







Saliency Detection: A Spectral Residual Approach
(显著性检测:一种光谱残差方法)
传统模型通过将特定的特征与目标联系起来,实际上是将这一问题转化为对特定类别物体的检测[3]。由于这些模型是基于训练的,可扩展性成为泛化任务的瓶颈。面对不可预测且种类繁多的视觉模式,需要一种通用的显著性检测系统。换句话说,显著性检测器应该在对对象的统计知识引用最少的情况下实现
大多数检测模型的重点是总结目标物体的属性。然而,不同类别的对象所共有的一般属性不太可能存在。在本文中,我们以另一种方式提出这个问题:探索背景的属性
视觉系统的一个基本原则是抑制对频繁出现的特征的反应,同时对偏离常态的特征保持敏感[9]。因此,只有意外的信号才能被传递到处理的后期阶段。
Frequency-tuned Salient Region Detection
( 频率调谐显著区检测)
检测视觉上显著的图像区域对于对象分割、自适应压缩和对象识别等应用非常有用。在本文中,我们介绍了一种显著区域检测方法,该方法输出具有明确定义的显著目标边界的全分辨率显著性地图。通过从原始图像中保留比其他现有技术多得多的频率内容来保留这些边界。该方法利用了颜色和亮度的特征,实现简单,计算效率高。我们将我们的算法与五种最先进的显著区域检测方法进行比较,这些方法具有频域分析、地面真值和显著目标分割应用。我们的方法在基础真值评估和分割任务上都优于五种算法,实现了更高的精度和更好的召回率。
一些方法在物体边缘产生较高的显著性值,而不是生成均匀覆盖整个物体的地图,这是由于未能利用原始图像的所有空间频率内容。
介绍了一种使用颜色和亮度特征估计中心环绕对比度的频率调谐方法,与现有方法相比,该方法具有三个优点:具有明确边界的均匀突出突出区域,全分辨率和计算效率。生成的显著性图可以在许多应用中更有效地使用,这里我们给出了目标分割的结果。
Global Contrast based Salient Region Detection
(基于全局对比度的显著区域检测)
视觉显著性的可靠估计允许在不事先了解其内容的情况下对图像进行适当的处理,因此在许多计算机视觉任务中仍然是重要的一步,包括图像分割,对象识别和自适应压缩。提出了一种基于区域对比度的显著性提取算法,该算法同时评估全局对比度差异和空间相干性。该算法简单、高效,可生成全分辨率显著性图。当使用最大的公开可用数据集进行评估时,我们的算法始终优于现有的显著性检测方法,产生更高的精度和更好的召回率。
显著性源于视觉上的独特性、不可预测性、稀有性或惊喜性,通常归因于图像属性的变化,如颜色、梯度、边缘和边界。
我们专注于自下而上的数据驱动显著性检测使用图像对比度。
基于全局对比度的方法将大型对象与其周围环境分离开来,优于基于局部对比度的方法,该方法在对象边缘或附近产生高显着值。
全局考虑允许分配可比较的显著值到相似的图像区域,并可以统一突出整个对象。
一个地区的显著性主要取决于显著性地图应该是快速和容易生成的,以允许处理大型图像集合,并促进有效的图像分类和检索其与附近地区的对比,而与遥远地区的对比则不那么显著。
请注意,我们的算法针对的是自然场景,对于提取高度纹理场景的显著性可能不是最优的(见图12)。
Salient Region Detection and Segmentation
(显著区域检测与分割)
摘要。显著图像区域检测对于图像分割、自适应压缩和基于区域的图像检索等应用非常有用。在本文中,我们提出了一种新的方法来确定显著区域的图像使用亮度和颜色的低级特征。该方法快速,易于实现,并生成与输入图像相同大小和分辨率的高质量显著性地图。我们演示了该算法在从数字图像中分割语义上有意义的整体对象中的应用。
我们将显著区域定义为图像中由于与周围区域形成对比而在视觉上更加显著的区域。
我们提出了一种新的方法来寻找图像中的显著区域,利用颜色和亮度的低电平特征,该方法易于实现,耐噪,并且足够快,可用于实时应用。它以与输入图像相同的分辨率生成显著性图。我们证明了该方法在广泛的图像中检测和分割显著区域的有效性。该方法在寻找显著性地图和生成高分辨率显著性地图方面的速度至少是显著性方法的五倍,从而可以更好地进行显著性目标分割。
Hierarchical Image Saliency Detection on Extended CSSD
(扩展CSSD的分层图像显著性检测)
复杂结构在自然图像中普遍存在。当图像在背景或前景中包含小规模高对比度模式时,显著性检测可能会受到不利影响,导致错误和不均匀的显著性分配。这个问题对以前的方法构成了根本性的挑战。我们从尺度的角度来解决这个问题,并提出了一种多层方法来分析显著性线索。与改变补丁大小或缩小图像不同,我们测量的是基于区域的尺度。
通过分层推理,结合不同尺度的显著性线索,最优地推断出最终的显著性值。通过我们的推理模型,选择单比例尺信息得到显著性图。我们的方法提高了传统方法无法很好处理的许多图像的检测质量。我们还构建了一个扩展的复杂场景显著性数据集(ECSSD),以包括复杂但一般的自然图像。
Graph-Regularized Saliency Detection With Convex-Hull-Based Center Prior
(基于凸壳中心先验的图正则化显著性检测)
摘要:对象级显著性检测对于许多基于内容的计算机视觉任务非常有用。在这封信中,我们提出了一种新的自下而上的显著目标检测方法,利用对比度,中心和平滑先验。首先,我们使用对比度和中心先验计算初始显著性映射。与大多数现有的基于中心先验的方法不同,我们使用兴趣点的凸包来估计显著目标的中心,而不是直接使用图像中心。这种策略使得显著性结果对目标位置的鲁棒性更强。其次,我们通过最小化一个连续的两两显著性能量函数来优化初始显著性图,该函数使用图形正则化来鼓励相邻像素或段采用相似的显著性值(即平滑先验)。平滑先验使得该方法能够在均匀突出突出目标的同时有效地抑制背景。在大型数据集上进行的大量实验表明,所提出的方法在准确性和效率方面优于最先进的方法。
SAMNet: Stereoscopically Attentive Multi-Scale Network for Lightweight Salient Object Detection
(基于立体关注的多尺度轻量显著目标检测网络)
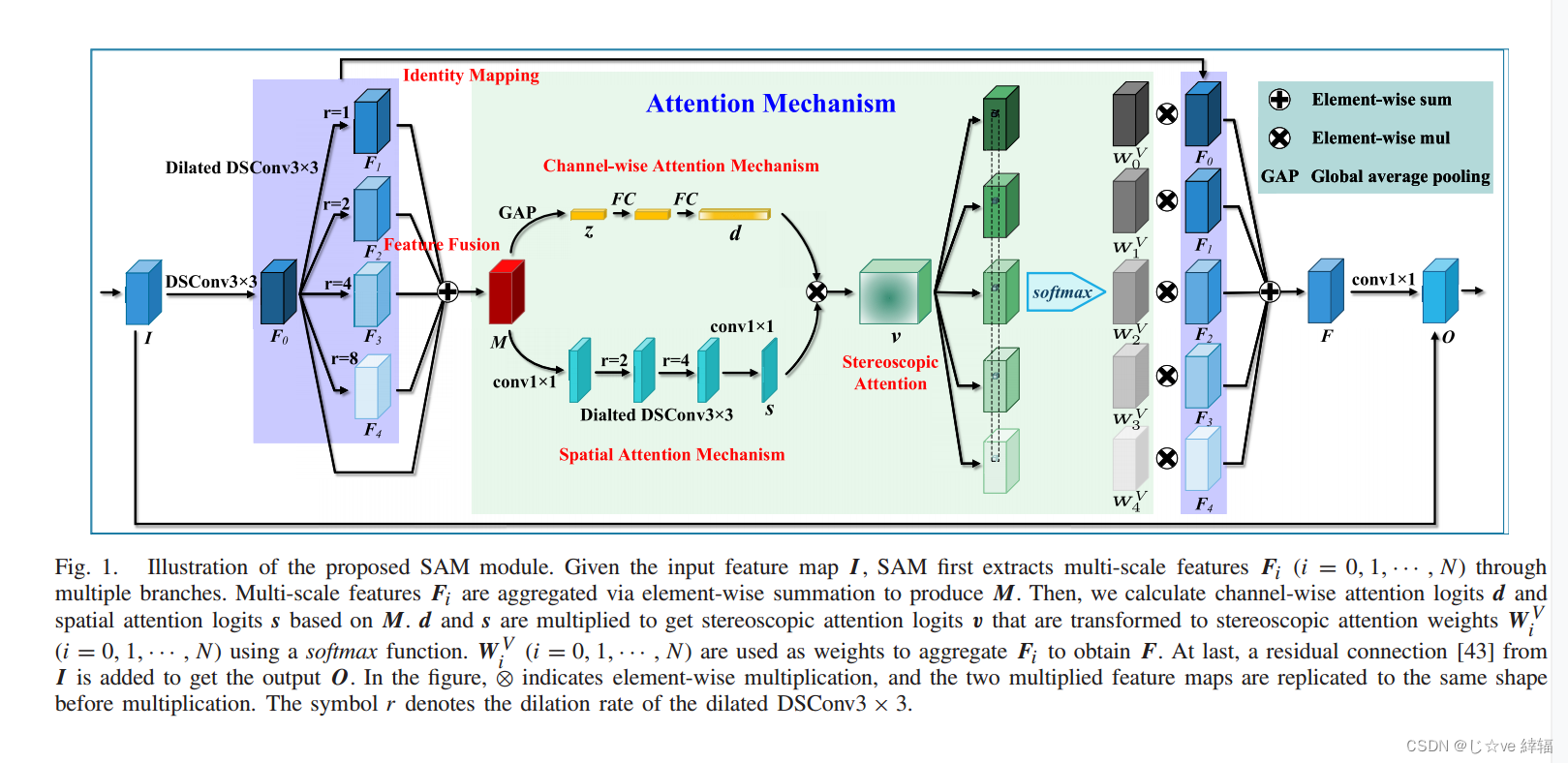
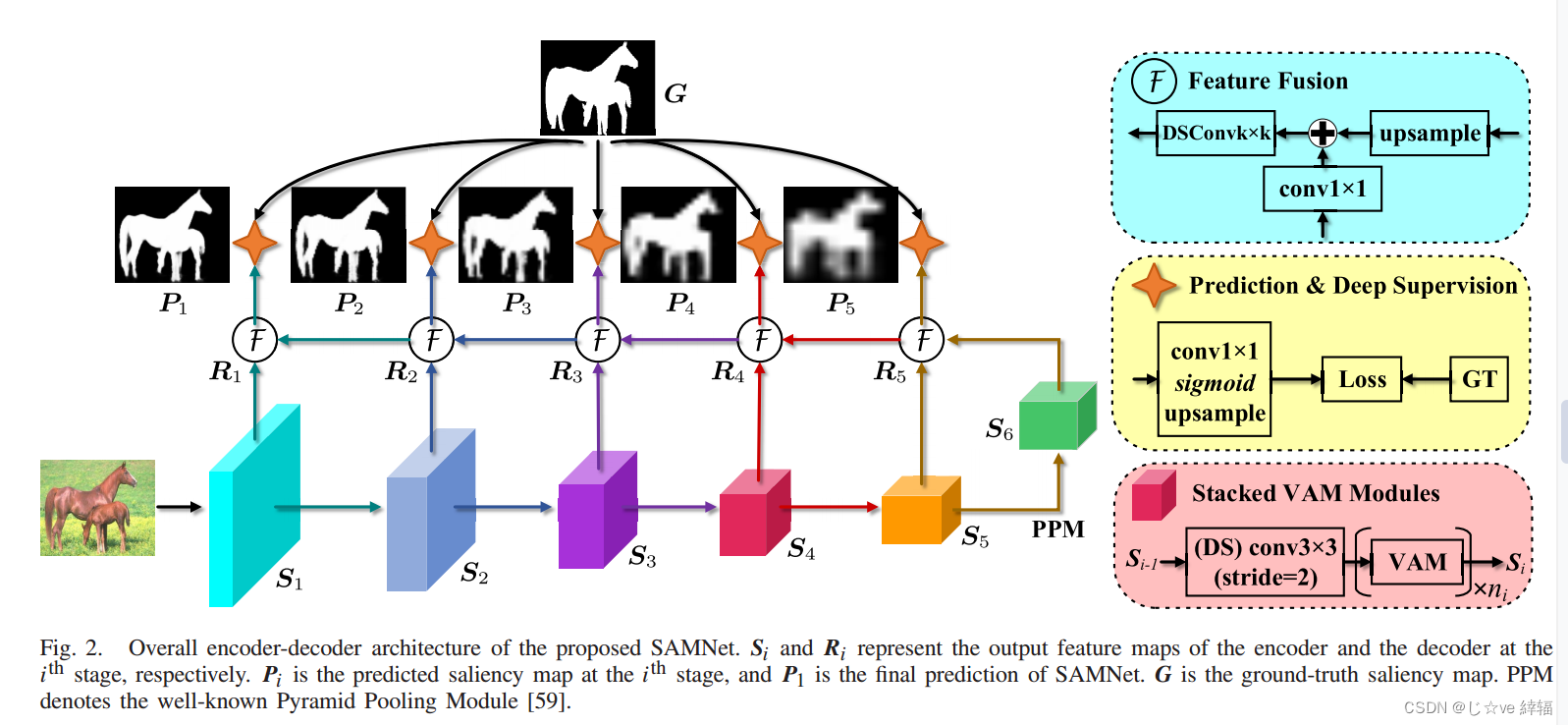
摘要显著目标检测(SOD)的最新进展主要得益于卷积神经网络(cnn)的爆炸性发展。然而,大部分的改进都伴随着更大的网络规模和更重的计算开销,在我们看来,这是不适合移动设备的,因此难以在实践中部署。为了使SOD系统更加实用,我们引入了一种新的立体注意多尺度(SAM)模块,该模块采用立体注意机制自适应融合不同尺度的特征。在这个模块上,我们提出了一个非常轻量级的SOD网络,即SAMNet。在流行的基准测试上进行的大量实验表明,所提出的SAMNet在GPU速度为343fps和CPU速度为5fps的情况下,对于只有1.33M参数的336×336输入,可以产生与最先进的方法相当的精度。因此,SAMNet为SOD开辟了新的途径。源代码可在项目页面https://mmcheng.net/SAMNet/上获得。
cnn可以在其顶部学习高级语义信息,在其底部学习低级精细细节。这使得cnn的不同侧输出包含多尺度信息。因此,为了学习多层次和多尺度的信息,目前最先进的SOD方法(大型网络)采用编码器-解码器网络架构[10]-[29],以整合骨干网的多层次侧输出特征。SOD的最新发展主要体现在多级主干特征有效融合的新策略和新模块上
在过去的二十年里,人们提出了许多方法来检测图像中的显著目标。传统方法主要基于手工制作的特征,如图像对比度[1]、纹理[45]、中心先验[8]、背景先验[46]等。尽管这些方法效率很高,但手工制作的特征本质上缺乏高级表示的能力,导致性能有限。
Learning Uncertain Convolutional Features for Accurate Saliency Detection(学习不确定卷积特征用于准确的显著性检测)
深度卷积神经网络(cnn)在许多计算机视觉任务中表现优异。
在本文中,我们提出了一种新的深度全卷积网络模型,用于精确的显著目标检测。这项工作的关键贡献是学习深度不确定卷积特征(UCF),这提高了显著性检测的鲁棒性和准确性。我们通过在特定的卷积层之后引入重新制定的dropout (R-dropout)来实现这一点,以构建内部特征单元的不确定集合。此外,我们提出了一种有效的混合上采样方法来减少解码器网络中反卷积算子的棋盘伪影。
所提出的方法也可以应用于其他深度卷积网络。与现有的显著性检测方法相比,所提出的UCF模型能够考虑不确定性因素,从而更准确地进行目标边界推断。大量的实验表明,我们提出的显著性模型优于最先进的方法。不确定特征学习机制和上采样方法可以显著提高其他像素级视觉任务的性能。
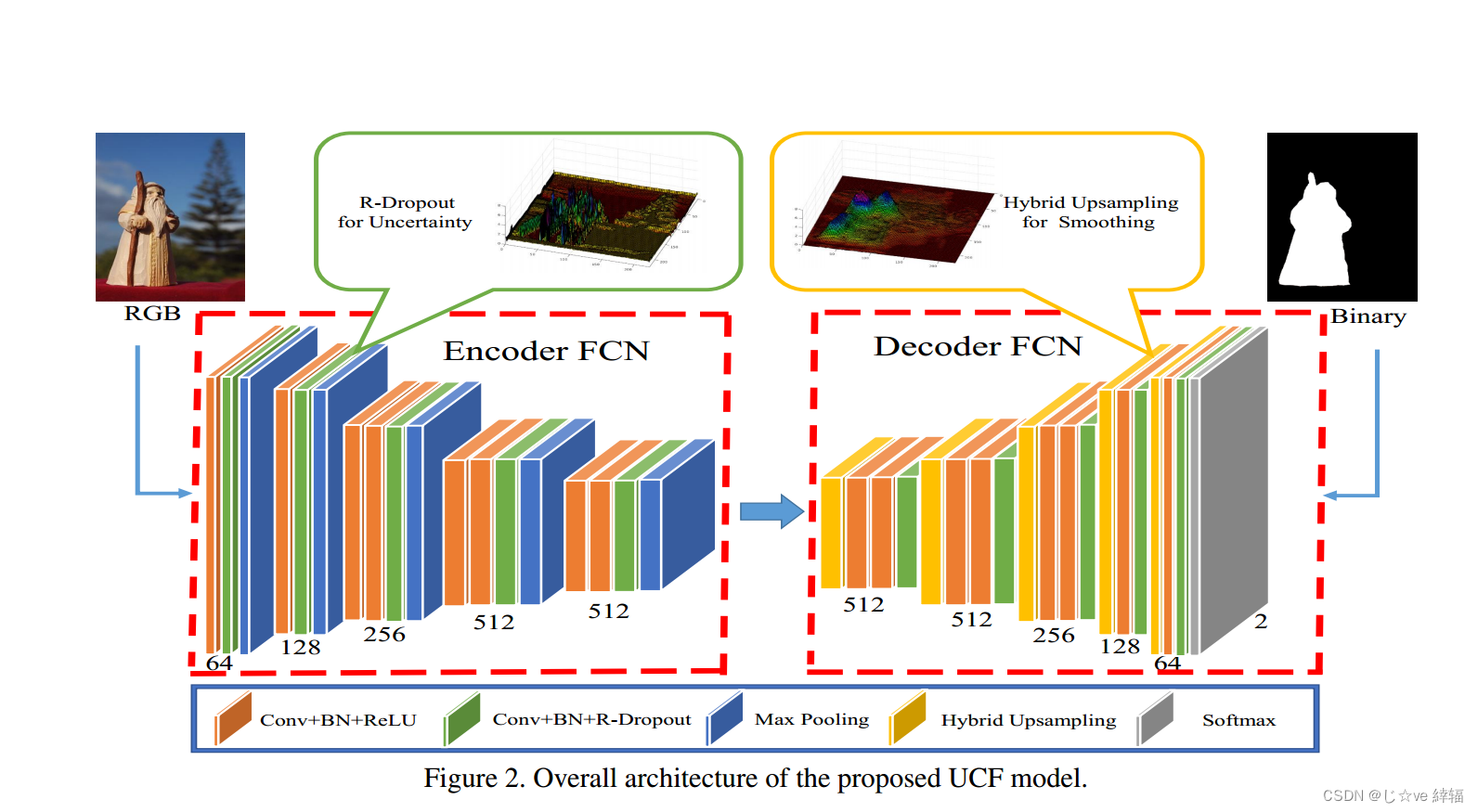
编码-解码结构
CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances
(基于cnn的显著目标检测编码器-解码器网络:全面回顾和最新进展)
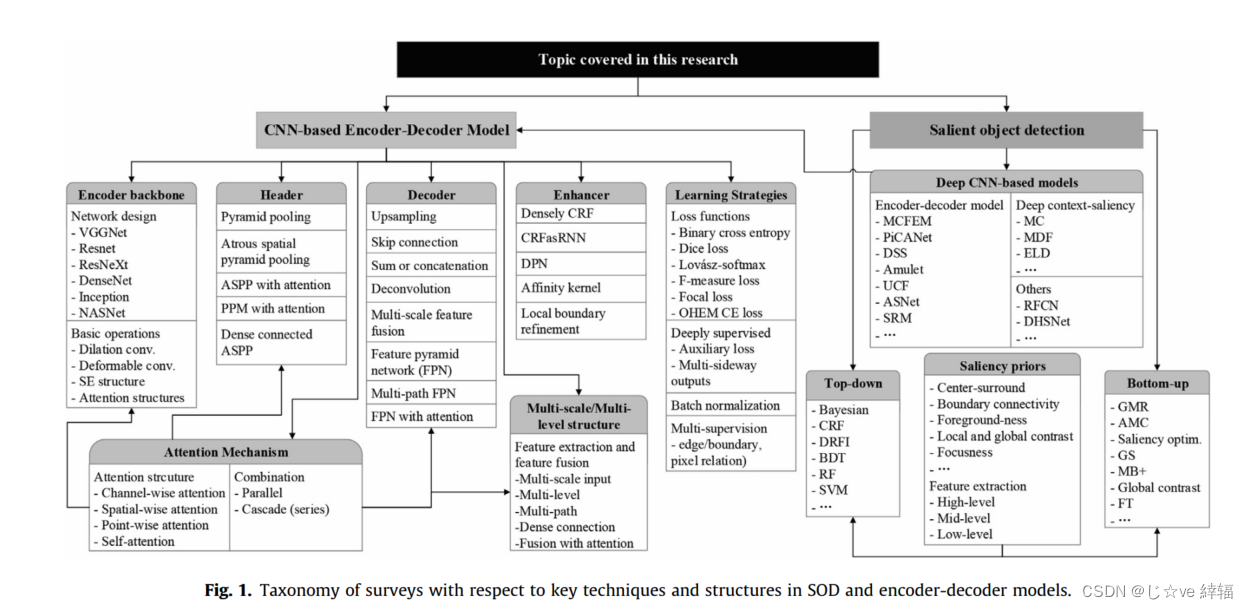 综述总结了显著性目标检测编码解码结构方法
综述总结了显著性目标检测编码解码结构方法
PiCANet:用于精确显著性检测的逐像素上下文注意学习
摘要在显著性检测中,每个像素都需要上下文信息来进行显著性预测。以前的模型通常整体地包含上下文。然而,对于每个像素,通常只有一部分上下文区域是有用的,有助于其预测,而其他部分可能作为噪音和干扰。在本文中,我们提出了一种新颖的逐像素上下文注意网络,即PiCANet,以学习选择性地关注每个像素上的信息上下文位置。具体来说,PiCANet在每个像素的上下文区域上生成一个注意力地图,其中每个注意力权重对应于上下文位置与引用像素的相关性。然后,通过选择性地将有用的上下文位置特征与习得的注意相结合,可以构建专注的上下文特征。我们提出了PiCANet的三种具体公式,通过将像素级上下文注意机制嵌入到池化和卷积操作中,以关注全局或局部上下文。这三种模型都是完全可微的,可以通过联合训练与cnn集成。我们将提出的picanet引入到U-Net[1]架构中,用于显著目标检测。实验结果表明,所提出的picanet能够显著提高显著性检测性能。生成的全局关注和局部关注可以分别学习融合全局对比度和平滑度,这有助于更准确地定位突出目标并更均匀地突出它们。因此,我们的显著性模型优于其他最先进的方法。此外,我们还验证了picanet还可以提高语义分割和目标检测性能,进一步证明了其有效性和泛化能力。
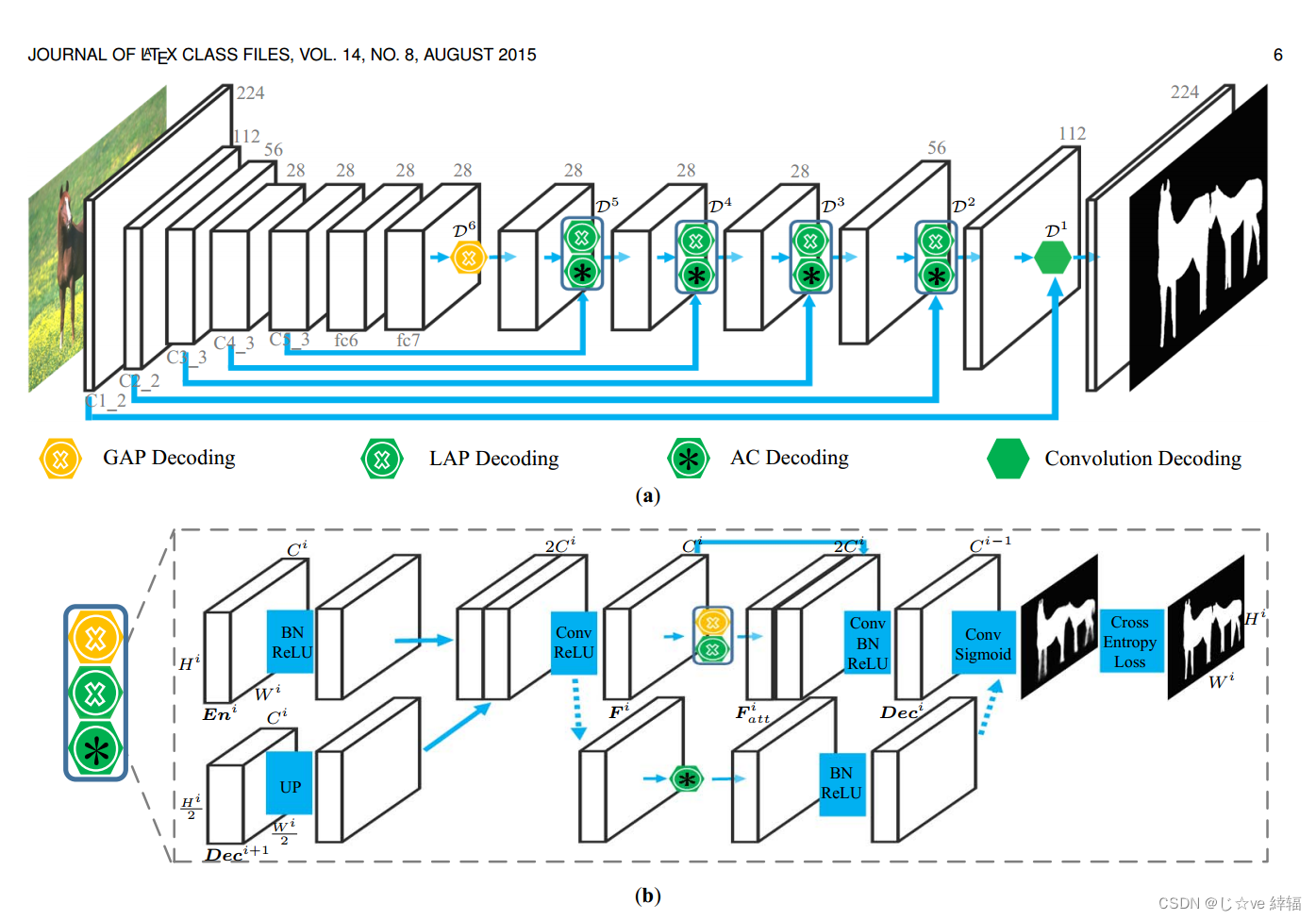
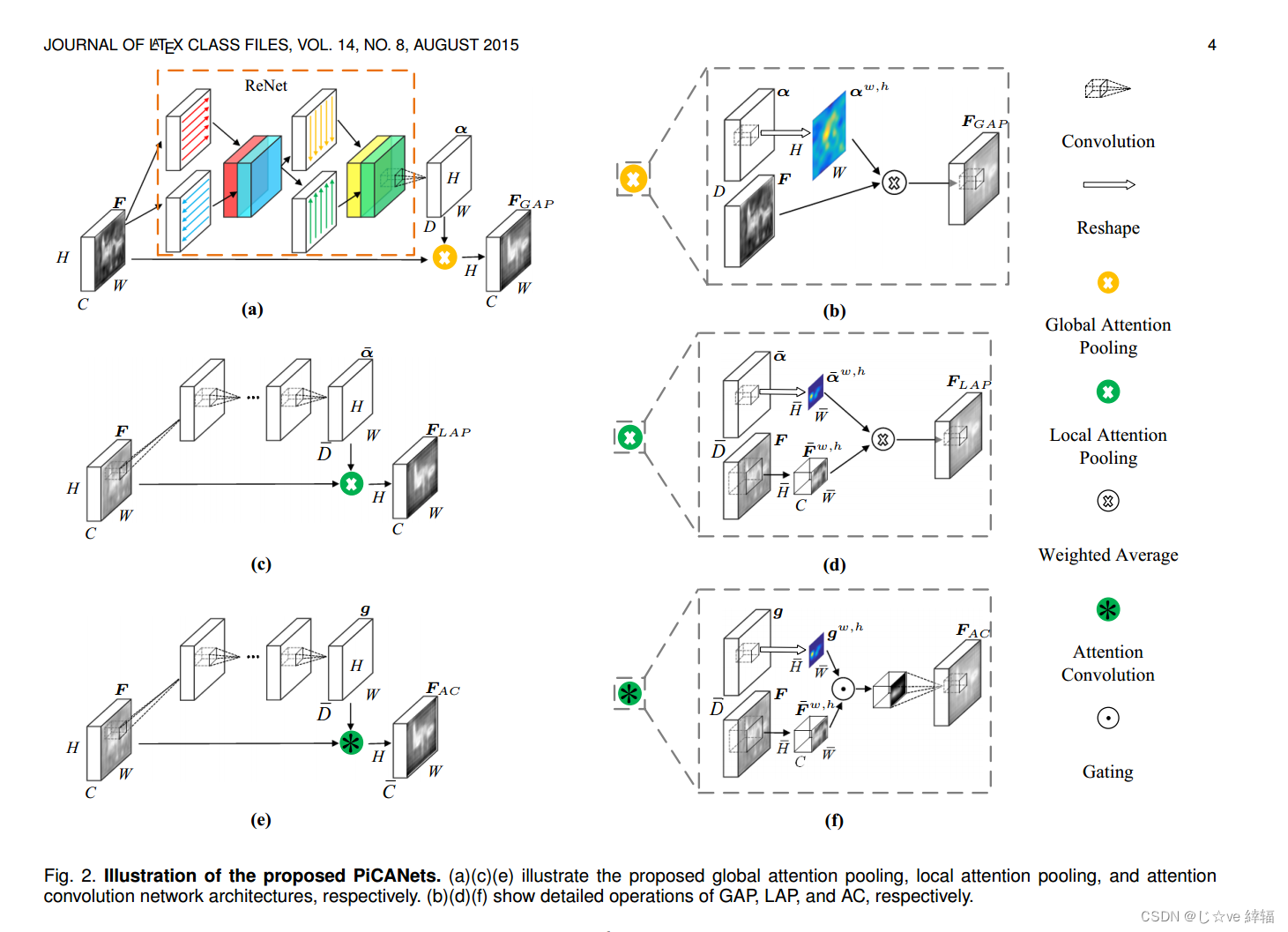
Detect Globally, Refine Locally: A Novel Approach to Saliency Detection
(全局检测,局部改进:一种显著性检测的新方法)
上下文信息的有效整合是显著目标检测的关键。为了实现这一点,大多数现有的基于“跳过”架构的方法主要集中在如何整合卷积神经网络(cnn)的层次特征上。它们只是应用连接或元素操作来合并高级语义线索和低级详细信息。然而,这可能会降低预测的质量,因为混乱和嘈杂的信息也可以通过。
为了解决这一问题,我们提出了一种全球循环定位网络(RLN),该网络通过加权响应图利用上下文信息来更准确地定位显著目标。特别是,使用循环模块在多个时间步长上逐步细化CNN的内部结构。此外,为了有效地恢复目标边界,我们提出了一种局部边界细化网络(BRN)来自适应学习每个空间位置的局部上下文信息。
学习到的传播系数可以用来最优地捕获每个像素与其邻居之间的关系。在五个具有挑战性的数据集上的实验表明,我们的方法在流行的评估指标方面优于所有现有方法。
最近基于cnn的方法[18,22,10,33,29]已经成功地缓解了上述问题,并引起了各种神经网络结构的扩散。通常,标准的卷积神经网络由一系列重复的卷积阶段组成,然后是空间池化。虽然以牺牲空间分辨率为代价,但较深的层编码具有更丰富的语义表示,而较浅的层包含更精细的结构。现有的显著性检测方法[18,10,33]试图将层次特征结合起来,同时捕获鲜明的对象和详细信息。然而,这些方法通常将分析集中在如何有效地组合特征上。经常被忽视的是,直接对不同的特征图应用连接或元素操作是次优的,因为一些图太杂乱,在检测和分割显著对象时可能会引入误导信息。图1说明了这个问题。
我们提出了一种新的循环定位网络(RLN),它由两个模块组成:一个类似于初始化的上下文加权模块(CWM)和一个循环模块(RM)。
 EDRNet: Encoder-Decoder Residual Network for Salient Object Detection of Strip Steel Surface Defects
EDRNet: Encoder-Decoder Residual Network for Salient Object Detection of Strip Steel Surface Defects
(用于带钢表面缺陷显著目标检测的编码器-解码器残差网络:一区)
目前,根据特征提取策略的不同,显著性检测方法主要分为两大类,即基于传统模型的方法和基于深度学习的方法。前者充分挖掘了手工制作的视觉特征的内在特征,并基于不同的假设或启发式先验开发了多种模型来检测显著目标,如稀疏编码[14]、流形排序[15]、低秩矩阵恢复[16,17]、先验知识[18]等。然而,这些人为设计的特征描述符相对复杂,提取的特征大多是浅层特征(如纹理、颜色、边缘、对比度),无法有效表征背景复杂的复杂图像。针对上述问题,基于深度学习的显著性检测方法可以在地面真值的监督下自动学习丰富的判别图像表示,显著提高显著性检测的性能。尽管这些方法与传统方法相比取得了令人印象深刻的结果,但它们预测的显著性图在目标完整性和边界保留方面仍然存在缺陷















 3194
3194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









