






Numpy数据分析01
一、Numpy介绍
1.1 Numpy是什么
Numpy全称Numerical Python,它是:
- 一个开源的python科学计算库
- 使用numpy可以方便的使用数组、矩阵进行计算
- 包含线性代数、傅里叶变换、随机数生成等大量函数
1.2 为什么使用Numpy
(1)对于同样的数值计算任务,使用Numpy比直接Python代码实现,优点:
- 代码更简洁:Numpy直接以数组、矩阵为粒度计算并且支撑大量的数字函数,而python需要用for循环从底层实现;
- 性能更高效:Numpy的数组存储效率和输入输出计算性能,比Python使用List或者嵌套List好很多;
- Numpy的数据存储和Python原生的List是不一样的
- Numpy的大部分代码都是C语言实现的,这是Numpy比纯Python代码高效的原因
(2)Numpy是Python各种数据科学库的基础库
比如:Scipy、Scikit-Learn、TensorFlow、pandas等
1.3 Numpy下载和安装
在Windows系统下安装Numpy有两种常用方式,下面分别对其进行介绍。
- 使用python包管理器pip来安装Numpy,是一种最简单、最轻量级的方法。只需要执行以下命令即可:pip install numpy
- 使用Anaconda是一个开源的Python发行版
1.4 Numpy与原生Python的性能对比
需求:
实现两个数组加法
数组A是0到N-1数字的平方
数组B是0到N-1数字的立方
(1)用原生Python实现
A_list = []
B_list = []
C_list = [] # 用于存放相加结果
#定义函数
def sum_func(n):
for i in range(n):
A_list.append(i**2)
B_list.append(i**3)
result = A_list[i] + B_list[i]
C_list.append(result)
return C_list
# 调用函数
sum_func(5)
(2)用Numpy实现
# 导入Numpy包
import numpy as np
def numpy_sum(n):
a = np.arange(n)**2
b = np.arange(n)**3
return a + b
# 调用函数
numpy_sum(5)
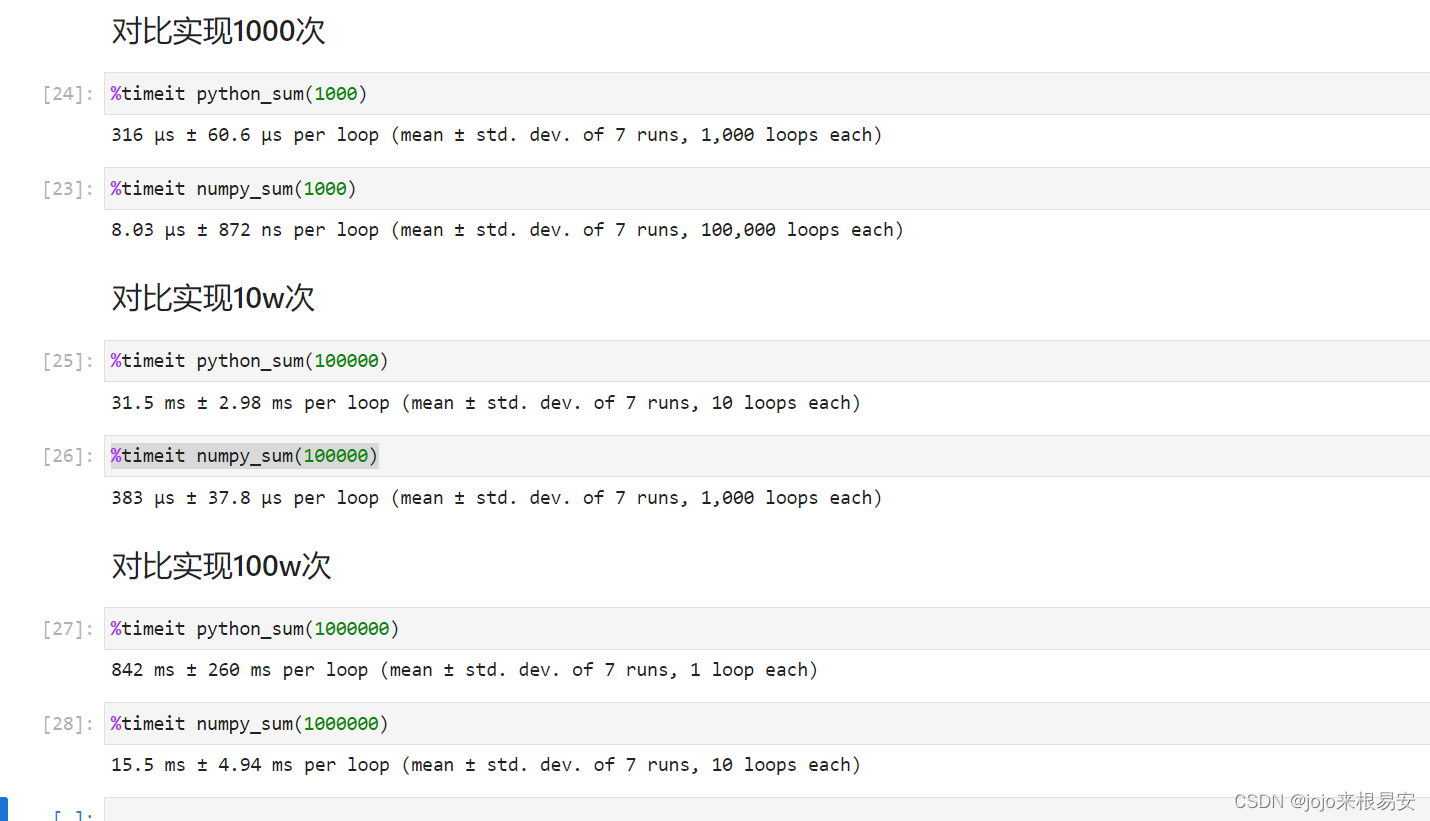
对比实现100次
print(%timeit python_sum(1000))
print(%timeit numpy_sum(1000))
输出结果:
1.4 Python和Numpy的绘图对比
import pandas as pd
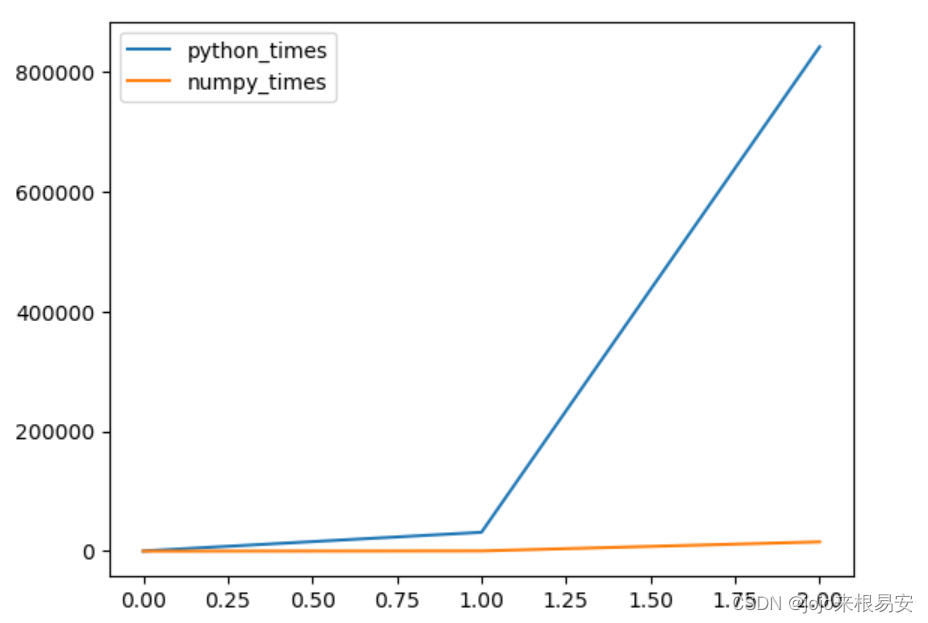
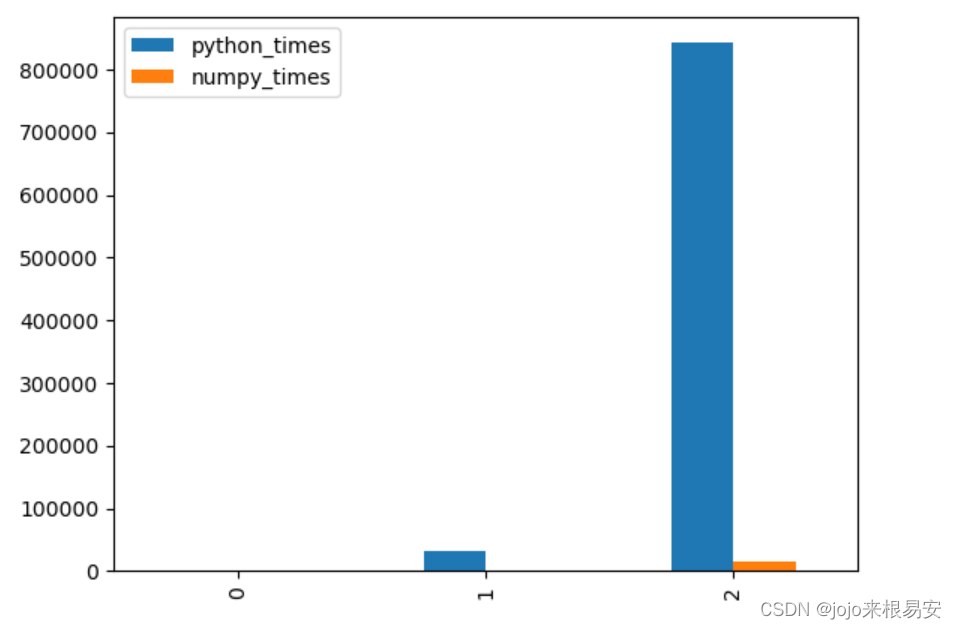
# 创建数据
python_times = [316,31.5*1000,842*1000] # us
numpy_times = [8.03,383,15.5*1000]
# 创建pandas的DataFrame类型数据
charts_data = pd.DataFrame({
'python_times':python_times,
'numpy_times':numpy_times,
})
# 打印pandas对象
print(charts_data)
# 线形图
charts_data.plot()
# 柱状图:
charts_data.plot.bar()
线形图:
柱状图:
二、Numpy ndarray对象
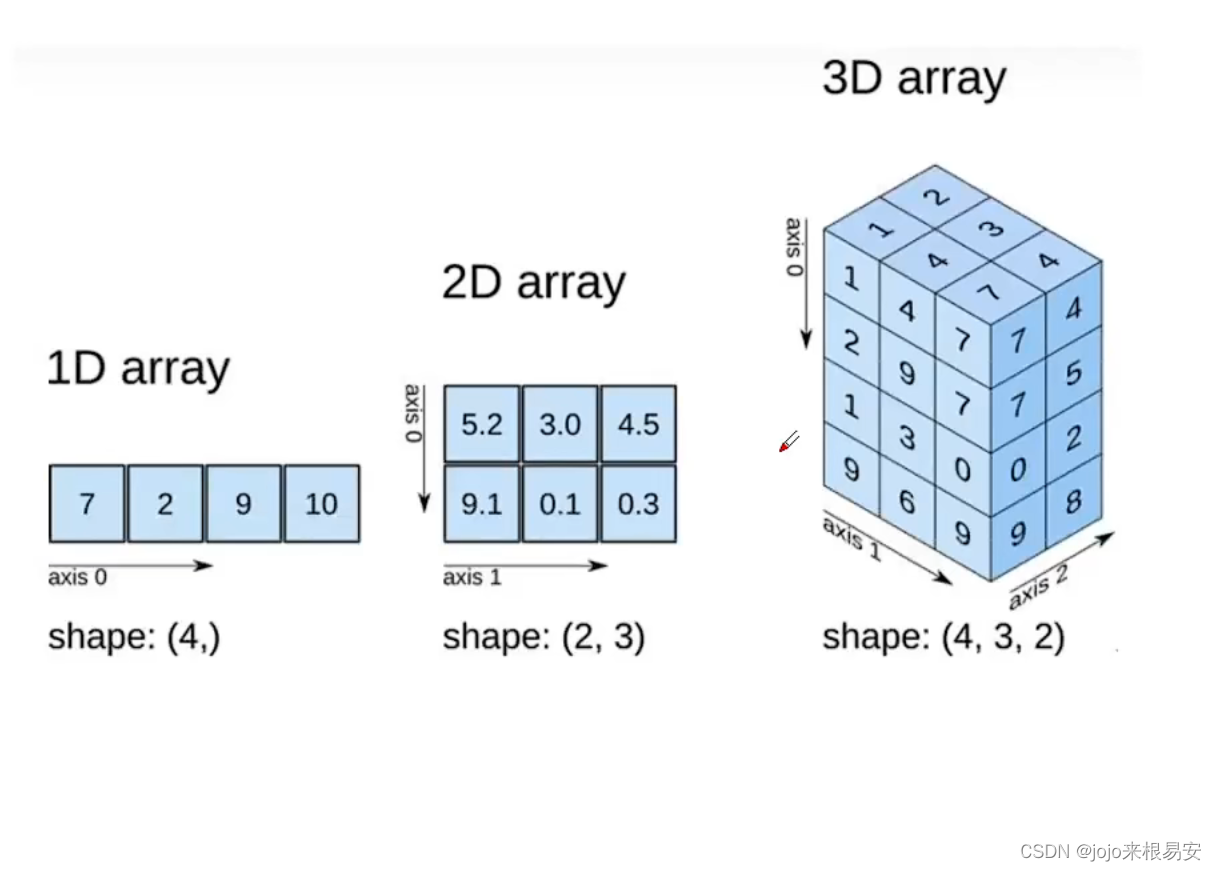
2.1 ndarray对象
- Numpy定义了一个n为数组对象,简称ndarray对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。
- ndarray对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)。
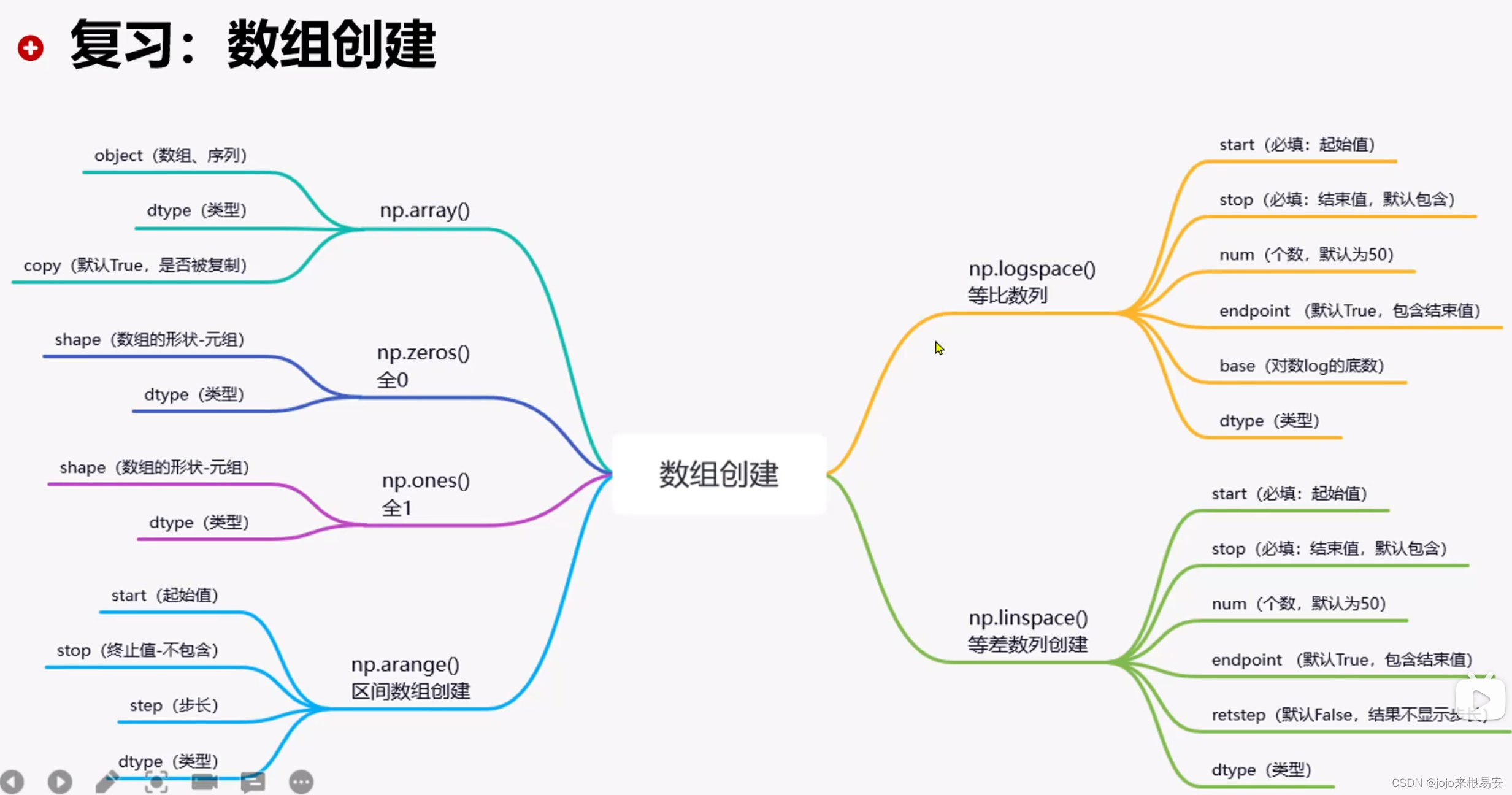
2.2 Numpy创建数组
numpy.array(object,type = None,copy = True,order = None ,subok = False ,ndmin = 0)
(1)参数# array()函数,括号内可以是列表、元组、数组、迭代对象、生成器等
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | object | 表示一个数组序列,可以把python的列表、元组等转换为数组类型 |
| 2 | dtype | 可选参数,通过它可以更改数组的数据类型 |
| 3 | copy | 可选参数,当数据源是ndarray时表示数组能否被复制,默认是True |
| 4 | order | 可选参数,以哪种内存布局创建数组,有3个可选值,分别是C(行序列)/F(列序列)/A(默认) |
| 5 | ndmin | 可选参数,用于指定数组的维度 |
| 6 | subok | 可选参数,类型为bool值,默认为False。为True时,表示使用object的内部数据类型;为False时,使用object数组的数据类型。 |
- 列表
# array()函数,括号内可以是列表、元组、数组、迭代对象、生成器等
array1 = np.array([1,2,3,4,5])
print(array1)
# 查看数组类型
print(type(array1))
np.array([1,2,3,4,5])
输出结果:(类型是np的数组类型,因为subok默认为False)

- 元组
# 元组
array2 = np.array((1,2,3,4,5))
print(array2)
print(type(array2))
np.array((1,2,3,4,5))
- 数组
# 数组
a = np.array([1,2,3,4,5])
np.array(a)
- 迭代对象
# 迭代对象
np.array(range(10))
输出结果:

- 生成器
# 生成器
np.array([i**2 for i in range(10)])
输出结果:

- 创建数组练习

- 当元素类型和数量不一致时
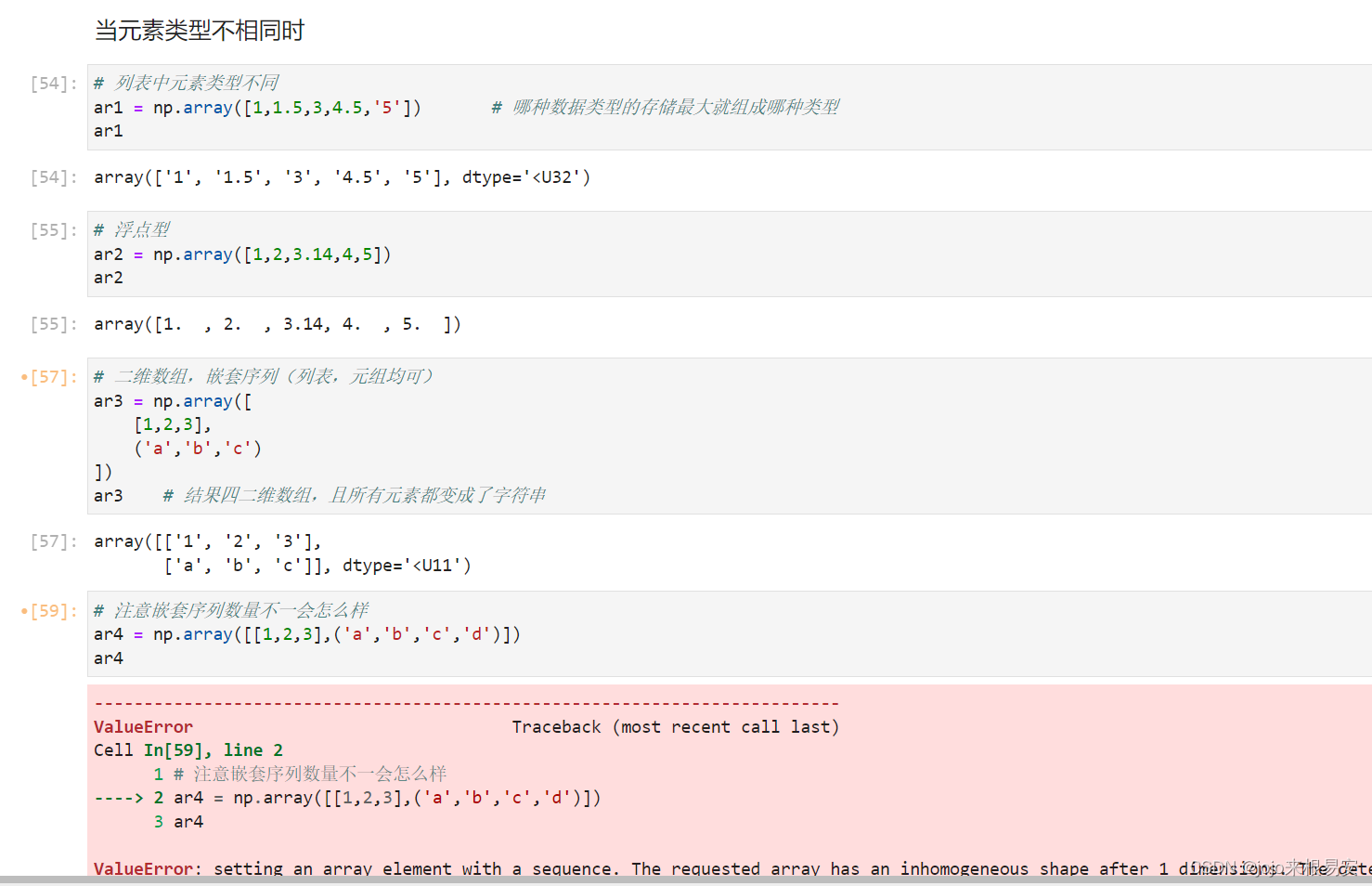
(2)设置dtype参数,默认自动识别
# 强制转化类型
a = np.array([1,2,3,4,5])
print(a)
# 设置数组元素类型
has_dtype_a = np.array([1,2,3,4,5],dtype='float')
has_dtype_a
输出结果:

如果将浮点型的数据设置为整型,会是什么情况?
# 强制转化类型
b = np.array([1.2,2.3,3.4,4.5,5.6])
print(b)
# 设置数组元素类型
has_dtype_b = np.array([1.2,2.3,3.4,4.5,5.6],dtype='int')
has_dtype_b
输出结果:

(3)设置copy参数,默认为True
在Python中,对列表变量有复制传值和引用传值两种操作。列表变量不直接存储数据,存的是该数据存放的内存地址。
如果是引用传值, 则被传值的变量b与传值变量a的id相同,即指向内存中同一位置的数据,相当于对原列表变量a的引用。对于引用传值,如果改变被传值变量b或者传值变量a中的元素值,a或者b中对应的元素值也会改变,因为它们指向的同一内存地址中存放的数据已经发生变化。
如果是复制传值,则相当于创建了一个新变量,新变量的值就是从原变量中复制而来,并且内存中会为新变量开辟一个新的存储位置用于存放新变量的数据。新变量c和原变量a的指针指向的是内存中不同的位置,因此当它们俩其中一个的元素发生变化时,并不会对另一个产生影响,因为另一个的指针指向的数据存放地址中的数据并没有发生改变。
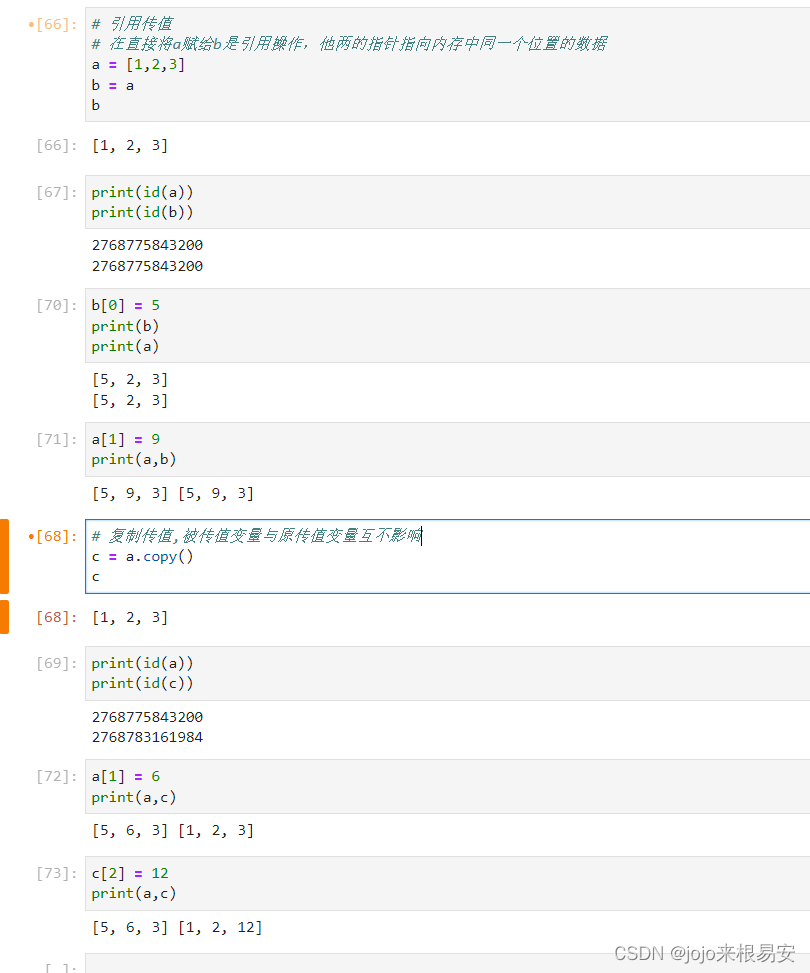
查看a和b的内存地址
a = np.array([1,2,3,4,5])
# 定义b,复制a
b = np.array(a)
# 输出a和b的id
print('a:',id(a),'b:',id(b))
print('以上可以看出a和b的地址')
输出:a和b的内存地址不同,说明两者之一发生变化时不会影响另一方。
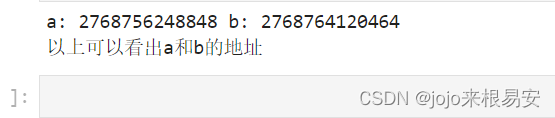
- 当设置copy参数为False时
定义b,当设置copy参数为False时,不会创建副本。两个变量会指向相同的内存地址,没有创建新对象,即copy参数为False时是引用传参。
a = np.array([1,2,3,4,5])
# 定义b,当设置copy参数为False时,不会创建副本
# 两个变量会指向相同的内存地址,没有创建新对象
# 即copy参数为False时是引用赋值
b = np.array(a,copy=False)
# 输出a和b的id
print('a:',id(a),'b:',id(b))
print('以上可以查看a和b的内存地址')
# 由于a和b指向的是相同的内存地址,因此修改b的元素时,a会发生变化
b[0] = 10
print('a:',a,'b:',b)
输出结果:
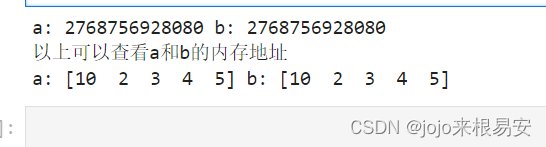
- 当默认copy参数为True时
定义b,会创建副本。两个变量会指向不同的内存地址,即创建新对象,说明copy参数为True时是复制传参。
(4)ndmin用于指定数组维度
a = np.array([1,2,3])
print(a)
a = np.array([1,2,3],ndmin=2)
print(a)
a.ndim # 查看数组a的维度
输出结果:

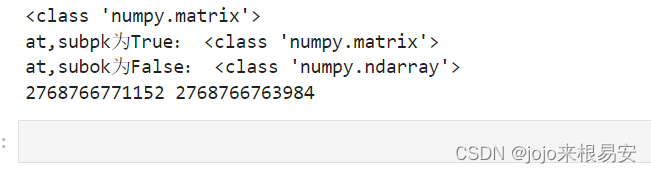
(5)subok参数,类型为bool值,默认为False。为True时,表示使用object的内部数据类型;为False时,使用object数组的数据类型。
# 创建一个矩阵
a = np.mat([1,2,3,4])
# 输出矩阵的类型
print(type(a))
# 既要复制一份副本,又要保持原类型
at = np.array(a,subok=True)
af = np.array(a) # 默认为False
print('at,subpk为True:',type(at))
print('at,subok为False:',type(af))
print(id(at),id(a))
输出结果:
练习
- 创建一个一维数组
- 创建一个二维数组
- 创建嵌套序列数量不一样的数组,查看结果
- 测试数组a,将数组赋值给b,修改b中的一个元素,查看a是否变化
- 紧接上一条,如果想让b变化不影响a,如何实现
import numpy as np
# 创建一个一维数组
a = np.array([1,2,3,4])
a

# 创建一个二维数组
b = np.array([[1,2,3],('a','b','c')])
print(b.ndim)
b
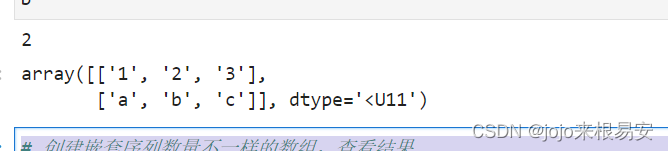
# 创建嵌套序列数量不一样的数组,查看结果
c = np.array([[1,2,3],(1,2,3,4)])
print(c.ndim)
c

# 测试数组a,将数组赋值给b,修改b中的一个元素,查看a是否变化
a = np.array([1,2,3,4])
b = np.array(a,copy=False) # 参数copy为False,不会创建副本,是引用传参
print('a的内存地址:',id(a),'b的内存地址:',id(b))
b[0] = 8
print(a,b)

# 紧接上一条,如果想让b变化不影响a,如何实现
a = np.array([1,2,3,4])
b = np.array(a) # 参数copy默认为True,不会创建副本,是复制传参
print('a的内存地址:',id(a),'b的内存地址:',id(b))
b[0] = 8
print(a,b)

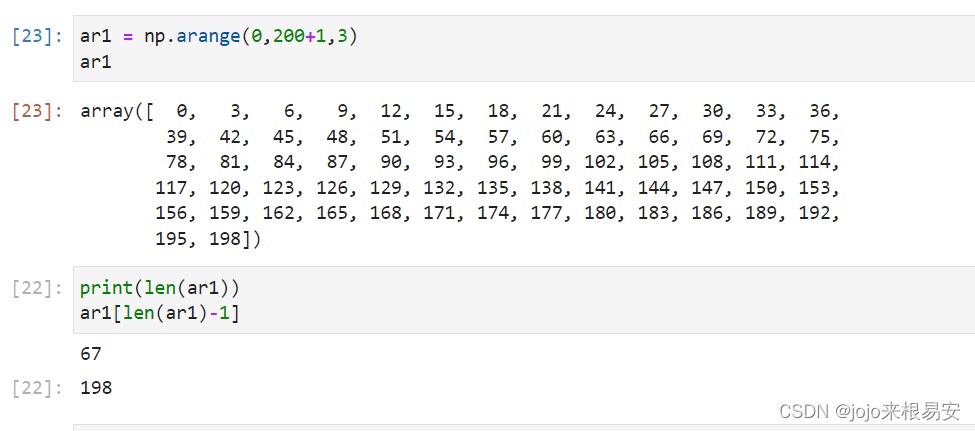
2.3 arange()生成区间数组
根据start与stop指定的范围以及step设定的步长,生成一个ndarray。
numpy.arange(start,stop,step,dtype)
参数说明:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 起始值,默认为0 |
| 2 | stop | 终止值(不包含) |
| 3 | step | 步长,默认为1 |
| 4 | dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型 |
arange比range更高级,因为arange可以带浮点型的数据,生成浮点型的数组。range只能带整型的数据,否则会报错。
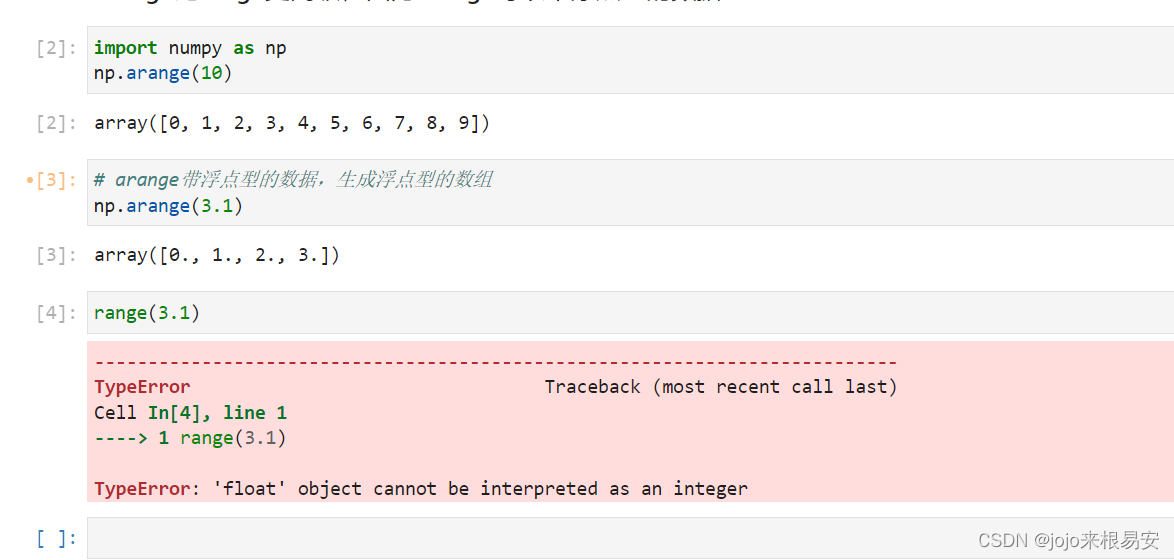
也可以通过dtype指定类型,返回浮点型的数据
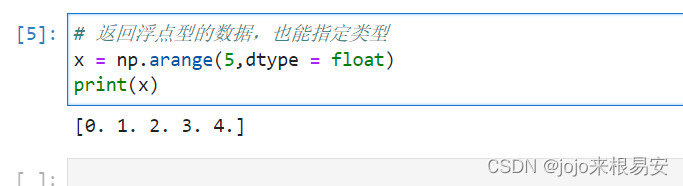
设置了起始值、终止值及步长:

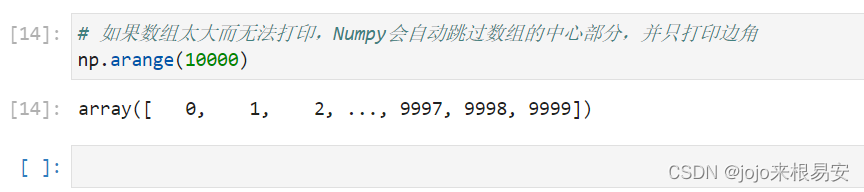
如果数组太大而无法打印,Numpy会自动跳过数组的中心部分,并只打印边角。
题目:在庆祝教师节活动中,学校为了烘托节日气氛,在200米长的校园主干道一侧,从起点开始,每间隔3米插一面彩旗,由近到远排成一排
问:
- 最后一面彩旗会插到终点处吗
- 一共应插多少面彩旗?
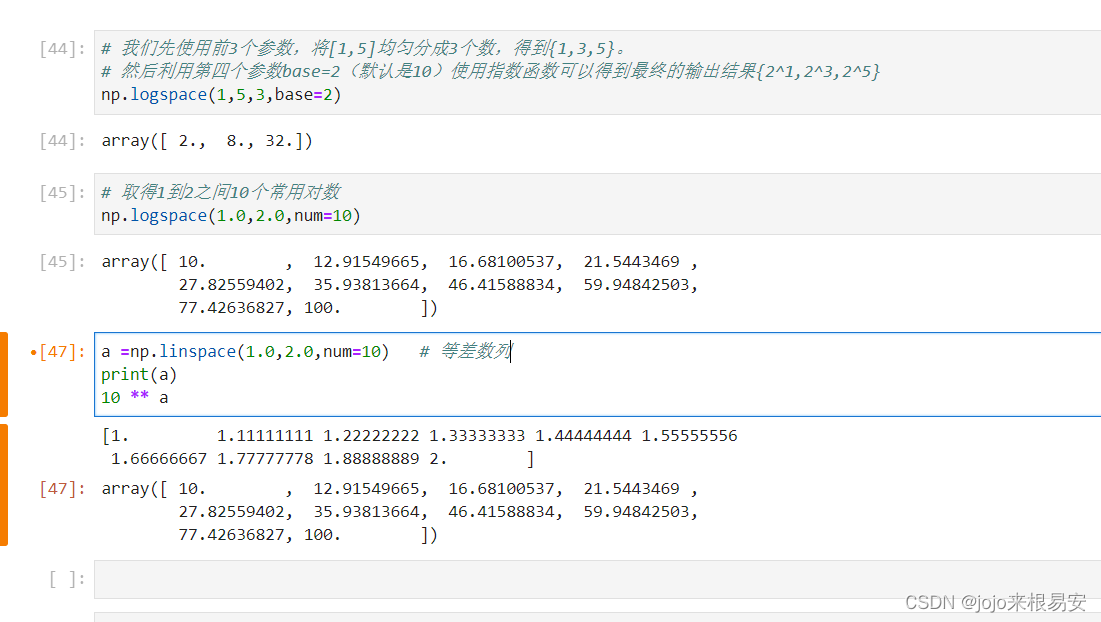
2.4 linspace()创建等差数列
返回在间隔[开始,停止]上计算的num个均匀间隔样本。数组是一个等差数列构成。
np.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
参数说明:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值 |
| 2 | stop | 必填项,序列的终止值,如果endpoint为True,该值包含在数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为True时,数列中包含stop值,反之不包含,默认是True |
| 5 | retstep | 如果为True时,生成的数组会显示间距,反之不显示。 |
| 6 | dtype | ndarray的数据类型 |
- 设置参数start、stop和num

- 设置参数endpoint

- 设置参数retstep

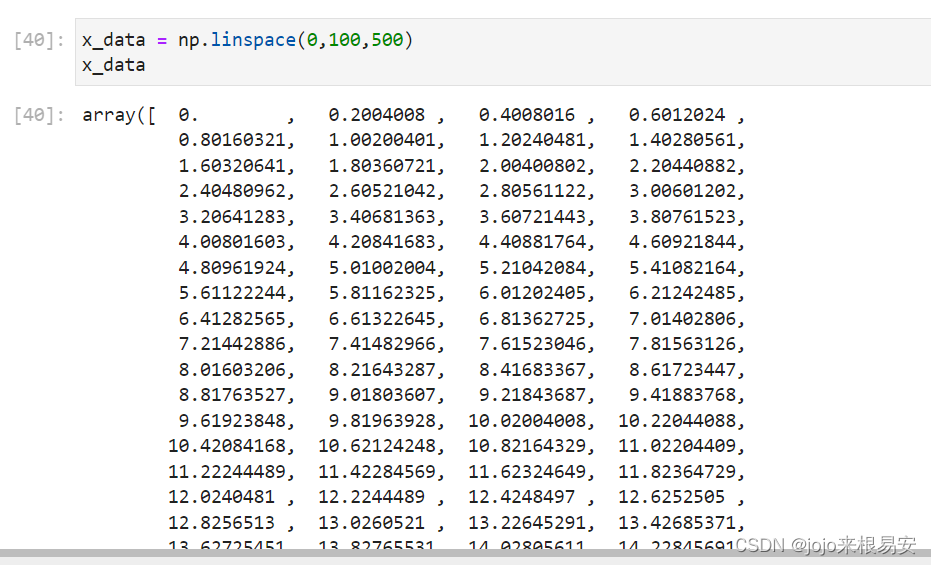
等差数列在线性回归中经常作为样本集
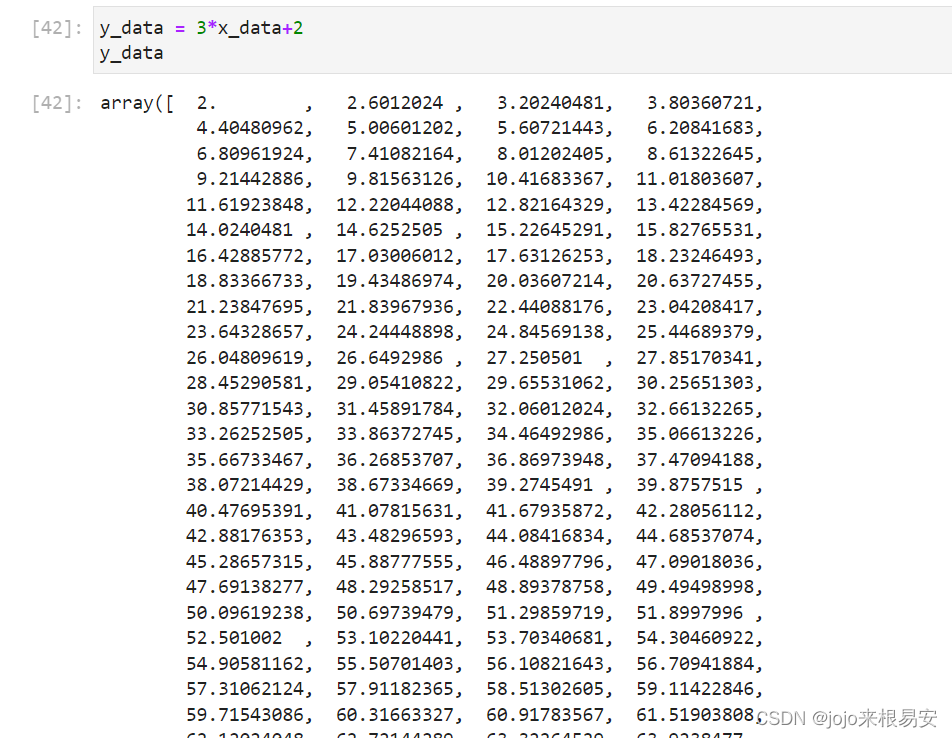
如:生成x_data,值为[0,100]之间的500个等差数列数据集合作为样本特征,根据目标线性方程y=3*x+2,生成相应的标签集合y_data。
y_data:
2.5 等比数列
返回在间隔[开始,结束]上计算的num个均匀间隔的样本。数组是一个等比数列构成
np.logspace(start,stop,num=50,endpoint=True,base=10.0,dtype=None)
参数说明:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值 |
| 2 | stop | 必填项,序列的终止值,如果endpoint为True,该值包含,于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为True时,数列中包含stop值,反之不包含,默认是True |
| 5 | base | 对数log的底数 |
| 6 | =dtype | ndarray的数据类型 |
np.logspace(A,B,C,base=D)
- A: 生成数组的起始值为D的A次方
- B:生成数组的结束值为D的B次方
- C:总共生成C个数
- D:指数型数组的底数为D,当省略base=D时,默认底数是10

等比数列,就是先生成一个等差数列,再用他们作为底数的幂次即可得到等比数列。
2.6 全0数列和全1数列
(1)全0数列
创建指定大小的数组,数组元素以0来填充,数据类型默认为浮点型。
numpy.zeros(shape,dtype=float,order='C')
参数说明:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | shape | 数组形状 |
| 2 | dtype | 数组类型,可选 |

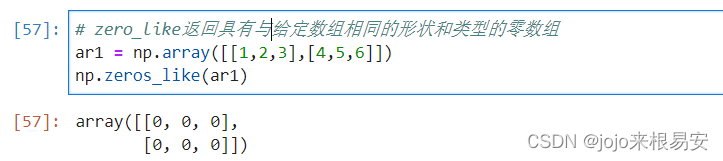
- zero_like返回具有与给定数组相同的形状和类型的零数组
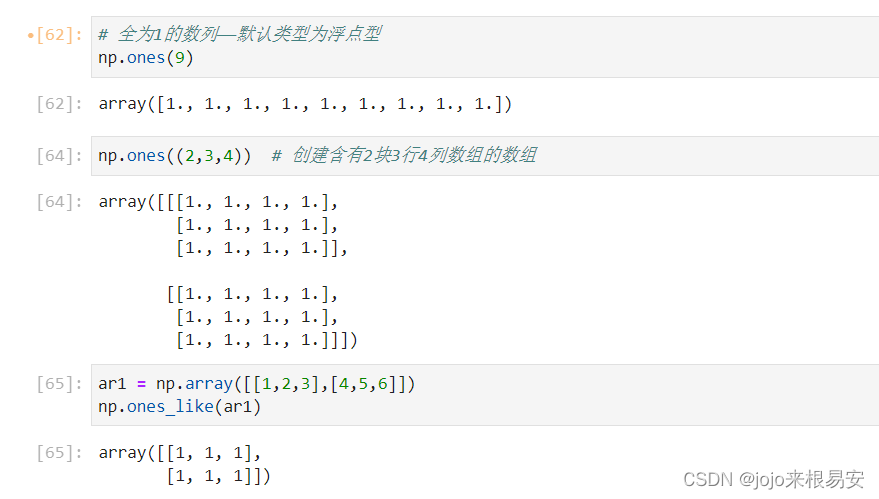
(2)全1数列
np.ones的参数与np.zeros的参数相同。
numpy.zeros(shape,dtype=float,order='C')
三、Numpy数组属性
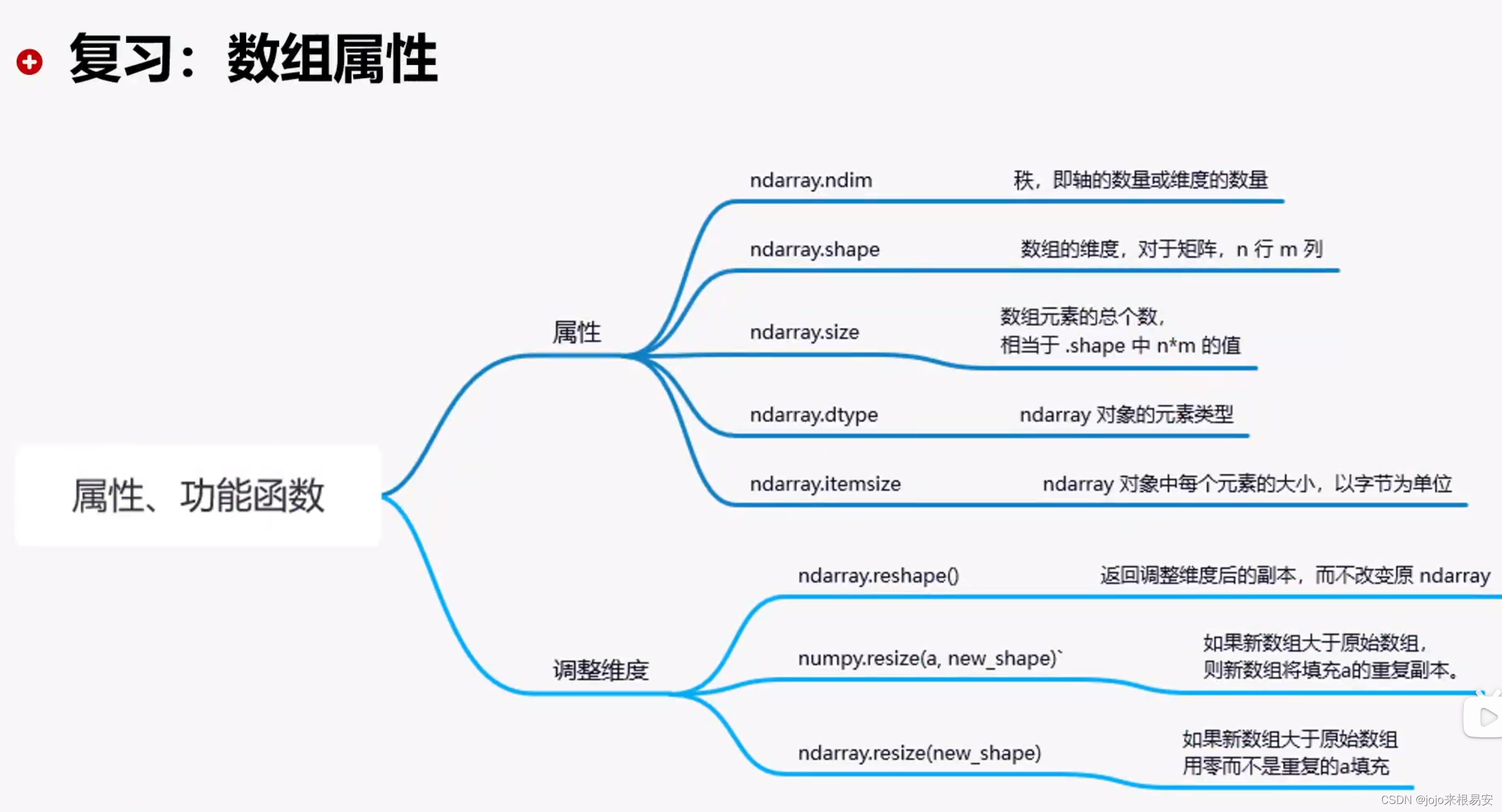
Numpy的数组中比较重要的ndarray对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度数量 |
| ndarray.shape | 数组的维度,对于矩阵,n行m列 |
| ndarray.size | 数组元素的总个数,相当于.shape中n*m的值 |
| ndarray.dtype | ndarray对象的元素类型 |
| ndarray.itemsize | 对象中每个元素的大小,以字节为单位 |
3.1 ndarray.shape
返回一个包含数组维度的元组,对于矩阵,n行m列,它也可以用于调整数组的维度。
a = np.array([1,2,3,4,5,6])
print('一维数组:',a.shape)
b = np.array([[1,2,3],[4,5,6]])
print('二维数组:',b.shape)
c = np.array([
[
[1,2,3],
[4,5,6]
],
[
[11,22,33],
[44,55,66]
]
])
print('三维数组:',c.shape)
输出结果:

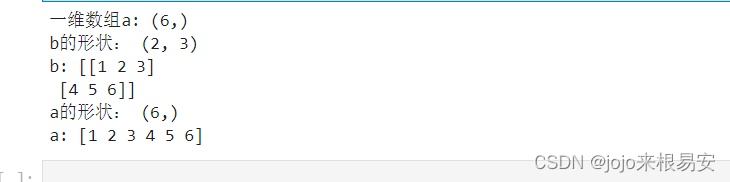
(1)调整维度reshape
返回调整维度后的副本,而不改变原ndarray。

a = np.array([1,2,3,4,5,6])
print('一维数组a:',a.shape)
# 使用a数组,创建一个新的数组b,并将形状修改为2行3列
b = a.reshape((2,3))
print('b的形状:',b.shape)
print('b:',b)
print('a的形状:',a.shape)
print('a:',a)
输出结果:
(2)调整维度resize
b=numpy.resize(a,new_shape) 如果新数组b大于原数组a,则新数组b将填充a的重复副本。
a.resize(new_size,refcheck=False) 如果新数组大于原数组,用0填充。
# a为2行2列
a = np.array([[0,1],[2,3]])
print('a:',a)
# 为原数组创建2行3列的新数组
b_2_3 = np.resize(a,(2,3))
print('b_2_3:',b_2_3)
输出结果:

# 用0填充
a = np.array([[0,1],[2,3]])
a.resize((3,4),refcheck=False) # refcheck=False 表示不进行检查
a
输出结果:
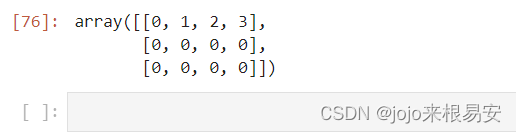
3.2 ndarray.ndim
返回数组的维度(秩):轴的数量,或者维度的数量,是一个标量,一维数组的秩为1,二维数组的秩为2。

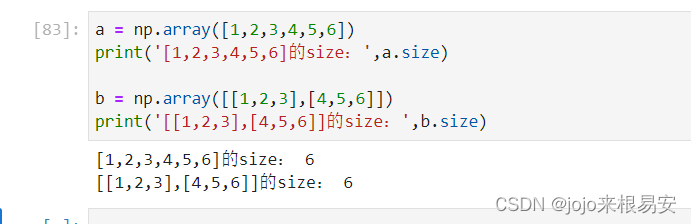
3.3 ndarray.size
数组元素总个数,相当于.shape中n*m的值
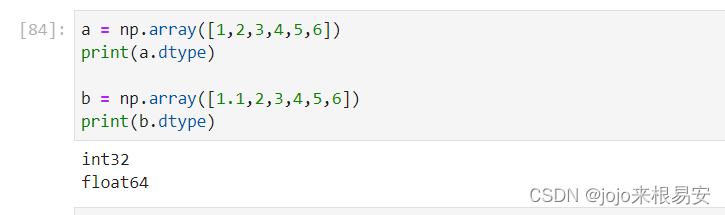
3.4 ndarray.dtype
ndarray对象的元素类型。
3.5 方法astype()
numpy数据类型转换,调用astype返回数据类型修改后的数据,但是源数据的类型不会变。
a = np.array([1.1,1.2])
print('a数据类型:',a.dtype)
print('astype修改后的数据类型:',a.astype('float32').dtype)
print('元数据类型并未改变',a.dtype)
print('--'*20)
# 若要修改a的数据类型,则将astype修改后的结果重新赋值给a
a = a.astype('float32')
print('修改类型后再次操作,类型改变:',a.dtype)
输出结果:

通过astype将a的数据类型改为整型。

3.6 ndarray.itemsize
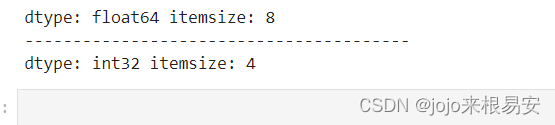
以字节的形式返回数组中每一个元素的大小。
例如,一个元素类型为float64的数组itemsize属性值为8(float64占用64个bits,每个字节长度为8,所以64/8,占用8个字节)
a = np.array([1.1,2.2,3.3])
print('dtype:',a.dtype,'itemsize:',a.itemsize)
print('--'*20)
b = np.array([1,2,3,4,5])
print('dtype:',b.dtype,'itemsize:',b.itemsize)
输出结果:
总结














 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









