接常用的大数据分析工具,如Hive、Kylin、Druid等,且支持自定义仪表盘,故可作为数仓的可视化工具。


- 第一梯队:ClickHouse、DorisDB、Kylin等优秀OLAP技术做存储,利用自带的连接引擎,快速响应,同时支持实时数据和离线数据的接入,外接可视化平台,通过权限管控后呈现给用户;
- 第二梯队:数据存在数据仓库Hive内或者NoSQL的Hbase,再通过较为优秀且高效的引擎Presto、Flink、Spark等接入可视化平台,通过权限管控后呈现给用户;
- 剩下就是一个特殊的,如MySQL,临时文件等文件的接入;
注意:常用的也还有其它技术架构,如ELK架构,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索)。 kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
组成
Apache Superset使用层面主要分为以下个部分;
- Data:主要功能是新增数据源和数据集Dataset(旧版本也叫Table),Dataset作为数据图表可视化的基础;
- Charts:图表,就是针对准备好的Dataset数据集,选择一款合适的图表呈现;
- Dashboards:仪表盘,其实就是报表、看板大屏展示,可以将多个Charts组合到一个仪表盘内一起展示。
- SQL Lab:SQL实验室,其实就是一个类似DBeaver、Navicat、DataGrip等一样的多功能数据库连接客户端,但是只有查询功能,配置驱动和连接后可以进行数据库、表、字段等模型的SQL查询操作。
- 设置:语言选择,登录注销、人员权限,操作日志等设置;

优缺点
开源的可视化分析(BI)工具
优点:
- 开源免费
- 上手简单,易于使用的界面,用于浏览和可视化数据
- 创建和共享仪表板
- 可扩展的高粒度安全性/权限模型,允许有关谁可以访问单个要素和数据集的复杂规则
- 引入外部图表库
缺点:
- 功能不是特别全
- 对SQL支持不是特别友好完善
支持的数据库
superset现在支持的所有数据库或分析引擎:

| Database | PyPI package | Connection String |
|---|---|---|
| Amazon Athena | pip install "PyAthenaJDBC>1.0.9 , pip install "PyAthena>1.2.0 | awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{ |
| Amazon DynamoDB | pip install "PyDynamoDB>=0.4.2 | dynamodb://{access_key_id}:{secret_access_key}@dynamodb.{region_name}.amazonaws.com?connector=superset |
| Amazon Redshift | pip install sqlalchemy-redshift | redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name> |
| Apache Drill | pip install sqlalchemy-drill | drill+sadrill:// For JDBC drill+jdbc:// |
| Apache Druid | pip install pydruid | druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql |
| Apache Hive | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Apache Impala | pip install impyla | impala://{hostname}:{port}/{database} |
| Apache Kylin | pip install kylinpy | kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2> |
| Apache Pinot | pip install pinotdb | pinot://BROKER:5436/query?server=http://CONTROLLER:5983/ |
| Apache Solr | pip install sqlalchemy-solr | solr://{username}:{password}@{hostname}:{port}/{server_path}/{collection} |
| Apache Spark SQL | pip install pyhive | hive://hive@{hostname}:{port}/{database} |
| Ascend.io | pip install impyla | ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true |
| Azure MS SQL | pip install pymssql | mssql+pymssql://UserName@presetSQL:TestPassword@presetSQL.database.windows.net:1433/TestSchema |
| Big Query | pip install sqlalchemy-bigquery | bigquery://{project_id} |
| ClickHouse | pip install clickhouse-connect | clickhousedb://{username}:{password}@{hostname}:{port}/{database} |
| CockroachDB | pip install cockroachdb | cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable |
| Dremio | pip install sqlalchemy_dremio | dremio://user:pwd@host:31010/ |
| Elasticsearch | pip install elasticsearch-dbapi | elasticsearch+http://{user}:{password}@{host}:9200/ |
| Exasol | pip install sqlalchemy-exasol | exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC |
| Google Sheets | pip install shillelagh[gsheetsapi] | gsheets:// |
| Firebolt | pip install firebolt-sqlalchemy | firebolt://{username}:{password}@{database} or firebolt://{username}:{password}@{database}/{engine_name} |
| Hologres | pip install psycopg2 | postgresql+psycopg2://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| IBM Db2 | pip install ibm_db_sa | db2+ibm_db:// |
| IBM Netezza Performance Server | pip install nzalchemy | netezza+nzpy://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| MySQL | pip install mysqlclient | mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Oracle | pip install cx_Oracle | oracle:// |
| PostgreSQL | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| Trino | pip install trino | trino://{username}:{password}@{hostname}:{port}/{catalog} |
| Presto | pip install pyhive | presto:// |
| SAP Hana | pip install hdbcli sqlalchemy-hana or pip install apache-superset[hana] | hana://{username}:{password}@{host}:{port} |
| Snowflake | pip install snowflake-sqlalchemy | snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse} |
| SQLite | No additional library needed | sqlite:// |
| SQL Server | pip install pymssql | mssql+pymssql:// |
| Teradata | pip install teradatasqlalchemy | teradatasql://{user}:{password}@{host} |
| TimescaleDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>:<Port>/<Database Name> |
| Vertica | pip install sqlalchemy-vertica-python | vertica+vertica_python://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| YugabyteDB | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
支持的图表
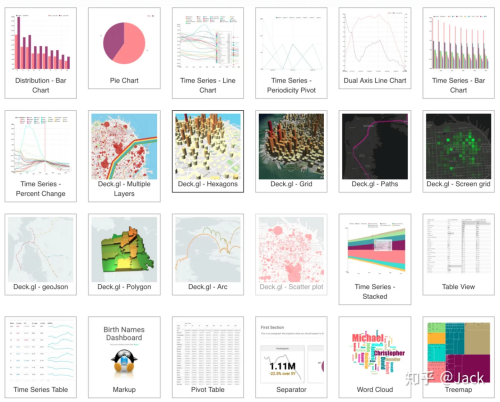
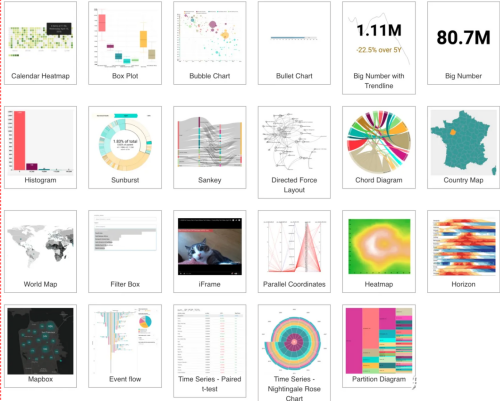
什么时候用Grafana,什么时候用Superset
- 时间序列,选Grafana
- 数据量很大,用Grafana
- 静态的日报、报表,Superset表现力很好
Superset安装及使用
Superset官网地址:http://superset.apache.org/
安装Python环境
Superset是由Python语言编写的Web应用,要求Python3.7的环境。
安装Miniconda
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同Python版本的软件包及其依赖,并能够在不同的Python环境之间切换,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,Miniconda包括Conda、Python。
此处,我们不需要如此多的工具包,故选择MiniConda。
(1)下载Miniconda(Python3版本)
下载地址:https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
(2)安装Miniconda
-
执行以下命令进行安装,并按照提示操作,直到安装完成。
[atguigu@hadoop102 lib]$ bash Miniconda3-latest-Linux-x86_64.sh -
在安装过程中,出现以下提示时,可以指定安装路径
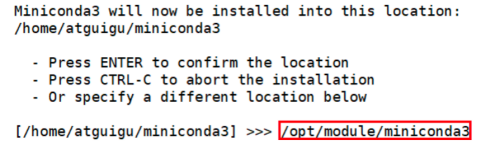
-
出现以下字样,即为安装完成
Thank you for installing Minicoda3!
(3)加载环境变量配置文件,使之生效
[atguigu@hadoop102 lib]$ source ~/.bashrc
(4)取消激活base环境
Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。
[atguigu@hadoop102 lib]$ conda config --set auto_activate_base false
创建Python3.7环境
(1)配置conda国内镜像
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
(base) [atguigu@hadoop102 ~]$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
(base) [atguigu@hadoop102 ~]$ conda config --set show_channel_urls yes
(2)创建Python3.7环境
(base) [atguigu@hadoop102 ~]$ conda create --name superset python=3.7
说明:conda环境管理常用命令:
- **创建环境:**conda create -n env_name
- **查看所有环境:**conda info --envs
- **删除一个环境:**conda remove -n env_name --all
(3)激活superset环境
(base) [atguigu@hadoop102 ~]$ conda activate superset
说明:退出当前环境
(superset) [atguigu@hadoop102 ~]$ conda deactivate
Superset部署
安装依赖
安装Superset之前,需安装以下所需依赖:
(superset) [atguigu@hadoop102 ~]$ sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel
安装Superset
(1)安装(更新)setuptools和pip
(superset) [atguigu@hadoop102 ~]$ pip install --upgrade setuptools pip -i https://pypi.douban.com/simple/
**说明:**pip是python的包管理工具,可以和centos中的yum类比
(2)安装Supetset
(superset) [atguigu@hadoop102 ~]$ pip install apache-superset -i https://pypi.douban.com/simple/
说明:-i的作用是指定镜像,这里选择国内镜像
注:如果遇到网络错误导致不能下载,可尝试更换镜像
(superset) [atguigu@hadoop102 ~]$ pip install apache-superset --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple
(3)初始化Supetset数据库
(superset) [atguigu@hadoop102 ~]$ superset db upgrade
(4)创建管理员用户
(superset) [atguigu@hadoop102 ~]$ export FLASK_APP=superset
(superset) [atguigu@hadoop102 ~]$ superset fab create-admin
指定用户名和密码
**说明:**flask是一个python web框架,Superset使用的就是flask
(5)Superset初始化
(superset) [atguigu@hadoop102 ~]$ superset init
安装gunicorn
gunicorn是一个Python Web Server,可以和java中的TomCat类比。
(superset) [atguigu@hadoop102 ~]$ pip install gunicorn -i https://pypi.douban.com/simple/
启动Supterset
(1)确保当前conda环境为superset
(2)启动
(superset) [atguigu@hadoop102 ~]$ gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 "superset.app:create_app()" --daemon
说明:
- –workers:指定进程个数
- –timeout:worker进程超时时间,超时会自动重启
- –bind:绑定本机地址,即为Superset访问地址
- –daemon:后台运行
(3)登录Superset
访问http://hadoop102:8787,并使用前面创建的管理员账号进行登录。
停止superset
停掉gunicorn进程
(superset) [atguigu@hadoop102 ~]$ ps -ef | awk '/superset/ && !/awk/{print $2}' | xargs kill -9
退出superset环境
(superset) [atguigu@hadoop102 ~]$ conda deactivate
superset启停脚本
(1)创建superset.sh文件
[atguigu@hadoop102 bin]$ vim superset.sh
内容如下
#!/bin/bash
superset_status(){
result=`ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | wc -l`
if [[ $result -eq 0 ]]; then
return 0
else
return 1
fi
}
superset_start(){
source ~/.bashrc
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
conda activate superset ; gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 --daemon 'superset.app:create_app()'
else
echo "superset正在运行"
fi
}
superset_stop(){
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
ps -ef | awk '/gunicorn/ && !/awk/{print $2}' | xargs kill -9
fi
}
case $1 in
start )
echo "启动Superset"
superset_start
;;
stop )
echo "停止Superset"
superset_stop
;;
restart )
echo "重启Superset"
superset_stop
superset_start
;;
status )
superset_status >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
echo "superset未在运行"
else
echo "superset正在运行"
fi
esac
(2)加执行权限
[atguigu@hadoop102 bin]$ chmod +x superset.sh
(3)测试
启动superset
[atguigu@hadoop102 bin]$ superset.sh start
停止superset
[atguigu@hadoop102 bin]$ superset.sh stop
Superset使用
对接MySQL数据源
(1)安装依赖
(superset) [atguigu@hadoop102 ~]$ conda install mysqlclient
说明:对接不同的数据源,需安装不同的依赖,以下地址为官网说明
https://superset.apache.org/docs/databases/installing-database-drivers
(2)重启Superset
(superset) [atguigu@hadoop102 ~]$ superset.sh restart
(3)数据源配置
1)Database配置
-
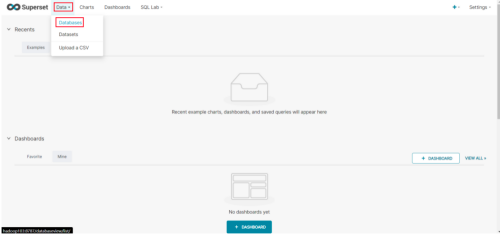
**Step1:**点击Data/Databases
-
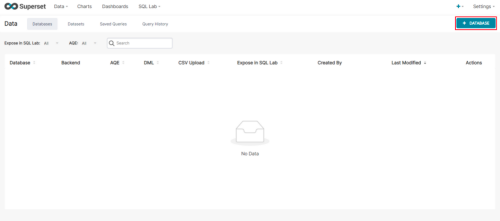
Step2:点击+DATABASE
-
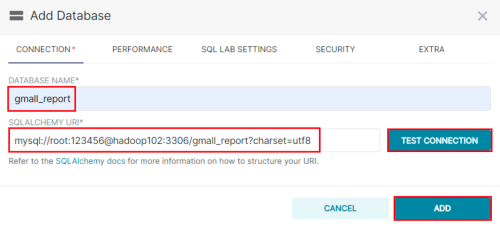
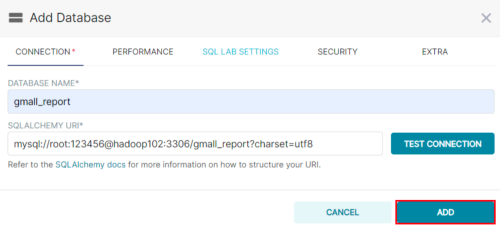
**Step3:**点击填写Database及SQL Alchemy URI
注:SQL Alchemy URI编写规范:mysql://用户名:密码@主机名:端口号/数据库名称
此处填写:
mysql://root:123456@hadoop102:3306/gmall_report?charset=utf8
-
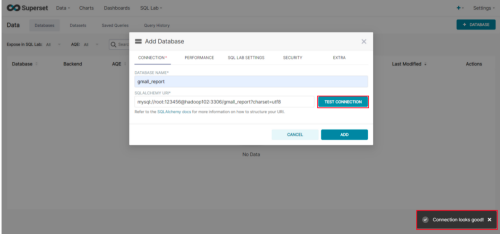
**Step4:**点击Test Connection,出现“Connection looks good!”提示即表示连接成功
-
**Step5:**点击ADD
2)Table配置
-
Step1:点击Data/Datasets

-
Step2:点击Data/ Datasets
-
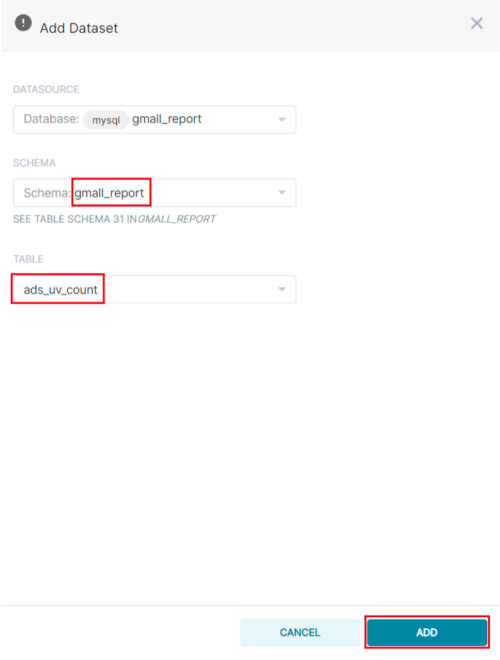
Step3:配置Table
制作仪表盘
创建空白仪表盘
(1)点击Dashboards/+DASHBOARDS
(2)命名并保存
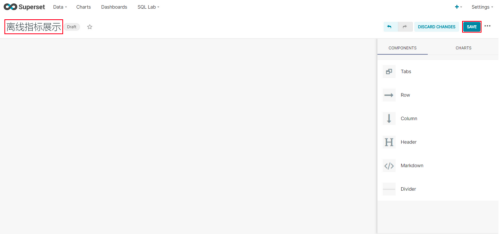
创建图表
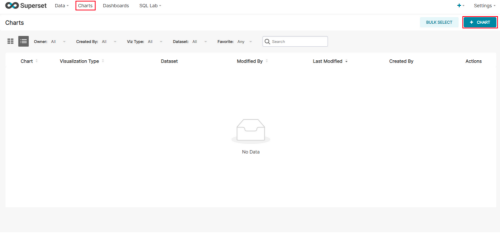
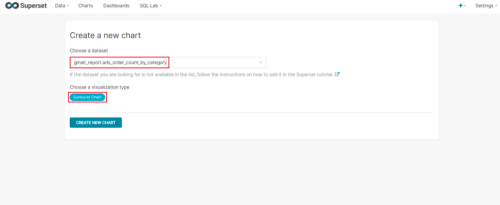
(1)点击Charts/+CHART
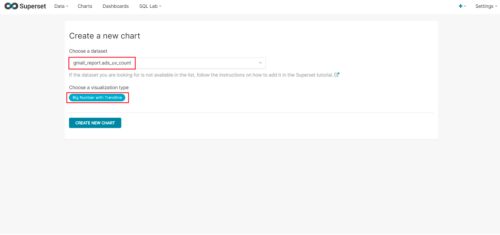
(2)选则数据源及图表类型
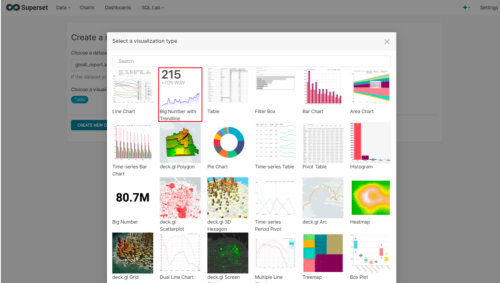
(3)选择何使的图表类型
(4)创建图表
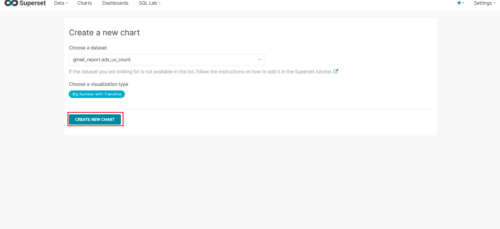
(5)按照说明配置图表
(6)点击“Run Query”
(7)如配置无误,可出现以下图标
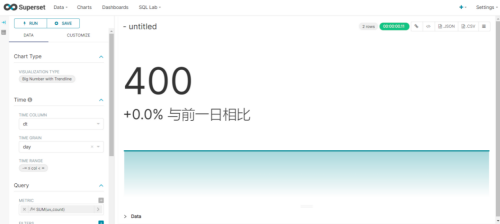
(8)命名该图表,并保存至仪表盘
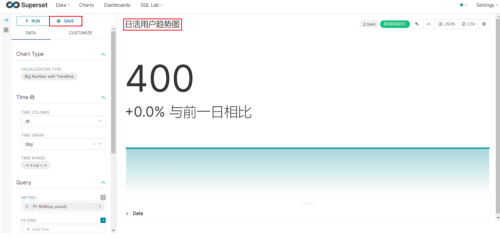
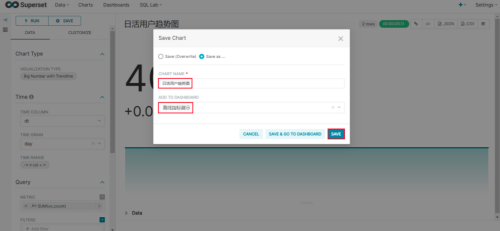
编辑仪表盘
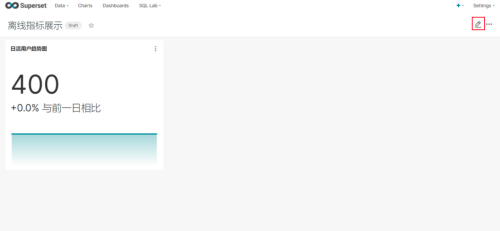
(1)打开仪表盘,点击编辑按钮
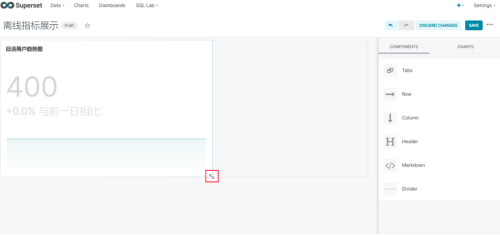
(2)调整图表大小以及图表盘布局
(3)点击下图中箭头,可调整仪表盘自动刷新时间
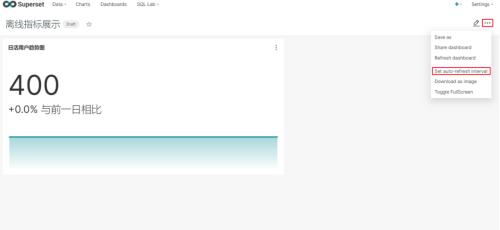
SQL Lab(SQL实验室)
SQL Lab其实就是一个数据库查询客户端,利用SQL语句对数据库的表,字段模型进行查询探索,同时支持智能补全,当然SQL Lab的查询结果也可以直接EXPLORE到Charts(图表),作为数据可视化的数据源。
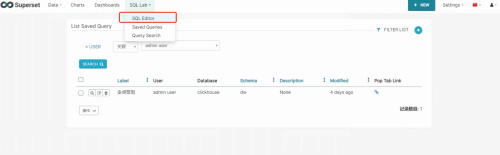
如图,SQL Lab有三个选项,三个选项的功能如下:
- SQL Editor:进行SQL查询探索
- Saved Queries:保存的通用查询SQL
- Query Search:查询的历史记录
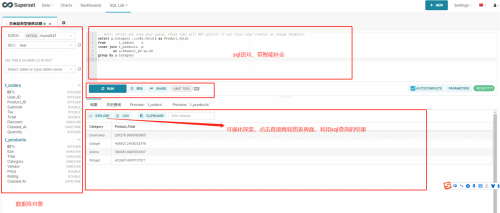
点击SQL Editor进入图中的SQL查询探索,左侧上方是配置好的数据库连接名和选择的数据库,左侧下方是将要用到的表及字段模型;右侧上方是写SQL语句的地方,支持RUN(查询),RUN SELECTION(查询鼠标选择局部语句),SAVE(保存),SHARE(分享)等,右下方是数据结果,支持EXPLORE到Charts(图表)可视化,.CSV下载,CLIPBOARD(复制到剪贴板)。
设置
角色列表及权限
Apache Superset中的安全性由Flask AppBuilder(FAB)处理,FAB是一个构建在Flask之上的应用程序开发框架。FAB提供身份验证、用户管理、权限和角色,可以查看其相关文档。
Apache Superset默认提供了不同的角色,每种角色拥有的权限不同,在运行superset init命令时,与每个角色关联的权限将重新同步到其原始值,不建议更改与每个角色关联的权限(例如,通过删除或添加权限),支持admin再自建角色类型,指定想要的权限,默认的角色及权限如下:
- Admin:管理员拥有所有可能的权限,包括授予或撤销其他用户的权限,以及更改其他用户的切片和仪表板;
- Alpha:Alpha用户可以访问所有数据源,但不能授予或撤消其他用户的访问权限。它们也仅限于改变它们所拥有的对象。Alpha用户可以添加和更改数据源。
- Gamma:Gamma用户的访问权限有限。他们只能使用来自通过另一个补充角色访问的数据源的数据。他们只能查看由他们可以访问的数据源制作的切片和仪表板。目前Gamma用户无法更改或添加数据源。我们假设他们主要是内容消费者,尽管他们可以创建切片和仪表盘。另请注意,当Gamma用户查看仪表板和切片列表视图时,他们将只看到他们有权访问的对象。
- sql_lab:sql_lab角色授予对sql lab的访问权限。请注意,虽然管理员用户在默认情况下可以访问所有数据库,但Alpha和Gamma用户都需要在每个数据库的基础上获得访问权限。
- public:要允许注销的用户访问某些超集功能,需要自己配置权限,并将其分配给另一个角色,您希望将其权限传递给该角色。
更多的角色权限可以查看官网Apache Superset Security,或者点开图中的编辑角色查看,尽量别改默认角色的权限。
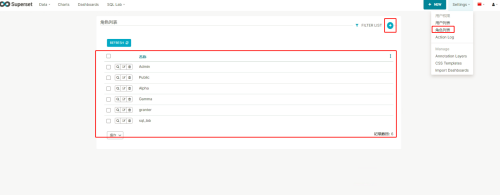
同时Apache Superset也支持管理员自己新增角色,如图,新建角色并指定角色权限。
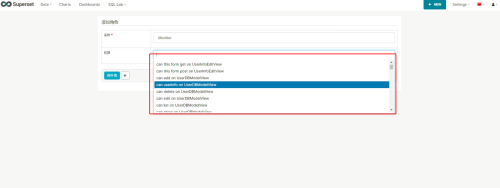
用户列表
新建、编辑用户指定角色,用户的权限是绑定在角色里面的,一个用户可以有多个角色,配置信息如图:
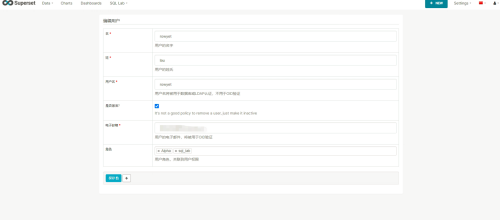
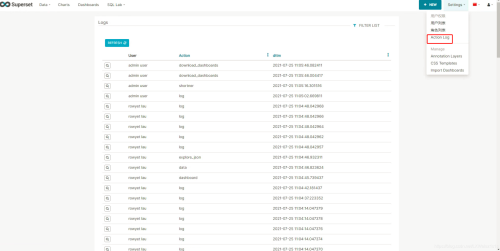
操作日志
操作日志记录的是在你的Superset平台上不同用户的行为日志,如图:
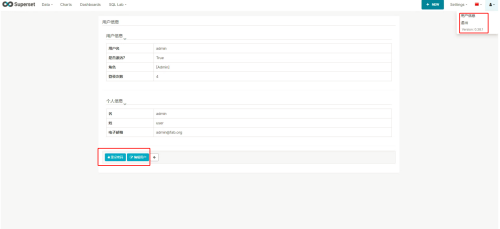
用户信息、退出、版本信息
菜单栏最右侧的个人信息,主要是包含:
用户信息:修改用户姓名,重置密码;退出:回到登录主界面;版本:目前您安装的Superset版本信息。
语言选择
作为Apache的顶级项目,自然是运用于全球的,支持世界上一些通用的语言 ,选择一款你最喜欢的即可。
管理设置
针对仪表盘,图表渲染加入自己想要的风格和模板,实际运用的用的不多。

+ NEW
菜单栏的+ NEW其实就是给最通用的三个模块SQL Query、图表、看板(仪表盘)的一个快捷方式,此三者的用法就不在累赘了。
项目实战
制作地图
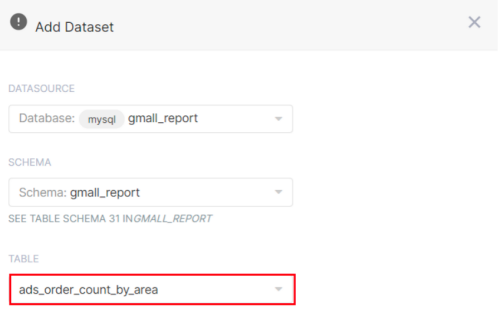
(1)配置Table
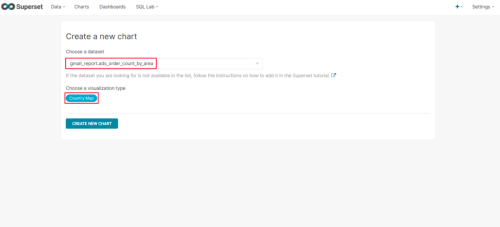
(2)配置Chart

制作饼状图
(1)配置Table
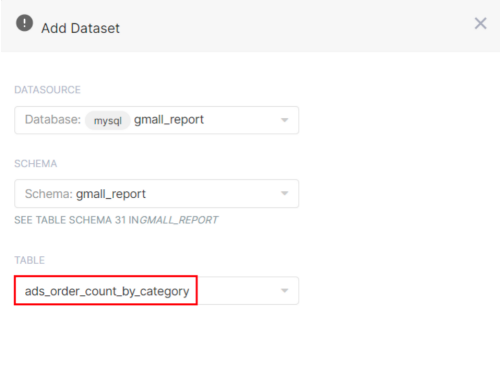
(2)配置Chart
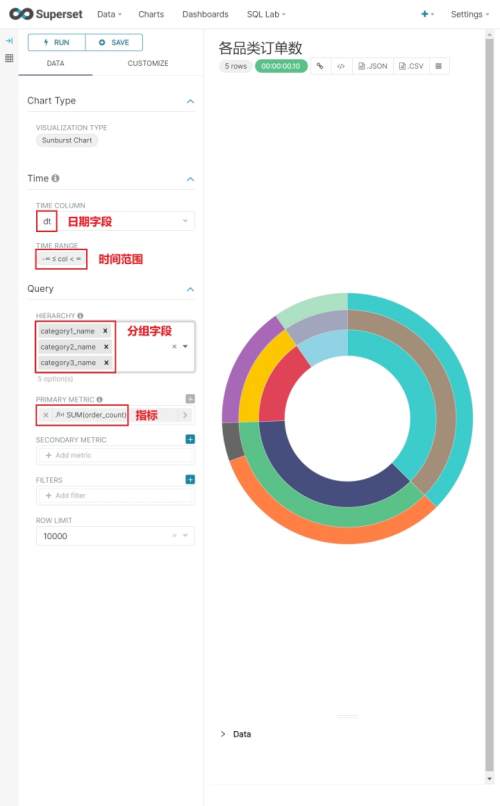
其他选项
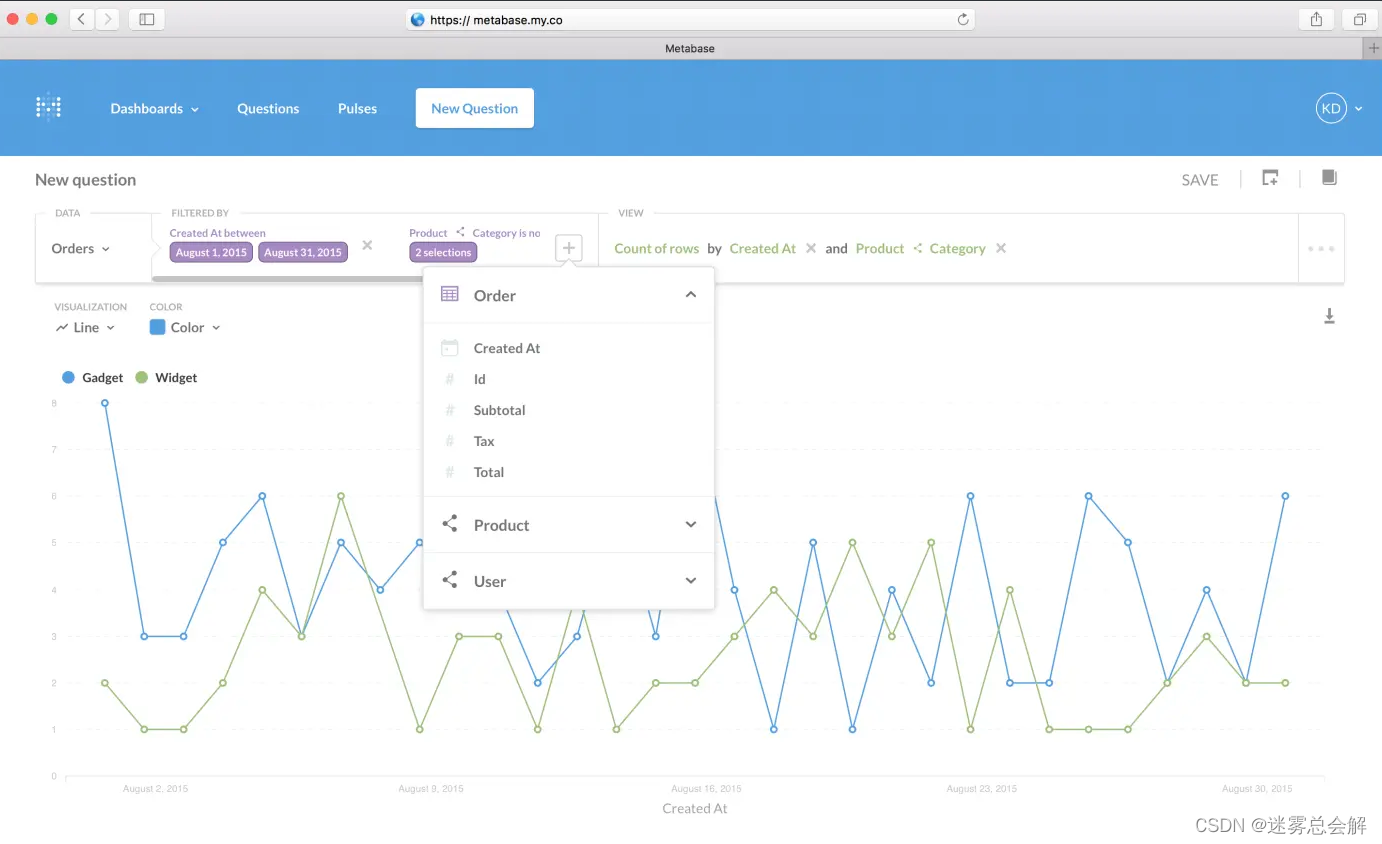
(1)metabase
-
https://github.com/metabase/metabase
-
目前不支持ClickHouse
(2)Redash
-
https://github.com/getredash/redash
-
支持ClickHouse
-
美观程度相比Superset不够精美
-
支持简单的报警规则
-
可以把Dashboard分享出去
-
支持的图表类型有限

(3)Zeppelin
-
https://github.com/apache/zeppelin
-
来自Apache项目
-
支持ClickHouse
-
炫酷程度2颗星
-
Zeppelin更像是一个notebook,而不是一个单纯的BI工具
(4)SQLPad
-
https://github.com/rickbergfalk/sqlpad
(5)Franchise
-
https://github.com/HVF/franchise
(6)CBoard
-
https://github.com/yzhang921/CBoard
-
国人开发的一款可视化工具
-
交互设计的不错,但是实际用起来感觉很奇怪
-
Java系
(7)Davinci
-
宜信开发的达芬奇,也是Java系
-
功能还是比较全面的,只是在国内还没有大范围的使用
-
https://github.com/edp963/davinci

(8)商业:
-
FineBI
- 国内做的一流的BI工具,很炫酷,也比较实用,目前不支持ClickHouse
-
Tableau
- 多少商业课程都是在教这个,不过互联网讲究的是免费,怎么会用『?』
-
其他可视化资源:
- https://github.com/thenaturalist/awesome-business-intelligence
- https://github.com/topics/business-intelligence?o=desc&s=stars

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









