






原始论文:https://arxiv.org/abs/2311.07152
代码:https://github.com/HuangJunJie2017/BEVDet
我的环境:
系统:Ubuntu20.04
显卡:RTX 3090 24G X2
CPU:13th Gen Intel® Core™ i9-13900K
Docker Version:24.0.7
- 根据Dockerfile构建镜像
# 在 https://github.com/HuangJunJie2017/BEVDet.git /docker目录下找到Dockerfile下载
# 与Dockerfile同目录,保持网络通畅执行,等待大约20分钟,完整镜像约18G大小
docker build -t dal .
# 创建容器 同时将外部数据集挂在到容器内/dataset 记得更改GPU数量,我的是2gpu
docker run -it --net host --shm-size 8g -v /media/ExtHDD01/datasets/nuScenes:/dataset --name dal-container --runtime=nvidia --gpus 2 dal /bin/bash
- 在容器内,在/workspace下clone代码,构建mmdet3d框架
git clone https://github.com/HuangJunJie2017/BEVDet.git
cd ..
pip install -v -e .

- 数据准备
首先创建/dataset到框架内的软连接
cd ~/workspace/BEVDet/data && mkdir nuscenes
ln -s /dataset/* ~/workspace/BEVDet/data/nuscenes
接下来需要处理数据集,create_data_bevdet.py执行后应该生成4个pkl和一个database文件夹。完整数据集下载后原目录如下:(v1pkl和v2pkl文件夹内是我之前用mmdet3d官方的create_data生成的索引,bevdet似乎不一样,要重新生成一下)
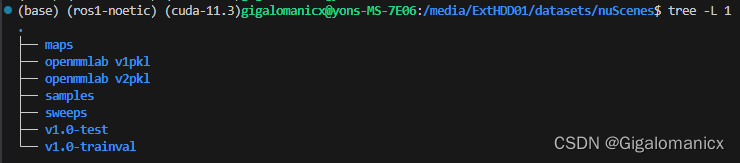
容器的路径是这样:

然后运行一下(有一点点慢,两个多小时)
python tools/create_data_bevdet.py
处理后目录如下:
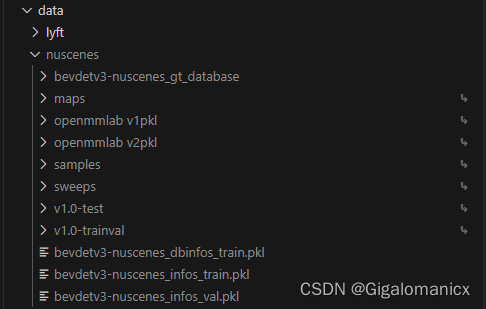
- 下载DAL预训练模型放到容器内
Tiny的FPS指标最好,但是作者在网盘里没有提供。目前只有Base和Large。

- 训练
# single gpu
python tools/train.py $config
# multiple gpu
./tools/dist_train.sh $config num_gpu
- 测试
# single gpu
python tools/test.py $config $checkpoint --eval mAP
# multiple gpu
./tools/dist_test.sh $config $checkpoint num_gpu --eval mAP
例如:
# single gpu test
python tools/test.py configs/dal/dal-base.py checkpoint/dal-base.pth --eval mAP
# multiple gpu test
./tools/dist_test.sh configs/dal/dal-base.py checkpoint/dal-base.pth 2 --eval mAP
# single gpu train
python tools/train.py configs/dal/dal-base.py
# multiple gpu train
./tools/dist_train.sh configs/dal/dal-base.py 2
- 评估推理时间
# single gpu
python tools/test.py $config $checkpoint --eval mAP
# multiple gpu
./tools/dist_test.sh $config $checkpoint num_gpu --eval mAP
我遇到的问题:
1.在执行 docker build -t dal . 时,提示FROM nvcr.io/nvidia/tensorrt:22.07-py3拉取权限问题。
见 此博客
得到NGC API Key后
docker login nvcr.io -p {$your_NGC_API_Key}
Username:$oauthtoken
2.容器运行即关闭 提示`WARNING: The NVIDIA Driver was not detected. GPU functionality will not be available.
这是因为docker并不原生支持nvidia的多卡调用。我们需要安装容器内的nvidia-toolkit,外部环境只需要安装了nvidia-driver即可。
见 此博客 和 官方安装指南
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey 或443 提示:curl: (6) Could not resolve host: nvidia.github.io 解决办法:换网
sudo nvidia-ctk runtime configure --runtime=docker 提示:INFO[0000] Loading config from /etc/docker/daemon.json ERRO[0000] unable to load config for runtime docker: EOF
 解决办法:默认用nano和vim生成的deamon.json是不带{ }的,导致判断为EOF。手动扩上{}即可。
解决办法:默认用nano和vim生成的deamon.json是不带{ }的,导致判断为EOF。手动扩上{}即可。
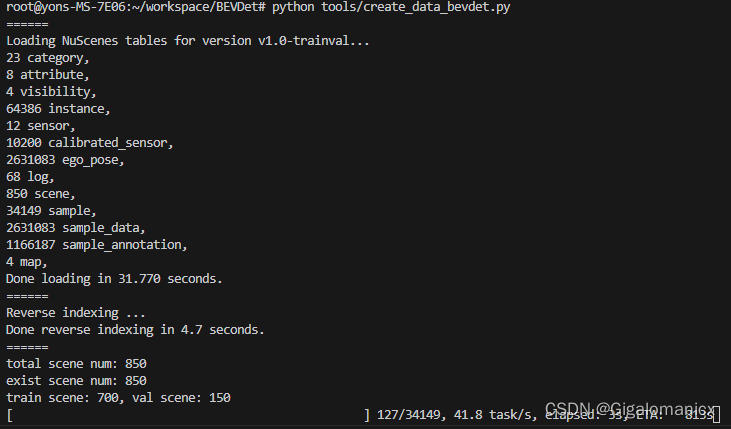
3.在容器内执行python tools/create_data_bevdet.py 提示SystemError: initialization of _internal failed without raising an exception
老问题了,在配置bevfusion的时候也遇到过,numba和numpy版本不兼容。pip list 查看为:numba=0.53.0 numpy=1.24.3
将numpy降为1.22.0成功
在转换GT database的时候有一条性能警告说是转tenser时先转numpy.ndarray能提升速度,那么修改一下 mmdet3d/datasets/pipelines/loading.py:1166
明显快了很多

4.执行测试 提示:ModuleNotFoundError: No module named ‘spconv’
pip install spconv-cu117
5.执行测试或训练提示docker内 shm共享内存不足
这里我忘了在run创建容器的时候指定–shm-size 8g(默认64mb) 此外docker update --memory 64g --memory-swap 64g dal-container
6.TypeError: FormatCode() got an unexpected keyword argument ‘verify’
pip install yapf==0.40.1
【附录】如何使用VS Code进行本地连接远程容器开发
1.确保当前用户有docker的执行权限,getent grpup查看docker组里有没有当期用户,没有加进去。
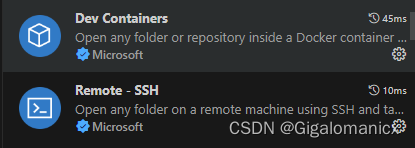
2.VS Code下载扩展
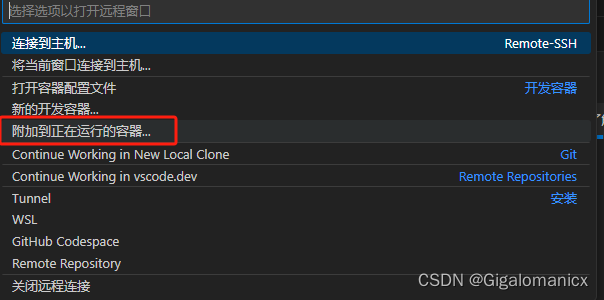
3.连接远程服务器之后,点VS Code左下角选择附加到容器

这下舒服了














 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









